Tutorial: Teste de validação automatizado
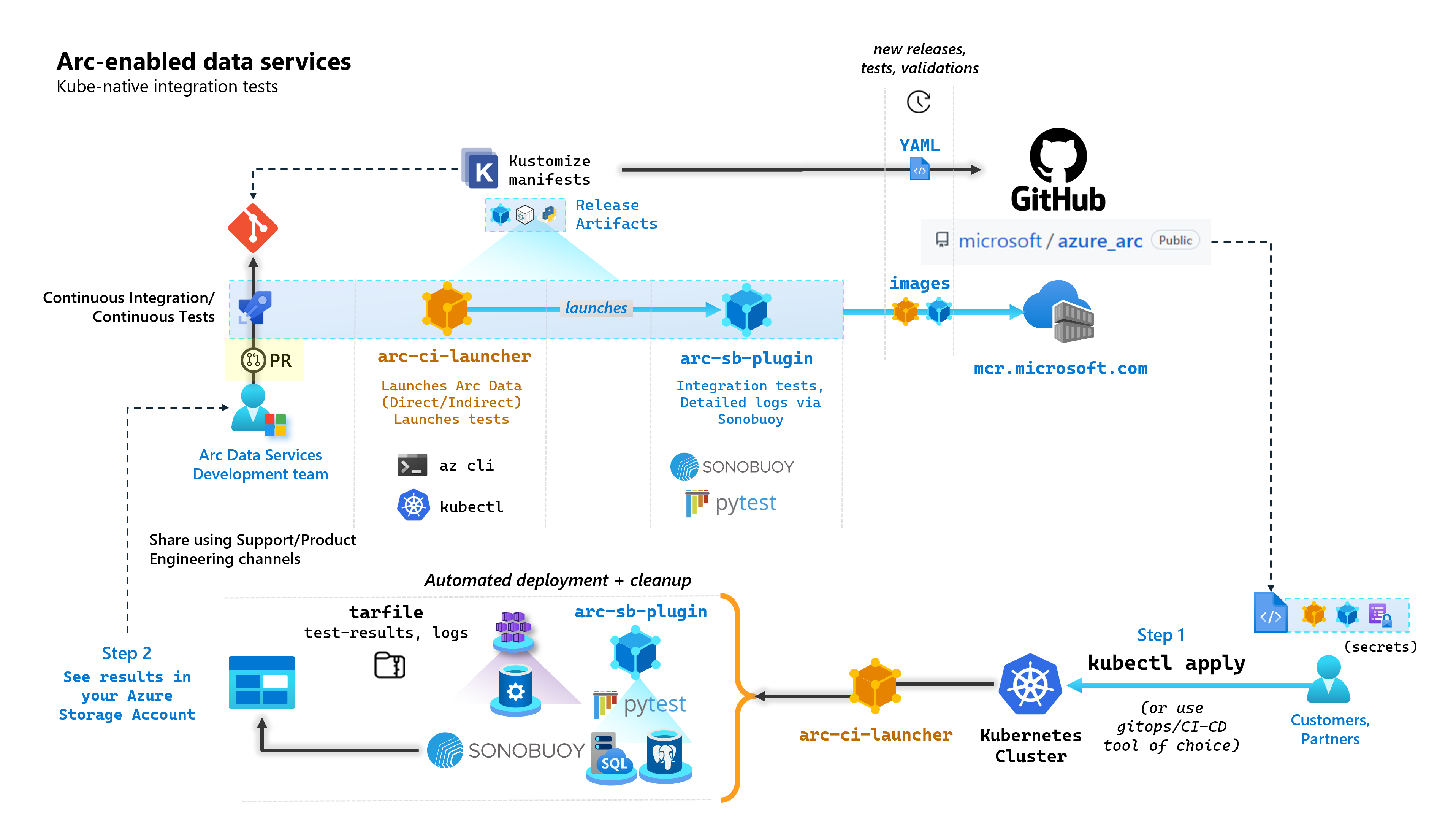
Como parte de cada confirmação que cria serviços de dados habilitados para Arc, a Microsoft executa pipelines automatizados de CI/CD que executam testes de ponta a ponta. Esses testes são orquestrados por meio de dois contêineres que são mantidos ao lado do produto principal (Controlador de Dados, Instância Gerenciada SQL habilitada pelo Azure Arc & servidor PostgreSQL). Estes contentores são:
arc-ci-launcher: Contendo dependências de implantação (por exemplo, extensões de CLI), bem como código de implantação de produto (usando a CLI do Azure) para os modos de conectividade Direta e Indireta. Depois que o Kubernetes é integrado ao Controlador de Dados, o contêiner aproveita o Sonobuoy para disparar testes de integração paralelos.arc-sb-plugin: Um plugin Sonobuoy contendo testes de integração de ponta a ponta baseados em Pytest, variando de simples testes de fumaça (implantações, exclusões), a cenários complexos de alta disponibilidade, testes de caos (exclusões de recursos) etc.
Esses contêineres de teste são disponibilizados publicamente para que clientes e parceiros realizem testes de validação de serviços de dados habilitados para Arc em seus próprios clusters Kubernetes executados em qualquer lugar, para validar:
- Distro/versões do Kubernetes
- Host disto/versões
- Armazenamento (/CSI), rede (
StorageClasspor exemploLoadBalancer, s, DNS) - Outros Kubernetes ou configuração específica de infraestrutura
Para clientes que pretendem executar serviços de dados habilitados para Arc em uma distribuição não documentada, eles devem executar esses testes de validação com êxito para serem considerados suportados. Além disso, os parceiros podem usar essa abordagem para certificar que sua solução está em conformidade com os Serviços de Dados habilitados para Arc - consulte Validação do Kubernetes dos serviços de dados habilitados para Arc do Azure.
