Este artigo descreve uma arquitetura que usa o Azure Machine Learning para prever as probabilidades de inadimplência e inadimplência dos solicitantes de empréstimo. As previsões do modelo baseiam-se no comportamento fiscal do requerente. O modelo usa um enorme conjunto de pontos de dados para classificar os candidatos e fornecer uma pontuação de elegibilidade para cada candidato.
Apache®, Spark e o logotipo flame são marcas registradas ou marcas comerciais da Apache Software Foundation nos Estados Unidos e/ou em outros países. Nenhum endosso da Apache Software Foundation está implícito no uso dessas marcas.
Arquitetura

Transfira um ficheiro do Visio desta arquitetura.
Fluxo de dados
O seguinte fluxo de dados corresponde ao diagrama anterior:
Armazenamento: os dados são armazenados em um banco de dados como um pool do Azure Synapse Analytics se estiver estruturado. Bancos de dados SQL mais antigos podem ser integrados ao sistema. Dados semiestruturados e não estruturados podem ser carregados em um data lake.
Ingestão e pré-processamento: os pipelines de processamento e o processamento ETL do Azure Synapse Analytics podem se conectar a dados armazenados no Azure ou em fontes de terceiros por meio de conectores internos. O Azure Synapse Analytics dá suporte a várias metodologias de análise que usam SQL, Spark, Azure Data Explorer e Power BI. Você também pode usar a orquestração existente do Azure Data Factory para os pipelines de dados.
Processamento: o Azure Machine Learning é usado para desenvolver e gerenciar os modelos de aprendizado de máquina.
Processamento inicial: Durante esta etapa, os dados brutos são processados para criar um conjunto de dados com curadoria que treinará um modelo de aprendizado de máquina. As operações típicas incluem formatação de tipo de dados, imputação de valores ausentes, engenharia de recursos, seleção de recursos e redução de dimensionalidade.
Formação: Durante a fase de formação, o Azure Machine Learning utiliza o conjunto de dados processado para treinar o modelo de risco de crédito e selecionar o melhor modelo.
Treinamento de modelo: você pode usar uma variedade de modelos de aprendizado de máquina, incluindo modelos clássicos de aprendizado de máquina e aprendizado profundo. Você pode usar o ajuste de hiperparâmetros para otimizar o desempenho do modelo.
Avaliação do modelo: o Azure Machine Learning avalia o desempenho de cada modelo treinado para que você possa selecionar o melhor para implantação.
Registro de modelo: você registra o modelo com melhor desempenho no Azure Machine Learning. Esta etapa disponibiliza o modelo para implantação.
c. IA responsável: A IA responsável é uma abordagem para desenvolver, avaliar e implantar sistemas de IA de forma segura, confiável e ética. Como esse modelo infere uma decisão de aprovação ou negação para uma solicitação de empréstimo, você precisa implementar os princípios da IA responsável.
As métricas de equidade avaliam o efeito do comportamento injusto e permitem estratégias de mitigação. Recursos e atributos sensíveis são identificados no conjunto de dados e em coortes (subconjuntos) dos dados. Para obter mais informações, consulte Desempenho e equidade do modelo.
A interpretabilidade é uma medida de quão bem você pode entender o comportamento de um modelo de aprendizado de máquina. Este componente da IA Responsável gera descrições compreensíveis por humanos das previsões do modelo. Para obter mais informações, consulte Interpretabilidade do modelo.
Implantação de aprendizado de máquina em tempo real: você precisa usar a inferência de modelo em tempo real quando a solicitação precisa ser revisada imediatamente para aprovação.
- Ponto de extremidade on-line de aprendizado de máquina gerenciado. Para pontuação em tempo real, você precisa escolher um destino de computação apropriado.
- Os pedidos de empréstimos online utilizam a pontuação em tempo real com base nos dados do formulário do candidato ou do pedido de empréstimo.
- A decisão e a entrada usada para a pontuação do modelo são armazenadas em armazenamento persistente e podem ser recuperadas para referência futura.
Implantação de aprendizado de máquina em lote: para processamento de empréstimos offline, o modelo está programado para ser acionado em intervalos regulares.
- Ponto de extremidade de lote gerenciado. A inferência em lote é agendada e o conjunto de dados de resultados é criado. As decisões baseiam-se na solvabilidade do requerente.
- O conjunto de resultados da pontuação do processamento em lote é persistido no banco de dados ou no data warehouse do Azure Synapse Analytics.
Interface com dados sobre a atividade do candidato: Os detalhes inseridos pelo candidato, o perfil de crédito interno e a decisão do modelo são todos preparados e armazenados em serviços de dados apropriados. Esses detalhes são usados no mecanismo de decisão para pontuações futuras, para que sejam documentados.
- Armazenamento: Todos os detalhes do processamento de crédito são retidos no armazenamento persistente.
