A inteligência artificial (IA) e o aprendizado de máquina (ML) oferecem oportunidades e desafios únicos para operações que abrangem os mundos virtual e físico. A IA e o ML podem reconhecer correlações entre dados de entrada e resultados do mundo real e tomar decisões que automatizam sistemas industriais físicos complexos. Mas os sistemas de aprendizado de máquina de IA não podem executar funções cognitivas de alto nível, como exploração, improvisação, pensamento criativo ou determinação de causalidade.
O ensino de máquina é um novo paradigma para sistemas de aprendizagem automática que:
- Infunde experiência no assunto em modelos automatizados de sistemas de IA.
- Utiliza a aprendizagem por reforço profundo para identificar padrões no processo de aprendizagem e adotar comportamentos positivos nos seus próprios métodos.
- Aproveita ambientes simulados para gerar grandes quantidades de dados sintéticos para casos de uso e cenários específicos do domínio.
A aprendizagem automática centra-se no desenvolvimento de novos algoritmos de aprendizagem ou na melhoria dos algoritmos existentes. O ensino de máquinas centra-se na eficácia dos próprios professores. Abstrair a complexidade da IA para se concentrar na experiência no assunto e nas condições do mundo real cria modelos poderosos de IA e ML que transformam sistemas de controle automatizados em sistemas autônomos.
Este artigo discute desenvolvimentos históricos de IA e conceitos usados no ensino de máquinas. Um artigo relacionado discute os sistemas autônomos em detalhes.
História da automação
Os seres humanos projetam ferramentas físicas e máquinas para executar tarefas de forma mais eficiente há milhares de anos. Estas tecnologias visam alcançar resultados de forma mais consistente, a um custo mais baixo e com menos trabalho manual direto.
A Primeira Revolução Industrial, do final de 1700 a meados de 1800, introduziu máquinas para substituir os métodos de produção manual na fabricação. A Revolução Industrial aumentou a eficiência da produção através da automação com energia a vapor e através da consolidação, transferindo a produção de casas para fábricas organizadas. A Segunda Revolução Industrial, de meados de 1800 ao início de 1900, avançou a capacidade de produção através da eletrificação e linhas de produção.
As I e II Guerras Mundiais trouxeram grandes avanços na teoria da informação, comunicações e processamento de sinais. O desenvolvimento do transistor permitiu que a teoria da informação fosse facilmente aplicada ao controle de sistemas físicos. Esta Terceira Revolução Industrial permitiu que os sistemas computacionais fizessem incursões no controle codificado de sistemas físicos como produção, transporte e saúde. Os benefícios da automação programada incluíam consistência, confiabilidade e segurança.
A Quarta Revolução Industrial introduziu a noção de sistemas ciber-físicos e a Internet das Coisas (IoT) industrial. Os sistemas que os seres humanos desejam controlar tornaram-se demasiado grandes e complexos para escrever regras totalmente prescritas. A inteligência artificial permite que máquinas inteligentes executem tarefas que normalmente exigiam inteligência humana. O aprendizado de máquina permite que as máquinas aprendam e melhorem automaticamente a partir da experiência sem serem explicitamente programadas.
IA e ML
IA e ML não são conceitos novos, e muitas das teorias permanecem inalteradas há décadas, mas os recentes avanços tecnológicos em armazenamento, largura de banda e computação permitem previsões de algoritmos mais precisas e úteis. O aumento da capacidade de processamento de dispositivos, miniaturização, capacidade de armazenamento e capacidade de rede permitem uma maior automação de sistemas e equipamentos. Esses avanços também permitem a coleta e o agrupamento de grandes quantidades de dados de sensores em tempo real.
A automação cognitiva é a aplicação de software e IA a processos e sistemas intensivos em informação. A IA cognitiva pode aumentar os trabalhadores manuais para aumentar a produtividade, substituir os trabalhadores humanos em campos monótonos ou perigosos e permitir novas perceções devido aos enormes volumes de dados que pode processar. Tecnologias cognitivas como visão computacional, processamento de linguagem natural, chatbots e robótica podem executar tarefas que antes apenas os humanos podiam fazer.
Muitos sistemas de produção atuais automatizam e realizam feitos impressionantes de engenharia e fabricação usando robôs industriais. A utilização e evolução da automação industrial nas indústrias transformadoras produz produtos de maior qualidade, mais seguros e com uma utilização mais eficiente da energia e das matérias-primas. No entanto, na maioria dos casos, os robôs só podem operar em ambientes altamente estruturados. Eles são tipicamente inflexíveis para mudar e altamente especializados para tarefas imediatas. O desenvolvimento de robôs também pode ser caro devido às regras de hardware e software que regem seus comportamentos.
O paradoxo da automação afirma que quanto mais eficiente um sistema automatizado se torna, mais crucial é o componente humano para as operações. O papel dos seres humanos muda de trabalho mundano por unidade de trabalho para melhorar e gerenciar o sistema automatizado e contribuir com conhecimentos essenciais de domínio. Embora um sistema automatizado possa produzir resultados de forma mais eficiente, ele também pode criar desperdícios e problemas se for mal projetado ou estiver funcionando incorretamente. O uso eficiente da automação torna os seres humanos mais importantes, não menos.
Casos de uso de IA
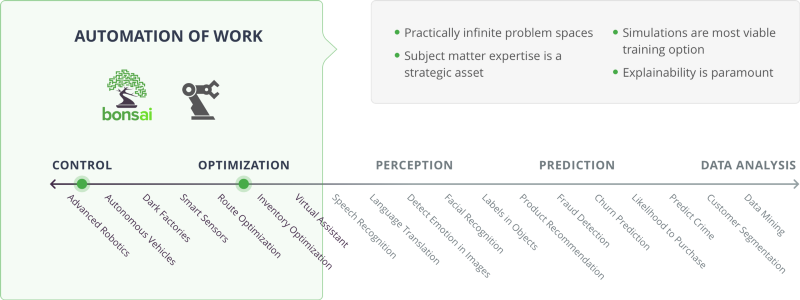
No diagrama anterior, as categorias Controlo e Otimização relacionam-se com a automatização do trabalho. Deste lado do espectro da IA, existem espaços de problemas praticamente infinitos. A especialização no assunto é um ativo estratégico, as simulações são a opção de treinamento mais factível e a explicabilidade é fundamental.
Os orquestradores incluem a fabricação inteligente e a plataforma de ensino de máquinas Bonsai. Os casos de uso incluem robótica avançada, veículos autônomos, fábricas escuras, sensores inteligentes, otimização de rotas, otimização de inventário e assistentes virtuais.
Aprendizagem por reforço
O ensino de máquinas depende da aprendizagem por reforço (RL) para treinar modelos, identificar padrões no processo de aprendizagem e adotar comportamentos positivos em seus próprios métodos. A aprendizagem por reforço profundo (DRL) aplica a aprendizagem por reforço a redes neuronais complexas de aprendizagem profunda.
RL em aprendizado de máquina diz respeito a como os agentes de software aprendem a maximizar recompensas e resultados desejados em seus ambientes. RL é um dos três paradigmas básicos de aprendizado de máquina:
- A aprendizagem supervisionada generaliza a partir de dados marcados ou estruturados.
- A aprendizagem não supervisionada comprime dados não rotulados ou não estruturados.
- A aprendizagem por reforço atua através de tentativa e erro.
Enquanto a aprendizagem supervisionada é aprender pelo exemplo, a aprendizagem por reforço é aprender com a experiência. Ao contrário da aprendizagem supervisionada, que se concentra em encontrar e rotular conjuntos de dados adequados, a RL concentra-se em projetar modelos de como executar tarefas.
Os principais componentes RL são:
- Agente: a entidade que pode tomar a decisão de alterar o ambiente atual.
- Ambiente: o mundo físico ou simulado em que o agente opera.
- Estado: a situação atual do agente e seu ambiente.
- Ação: uma interação do agente em seu ambiente.
- Recompensa: o feedback do ambiente, decorrente de uma ação do agente.
- Política: o método ou função para mapear o estado atual do agente e seu ambiente para ações.
A RL usa funções e políticas de recompensa para avaliar as ações dos agentes e fornecer feedback. Através da tomada de decisão sequencial com base no ambiente atual, os agentes aprendem a maximizar a recompensa ao longo do tempo e a prever as melhores ações possíveis em situações específicas.