O diagrama a seguir descreve esse processo de alto nível:
Neste tutorial, irá aprender a:
- Implantar
arc-ci-launcherusandokubectl - Examinar os resultados do teste de validação em sua conta de Armazenamento de Blob do Azure
Pré-requisitos
Credenciais:
- O
test.env.tmplarquivo contém as credenciais necessárias necessárias e é uma combinação dos pré-requisitos existentes necessários para integrar um Cluster Conectado do Azure Arc e um Controlador de Dados Diretamente Conectado. A configuração deste arquivo é explicada abaixo com exemplos. - Um arquivo kubeconfig para o cluster Kubernetes testado com
cluster-adminacesso (necessário para integração de cluster conectado no momento)
- O
Ferramentas para clientes:
kubectlinstalado - versão mínima (Major:"1", Minor:"21")gitinterface de linha de comando (ou alternativas baseadas em interface do usuário)
Preparação do manifesto do Kubernetes
O lançador é disponibilizado como parte do repositório, como um manifesto microsoft/azure_arc Kustomize - Kustomize é construído -kubectlportanto, nenhuma ferramenta adicional é necessária.
- Clone o repositório localmente:
git clone https://github.com/microsoft/azure_arc.git
- Navegue até
azure_arc/arc_data_services/test/launcher, para ver a seguinte estrutura de pastas:
├── base <- Comon base for all Kubernetes Clusters
│ ├── configs
│ │ └── .test.env.tmpl <- To be converted into .test.env with credentials for a Kubernetes Secret
│ ├── kustomization.yaml <- Defines the generated resources as part of the launcher
│ └── launcher.yaml <- Defines the Kubernetes resources that make up the launcher
└── overlays <- Overlays for specific Kubernetes Clusters
├── aks
│ ├── configs
│ │ └── patch.json.tmpl <- To be converted into patch.json, patch for Data Controller control.json
│ └── kustomization.yaml
├── kubeadm
│ ├── configs
│ │ └── patch.json.tmpl
│ └── kustomization.yaml
└── openshift
├── configs
│ └── patch.json.tmpl
├── kustomization.yaml
└── scc.yaml
Neste tutorial, vamos nos concentrar nas etapas para o AKS, mas a estrutura de sobreposição acima pode ser estendida para incluir distribuições Kubernetes adicionais.
O manifesto pronto para implantar representará o seguinte:
├── base
│ ├── configs
│ │ ├── .test.env <- Config 1: For Kubernetes secret, see sample below
│ │ └── .test.env.tmpl
│ ├── kustomization.yaml
│ └── launcher.yaml
└── overlays
└── aks
├── configs
│ ├── patch.json.tmpl
│ └── patch.json <- Config 2: For control.json patching, see sample below
└── kustomization.yam
Há dois arquivos que precisam ser gerados para localizar o iniciador para ser executado dentro de um ambiente específico. Cada um desses arquivos pode ser gerado copiando-colando e preenchendo cada um dos arquivos de modelo (*.tmpl) acima:
.test.env: preencher a partir de.test.env.tmplpatch.json: preencher a partir depatch.json.tmpl
Gorjeta
O .test.env é um único conjunto de variáveis de ambiente que impulsiona o comportamento do iniciador. Gerá-lo com cuidado para um determinado ambiente garantirá a reprodutibilidade do comportamento do lançador.
Configuração 1: .test.env
Uma amostra preenchida do .test.env arquivo, gerada com base em .test.env.tmpl , é compartilhada abaixo com comentários embutidos.
Importante
A export VAR="value" sintaxe abaixo não deve ser executada localmente para originar variáveis de ambiente da sua máquina - mas está lá para o iniciador. O lançador monta este .test.env arquivo como está como um Kubernetes usando Kustomize (Kustomize secretGenerator pega um arquivo, base64 codifica todo o conteúdo do arquivo e o transforma em um segredo do Kubernetessecret). Durante a inicialização, o lançador executa o comando bash source , que importa as variáveis de ambiente do arquivo montado .test.env como está para o ambiente do iniciador.
Em outras palavras, depois de .test.env.tmpl copiar e colar e editar para criar .test.env, o arquivo gerado deve ser semelhante ao exemplo abaixo. O processo para preencher o arquivo é idêntico em todos os .test.env sistemas operacionais e terminais.
Gorjeta
Há um punhado de variáveis de ambiente que requerem explicação adicional para clareza na reprodutibilidade. Estes serão comentados com see detailed explanation below [X].
Gorjeta
Observe que o exemplo abaixo é para o .test.env modo direto. Algumas dessas variáveis, como ARC_DATASERVICES_EXTENSION_VERSION_TAG não se aplicam ao modo indireto . Para simplificar, é melhor configurar o arquivo com variáveis de modo direto em mente, a mudança CONNECTIVITY_MODE=indirect fará com que o .test.env iniciador ignore as configurações específicas do modo direto e use um subconjunto da lista.
Em outras palavras, o planejamento para o modo direto nos permite satisfazer variáveis de modo indireto .
Amostra acabada de .test.env:
# ======================================
# Arc Data Services deployment version =
# ======================================
# Controller deployment mode: direct, indirect
# For 'direct', the launcher will also onboard the Kubernetes Cluster to Azure Arc
# For 'indirect', the launcher will skip Azure Arc and extension onboarding, and proceed directly to Data Controller deployment - see `patch.json` file
export CONNECTIVITY_MODE="direct"
# The launcher supports deployment of both GA/pre-GA trains - see detailed explanation below [1]
export ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN="stable"
export ARC_DATASERVICES_EXTENSION_VERSION_TAG="1.11.0"
# Image version
export DOCKER_IMAGE_POLICY="Always"
export DOCKER_REGISTRY="mcr.microsoft.com"
export DOCKER_REPOSITORY="arcdata"
export DOCKER_TAG="v1.11.0_2022-09-13"
# "arcdata" Azure CLI extension version override - see detailed explanation below [2]
export ARC_DATASERVICES_WHL_OVERRIDE=""
# ================
# ARM parameters =
# ================
# Custom Location Resource Provider Azure AD Object ID - this is a single, unique value per Azure AD tenant - see detailed explanation below [3]
export CUSTOM_LOCATION_OID="..."
# A pre-rexisting Resource Group is used if found with the same name. Otherwise, launcher will attempt to create a Resource Group
# with the name specified, using the Service Principal specified below (which will require `Owner/Contributor` at the Subscription level to work)
export LOCATION="eastus"
export RESOURCE_GROUP_NAME="..."
# A Service Principal with "sufficient" privileges - see detailed explanation below [4]
export SPN_CLIENT_ID="..."
export SPN_CLIENT_SECRET="..."
export SPN_TENANT_ID="..."
export SUBSCRIPTION_ID="..."