- Interface do utilizador: A decisão de aprovação ou recusa é apresentada ao requerente.
Relatórios: Insights em tempo real sobre o número de aplicativos processados e aprovam ou negam resultados são continuamente apresentados aos gerentes e lideranças. Exemplos de relatórios incluem relatórios quase em tempo real de valores aprovados, a carteira de empréstimos criada e o desempenho do modelo.
Componentes
- O Armazenamento de Blobs do Azure fornece armazenamento de objetos escalável para dados não estruturados. Ele é otimizado para armazenar arquivos como arquivos binários, registros de atividades e arquivos que não aderem a um formato específico.
- O Armazenamento Azure Data Lake é a base de armazenamento para a criação de data lakes econômicos no Azure. Ele fornece armazenamento de blob com uma estrutura hierárquica de pastas e desempenho, gerenciamento e segurança aprimorados. Ele atende a vários petabytes de informações enquanto sustenta centenas de gigabits de taxa de transferência.
- O Azure Synapse Analytics é um serviço de análise que reúne o melhor das tecnologias SQL e Spark e uma experiência de usuário unificada para o Azure Synapse Data Explorer e pipelines. Ele se integra ao Power BI, Azure Cosmos DB e Azure Machine Learning. O serviço suporta modelos de recursos dedicados e sem servidor e a capacidade de alternar entre esses modelos.
- O Banco de Dados SQL do Azure é um banco de dados relacional sempre atualizado e totalmente gerenciado criado para a nuvem.
- O Azure Machine Learning é um serviço de nuvem para gerenciar ciclos de vida de projetos de aprendizado de máquina. Ele fornece um ambiente integrado para exploração de dados, criação e gerenciamento de modelos e implantação e suporta abordagens code-first e low-code/no-code para aprendizado de máquina.
- O Power BI é uma ferramenta de visualização que fornece integração fácil com recursos do Azure.
- O Serviço de Aplicativo do Azure permite que você crie e hospede aplicativos Web, back-ends móveis e APIs RESTful sem gerenciar a infraestrutura. As linguagens suportadas incluem .NET, .NET Core, Java, Ruby, Node.js, PHP e Python.
Alternativas
Você pode usar o Azure Databrickspara desenvolver, implantar e gerenciar modelos de aprendizado de máquina e cargas de trabalho de análise. O serviço fornece um ambiente unificado para o desenvolvimento de modelos.
Detalhes do cenário
As organizações do setor financeiro precisam prever o risco de crédito de indivíduos ou empresas que solicitam crédito. Esse modelo avalia as probabilidades de inadimplência e inadimplência dos solicitantes de empréstimos.
A previsão do risco de crédito envolve uma análise profunda do comportamento da população e a classificação da base de clientes em segmentos com base na responsabilidade fiscal. Outras variáveis incluem fatores de mercado e condições econômicas, que têm uma influência significativa nos resultados.
Desafios. Os dados de entrada incluem dezenas de milhões de perfis de clientes e dados sobre o comportamento de crédito e hábitos de consumo do cliente, baseados em bilhões de registros de sistemas diferentes, como sistemas internos de atividade do cliente. Os dados de terceiros sobre as condições econômicas e a análise de mercado do país/região podem vir de instantâneos mensais ou trimestrais que exigem o carregamento e a manutenção de centenas de GB de arquivos. São necessárias informações do birô de crédito sobre o candidato ou linhas semiestruturadas de dados do cliente e cruzamentos entre esses conjuntos de dados e verificações de qualidade para validar a integridade dos dados.
Os dados geralmente consistem em tabelas de colunas amplas de informações de clientes de birôs de crédito, juntamente com análises de mercado. A atividade do cliente consiste em registros com layout dinâmico que podem não ser estruturados. Os dados também estão disponíveis em texto de forma livre nas notas de atendimento ao cliente e formulários de interação com o candidato.
O processamento desses grandes volumes de dados e a garantia de que os resultados estejam atualizados exigem um processamento simplificado. Você precisa de um processo de armazenamento e recuperação de baixa latência. A infraestrutura de dados deve ser dimensionada para suportar fontes de dados díspares e fornecer a capacidade de gerenciar e proteger o perímetro de dados. A plataforma de aprendizado de máquina precisa suportar a análise complexa dos muitos modelos que são treinados, testados e validados em muitos segmentos populacionais.
Sensibilidade e privacidade dos dados. O processamento de dados para este modelo envolve dados pessoais e detalhes demográficos. É preciso evitar o perfil das populações. A visibilidade direta de todos os dados pessoais deve ser limitada. Exemplos de dados pessoais incluem números de conta, detalhes de cartão de crédito, números de segurança social, nomes, endereços e códigos postais.
