Esta arquitetura de referência mostra um conjunto de práticas comprovadas para a execução de uma aplicação de N camadas em várias regiões do Azure, para obter disponibilidade e uma infraestrutura de recuperação após desastre robusta.
Arquitetura
Transfira um ficheiro do Visio desta arquitetura.
Fluxo de Trabalho
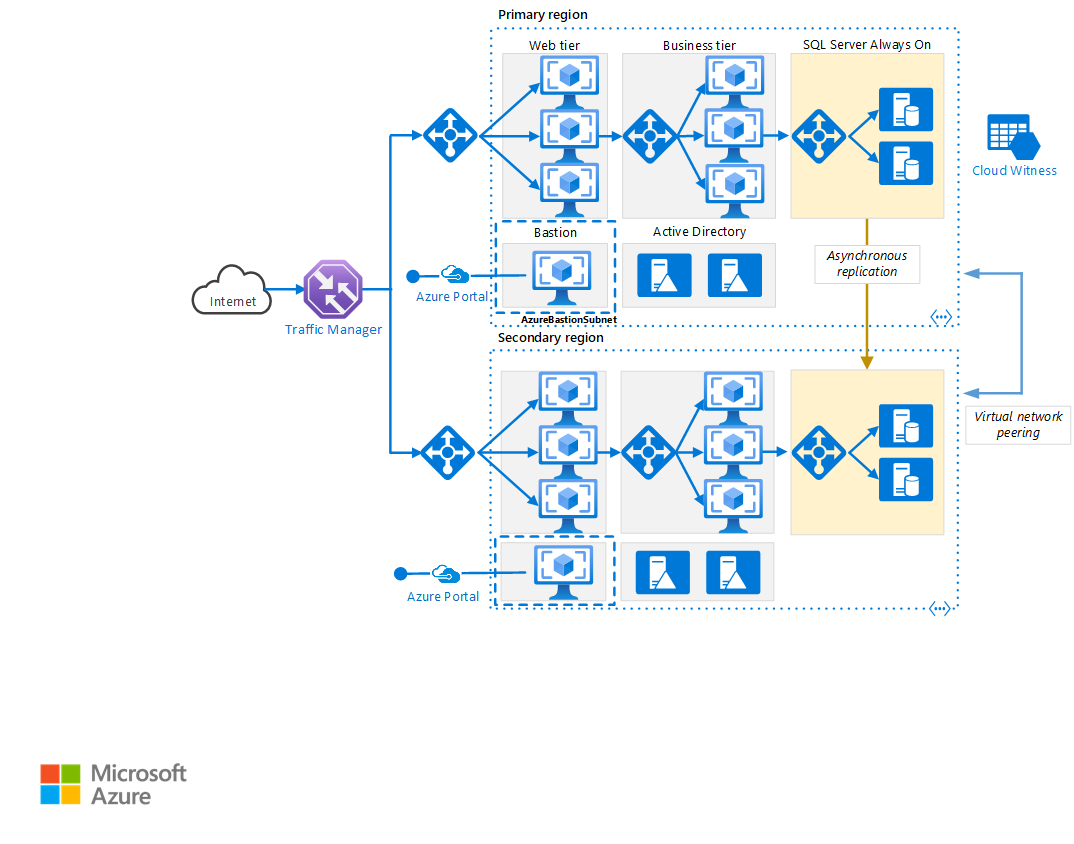
Regiões primária e secundária. Utilize duas regiões para alcançar uma disponibilidade mais elevada. Uma é a região primária. A outra região destina-se a ativação pós-falha.
Gestor de Tráfego do Azure. O Gestor de Tráfego encaminha os pedidos recebidos para uma das regiões. Durante as operações normais, este encaminha os pedidos para a região primária. Se esta região ficar indisponível, o Gestor de Tráfego efetuará a ativação pós-falha para a região secundária. Para obter mais informações, veja a secção Configuração do Gestor de Tráfego.
Grupos de recursos. Crie grupos de recursos separados para a região primária, a região secundária e o Gestor de Tráfego. Esse método oferece a flexibilidade de gerenciar cada região como uma única coleção de recursos. Por exemplo, pode reimplementar uma região, sem ter de encerrar a outra. Ligue os grupos de recursos para que possa executar uma consulta para listar todos os recursos da aplicação.
Redes virtuais. Crie uma rede virtual separada para cada região. Certifique-se de que os espaços de endereço não se sobrepõem.