RL ensina o agente a completar um objetivo, recompensando o comportamento desejado e não recompensando o comportamento indesejado. O diagrama a seguir ilustra o fluxo conceitual de RL e como os principais componentes interagem:
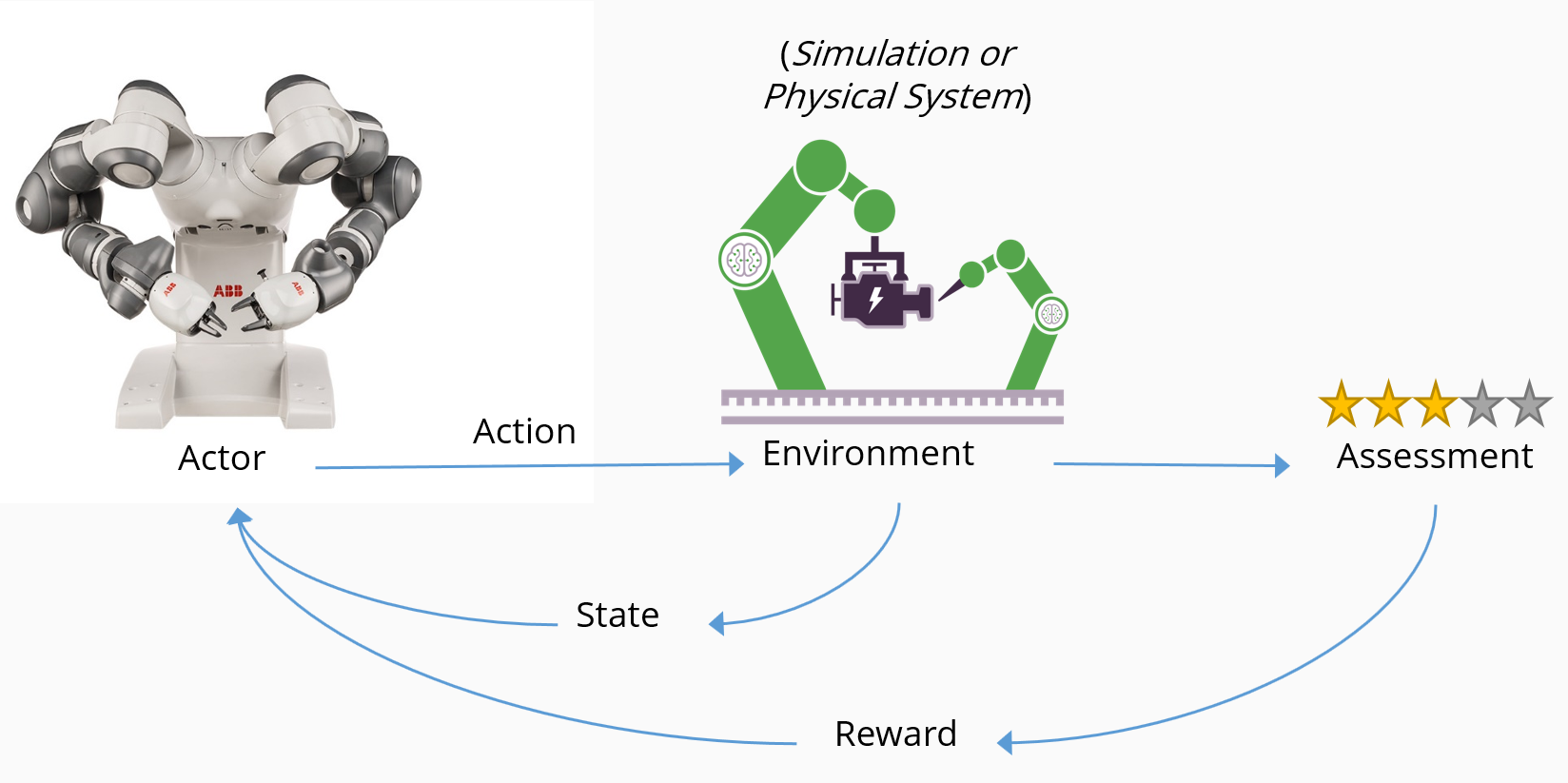
- Um agente, neste caso um robô, toma uma ação num ambiente, neste caso uma linha de produção inteligente.
- A ação faz com que o ambiente mude de estado e retorne seu estado alterado para o agente.
- Um mecanismo de avaliação aplica uma política para determinar qual consequência entregar ao agente.
- O mecanismo de recompensa incentiva ações benéficas ao entregar uma recompensa positiva e pode desencorajar ações negativas ao aplicar uma penalidade.
- As recompensas fazem com que as ações desejadas aumentem, enquanto as penalidades fazem com que as ações indesejadas diminuam.
Um problema pode ser estocástico (aleatório) por natureza, ou determinístico. Embora um agente seja mais comum, também pode haver vários agentes no ambiente. O agente sente o ambiente pela observação. O ambiente pode ser total ou parcialmente observável, conforme determinado pelos sensores do agente, e as observações podem ser discretas ou contínuas.
Cada observação é seguida por uma ação, que faz com que o ambiente mude. Este ciclo repete-se até ser atingido um estado terminal. Normalmente, o sistema não tem memória, e o algoritmo simplesmente se preocupa com o estado de origem, o estado em que chega e a recompensa que recebe.
À medida que o agente aprende por tentativa e erro, ele precisa de grandes quantidades de dados para avaliar suas ações. RL é mais aplicável a domínios que têm grandes corpos históricos de dados, ou que podem facilmente produzir dados simulados.
Funções de recompensa
Uma função de recompensa determina quanto e quando recompensar uma determinada ação. A estrutura de recompensa é normalmente deixada ao proprietário do sistema para definir. Ajustar este parâmetro pode afetar significativamente os resultados.
O agente usa a função de recompensa para aprender sobre a física e a dinâmica do mundo ao seu redor. O processo fundamental pelo qual um agente aprende a maximizar sua recompensa, pelo menos inicialmente, é a tentativa e erro.
Compromisso entre exploração e exploração
Dependendo do objetivo e da função de recompensa, o agente deve equilibrar a exploração versus a maximização de sua recompensa. Essa escolha é chamada de trade-off de exploração versus exploração. Tal como acontece com muitos aspetos do mundo real, o agente deve equilibrar os méritos de uma maior exploração do ambiente, o que pode levar a melhores decisões no futuro, com a exploração do ambiente, usando todo o conhecimento que o agente tem atualmente sobre o mundo para maximizar a recompensa. Tomar diferentes ações pode oferecer uma nova perspetiva, especialmente se as ações não tiverem sido tentadas antes.
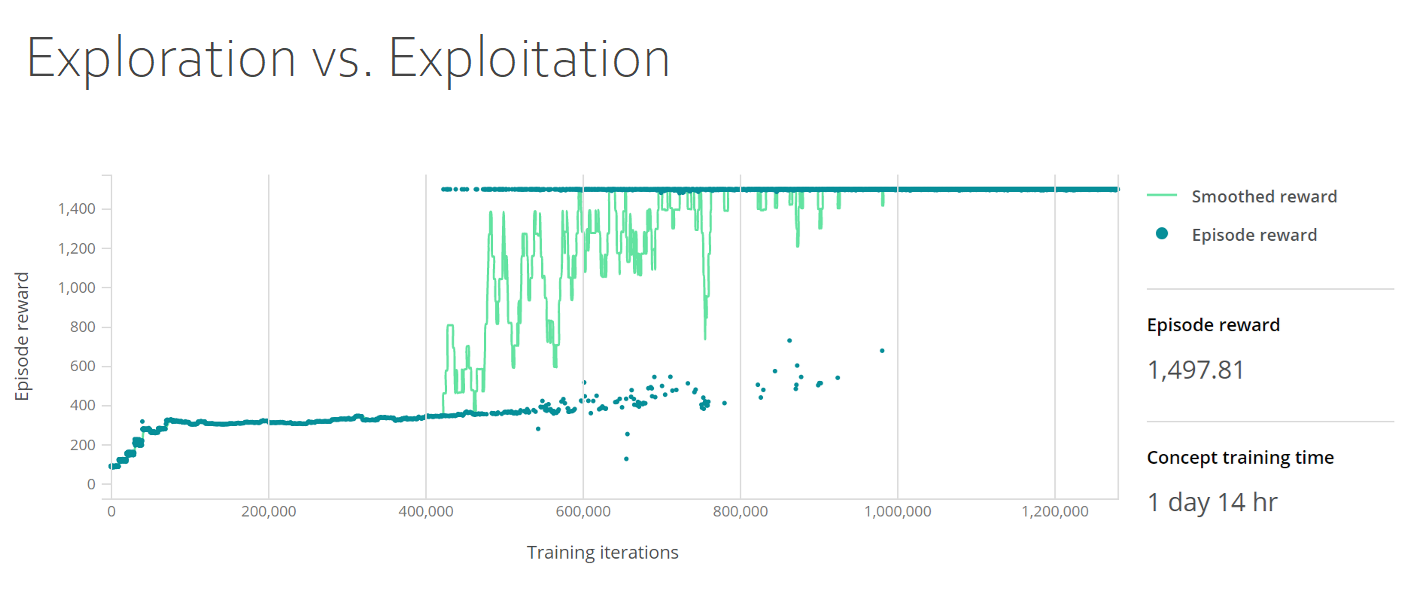
O painel de treinamento a seguir mostra a troca exploração versus exploração. O gráfico mostra as recompensas suavizadas e as recompensas do episódio, com as recompensas do episódio no eixo y e as iterações de treinamento no eixo x. A densidade de recompensa do episódio sobe para 400 nas primeiras 50.000 iterações, depois se mantém estável até 400.000 iterações, quando sobe para 1.500 e permanece estável.