Os números de cartão de crédito e de conta bancária devem ser sempre ofuscados. Certos elementos de dados precisam ser mascarados e sempre criptografados, não fornecendo acesso às informações subjacentes, mas disponíveis para análise.
Os dados precisam ser criptografados em repouso, em trânsito e durante o processamento por meio de enclaves seguros. O acesso a itens de dados é registrado em uma solução de monitoramento. O sistema de produção precisa ser configurado com pipelines de CI/CD apropriados com aprovações que acionem implantações e processos de modelos. A auditoria dos logs e do fluxo de trabalho deve fornecer as interações com os dados para quaisquer necessidades de conformidade.
Em processamento. Este modelo requer alto poder computacional para análise, contextualização e treinamento e implantação de modelos. A pontuação do modelo é validada em relação a amostras aleatórias para garantir que as decisões de crédito não incluam qualquer viés de raça, gênero, etnia ou localização geográfica. O modelo de decisão precisa ser documentado e arquivado para referência futura. Todos os fatores envolvidos nos resultados da decisão são armazenados.
O processamento de dados requer alto uso da CPU. Inclui processamento SQL de dados estruturados em formato DB e JSON, processamento Spark dos quadros de dados ou análise de big data em terabytes de informações em vários formatos de documentos. Os trabalhos ELT/ETL de dados são programados ou acionados em intervalos regulares ou em tempo real, dependendo do valor dos dados mais recentes.
Conformidade e enquadramento regulamentar. Cada detalhe do processamento do empréstimo precisa ser documentado, incluindo o pedido enviado, os recursos usados na pontuação do modelo e o conjunto de resultados do modelo. As informações de treinamento de modelo, os dados usados para treinamento e os resultados do treinamento devem ser registrados para futuras solicitações de referência e auditoria e conformidade.
Lote versus pontuação em tempo real. Certas tarefas são proativas e podem ser processadas como trabalhos em lote, como transferências de saldo pré-aprovadas. Algumas solicitações, como aumentos de linhas de crédito online, exigem aprovação em tempo real.
O acesso em tempo real ao status dos pedidos de empréstimo on-line deve estar disponível para o candidato. A instituição financeira emissora de empréstimos monitora continuamente o desempenho do modelo de crédito e precisa de informações sobre métricas como status de aprovação de empréstimos, número de empréstimos aprovados, valores em dólares emitidos e a qualidade de novas originações de empréstimos.
IA responsável
O painel de IA Responsável fornece uma interface única para várias ferramentas que podem ajudá-lo a implementar a IA Responsável. O Padrão de IA Responsável baseia-se em seis princípios:
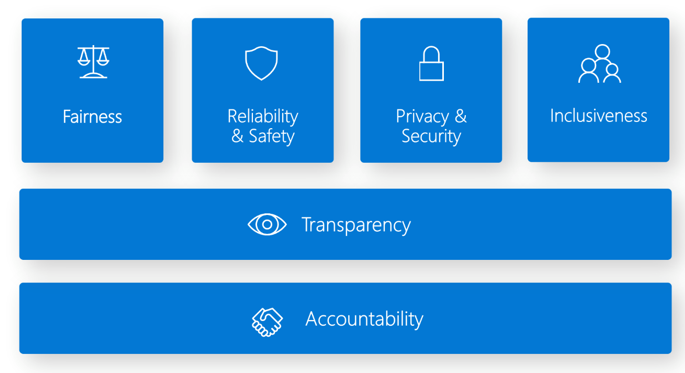
Equidade e inclusão no Azure Machine Learning. Este componente do painel de IA Responsável ajuda a avaliar comportamentos injustos, evitando danos de alocação e danos de qualidade de serviço. Você pode usá-lo para avaliar a equidade em grupos sensíveis definidos em termos de gênero, idade, etnia e outras características. Durante a avaliação, a equidade é quantificada através de métricas de disparidade. Você deve implementar os algoritmos de mitigação no pacote de código aberto Fairlearn , que usam restrições de paridade.
Fiabilidade e segurança no Azure Machine Learning. O componente de análise de erros da IA Responsável pode ajudá-lo a:
- Obtenha uma compreensão profunda de como a falha é distribuída para um modelo.
- Identificar coortes de dados com uma taxa de erro mais elevada do que o valor de referência geral.
Transparência no Azure Machine Learning. Uma parte crucial da transparência é entender como os recursos afetam o modelo de aprendizado de máquina.
- A interpretabilidade do modelo ajuda a entender o que influencia o comportamento do modelo. Gera descrições compreensíveis para o ser humano das previsões do modelo. Essa compreensão ajuda a garantir que você possa confiar no modelo e ajuda a depurá-lo e melhorá-lo. O InterpretML pode ajudá-lo a entender a estrutura dos modelos de caixa de vidro ou a relação entre os recursos em modelos de redes neurais profundas de caixa preta.