Grupo de Disponibilidade AlwaysOn do SQL Server. Se você usa o SQL Server, recomendamos os Grupos de Disponibilidade Sempre Ativos do SQL para alta disponibilidade. Crie um único grupo de disponibilidade que inclua as instâncias do SQL Server em ambas as regiões.
Nota
Considere também a Base de Dados SQL do Azure, que fornece uma base de dados relacional como um serviço cloud. Com a Base de Dados SQL Server, não precisa de configurar um grupo de disponibilidade ou gerir a ativação pós-falha.
Emparelhamento de rede virtual. Emparelhe as duas redes virtuais para permitir a replicação de dados da região primária para a região secundária. Para obter mais informações, consulte Emparelhamento de rede virtual.
Componentes
- Os conjuntos de disponibilidade garantem que as VMs implantadas no Azure sejam distribuídas em vários nós de hardware isolados em um cluster. Se ocorrer uma falha de hardware ou software no Azure, apenas um subconjunto de suas VMs será afetado e toda a sua solução permanecerá disponível e operacional.
- As zonas de disponibilidade protegem seus aplicativos e dados contra falhas no datacenter. As zonas de disponibilidade são locais físicos separados dentro de uma região do Azure. Cada zona consiste em um ou mais datacenters equipados com energia, resfriamento e rede independentes.
- O Azure Traffic Manager é um balanceador de carga de tráfego baseado em DNS que distribui o tráfego de forma otimizada. Ele fornece serviços em todas as regiões globais do Azure, com alta disponibilidade e capacidade de resposta.
- O Azure Load Balancer distribui o tráfego de entrada, de acordo com regras definidas e testes de integridade. Um balanceador de carga fornece baixa latência e alta taxa de transferência, dimensionando até milhões de fluxos para todos os aplicativos TCP e UDP. Um balanceador de carga público é usado nesse cenário, para distribuir o tráfego de entrada do cliente para a camada da Web. Um balanceador de carga interno é usado nesse cenário para distribuir o tráfego da camada de negócios para o cluster back-end do SQL Server.
- O Azure Bastion fornece conectividade RDP e SSH segura para todas as VMs, na rede virtual na qual ele é provisionado. Use o Azure Bastion para proteger suas máquinas virtuais contra a exposição de portas RDP/SSH para o mundo exterior, enquanto ainda fornece acesso seguro usando RDP/SSH.
Recomendações
Uma arquitetura de várias regiões pode fornecer maior disponibilidade em comparação com a implementação de uma única região. Se uma falha regional afetar a região primária, poderá utilizar o Gestor de Tráfego para efetuar a ativação pós-falha para a região secundária. Esta arquitetura também poderá ajudar se um subsistema individual da aplicação falhar.
Existem várias abordagens gerais para assegurar elevada disponibilidade nas regiões:
- Modo ativo/passivo com reserva ativa. O tráfego segue para uma região, enquanto a outra aguarda na reserva ativa. Hot standby significa que as VMs na região secundária são alocadas e estão sempre em execução.
- Modo ativo/passivo com reserva progressiva. O tráfego segue para uma região, enquanto a outra aguarda na reserva progressiva. O modo de espera a frio significa que as VMs na região secundária não são alocadas até que seja necessário para o failover. Esta abordagem tem um custo de execução inferior, mas geralmente demora mais tempo a ficar online durante uma falha.
- Modo ativo/ativo. Ambas as regiões estão ativas e a carga dos pedidos é balanceada entre ambas. Se uma região ficar indisponível, ela será retirada da rotação.
Esta arquitetura de referência centra-se no modo ativo/passivo com reserva ativa e utiliza o Gestor de Tráfego para a ativação pós-falha. Você pode implantar algumas VMs para espera ativa e, em seguida, expandir conforme necessário.
Emparelhamento regional
Cada região do Azure é emparelhada com outra região na mesma geografia. Em geral, escolha regiões do mesmo par regional (por exemplo, E.U.A. Leste 2 e E.U.A. Central). Benefícios desta opção:
- Se houver uma interrupção ampla, a recuperação de pelo menos uma região de cada par é priorizada.
- As atualizações planeadas do sistema Azure são implementadas em regiões emparelhadas sequencialmente, para minimizar a possibilidade de períodos de indisponibilidade.
- Os pares residem na mesma área geográfica para satisfazer os requisitos de residência dos dados.