Efeito cobra
As recompensas estão sujeitas ao que é conhecido em economia como o efeito cobra. Durante o domínio britânico da Índia colonial, o governo decidiu abater a grande população de cobras selvagens, oferecendo uma recompensa por cada cobra morta. Inicialmente, esta política foi bem-sucedida, pois um grande número de cobras foram mortas para reivindicar a recompensa. No entanto, não demorou muito para as pessoas começarem a jogar o sistema e criar cobras deliberadamente para coletar a recompensa. Eventualmente, as autoridades notaram esse comportamento e cancelaram o programa. Sem nenhum incentivo adicional, os criadores de cobras libertaram suas cobras, com o resultado de que a população de cobras selvagens realmente aumentou em comparação com o que era no início do incentivo.
O incentivo bem-intencionado piorou a situação, não melhorou. O aprendizado com isso é que os agentes aprendem o comportamento que você incentiva, o que pode não produzir o resultado pretendido.
Recompensas moldadas
Criar uma função de recompensa com uma forma específica pode permitir que o agente aprenda uma política apropriada com mais facilidade e rapidez.
Uma função step é um exemplo de uma função de recompensa esparsa que não diz muito ao agente sobre o quão boa foi a sua ação. Na função de recompensa do passo seguinte, apenas uma ação de distância entre 0,0 e 0,1 gera uma recompensa total de 1,0. Quando a distância é superior a 0,1, não há recompensa.

Em contraste, uma função de recompensa em forma dá ao agente um sinal de quão próxima a ação está da resposta desejada. A seguinte função de recompensa em forma dá uma recompensa maior, dependendo de quão próxima a resposta está da ação 0.0 desejada. A curva da função é uma hipérbole. A recompensa é de 1,0 para a distância 0,0 e gradualmente cai para 0,0 à medida que a distância se aproxima de 1,0.
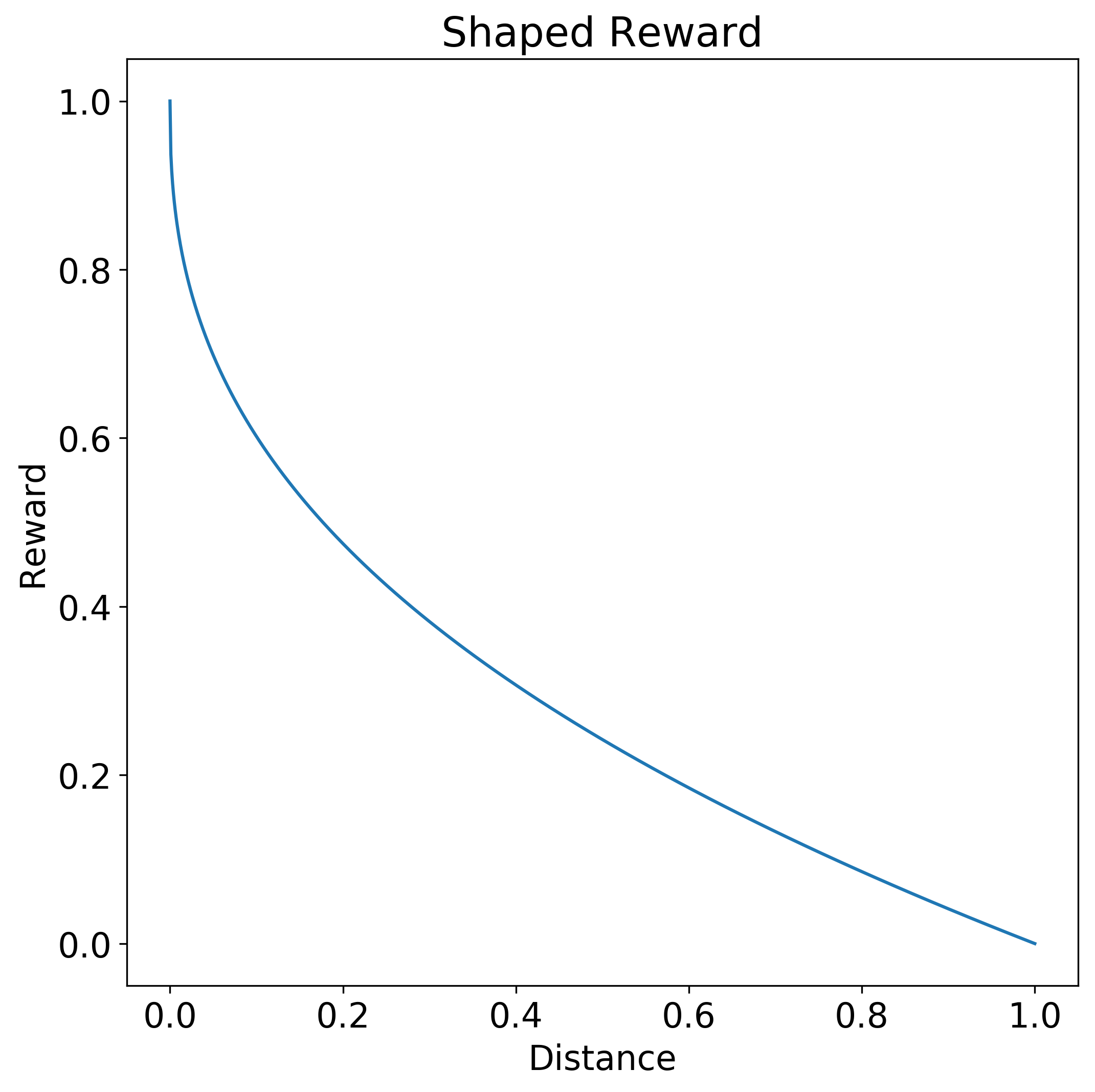
A modelagem pode descontar o valor de uma recompensa futura versus uma recompensa mais imediata, ou incentivar a exploração, reduzindo o tamanho das recompensas em torno do objetivo.
Às vezes, uma função de recompensa pode especificar considerações temporais e espaciais, para encorajar sequências ordenadas de ações. No entanto, se uma função de recompensa moldada está se tornando grande e complexa, considere dividir o problema em estágios menores e usar redes conceituais.
Redes conceptuais
As redes de conceito permitem especificar e reutilizar conhecimentos específicos do domínio e experiência no assunto para coletar uma ordem desejada de comportamento em uma sequência específica de tarefas separadas. As redes de conceito ajudam a restringir o espaço de pesquisa dentro do qual o agente pode operar e tomar ações.
Na seguinte rede de conceito para agarrar e empilhar objetos, a caixa Grasp e Stack' é o pai de duas caixas cinza, Reach e Move, e três caixas verdes, Orient, Grasp e Stack.
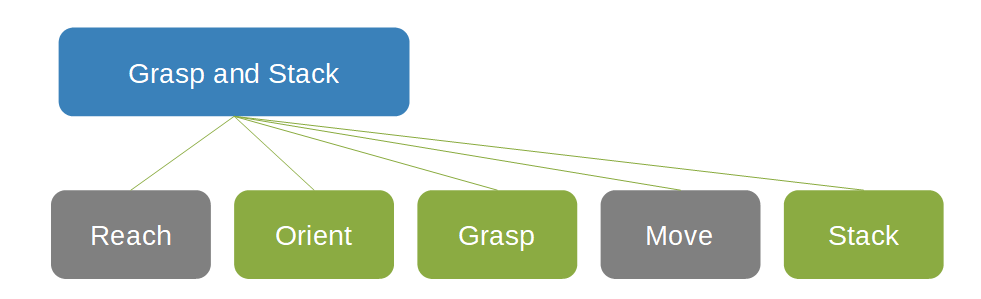
As redes conceptuais permitem muitas vezes que as funções de recompensa sejam mais facilmente definidas. Cada conceito pode usar a abordagem mais apropriada para essa tarefa. A noção de redes conceituais ajuda na decomposição da solução em partes constituintes. Os componentes podem ser substituídos sem retreinamento de todo o sistema, permitindo a reutilização de modelos pré-treinados e o uso de controladores existentes ou outros componentes do ecossistema existentes. Especialmente em sistemas de controle industrial, a melhoria incremental fragmentada pode ser mais desejável do que a remoção e substituição completas.
Aprendizagem curricular e aprendizagem aprendizagem
Dividir o problema em tarefas sequenciais separadas com redes conceituais permite dividir o problema em estágios de dificuldade e apresentá-lo ao agente como um currículo de dificuldade crescente. Esta abordagem faseada começa com um problema simples, permite que o agente pratique, depois desafia-o cada vez mais à medida que a sua capacidade aumenta. A função de recompensa muda e evolui à medida que o agente se torna mais capaz em sua tarefa. Esta abordagem de aprendizagem curricular ajuda a orientar a exploração e reduz drasticamente o tempo de treinamento necessário.