- Hipóteses contrafactuais podem ajudá-lo a entender e depurar um modelo de aprendizado de máquina em termos de como ele reage a alterações e perturbações de recursos.
Privacidade e segurança no Azure Machine Learning. Os administradores de aprendizado de máquina precisam criar uma configuração segura para desenvolver e gerenciar a implantação de modelos. Os recursos de segurança e governança podem ajudá-lo a cumprir as políticas de segurança da sua organização. Outras ferramentas podem ajudá-lo a avaliar e proteger seus modelos.
Responsabilidade no Azure Machine Learning. As operações de aprendizado de máquina (MLOps) são baseadas em princípios e práticas de DevOps que aumentam a eficiência dos fluxos de trabalho de IA. O Azure Machine Learning pode ajudá-lo a implementar recursos de MLOps:
- Registrar, empacotar e implantar modelos
- Receba notificações e alertas sobre alterações em modelos
- Capture dados de governança para o ciclo de vida de ponta a ponta
- Monitorar aplicativos em busca de problemas operacionais
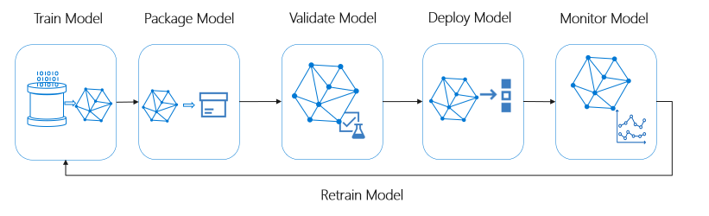
Este diagrama ilustra os recursos de MLOps do Azure Machine Learning:
Potenciais casos de utilização
Você pode aplicar essa solução aos seguintes cenários:
- Finanças: Obtenha análise financeira de clientes ou análise de vendas cruzadas de clientes para campanhas de marketing direcionadas.
- Cuidados de saúde: Use as informações do paciente como entrada para sugerir ofertas de tratamento.
- Hospitalidade: crie um perfil de cliente para sugerir ofertas de hotéis, voos, pacotes de cruzeiros e associações.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios orientadores que você pode usar para melhorar a qualidade de uma carga de trabalho. Para obter mais informações, consulte Microsoft Azure Well-Architected Framework.
Segurança
A segurança oferece garantias contra ataques deliberados e o abuso de seus valiosos dados e sistemas. Para obter mais informações, consulte Visão geral do pilar de segurança.
As soluções do Azure fornecem defesa em profundidade e uma abordagem Zero Trust.
Considere implementar os seguintes recursos de segurança nessa arquitetura:
- Implantar serviços dedicados do Azure em redes virtuais
- Recursos de segurança do Banco de Dados SQL do Azure
- Proteja as credenciais no data factory usando o Cofre da Chave
- Segurança e governação empresariais para o Azure Machine Learning
- Linha de base de segurança do Azure para o Synapse Analytics Workspace
Otimização de custos
A otimização de custos consiste em reduzir despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, consulte Visão geral do pilar de otimização de custos.
Para estimar o custo de implementação dessa solução, use a calculadora de preços do Azure.
Considere também estes recursos:
- Planear e gerir os custos do Azure Synapse Analytics
- Planejar e gerenciar custos para o Azure Machine Learning
Excelência operacional
A excelência operacional abrange os processos operacionais que implantam um aplicativo e o mantêm em execução na produção. Para obter mais informações, consulte Visão geral do pilar de excelência operacional.
As soluções de aprendizado de máquina precisam ser escaláveis e padronizadas para facilitar o gerenciamento e a manutenção. Certifique-se de que sua solução ofereça suporte à inferência contínua com ciclos de retreinamento e reimplantações automatizadas de modelos.
Para obter mais informações, consulte Azure MLOps (v2) solution accelerator.
Eficiência de desempenho
Eficiência de desempenho é a capacidade da sua carga de trabalho para dimensionar para satisfazer as exigências que os utilizadores lhe colocam de forma eficiente. Para obter mais informações, consulte Visão geral do pilar de eficiência de desempenho.
- Para obter mais informações sobre como projetar soluções escaláveis, consulte Lista de verificação de eficiência de desempenho.
- Para obter informações sobre setores regulamentados, consulte Dimensionar iniciativas de IA e aprendizado de máquina em setores regulamentados.
- Gerencie seu ambiente do Azure Synapse Analytics com SQL, Spark ou pools SQL sem servidor.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Autor principal:
- Charitha Basani - Brasil | Arquiteto de Soluções Cloud Sênior
Outros contribuidores:
- Mick Alberts - Brasil | Redator Técnico
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
- Linha de base de segurança do Azure Machine Learning
- Azure Synapse Analytics
- Implantar modelos de aprendizado de máquina no Azure
- O que é IA responsável?