No entanto, verifique se ambas as regiões suportam todos os serviços do Azure necessários para a sua aplicação (veja Serviços por região). Para obter mais informações sobre pares regionais, veja Continuidade do negócio e recuperação após desastre (BCDR): Regiões Emparelhadas do Azure.
Configuração do Gestor de Tráfego
Quando configurar o Gestor de Tráfego, considere os seguintes pontos:
- Encaminhamento. O Gestor de Tráfego suporta vários algoritmos de encaminhamento. Para o cenário descrito neste artigo, utilize o encaminhamento prioritário (anteriormente denominado encaminhamento ativação pós-falha). Com esta definição, Gestor de Tráfego envia todos os pedidos para a região primária, a menos que a região primária fique inacessível. Nessa altura, este efetua a ativação pós-falha automaticamente para a região secundária. Veja Configurar o método de encaminhamento de ativação pós-falha.
- Sonda de estado de funcionamento. O Gestor de Tráfego utiliza uma sonda HTTP (ou HTTPS) para monitorizar a disponibilidade de cada região. A sonda verifica a existência de uma resposta HTTP 200 para um caminho de URL especificado. Como melhor prática, crie um ponto final que reporte o estado de funcionamento geral da aplicação e utilize este ponto final para a sonda de estado de funcionamento. Caso contrário, a sonda pode indicar que um ponto final está em bom estado quando, na verdade, as partes críticas da aplicação estão a falhar. Para obter mais informações, consulte Padrão de monitoramento de ponto de extremidade de integridade.
Quando o Gerenciador de Tráfego faz failover, há um período de tempo em que os clientes não conseguem acessar o aplicativo. A duração é afetada pelos seguintes fatores:
- A sonda de estado de funcionamento tem de detetar que a região primária ficou inacessível.
- Os servidores DNS têm de atualizar os registos DNS em cache do endereço IP, o qual depende do time-to-live (TTL) do DNS. O TTL predefinido é de 300 segundos (5 minutos), mas também pode configurar este valor quando cria o perfil do Gestor de Tráfego.
Para obter detalhes, veja Acerca da Monitorização do Gestor de Tráfego.
Se o Gestor de Tráfego efetuar uma ativação pós-falha, recomendamos a execução de uma reativação pós-falha manual ao invés de implementar uma reativação pós-falha automática. Caso contrário, a aplicação pode alternar continuamente entre as regiões. Verifique se todos os subsistemas da aplicação estão em bom estado antes da reativação pós-falha.
O Gestor de Tráfego falha automaticamente por predefinição. Para evitar esse problema, diminua manualmente a prioridade da região primária após um evento de failover. Por exemplo, suponha que a região primária tem uma prioridade 1 e a secundária uma prioridade 2. Após uma ativação pós-falha, defina a região primária para uma prioridade 3, para impedir a reativação pós-falha automática. Quando estiver pronto para voltar, atualize a prioridade para 1.
O seguinte comando da CLI do Azure atualiza a prioridade:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --priority 3
Outra abordagem é desativar temporariamente o ponto de extremidade até que você esteja pronto para failback:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --endpoint-status Disabled
Dependendo do motivo de uma ativação pós-falha, pode ter de reimplementar os recursos numa região. Antes da reativação pós-falha, realize um teste de preparação operacional. O teste deve verificar fatores como:
- As VMs estão configuradas corretamente. (Todo o software necessário está instalado, o IIS está em execução, entre outros.)
- Os subsistemas da aplicação estão em bom estado.
- Teste funcional. (Por exemplo, a camada de base de dados está acessível a partir da camada Web.)
Configurar os Grupos de Disponibilidade AlwaysOn do SQL Server
Com as versões anteriores ao Windows Server 2016, os Grupos de Disponibilidade AlwaysOn do SQL Server necessitam de um controlador de domínio e todos os nós no grupo de disponibilidade têm de estar no mesmo domínio do Active Directory (AD).
Para configurar o grupo de disponibilidade:
No mínimo, coloque dois controladores de domínio em cada região.
Atribua um endereço IP estático a cada controlador de domínio.
Emparelhe as duas redes virtuais para permitir a comunicação entre elas.
Para cada rede virtual, adicione os endereços IP dos controladores de domínio (de ambas as regiões) à lista de servidores DNS. Pode utilizar o seguinte comando da CLI. Para obter mais informações, consulte Alterar servidores DNS.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Crie um cluster WSFC (Clustering de Ativação Pós-falha do Windows Server) que inclua as instâncias do SQL Server em ambas as regiões.