# Optional: certain integration tests test upload to Log Analytics workspace:
# https://learn.microsoft.com/azure/azure-arc/data/upload-logs
export WORKSPACE_ID="..."
export WORKSPACE_SHARED_KEY="..."
# ====================================
# Data Controller deployment profile =
# ====================================
# Samples for AKS
# To see full list of CONTROLLER_PROFILE, run: az arcdata dc config list
export CONTROLLER_PROFILE="azure-arc-aks-default-storage"
# azure, aws, gcp, onpremises, alibaba, other
export DEPLOYMENT_INFRASTRUCTURE="azure"
# The StorageClass used for PVCs created during the tests
export KUBERNETES_STORAGECLASS="default"
# ==============================
# Launcher specific parameters =
# ==============================
# Log/test result upload from launcher container, via SAS URL - see detailed explanation below [5]
export LOGS_STORAGE_ACCOUNT="<your-storage-account>"
export LOGS_STORAGE_ACCOUNT_SAS="?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=..."
export LOGS_STORAGE_CONTAINER="arc-ci-launcher-1662513182"
# Test behavior parameters
# The test suites to execute - space seperated array,
# Use these default values that run short smoke tests, further elaborate test suites will be added in upcoming releases
export SQL_HA_TEST_REPLICA_COUNT="3"
export TESTS_DIRECT="direct-crud direct-hydration controldb"
export TESTS_INDIRECT="billing controldb kube-rbac"
export TEST_REPEAT_COUNT="1"
export TEST_TYPE="ci"
# Control launcher behavior by setting to '1':
#
# - SKIP_PRECLEAN: Skips initial cleanup
# - SKIP_SETUP: Skips Arc Data deployment
# - SKIP_TEST: Skips sonobuoy tests
# - SKIP_POSTCLEAN: Skips final cleanup
# - SKIP_UPLOAD: Skips log upload
#
# See detailed explanation below [6]
export SKIP_PRECLEAN="0"
export SKIP_SETUP="0"
export SKIP_TEST="0"
export SKIP_POSTCLEAN="0"
export SKIP_UPLOAD="0"
Importante
Se estiver executando a geração do arquivo de configuração em uma máquina Windows, você precisará converter a sequência de fim de linha de CRLF (Windows) para LF (Linux), como executado como arc-ci-launcher um contêiner Linux. Deixar a linha terminando como pode causar um erro no arc-ci-launcher início do contêiner - comoCRLF: /launcher/config/.test.env: $'\r': command not found Por exemplo, execute a alteração usando VSCode (canto inferior direito da janela):

Explicação detalhada para determinadas variáveis
1. ARC_DATASERVICES_EXTENSION_* - Versão de extensão e comboio
Obrigatório: isso é necessário para
directimplantações de modo.
O lançador pode implantar versões GA e pré-GA.
A versão de extensão para o mapeamento release-train (ARC_DATASERVICES_EXTENSION_RELEASE_TRAIN) é obtida aqui:
- GA:
stable- Registo de versões - Pré-GA:
preview- Testes de pré-lançamento
2. ARC_DATASERVICES_WHL_OVERRIDE - URL de download da versão anterior da CLI do Azure
Opcional: deixe isso vazio para
.test.envusar o padrão pré-empacotado.
A imagem do iniciador é pré-empacotada com a versão mais recente da CLI arcdata no momento da liberação de cada imagem de contêiner. No entanto, para trabalhar com versões mais antigas e testes de atualização, pode ser necessário fornecer ao iniciador o link de download da URL do Blob da CLI do Azure, para substituir a versão pré-empacotada; Por exemplo, para instruir o iniciador a instalar a versão 1.4.3, preencha:
export ARC_DATASERVICES_WHL_OVERRIDE="https://azurearcdatacli.blob.core.windows.net/cli-extensions/arcdata-1.4.3-py2.py3-none-any.whl"
A versão da CLI para mapeamento de URL de Blob pode ser encontrada aqui.
3. CUSTOM_LOCATION_OID - ID de objeto de locais personalizados do seu locatário específico do Microsoft Entra
Obrigatório: isso é necessário para a criação do Local Personalizado do Cluster Conectado.
As etapas a seguir são originadas de Habilitar locais personalizados em seu cluster para recuperar a ID de Objeto de Local Personalizado exclusiva para seu locatário do Microsoft Entra.
Há duas abordagens para obter o para seu locatário do CUSTOM_LOCATION_OID Microsoft Entra.
Através da CLI do Azure:
az ad sp show --id bc313c14-388c-4e7d-a58e-70017303ee3b --query objectId -o tsv # 51dfe1e8-70c6-4de... <--- This is for Microsoft's own tenant - do not use, the value for your tenant will be different, use that instead to align with the Service Principal for launcher.
Através do portal do Azure - navegue até à folha do Microsoft Entra e procure por
Custom Locations RP: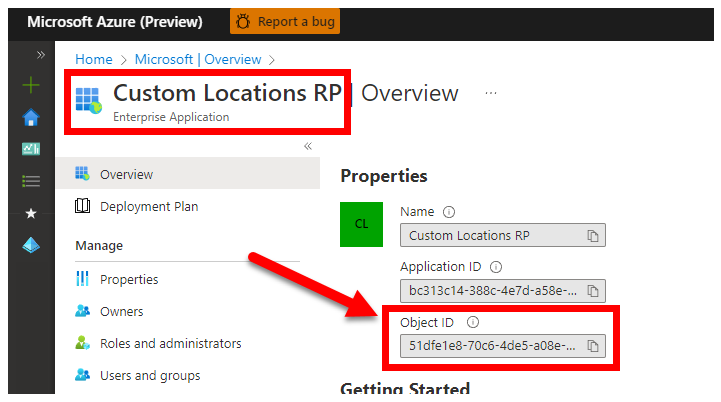
4. SPN_CLIENT_* - Credenciais da entidade de serviço
Obrigatório: é necessário para implantações no Modo Direto.
O iniciador inicia sessão no Azure utilizando estas credenciais.
O teste de validação destina-se a ser executado no cluster Kubernetes de Não Produção/Teste & Assinaturas do Azure - com foco na validação funcional da configuração do Kubernetes/Infraestrutura. Portanto, para evitar o número de etapas manuais necessárias para executar iniciações, é recomendável fornecer um SPN_CLIENT_ID/SECRET que tenha Owner no nível de Grupo de Recursos (ou Assinatura), pois criará vários recursos nesse Grupo de Recursos, bem como atribuirá permissões a esses recursos em relação a várias Identidades Gerenciadas criadas como parte da implantação (essas atribuições de função, por sua vez, exigem que a Entidade de Serviço tenha Owner).
5. LOGS_STORAGE_ACCOUNT_SAS - URL SAS da Conta de Armazenamento de Blob
Recomendado: deixar isso vazio significa que você não obterá resultados de testes e logs.
O iniciador precisa de um local persistente (Armazenamento de Blobs do Azure) para carregar resultados, já que o Kubernetes (ainda) não permite copiar arquivos de pods parados/concluídos - veja aqui. O iniciador obtém conectividade com o Armazenamento de Blobs do Azure usando uma URL SAS com escopo de conta (em oposição ao escopo de contêiner ou blob) - uma URL assinada com uma definição de acesso com limite de tempo - consulte Conceder acesso limitado aos recursos do Armazenamento do Azure usando assinaturas de acesso compartilhado (SAS), para:
- Crie um novo Contêiner de Armazenamento na Conta de Armazenamento pré-existente (), se ele não existir (
LOGS_STORAGE_ACCOUNTnome baseado emLOGS_STORAGE_CONTAINER) - Criar novos blobs com nomes exclusivos (arquivos tar de log de teste)
As etapas a seguir são originadas de Conceder acesso limitado aos recursos do Armazenamento do Azure usando assinaturas de acesso compartilhado (SAS).
Gorjeta
Os URLs SAS são diferentes da Chave de Conta de Armazenamento, um URL SAS é formatado da seguinte forma.
?sv=2021-06-08&ss=bfqt&srt=sco&sp=rwdlacupiytfx&se=...&spr=https&sig=...
Existem várias abordagens para gerar uma URL SAS. Este exemplo mostra o portal:
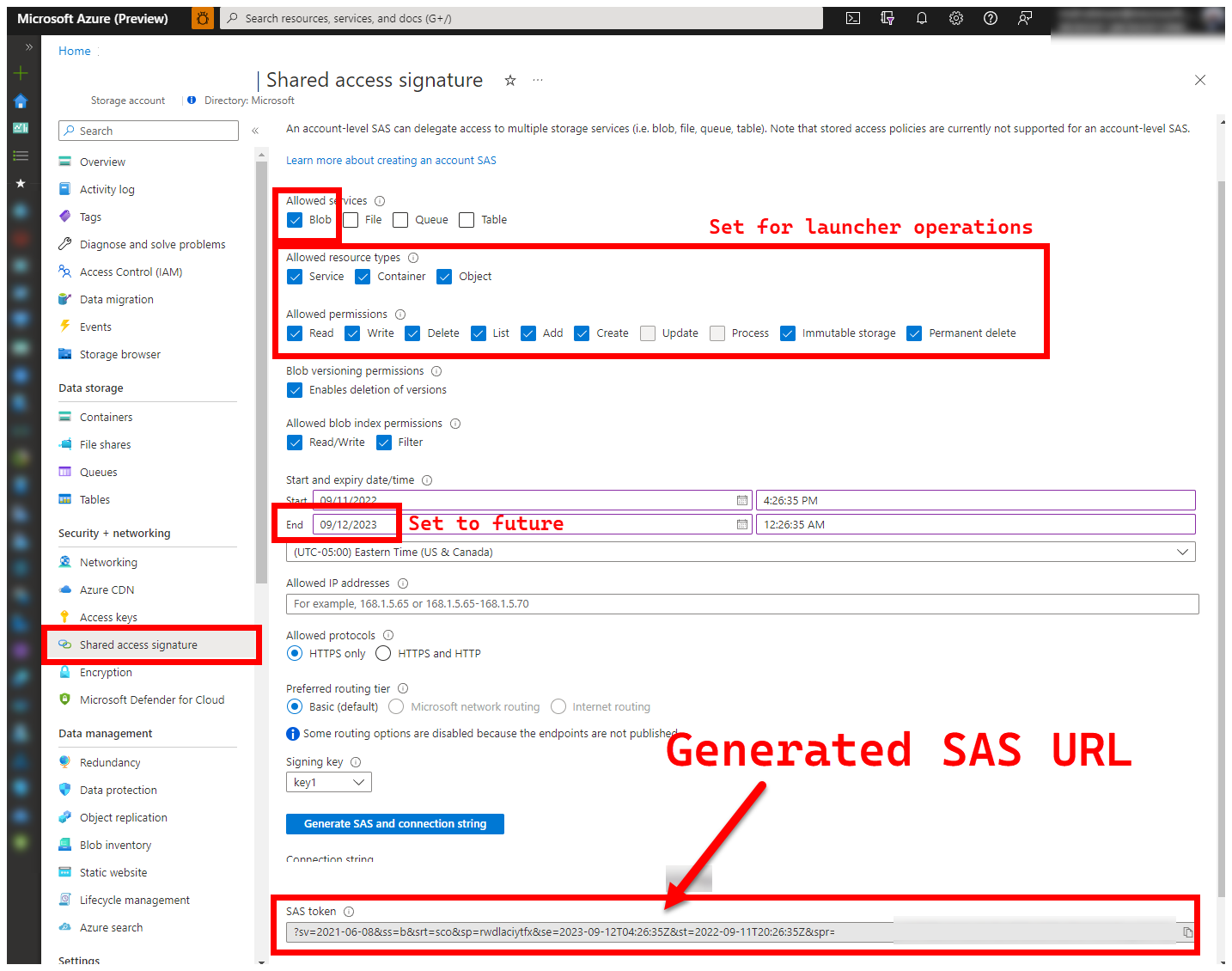
Para usar a CLI do Azure em vez disso, consulte az storage account generate-sas
6. SKIP_* - controlar o comportamento do lançador pulando certos estágios
Opcional: deixe em branco para executar todas as etapas (equivalente ou
0em branco.test.env)
O lançador expõe SKIP_* variáveis, para executar e pular etapas específicas - por exemplo, para executar uma execução "somente limpeza".
Embora o lançador seja projetado para limpar tanto no início quanto no final de cada corrida, é possível que falhas de lançamento e/ou teste deixem recursos residuais para trás. Para executar o iniciador no modo "somente limpeza", defina as seguintes variáveis em .test.env:
export SKIP_PRECLEAN="0" # Run cleanup
export SKIP_SETUP="1" # Do not setup Arc-enabled Data Services
export SKIP_TEST="1" # Do not run integration tests
export SKIP_POSTCLEAN="1" # POSTCLEAN is identical to PRECLEAN, although idempotent, not needed here
export SKIP_UPLOAD="1" # Do not upload logs from this run
As configurações acima instruem o iniciador a limpar todos os recursos do Arc e Arc Data Services e a não implantar/testar/carregar logs.
Configuração 2: patch.json
Uma amostra preenchida do patch.json arquivo, gerada com base em patch.json.tmpl é compartilhada abaixo:
Note que o
spec.docker.registry, repository, imageTagdeve ser idêntico aos valores acima.test.env
Amostra acabada de patch.json:
{
"patch": [
{
"op": "add",
"path": "spec.docker",
"value": {
"registry": "mcr.microsoft.com",
"repository": "arcdata",
"imageTag": "v1.11.0_2022-09-13",
"imagePullPolicy": "Always"
}
},
{
"op": "add",
"path": "spec.storage.data.className",
"value": "default"
},
{
"op": "add",
"path": "spec.storage.logs.className",
"value": "default"
}
]
}
Implantação do iniciador
Recomenda-se implantar o iniciador em um cluster de não-produção/teste - pois ele executa ações destrutivas no Arc e em outros recursos usados do Kubernetes.
imageTag Especificação
O lançador é definido dentro do Manifesto do Kubernetes como um Job, o que requer instruir o Kubernetes onde encontrar a imagem do lançador. Isto é definido em base/kustomization.yaml:
images:
- name: arc-ci-launcher
newName: mcr.microsoft.com/arcdata/arc-ci-launcher
newTag: v1.11.0_2022-09-13
Gorjeta
Para recapitular, neste ponto - há 3 lugares que especificamos imageTags, para clareza, aqui está uma explicação dos diferentes usos de cada um. Normalmente - ao testar uma determinada versão, todos os 3 valores seriam os mesmos (alinhando-se a uma determinada versão):
| # | Nome do ficheiro | Nome da variável | Porquê? | Usado por? |
|---|---|---|---|---|
| 5 | .test.env |
DOCKER_TAG |
Fornecendo a imagem do Bootstrapper como parte da instalação da extensão | az k8s-extension create no lançador |
| 2 | patch.json |
value.imageTag |
Fornecimento da imagem do Controlador de Dados | az arcdata dc create no lançador |
| 3 | kustomization.yaml |
images.newTag |
Fornecendo a imagem do lançador | kubectl applying o lançador |
kubectl apply
Para validar se o manifesto foi configurado corretamente, tente a validação do lado do cliente com --dry-run=client, que imprime os recursos do Kubernetes a serem criados para o iniciador:
kubectl apply -k arc_data_services/test/launcher/overlays/aks --dry-run=client
# namespace/arc-ci-launcher created (dry run)
# serviceaccount/arc-ci-launcher created (dry run)
# clusterrolebinding.rbac.authorization.k8s.io/arc-ci-launcher created (dry run)
# secret/test-env-fdgfm8gtb5 created (dry run) <- Created from Config 1: `patch.json`
# configmap/control-patch-2hhhgk847m created (dry run) <- Created from Config 2: `.test.env`
# job.batch/arc-ci-launcher created (dry run)
Para implantar o iniciador e os logs de cauda, execute o seguinte:
kubectl apply -k arc_data_services/test/launcher/overlays/aks
kubectl wait --for=condition=Ready --timeout=360s pod -l job-name=arc-ci-launcher -n arc-ci-launcher
kubectl logs job/arc-ci-launcher -n arc-ci-launcher --follow
Neste ponto, o lançador deve começar - e você deve ver o seguinte:
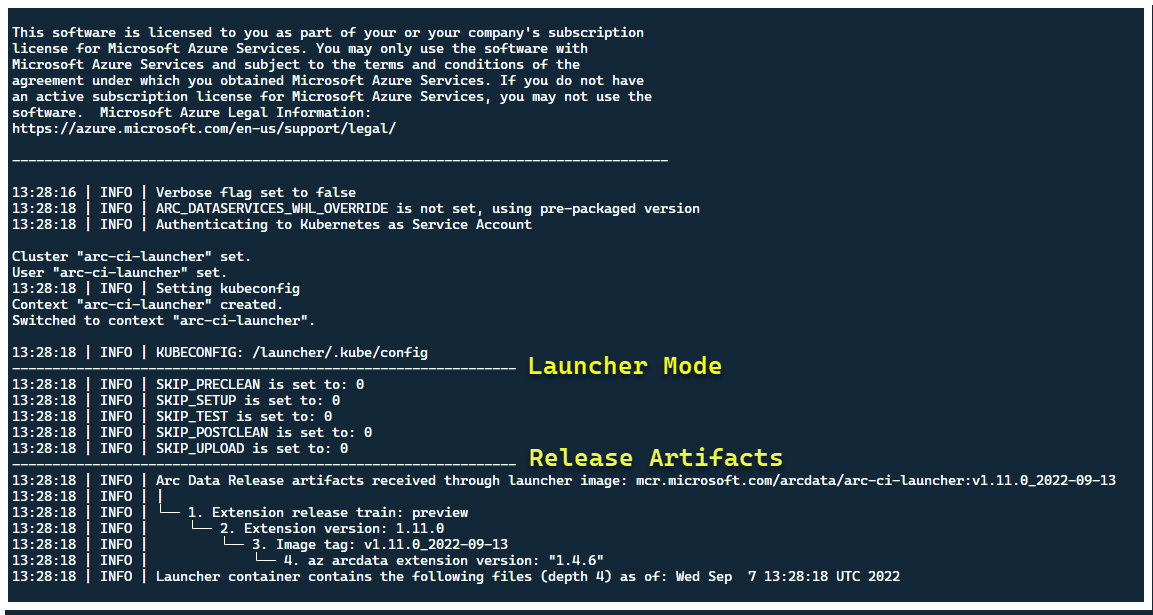
Embora seja melhor implantar o iniciador em um cluster sem recursos Arc pré-existentes, o iniciador contém validação pré-voo para descobrir CRDs e recursos ARM pré-existentes do Arc e Arc Data Services e tenta limpá-los com base no melhor esforço (usando as credenciais da entidade de serviço fornecida), antes de implantar a nova versão:
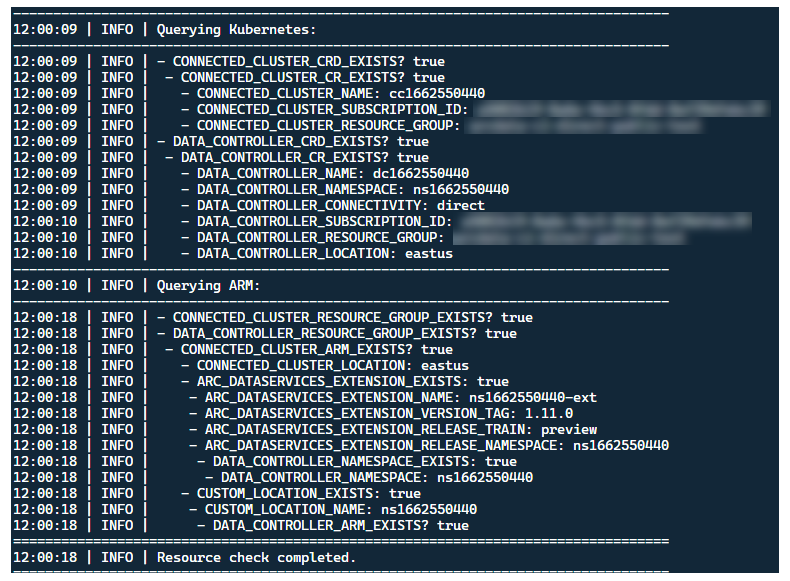
Esse mesmo processo de descoberta e limpeza de metadados também é executado na saída do iniciador, para deixar o cluster o mais próximo possível do estado pré-existente antes do lançamento.
Etapas executadas pelo iniciador
Em um alto nível, o lançador executa a seguinte sequência de etapas:
Autenticar na API do Kubernetes usando a conta de serviço montada no pod
Autenticar na API ARM usando a entidade de serviço montada em segredo
Execute a verificação de metadados CRD para descobrir recursos personalizados existentes do Arc e Arc Data Services
Limpe todos os Recursos Personalizados existentes no Kubernetes e os recursos subsequentes no Azure. Se houver alguma incompatibilidade entre as credenciais em
.test.envcomparação com os recursos existentes no cluster, saia.Gere um conjunto exclusivo de variáveis de ambiente com base no carimbo de data/hora para o nome do Arc Cluster, o Controlador de Dados e o Local/Namespace personalizado. Imprime as variáveis de ambiente, ofuscando valores sensíveis (por exemplo, Senha da Entidade de Serviço, etc.)
a. Para o Modo Direto - Integre o Cluster ao Azure Arc e, em seguida, implante o controlador.
b. Para o modo indireto: implante o controlador de dados
Quando o Controlador de Dados estiver
Ready, gere um conjunto de logs da CLI do Azure (az arcdata dc debug) e armazene localmente, rotulado como - comosetup-completeuma linha de base.Use a
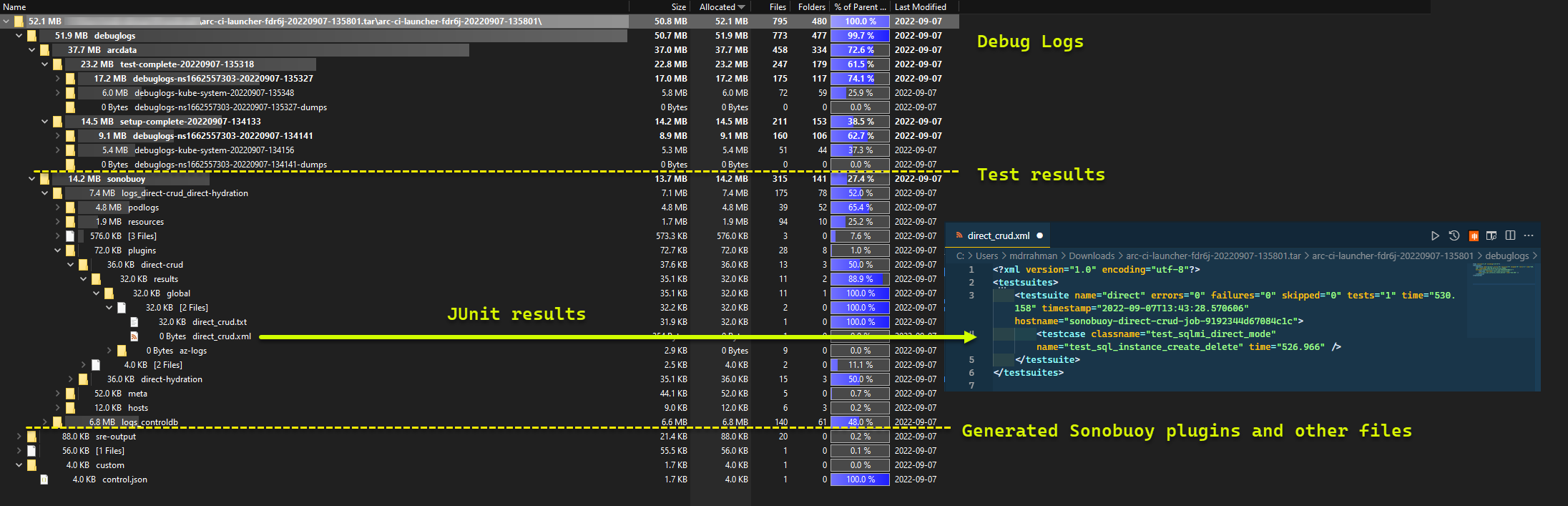
TESTS_DIRECT/INDIRECTvariável de ambiente de para iniciar um conjunto de execuções de.test.envteste Sonobuoy paralelizadas com base em uma matriz separada por espaço (TESTS_(IN)DIRECT). Essas execuções são executadas em um novosonobuoynamespace, usandoarc-sb-pluginpod que contém os testes de validação do Pytest.O agregador Sonobuoy acumula os resultados do teste e os logs por
arc-sb-pluginexecução de teste, que são exportados para o pod dojunitlançador.Retorna o código de saída dos testes e gera outro conjunto de logs de depuração - CLI do Azure e
sonobuoy- armazenados localmente, rotulados comotest-complete.Execute uma verificação de metadados CRD, semelhante à Etapa 3, para descobrir recursos personalizados existentes do Arc e Arc Data Services. Em seguida, prossiga para destruir todos os recursos Arc e Arc Data na ordem inversa da implantação, bem como CRDs, Role/ClusterRoles, PV/PVCs etc.
Tente usar o token
LOGS_STORAGE_ACCOUNT_SASSAS fornecido para criar um novo contêiner de Conta de Armazenamento nomeado com base emLOGS_STORAGE_CONTAINER, na ContaLOGS_STORAGE_ACCOUNTde Armazenamento pré-existente. Se o contêiner Conta de Armazenamento já existir, use-o. Carregue todos os resultados e logs de testes locais para este contêiner de armazenamento como um tarball (veja abaixo).Sair.
Testes realizados por conjunto de testes
Há aproximadamente 375 testes de integração exclusivos disponíveis, em 27 suítes de teste - cada uma testando uma funcionalidade separada.
| Suite # | Nome do conjunto de testes | Descrição do teste |
|---|---|---|
| 5 | ad-connector |
Testa a implantação e a atualização de um Ative Directory Connector (AD Connector). |
| 2 | billing |
O teste de vários tipos de licença Business Critical é refletido na tabela de recursos no controlador, usada para upload de faturamento. |
| 3 | ci-billing |
Semelhante ao billing, mas com mais permutações de CPU/Memória. |
| 4 | ci-sqlinstance |
Testes de longa duração para criação de várias réplicas, atualizações, GP -> BC Update, validação de backup e SQL Server Agent. |
| 5 | controldb |
Banco de dados de controle de testes - verificação secreta SA, verificação de login do sistema, criação de auditoria e verificações de sanidade para a versão de compilação SQL. |
| 6 | dc-export |
Faturação do modo indireto e carregamento de utilização. |
| 7 | direct-crud |
Cria uma instância SQL usando chamadas ARM, valida em Kubernetes e ARM. |
| 8 | direct-fog |
Cria várias instâncias SQL e cria um Grupo de Failover entre elas usando chamadas ARM. |
| 9 | direct-hydration |
Cria instância SQL com API do Kubernetes, valida presença em ARM. |
| 10 | direct-upload |
Valida o carregamento de faturação no Modo Direto |
| 11 | kube-rbac |
Garante que as permissões da Conta de Serviço do Kubernetes para Arc Data Services correspondam às expectativas de privilégios mínimos. |
| 12 | nonroot |
Garante que os contêineres sejam executados como usuário não-root |
| 13 | postgres |
Conclui vários testes de criação, dimensionamento e backup/restauração do Postgres. |
| 14 | release-sanitychecks |
Verificações de sanidade para versões mensais, como versões do SQL Server Build. |
| 15 | sqlinstance |
Versão mais curta do ci-sqlinstance, para validações rápidas. |
| 16 | sqlinstance-ad |
Testa a criação de instâncias SQL com o Ative Directory Connector. |
| 17 | sqlinstance-credentialrotation |
Testa a rotação automatizada de credenciais para fins gerais e críticos para os negócios. |
| 18 | sqlinstance-ha |
Vários testes de estresse de alta disponibilidade, incluindo reinicializações de pods, failovers forçados e suspensões. |
| 19 | sqlinstance-tde |
Vários testes de criptografia de dados transparentes. |
| 20 | telemetry-elasticsearch |
Valida a ingestão de log no Elasticsearch. |
| 21 | telemetry-grafana |
Valida que o Grafana está acessível. |
| 22 | telemetry-influxdb |
Valida a ingestão de métricas no InfluxDB. |
| 23 | telemetry-kafka |
Vários testes para Kafka usando SSL, configuração de corretor único / multi-corretor. |
| 24 | telemetry-monitorstack |
Testes Componentes de monitoramento, como Fluentbit e Collectd são funcionais. |
| 25 | telemetry-telemetryrouter |
Testa Telemetria Aberta. |
| 26 | telemetry-webhook |
Testa Webhooks de Serviços de Dados com chamadas válidas e inválidas. |
| 27 | upgrade-arcdata |
Atualiza um conjunto completo de instâncias SQL (GP, réplica BC 2, réplica BC 3, com Ative Directory) e atualiza da versão do mês passado para a compilação mais recente. |
Por exemplo, para sqlinstance-hao , são realizados os seguintes testes:
test_critical_configmaps_present: Garante que o ConfigMaps e os campos relevantes estejam presentes para uma instância SQL.test_suspended_system_dbs_auto_heal_by_orchestrator: Garante semasteremsdbsão suspensos por qualquer meio (neste caso, usuário). A manutenção do orquestrador reconcilia-o automaticamente.test_suspended_user_db_does_not_auto_heal_by_orchestrator: Garante que, se um banco de dados de usuários for deliberadamente suspenso pelo usuário, a reconciliação de manutenção do Orchestrator não o recuperará automaticamente.test_delete_active_orchestrator_twice_and_delete_primary_pod: Exclui o pod do orchestrator várias vezes, seguido pela réplica primária, e verifica se todas as réplicas estão sincronizadas. As expectativas de tempo de failover para 2 réplicas são relaxadas.test_delete_primary_pod: Exclui a réplica primária e verifica se todas as réplicas estão sincronizadas. As expectativas de tempo de failover para 2 réplicas são relaxadas.test_delete_primary_and_orchestrator_pod: Exclui a réplica primária e o pod do orquestrador e verifica se todas as réplicas estão sincronizadas.test_delete_primary_and_controller: Exclui a réplica primária e o pod do controlador de dados e verifica se o ponto de extremidade primário está acessível e se a nova réplica primária está sincronizada. As expectativas de tempo de failover para 2 réplicas são relaxadas.test_delete_one_secondary_pod: Exclui a réplica secundária e o pod do controlador de dados e verifica se todas as réplicas estão sincronizadas.test_delete_two_secondaries_pods: Exclui réplicas secundárias e pod do controlador de dados e verifica se todas as réplicas estão sincronizadas.test_delete_controller_orchestrator_secondary_replica_pods:test_failaway: Força o failover AG para longe do primário atual, garante que o novo primário não seja o mesmo que o primário antigo. Verifica se todas as réplicas estão sincronizadas.test_update_while_rebooting_all_non_primary_replicas: Testes As atualizações orientadas pelo controlador são resilientes com novas tentativas, apesar de várias circunstâncias turbulentas.
Nota
Alguns testes podem exigir hardware específico, como acesso privilegiado a controladores de domínio para ad testes de criação de conta e entrada de DNS - que pode não estar disponível em todos os ambientes que desejam usar o arc-ci-launcher.
Examinando os resultados dos testes
Um contêiner de armazenamento de amostra e arquivo carregado pelo iniciador:
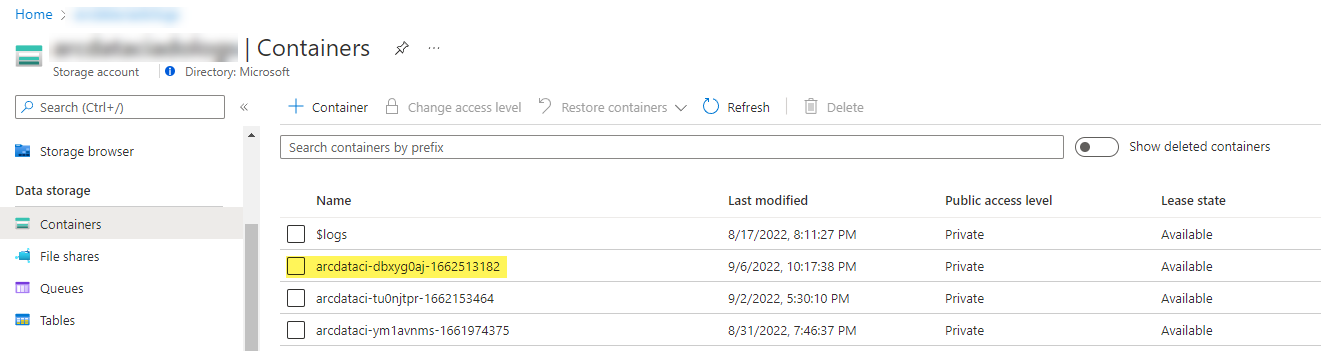
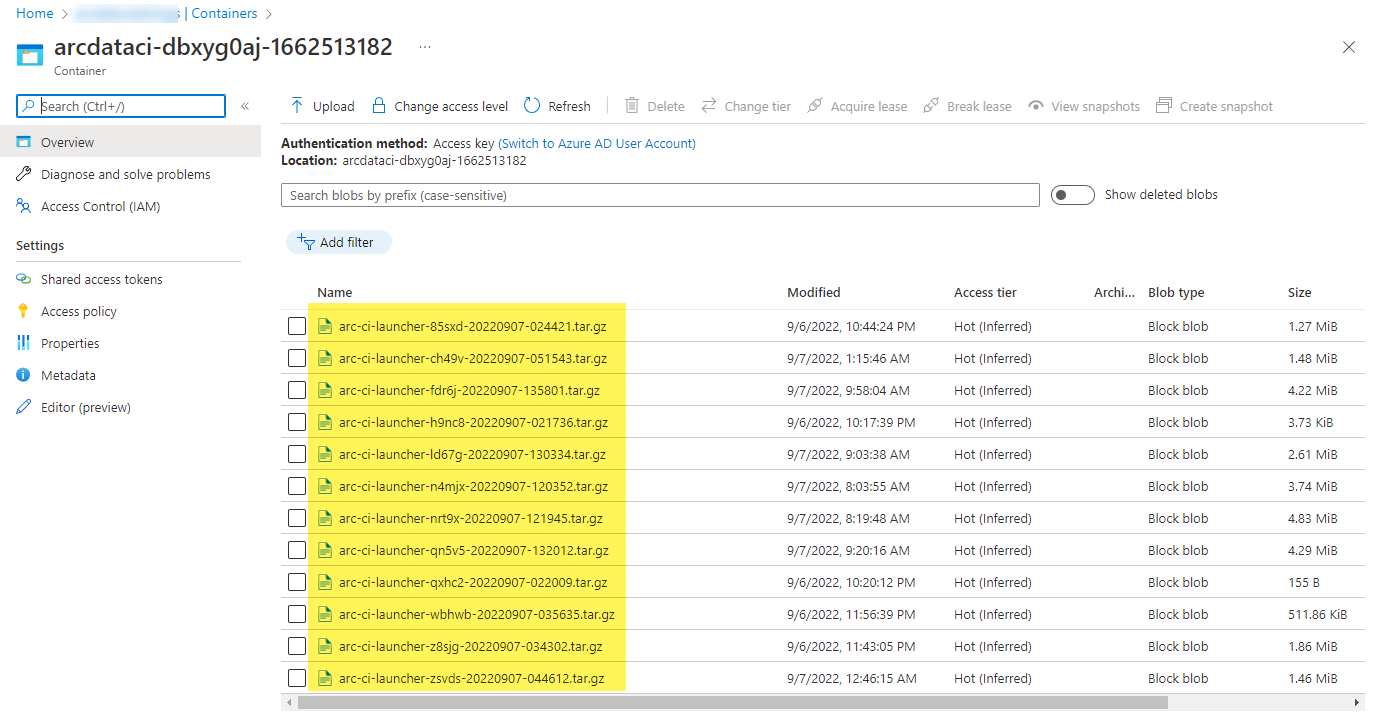
E os resultados do teste gerados a partir da corrida:
Clean up resources (Limpar recursos)
Para excluir o iniciador, execute:
kubectl delete -k arc_data_services/test/launcher/overlays/aks
Isso limpa os manifestos de recursos implantados como parte do iniciador.