Você também pode restringir o espaço de pesquisa de política para o agente, instruindo-o a aprender imitando o comportamento de um especialista externo. A aprendizagem por aprendizagem usa exemplos orientados por especialistas para restringir o espaço estatal que o agente explora. A aprendizagem por aprendizagem compensa a aprendizagem de soluções conhecidas mais rapidamente em detrimento da não descoberta de soluções inovadoras.
Um exemplo de aprendizagem é ensinar um agente de carro autônomo a imitar as ações de um motorista humano. O agente aprende a dirigir, mas também herda quaisquer falhas e idiossincrasias do professor.
Projeto de sistemas de IA baseados em RL
A estratégia a seguir é um guia prático para construir e construir sistemas de IA baseados em RL:
- Formular e iterar sobre estados, condições terminais, ações e recompensas.
- Crie funções de recompensa, moldando-as conforme necessário.
- Aloque recompensas para subobjetivos específicos.
- Desconte recompensas agressivamente, se necessário.
- Experimente com estados iniciais.
- Experimente uma amostra de exemplos para treinamento.
- Limitar a variação dos parâmetros da dinâmica de simulação durante o treino.
- Generalize durante a previsão e mantenha o treinamento o mais suave possível.
- Introduza algum ruído fisicamente relevante para acomodar o ruído em máquinas reais.
Simulações
Os sistemas de IA são ávidos por dados e exigem exposição a muitos cenários para garantir que sejam treinados para tomar decisões apropriadas. Os sistemas geralmente exigem protótipos caros que correm o risco de danos em ambientes do mundo real. O custo de coletar e rotular manualmente dados de treinamento de alta fidelidade é alto, tanto em termos de tempo quanto de mão de obra direta. O uso de simuladores e dados de treinamento densamente rotulados gerados por simuladores é um meio poderoso de resolver grande parte desse déficit de dados.
A maldição da dimensionalidade refere-se aos fenômenos que surgem quando se lida com grandes quantidades de dados em espaços de alta dimensão. Modelar com precisão certos cenários e conjuntos de problemas requer o uso de redes neurais profundas. Essas redes em si são altamente dimensionais, com muitos parâmetros que precisam ser ajustados. À medida que a dimensionalidade aumenta, o volume do espaço aumenta a uma taxa tal que os dados disponíveis do mundo real se tornam escassos, tornando difícil coletar dados suficientes para fazer correlações estatisticamente significativas. Sem dados suficientes, o treinamento resulta em um modelo que se ajusta aos dados e não generaliza bem para novos dados, o que derrota o propósito de um modelo.
O problema tem duas vertentes:
- O algoritmo de treinamento tem uma grande capacidade de aprendizado para modelar com precisão o problema, mas precisa de mais dados para evitar o underfitting.
- Coletar e rotular essa grande quantidade de dados, se possível, é difícil, caro e propenso a erros.
As simulações oferecem uma alternativa à necessidade de coletar grandes quantidades de dados de treinamento do mundo real, modelando virtualmente os sistemas em seus ambientes físicos pretendidos. As simulações permitem treinar em ambientes perigosos, ou em condições difíceis de reproduzir no mundo real, como vários tipos de condições meteorológicas. Dados simulados artificialmente evitam a dificuldade na coleta de dados e mantêm os algoritmos adequadamente alimentados com cenários de exemplo que lhes permitem generalizar com precisão para o mundo real.
As simulações são a fonte de treino ideal para DRL, porque são:
- Flexível para ambientes personalizados.
- Seguro e económico para a geração de dados.
- Paralelizável, permitindo tempos de treino mais rápidos.
As simulações estão disponíveis em uma ampla gama de indústrias e sistemas, incluindo engenharia mecânica e elétrica, veículos autônomos, segurança e redes, transporte e logística e robótica.
As ferramentas de simulação incluem:
- Simulink, uma ferramenta de programação gráfica desenvolvida pela MathWorks para modelar, simular e analisar sistemas dinâmicos.
- Gazebo, uma ferramenta para permitir a simulação precisa de populações de robôs em ambientes internos e externos complexos.
- Microsoft AirSim, uma plataforma de simulação robótica de código aberto.
Paradigma do ensino de máquinas
O ensino de máquinas oferece um novo paradigma para a construção de sistemas de ML que desvia o foco dos algoritmos para a geração e implantação bem-sucedida de modelos. O ensino de máquina identifica padrões no próprio processo de aprendizagem e adota comportamentos positivos em seu próprio método. Grande parte da atividade em aprendizado de máquina está focada em melhorar algoritmos existentes ou desenvolver novos algoritmos de aprendizagem. Em contrapartida, o ensino de máquinas centra-se na eficácia dos próprios professores.
Ensino de máquinas:
- Combina experiência no assunto de especialistas em domínio humano com IA e ML.
- Automatiza a geração e gestão de algoritmos e modelos de aprendizagem por reforço profundo.
- Integra simulações para otimização e escalabilidade do modelo.
- Proporciona uma maior explicabilidade do comportamento dos modelos resultantes.
O estado do aprendizado de máquina foi amplamente determinado por alguns especialistas em algoritmos. Esses especialistas têm um profundo conhecimento de ML e podem alterar um algoritmo ou arquitetura de ML para atender às métricas de desempenho ou precisão necessárias. O número de especialistas em ML globalmente pode ser estimado em dezenas de milhares, o que retarda a adoção de soluções de ML. A complexidade arrogante dos modelos coloca os recursos de ML fora do alcance de muitos.
Enquanto os especialistas em ML são poucos, os especialistas no assunto são abundantes. Globalmente, existem dezenas de milhões de especialistas em domínios. O ensino de máquinas explora esse grupo maior de especialistas que entendem a semântica dos problemas e podem fornecer exemplos, mas não precisam estar cientes dos meandros do ML. O ensino de máquina é a abstração fundamental necessária para programar eficientemente a experiência no assunto, codificando o que ensinar e como ensiná-lo. Especialistas no assunto sem experiência em IA podem dividir seus conhecimentos em etapas e tarefas, critérios e resultados desejados.
Para os engenheiros, o ensino de máquina eleva o nível da abstração além da seleção de algoritmos de IA e ajustes de hiperparâmetros para se concentrar em problemas de domínio de aplicativos mais valiosos. Os engenheiros que constroem sistemas autônomos podem criar modelos precisos e detalhados de sistemas e ambientes, e torná-los inteligentes usando métodos como deep learning, aprendizagem por imitação e aprendizagem por reforço. Outro resultado bem-vindo do ensino de máquina é um tempo mais rápido para a implantação do modelo, reduzindo ou eliminando a necessidade de intervenção manual de especialistas em aprendizado de máquina durante o desenvolvimento.
O ensino de máquinas simplifica o processo de construção de soluções de ML, analisando práticas comuns de ML e adotando estratégias benéficas em seus próprios métodos. Com instruções e configuração do desenvolvedor, o Bonsai, o serviço de ensino de máquina na Microsoft Autonomous Systems Platform, pode automatizar o desenvolvimento de modelos de IA em um sistema de IA.
O Bonsai fornece um painel central facilmente compreensível que rastreia o estado atual de cada projeto com ferramentas de controle de versão. O uso dessa infraestrutura de ensino de máquina garante que os resultados do modelo possam ser reproduzidos e permite que os desenvolvedores atualizem facilmente os sistemas de IA com futuros avanços algorítmicos de IA.
Uma mudança de perspetiva para uma metodologia de ensino de máquina promove a adoção de ML com um processo mais simplificado e acessível para gerar e implantar modelos de ML. O ensino de máquinas oferece uma maneira para os especialistas do domínio aplicarem o poder da DRL como uma ferramenta. O ensino de máquinas move a tecnologia da IA de um foco em algoritmos e técnicas de ML para a aplicação desses algoritmos por especialistas de domínio a problemas do mundo real.
Processo de ensino de máquinas
O desenvolvimento e a implantação do ensino de máquinas têm três fases: Compilar, Treinar e Implantar.
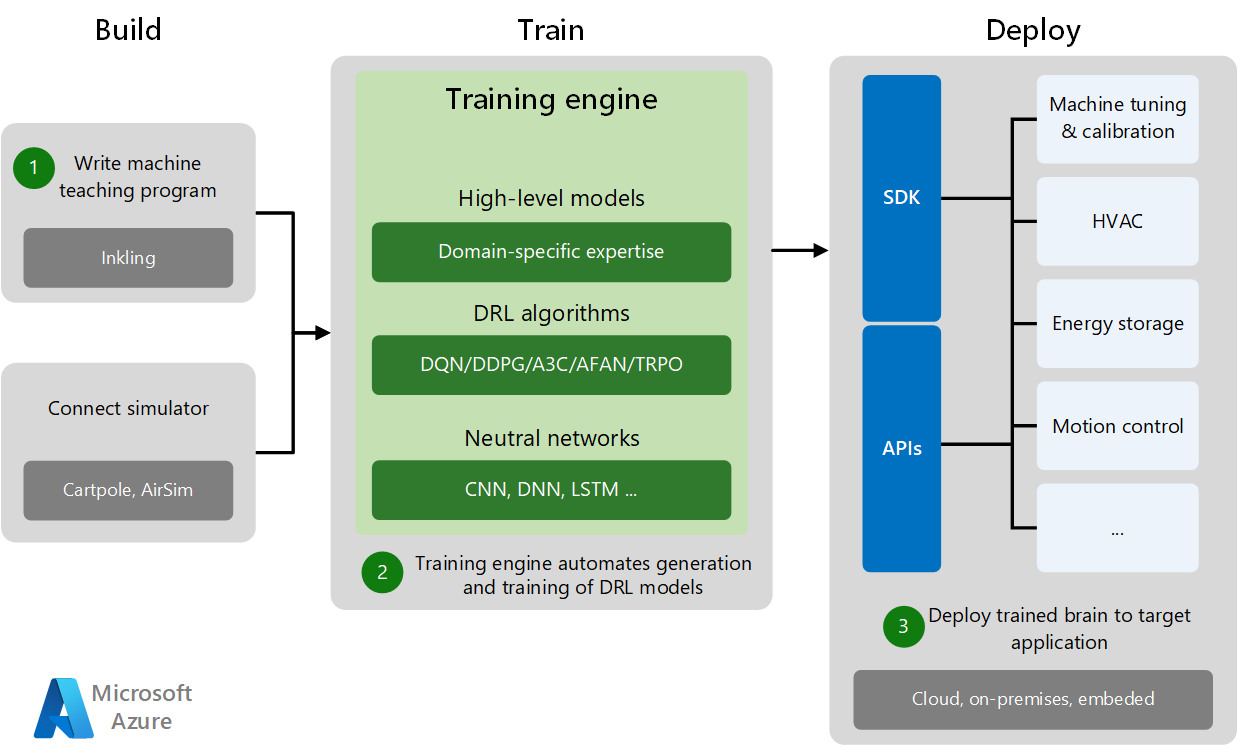
- A fase Build consiste em escrever o programa de ensino de máquina e conectar-se a um simulador de treinamento específico do domínio. Os simuladores geram dados de treinamento suficientes para experimentos e prática de máquinas.
- Na fase Train, o mecanismo de treinamento automatiza a geração e o treinamento de modelos DRL combinando modelos de domínio de alto nível com algoritmos DRL apropriados e redes neurais.
- A fase Implantação implanta o modelo treinado no aplicativo de destino na nuvem, no local ou incorporado no local. SDKs específicos e APIs de implantação implantam sistemas de IA treinados para vários aplicativos de destino, executam o ajuste da máquina e controlam os sistemas físicos.
Os ambientes simulados geram grandes quantidades de dados sintéticos abrangendo muitos casos de uso e cenários. As simulações fornecem geração de dados segura e econômica para treinamento de algoritmos de modelo e tempos de treinamento mais rápidos com paralelização de simulação. As simulações ajudam a treinar os modelos em diferentes tipos de condições ambientais e cenários, muito mais rápido e seguro do que é viável no mundo real.
Os especialistas no assunto podem supervisionar os agentes enquanto eles trabalham para resolver problemas em ambientes simulados e fornecer feedback e orientação que permitem que os agentes se adaptem dinamicamente dentro da simulação. Após a conclusão do treinamento, os engenheiros implantam os agentes treinados em hardware real, onde podem usar seu conhecimento para alimentar sistemas autônomos no mundo real.
Aprendizagem automática e ensino de máquina
O ensino e o aprendizado de máquina são complementares e podem evoluir de forma independente. A pesquisa de aprendizado de máquina se concentra em tornar o aluno melhor, melhorando os algoritmos de aprendizado de máquina. A pesquisa de ensino de máquina se concentra em tornar o professor mais produtivo na construção dos modelos de aprendizado de máquina. As soluções de ensino de máquina requerem vários algoritmos de aprendizagem automática para produzir e testar modelos ao longo do processo de ensino.
O diagrama a seguir mostra um pipeline representativo para a criação de um modelo de aprendizado de máquina:
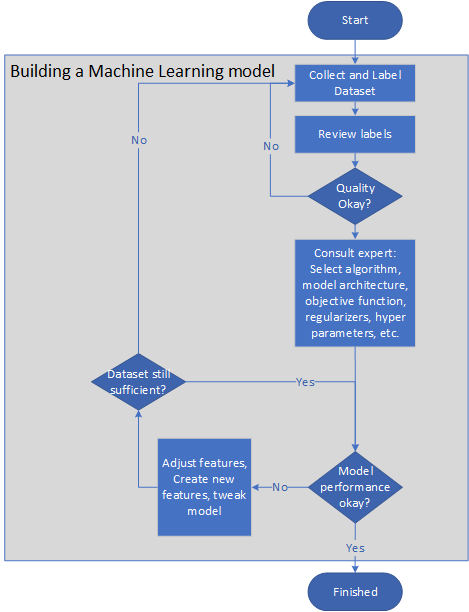
- O proprietário do problema coleta e rotula conjuntos de dados ou monta uma diretriz de rótulo para que a tarefa de rotulagem possa ser terceirizada.
- O proprietário do problema revê os rótulos até que a sua qualidade seja satisfatória.
- Os especialistas em aprendizado de máquina selecionam um algoritmo, arquitetura de modelo, função objetiva, regularizadores e conjuntos de validação cruzada.
- Os engenheiros treinam o modelo ciclicamente, ajustando os recursos ou criando novos recursos para melhorar a precisão e a velocidade do modelo.
- O modelo é testado numa pequena amostra. Se o sistema não se sair bem no teste, as etapas anteriores serão repetidas.
- O desempenho do modelo é monitorado em campo. Se o desempenho cair abaixo de um nível crítico, o modelo é modificado repetindo as etapas anteriores.
O ensino de máquinas automatiza a criação de tais modelos, facilitando a necessidade de intervenção manual no processo de aprendizagem para melhorar a seleção de recursos ou exemplos, ou ajustes de hiperparâmetros. Com efeito, o ensino de máquina introduz um nível de abstração nos elementos de IA do modelo, permitindo que o desenvolvedor se concentre no conhecimento do domínio. Esta abstração também permite que o algoritmo de IA seja substituído por novos algoritmos mais inovadores no tempo, sem exigir uma reespecificação do problema.
O papel do professor é otimizar a transferência de conhecimento para o algoritmo de aprendizagem para que possa gerar um modelo útil. Os professores também desempenham um papel central na recolha e rotulagem de dados. Os professores podem filtrar dados sem rótulo para selecionar exemplos específicos ou examinar os dados de exemplo disponíveis e adivinhar seu rótulo com base em sua própria intuição ou vieses. Da mesma forma, dadas duas características em um grande conjunto não rotulado, os professores podem conjeturar que um é melhor do que o outro.
A imagem a seguir mostra o processo de alto nível do ensino de máquinas:
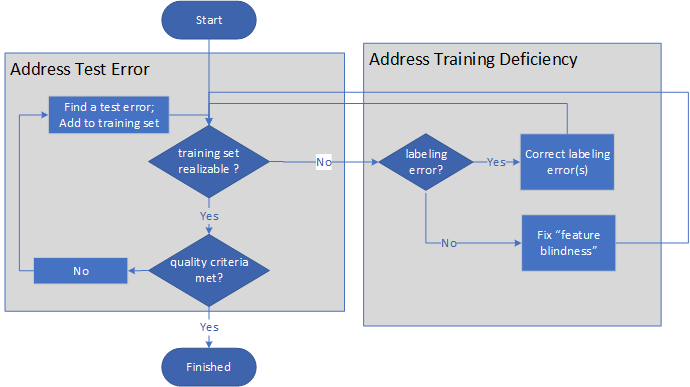
- O professor primeiro questiona se um conjunto de treinamento é realizável.
- Se o conjunto de treinamento não for realizável, o professor determina se o problema se deve a rotulagem inadequada ou deficiências de recursos. Depois de corrigir a etiquetagem ou adicionar recursos, o professor avalia novamente se o conjunto de treinamento é realizável.
- Se o conjunto formativo for realizável, o professor avalia se os critérios de qualidade da formação estão a ser cumpridos.
- Se os critérios de qualidade não estiverem a ser cumpridos, o professor encontra os erros do teste e adiciona as correções ao conjunto de treino, repetindo depois os passos de avaliação.
- Uma vez que o conjunto de treinamento é realizável e os critérios de qualidade são atendidos, o processo termina.
O processo é um par de loops indefinidos, terminando apenas quando o modelo e o treinamento em si são de qualidade suficiente.
A capacidade de aprendizagem do modelo aumenta sob demanda. Não há necessidade de regularização tradicional, pois o professor controla a capacidade do sistema de aprendizagem, adicionando recursos apenas quando necessário.
Ensino de máquinas e programação tradicional
O ensino de máquina é uma forma de programação. O objetivo da programação e do ensino de máquina é criar uma função. As etapas para criar uma função de destino sem estado que retorna o valor Y dado uma entrada X são semelhantes para ambos os processos:
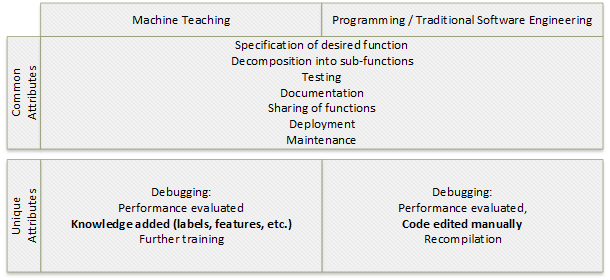
- Especifique a função de destino.
- Decomponha a função de destino em subfunções, se aplicável.
- Depure e teste as funções e subfunções.
- Documente as funções.
- Partilhe as funções.
- Implante as funções.
- Mantenha as funções com ciclos de depuração programados e não agendados.
Depurar ou avaliar o desempenho da solução tem atributos diferentes entre os dois processos. Na programação, a depuração envolve a edição manual e a recompilação do código. No ensino de máquinas, a depuração inclui a adição de rótulos e recursos de conhecimento e treinamento adicional.
A construção de uma função de classificação de destino que retorna a classe Y dada entrada X envolve um algoritmo de aprendizado de máquina, enquanto o processo para o ensino de máquina é como o conjunto de etapas de programação acima.
A tabela a seguir ilustra algumas semelhanças conceituais entre programação tradicional e ensino de máquina:
| Programação | Machine teaching |
|---|---|
| Compilador | Algoritmos de aprendizagem automática, máquinas vetoriais de suporte (SVMS), redes neuronais, motor de treino |
| Sistemas operacionais, serviços, ambientes de desenvolvimento integrado (IDEs) | Treinamento, amostragem, seleção de recursos, serviço de treinamento de máquinas |
| Frameworks | ImageNet, palavra2vec |
| Linguagens de programação como Python e C# | Tinta, rótulos, recursos, esquemas |
| Experiência em programação | Perícia pedagógica |
| Controlo de versões | Controlo de versões |
| Processos de desenvolvimento como especificações, testes unitários, implantação, monitoramento | Processos de ensino como recolha de dados, testes, publicação |
Um conceito poderoso que permite aos engenheiros de software escrever sistemas que resolvem problemas complexos é a decomposição. A decomposição usa conceitos mais simples para expressar conceitos mais complexos. Os professores de máquinas podem aprender a decompor problemas complexos de aprendizado de máquina com as ferramentas e experiências certas. A disciplina de ensino de máquinas pode trazer as expectativas de sucesso para ensinar uma máquina a um nível comparável ao da programação.
Projetos de ensino de máquinas
Pré-requisitos:
- Alguma experiência com coleta, exploração, limpeza, preparação e análise de dados
- Familiaridade com conceitos básicos de ML, como funções objetivas, treinamento, validação cruzada e regularização
Ao construir um projeto de ensino de máquinas, comece com um modelo fiel à vida, mas relativamente simples, para permitir iteração e formulação rápidas. Em seguida, melhore iterativamente a fidelidade do modelo e torne o modelo mais generalizável através de uma melhor cobertura de cenário.
O diagrama a seguir mostra as fases do desenvolvimento iterativo do modelo de ensino de máquina. Cada etapa sucessiva requer um número maior de amostras de treinamento.
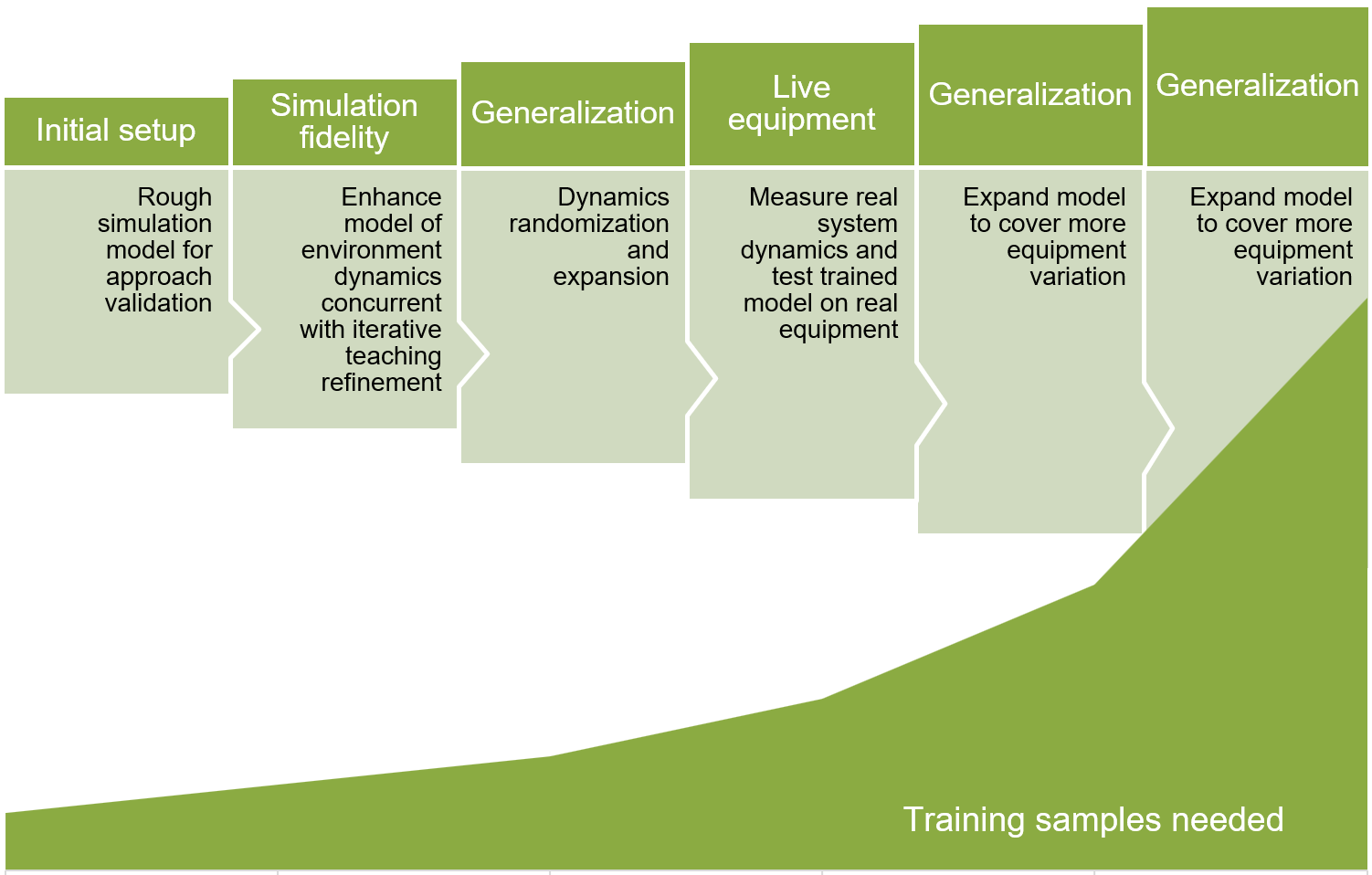
- Configure o modelo inicial de simulação aproximada para validação de abordagem.
- Melhore a fidelidade da simulação modelando a dinâmica do ambiente simultaneamente com refinamentos de ensino iterativos.
- Generalizar modelo com randomização dinâmica e expansão.
- Meça a dinâmica real do sistema e teste o modelo treinado em equipamentos reais.
- Expanda o modelo para cobrir mais variação de equipamentos.
Definir parâmetros exatos para projetos de ensino de máquinas requer um pouco de experimentação e exploração empírica. Uma plataforma de ensino de máquina como o Bonsai na plataforma Microsoft Autonomous Systems usa inovações e simulações DRL para ajudar a simplificar o desenvolvimento de modelos de IA.
Exemplo de projeto
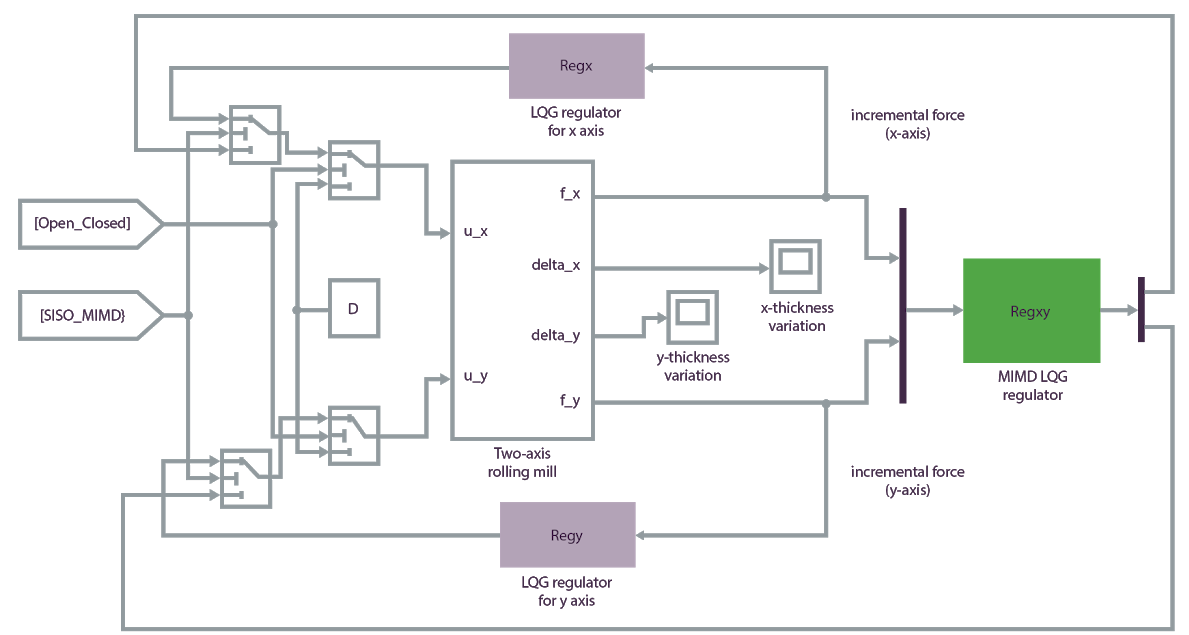
Um exemplo de um projeto de IA de sistemas autônomos é o caso de uso de uma otimização de processo de fabricação. O objetivo é otimizar a tolerância de espessura de uma viga de aço que está sendo fabricada em uma linha de produção. Os rolos fornecem pressão através de um pedaço de aço para moldá-lo na espessura projetada.
As entradas de estado da máquina para o sistema de IA são a força de rolamento, erro de rolo e ruído de rolo. As ações de controle do sistema de IA são comandos atuadores para controlar a operação e o movimento dos rolos e otimizar a tolerância de espessura do feixe de aço.
Primeiro, encontre ou desenvolva um simulador que possa simular agentes, sensores e o ambiente. O seguinte modelo de simulação Matlab fornece um ambiente de treinamento preciso para este sistema de IA:
Use o serviço de ensino de máquina Bonsai na Plataforma de Sistemas Autônomos da Microsoft para construir um plano de ensino de máquina em um modelo, treinar o modelo em relação ao simulador e implantar o sistema de IA treinado na instalação de produção real. Inkling é uma linguagem específica para descrever formalmente planos de ensino de máquinas. No Bonsai, você pode usar o Inkling para desconstruir o problema no esquema:

Em seguida, defina conceitos-chave e crie um currículo para ensinar o sistema de IA, especificando a função de recompensa para o estado de simulação:

O sistema de IA aprende praticando a tarefa de otimização em simulação, seguindo os conceitos de ensino de máquina. Você pode carregar a simulação no Bonsai, onde ela fornece visualizações do progresso do treinamento à medida que ele é executado.
Depois de construir e treinar o modelo ou cérebro, você pode exportá-lo para implantá-lo na instalação de produção, onde os comandos ideais do atuador fluem do mecanismo de IA para apoiar as decisões do operador em tempo real.
Outros exemplos de aplicações
Os exemplos de ensino de máquina a seguir criam políticas para controlar os movimentos de sistemas físicos. Em ambos os casos, criar manualmente uma política para o agente é inviável ou muito difícil. Permitir que o agente explore o espaço em simulação e orientá-lo a fazer escolhas através de funções de recompensa produz soluções precisas.
Carrinho
No projeto Cartpole de amostra em Bonsai, o objetivo é ensinar um poste a permanecer ereto em um carrinho em movimento. O poste é fixado por uma junta não ativada ao carrinho, que se move ao longo de uma pista sem atrito. As informações disponíveis do sensor incluem a posição e a velocidade do carrinho, bem como o ângulo do polo e a velocidade angular.
A aplicação de uma força ao carrinho controla o sistema. As ações do agente suportado são empurrar o carrinho para a esquerda ou para a direita. O programa oferece uma recompensa positiva por cada passo que o poste permanece ereto. O episódio termina quando o poste está a mais de 15 graus da vertical, ou o carrinho se move mais do que um número predefinido de unidades do centro.
O exemplo usa a linguagem Inkling para escrever o programa de ensino de máquina e o simulador Cartpole fornecido para acelerar e melhorar o treinamento.
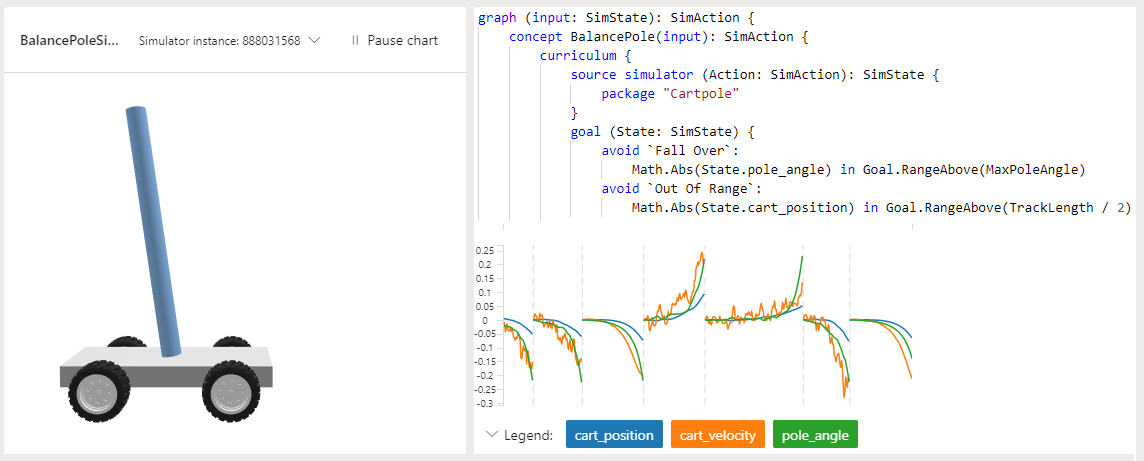
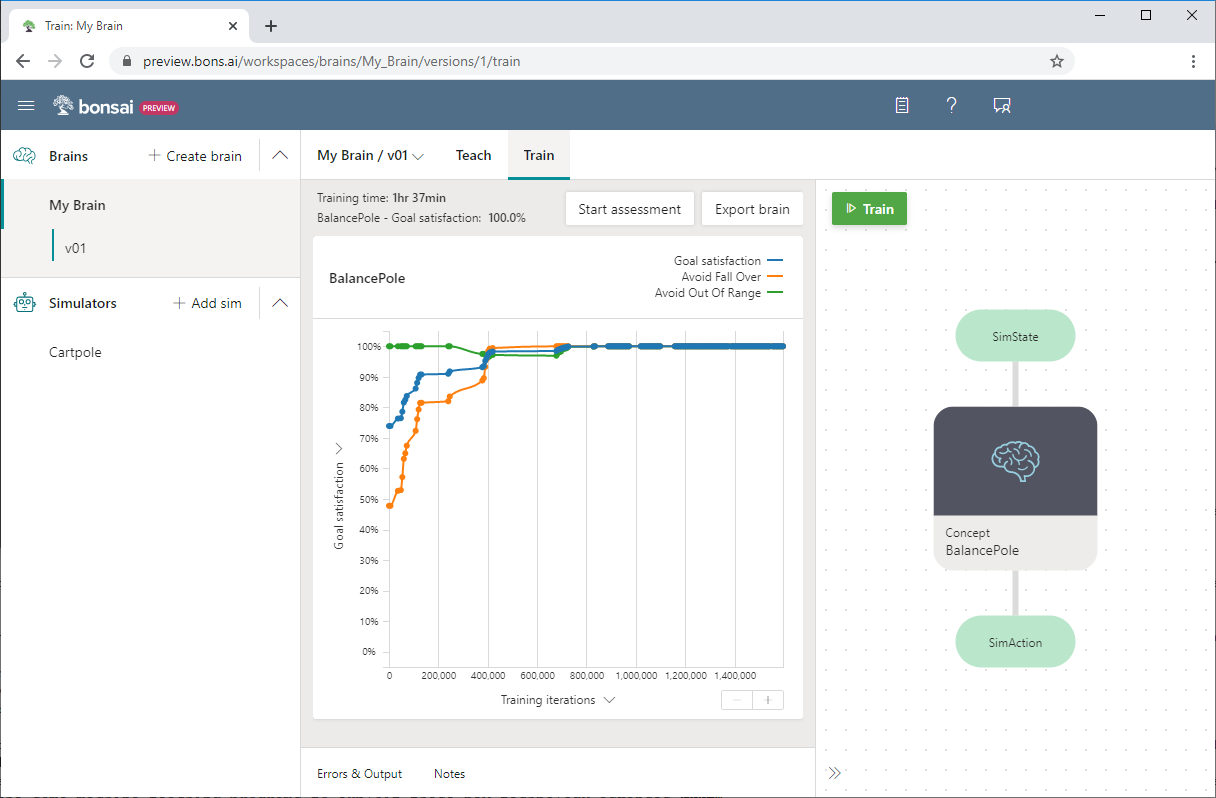
A captura de tela do Bonsai a seguir mostra um treinamento Cartpole, com satisfação de metas no eixo y e iterações de treinamento no eixo x. O painel do Bonsai também mostra a percentagem de satisfação com os objetivos e o tempo total de treino.
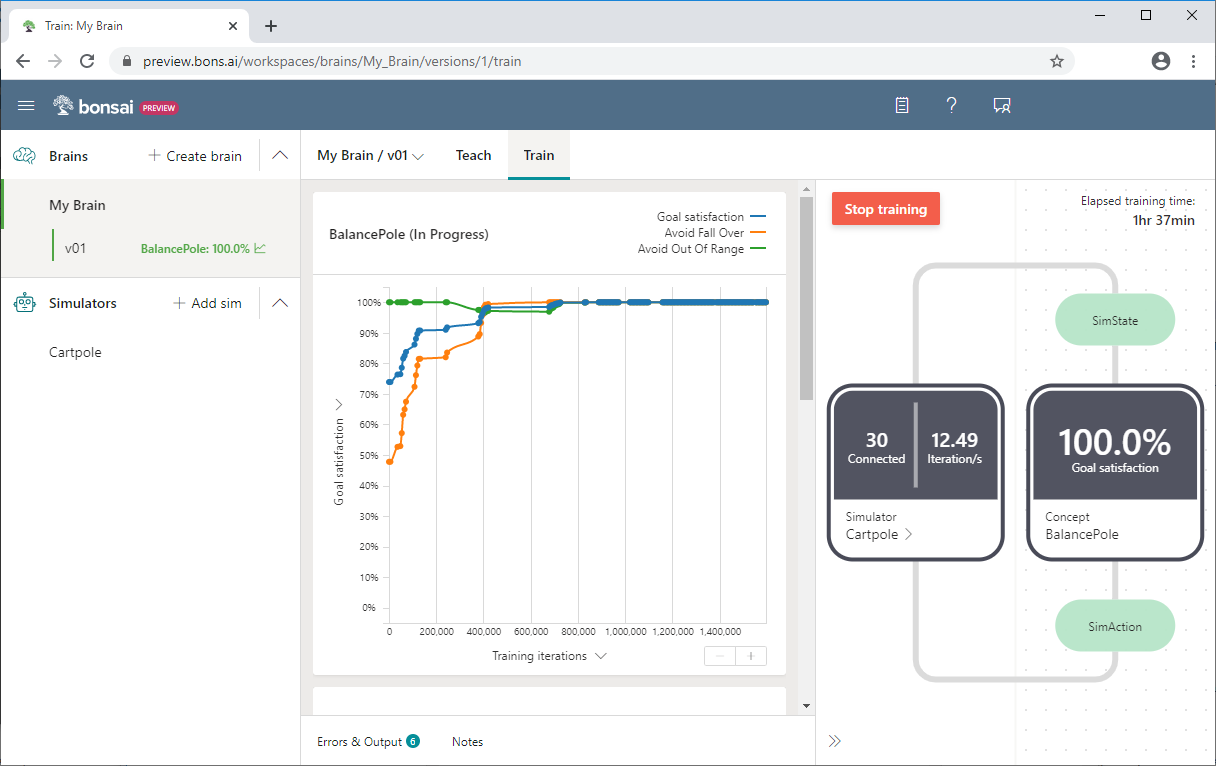
Para obter mais informações sobre o exemplo do Cartpole ou para experimentá-lo você mesmo, consulte Saiba como você pode ensinar um agente de IA a equilibrar um poste.
Perfuração de petróleo
O aplicativo Horizontal Oil Drilling é um controlador de movimento para automatizar plataformas de petróleo que perfuram horizontalmente no subsolo. Um operador controla a broca subterrânea com um joystick para manter a broca dentro do xisto betuminoso, evitando obstáculos. A broca faz o menor número possível de ações de direção, para uma perfuração mais rápida. O objetivo é usar o aprendizado de reforço para automatizar o controle da broca de petróleo horizontal.
As informações disponíveis do sensor incluem a direção da força da broca, o peso da broca, a força lateral e o ângulo de perfuração. As ações do agente suportado são mover a broca para cima, para baixo, para a esquerda ou para a direita. O programa fornece uma recompensa positiva quando a broca está dentro da distância de tolerância das paredes da câmara. O modelo aprende a se adaptar a diferentes planos de poço, posições iniciais de perfuração e imprecisões de sensores.
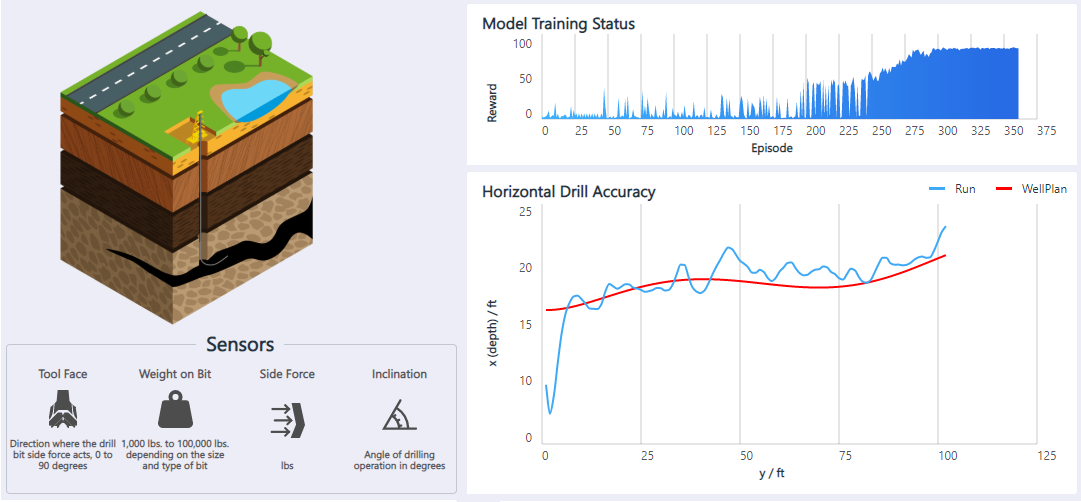
Para obter mais informações e uma demonstração dessa solução, consulte Controle de movimento: perfuração horizontal de óleo.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Autor principal:
- Jose Contreras - Brasil | Gerente Principal de Engenharia de Software
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
- Ensino de máquinas para sistemas autónomos
- Sistemas autónomos com IA da Microsoft
- Autonomia para sistemas de controlo industrial
- Ensino de máquinas: como a experiência das pessoas torna a IA ainda mais poderosa
- Microsoft amplia disponibilidade de ferramentas de sistemas autônomos para engenheiros e desenvolvedores
- Espaço de inovação: Sistemas autónomos (Vídeo)
- Microsoft O Blog da IA
- Plataforma de Informática Aérea e Robótica (AirSim)
- Miradouro
- Simulink
Saiba mais sobre o ensino de máquinas:
- "Bonsai, AI para Todos", 2016 março 2
- "Casos de uso de IA: inovações resolvendo mais do que apenas problemas de brinquedos", 2017 março 2
- Patrice Y. Simard, Saleema Amershi, David M. Chickering, et al., "Machine Teaching: A New Paradigm for Building Machine Learning Systems", 2017
- Carlos E. Perez, "Deep Teaching: The Sexiest Job of the Future" (Ensino profundo: o trabalho mais sexy do futuro), 29 de julho de 2017
- Tambet Matiisen, "Desmistificando a aprendizagem profunda por reforço", 2015 19 de dezembro
- Andrej Karpathy, "Deep Reinforcement Learning: Pong from Pixels", 31 de maio de 2016
- David Kestenbaum, "Pop Quiz: Como você impede os capitães do mar de matar seus passageiros?" 2010 setembro 10