Crie um Grupo de Disponibilidade AlwaysOn do SQL Server que inclua as instâncias do SQL Server tanto na região primária como na secundária. Para obter os passos seguintes, veja Extending Always On Availability Group to Remote Azure Datacenter (PowerShell) (Expandir o Grupo de Disponibilidade AlwaysOn para o Datacenter do Azure Remoto (PowerShell)).
Coloque a réplica primária na região primária.
Coloque uma ou mais réplicas secundárias na região primária. Configure essas réplicas para usar confirmação síncrona com failover automático.
Coloque uma ou mais réplicas secundárias na região secundária. Configure essas réplicas para usar confirmação assíncrona , por motivos de desempenho. (Caso contrário, todas as transações T-SQL têm de esperar por um percurso de ida e volta na rede para a região secundária.)
Nota
As réplicas de confirmação assíncronas não suportam failover automático.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios orientadores que podem ser usados para melhorar a qualidade de uma carga de trabalho. Para obter mais informações, consulte Microsoft Azure Well-Architected Framework.
Disponibilidade
Com uma aplicação de N camadas complexa, pode não ter de replicar toda a aplicação na região secundária. Em vez disso, pode replicar apenas um subsistema crítico necessário para suportar a continuidade do negócio.
O Gestor de Tráfego é um ponto de falha possível no sistema. Se o serviço Gerenciador de Tráfego falhar, os clientes não poderão acessar seu aplicativo durante o tempo de inatividade. Reveja o SLA do Gestor de Tráfego e determine se a utilização do Gestor de Tráfego cumpre os seus requisitos de negócio para elevada disponibilidade. Se não for o caso, pondere adicionar outra solução de gestão de tráfego para fins de reativação pós-falha. Se o serviço Gestor de Tráfego do Azure falhar, altere os registos CNAME no DNS de modo a apontar para o outro serviço de gestão de tráfego. (Este passo tem de ser realizado manualmente e a aplicação ficará indisponível até que as alterações do DNS sejam propagadas.)
Para o cluster do SQL Server, existem dois cenários de ativação pós-falha a ter em consideração:
Todas as réplicas da base de dados do SQL Server na região primária falham. Por exemplo, essa falha pode acontecer durante uma interrupção regional. Nesse caso, tem realizar manualmente a ativação pós-falha do grupo de disponibilidade, apesar de o Gestor de Tráfego realizar automaticamente a ativação pós-falha no front-end. Siga os passos em Executar uma Ativação Pós-falha Manual Forçada de um Grupo de Disponibilidade do SQL Server, que descreve como efetuar uma ativação pós-falha forçada com o Management Studio do SQL Server, o Transact-SQL ou o PowerShell no SQL Server 2016.
Aviso
Com o failover forçado, há um risco de perda de dados. Assim que a região primária esteja novamente online, tire um instantâneo da base de dados e utilize tablediff para encontrar as diferenças.
O Gestor de Tráfego efetua a ativação pós-falha para a região secundária, mas a réplica primária da base de dados do SQL Server continua disponível. Por exemplo, a camada front-end pode falhar, sem afetar as VMs do SQL Server. Nesse caso, o tráfego da Internet é encaminhado para a região secundária e essa região ainda pode estabelecer uma ligação com a réplica primária. No entanto, haverá uma maior latência, uma vez que as ligações do SQL Server estão a atravessar regiões. Nesta situação, deve efetuar uma ativação pós-falha manual da seguinte forma:
- Ative temporariamente uma réplica da base de dados do SQL Server na região secundária para uma consolidação síncrona. Esta etapa garante que não haverá perda de dados durante o failover.
- Efetue a ativação pós-falha para essa réplica.
- Quando efetuar a reativação pós-falha para a região primária, restaure a definição de consolidação assíncrona.
Capacidade de gestão
Quando atualiza a implementação, atualize uma região de cada vez para reduzir a probabilidade de uma falha global provocada por uma configuração incorreta ou um erro na aplicação.
Teste a resiliência do sistema quanto a falhas. Seguem-se alguns cenários comuns de falha para teste:
- Encerrar as instâncias de VM.
- Recursos de pressão, tal como CPU e memória.
- Desligar/atrasar a rede.
- Falhar os processos.
- Expirar certificados.
- Simular falhas de hardware.
- Encerrar o serviço DNS nos controladores de domínio.
Avalie os tempos de recuperação e verifique se cumprem os requisitos comerciais. Teste também os modos de combinações de falhas.
Otimização de custos
A otimização de custos consiste em procurar formas de reduzir despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, consulte Visão geral do pilar de otimização de custos.
Use a Calculadora de Preços do Azure para estimar custos. Aqui estão algumas outras considerações.
Conjuntos de Dimensionamento de Máquinas Virtuais
Os Conjuntos de Dimensionamento de Máquina Virtual estão disponíveis em todos os tamanhos de VM do Windows. Você só é cobrado pelas VMs do Azure implantadas e por quaisquer recursos de infraestrutura subjacentes adicionados que sejam consumidos, como armazenamento e rede. Não há cobranças incrementais para o serviço Conjuntos de Dimensionamento de Máquina Virtual.
Para opções de preços de VMs únicas, consulte Preços de VMs do Windows.
SQL Server
Se você escolher o Azure SQL DBaas, poderá economizar custos porque não precisa configurar um Grupo de Disponibilidade Always On e máquinas de controlador de domínio. Há várias opções de implantação, desde um único banco de dados até a instância gerenciada ou pools elásticos. Para obter mais informações, consulte Preços do SQL do Azure.
Para opções de preços de VMs do SQL Server, consulte Preços de VMs do SQL.
Balanceadores de carga
Você será cobrado apenas pelo número de regras de balanceamento de carga e saída configuradas. As regras de NAT de entrada são gratuitas. Não há cobrança por hora para o Balanceador de Carga Padrão quando nenhuma regra está configurada.
Preços do Gestor de Tráfego
A faturação do Gestor de Tráfego é baseada no número de consultas de DNS recebidas, com um desconto para serviços que recebem mais de um bilião de consultas mensais. Você também é cobrado por cada ponto de extremidade monitorado.
Para obter mais informações, veja a secção de custos Well-Architected Framework do Microsoft Azure.
Preços de emparelhamento VNET
Uma implantação de alta disponibilidade que usa várias Regiões do Azure usará o VNET-Peering. Existem diferentes taxas para VNET-Peering dentro da mesma região e para Global VNET-Peering.
Para obter mais informações, consulte Preços de rede virtual.
DevOps
Use um único modelo do Azure Resource Manager para provisionar os recursos do Azure e suas dependências. Use o mesmo modelo para implantar os recursos em regiões primárias e secundárias. Inclua todos os recursos na mesma rede virtual para que fiquem isolados na mesma carga de trabalho básica. Ao incluir todos os recursos, você facilita a associação dos recursos específicos da carga de trabalho a uma equipe de DevOps, para que a equipe possa gerenciar de forma independente todos os aspetos desses recursos. Esse isolamento permite que a equipe e os serviços de DevOps realizem integração contínua e entrega contínua (CI/CD).
Além disso, você pode usar diferentes modelos do Azure Resource Manager e integrá-los aos Serviços de DevOps do Azure para provisionar ambientes diferentes em minutos, por exemplo, para replicar a produção, como cenários ou ambientes de teste de carga, somente quando necessário, economizando custos.
Considere utilizar o Azure Monitor para analisar e otimizar o desempenho da sua infraestrutura, monitorizar e diagnosticar problemas de rede sem iniciar sessão nas suas máquinas virtuais. O Application Insights é, na verdade, um dos componentes do Azure Monitor, que fornece métricas e logs avançados para verificar o estado de todo o cenário do Azure. O Azure Monitor irá ajudá-lo a acompanhar o estado da sua infraestrutura.
Certifique-se não apenas de monitorar seus elementos de computação que suportam o código do aplicativo, mas também sua plataforma de dados, em particular seus bancos de dados, uma vez que um baixo desempenho da camada de dados de um aplicativo pode ter sérias consequências.
Para testar o ambiente do Azure onde os aplicativos estão sendo executados, ele deve ser controlado por versão e implantado por meio dos mesmos mecanismos que o código do aplicativo, então ele pode ser testado e validado usando paradigmas de teste de DevOps também.
Para obter mais informações, consulte a seção Excelência Operacional em Microsoft Azure Well-Architected Framework.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Autor principal:
- Donnie Trumpower - Brasil | Arquiteto de Soluções Cloud Sênior
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
Recursos relacionados
A arquitetura a seguir usa algumas das mesmas tecnologias: