Configurar grupo de failover - CLI
Este artigo explica como configurar a recuperação de desastres para a Instância Gerenciada SQL habilitada pelo Azure Arc com a CLI. Antes de continuar, revise as informações e os pré-requisitos na Instância Gerenciada SQL habilitada pelo Azure Arc - recuperação de desastres.
Pré-requisitos
Os seguintes pré-requisitos devem ser atendidos antes de configurar grupos de failover entre duas instâncias da Instância Gerenciada SQL habilitadas pelo Azure Arc:
- Um controlador de dados do Azure Arc e uma instância gerenciada SQL habilitada para Arc provisionada no site primário com
--license-typecomo um dosBasePriceouLicenseIncluded. - Um controlador de dados do Azure Arc e uma instância gerenciada SQL habilitada para Arc provisionada no site secundário com configuração idêntica à principal em termos de:
- CPU
- Memória
- Armazenamento
- Escalão de serviço
- Agrupamento
- Outras configurações de instância
- A instância no site secundário requer
--license-typecomoDisasterRecovery. Esta instância precisa ser nova, sem nenhum objeto de usuário.
Nota
- É importante especificar o
--license-typedurante a criação da instância gerenciada. Isso permitirá que a instância de DR seja semeada da instância primária no data center primário. A atualização desta propriedade após a implantação não terá o mesmo efeito.
Processo de implementação
Para configurar um grupo de failover do Azure entre duas instâncias, conclua as seguintes etapas:
- Criar recurso personalizado para o grupo de disponibilidade distribuída no site primário
- Criar recurso personalizado para o grupo de disponibilidade distribuída no site secundário
- Copie os dados binários dos certificados de espelhamento
- Configurar o grupo de disponibilidade distribuída entre os sites primário e secundário no modo ou
asyncnosyncmodo
A imagem a seguir mostra um grupo de disponibilidade distribuído configurado corretamente:
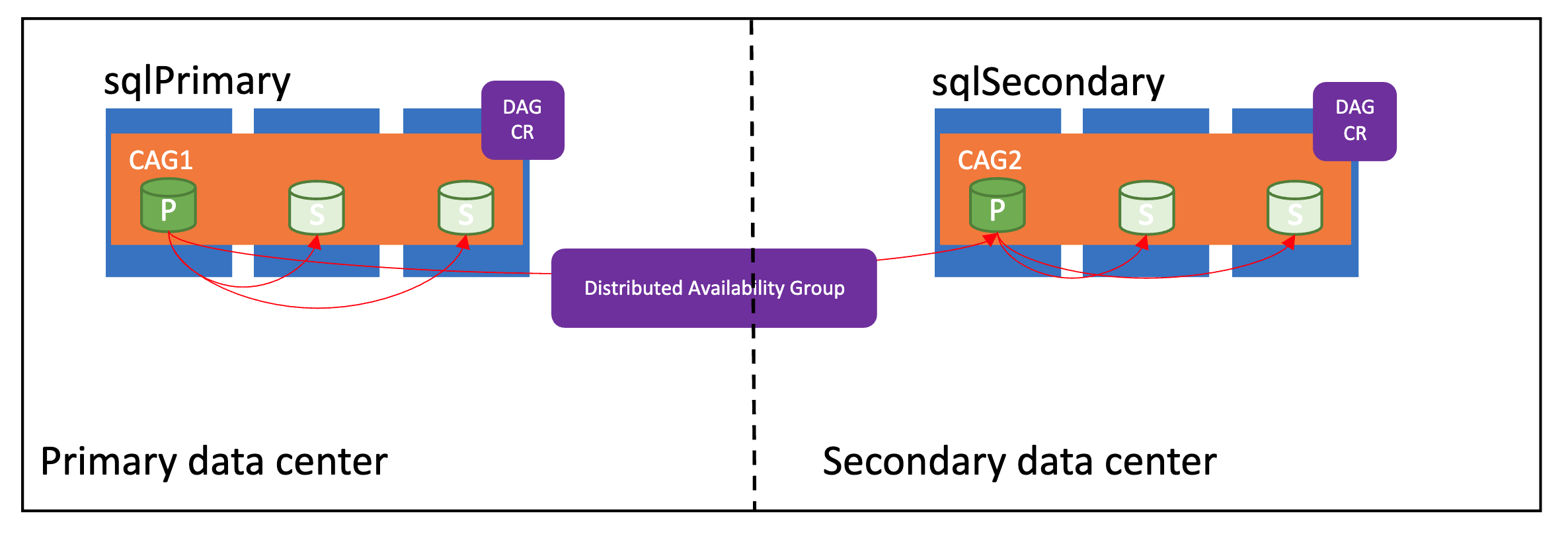
Modos de sincronização
Os grupos de failover nos serviços de dados do Azure Arc oferecem suporte a dois modos de sincronização - sync e async. O modo de sincronização afeta diretamente como os dados são sincronizados entre as instâncias e, potencialmente, o desempenho na instância gerenciada primária.
Se os locais primários e secundários estiverem a poucos quilômetros um do outro, use sync o modo. Caso contrário, use async o modo para evitar qualquer impacto no desempenho do site primário.
Configurar o grupo de failover do Azure - modo direto
Siga as etapas abaixo se os serviços de dados do Azure Arc forem implantados no directly modo conectado.
Quando os pré-requisitos forem atendidos, execute o comando abaixo para configurar o grupo de failover do Azure entre as duas instâncias:
az sql instance-failover-group-arc create --name <name of failover group> --mi <primary SQL MI> --partner-mi <Partner MI> --resource-group <name of RG> --partner-resource-group <name of partner MI RG>
Exemplo:
az sql instance-failover-group-arc create --name sql-fog --mi sql1 --partner-mi sql2 --resource-group rg-name --partner-resource-group rg-name
O comando acima:
- Cria os recursos personalizados necessários em sites primários e secundários
- Copia os certificados de espelhamento e configura o grupo de failover entre as instâncias
Configurar o grupo de failover do Azure - modo indireto
Siga as etapas abaixo se os serviços de dados do Azure Arc forem implantados no indirectly modo conectado.
Provisione a instância gerenciada no site primário.
az sql mi-arc create --name <primaryinstance> --tier bc --replicas 3 --k8s-namespace <namespace> --use-k8sAlterne o contexto para o cluster secundário executando
kubectl config use-context <secondarycluster>e provisionando a instância gerenciada no site secundário que será a instância de recuperação de desastre. Neste ponto, os bancos de dados do sistema não fazem parte do grupo de disponibilidade contido.Nota
É importante especificar
--license-type DisasterRecoverydurante a instância gerenciada. Isso permitirá que a instância de DR seja semeada da instância primária no data center primário. A atualização desta propriedade após a implantação não terá o mesmo efeito.az sql mi-arc create --name <secondaryinstance> --tier bc --replicas 3 --license-type DisasterRecovery --k8s-namespace <namespace> --use-k8sCertificados de espelhamento - Os dados binários dentro da propriedade Certificado de Espelhamento da instância gerenciada são necessários para a criação de CR (Recurso Personalizado) do Grupo de Failover de Instância.
Isto pode ser conseguido de algumas formas:
(a) Se estiver usando
aza CLI, gere primeiro o arquivo de certificado de espelhamento e, em seguida, aponte para esse arquivo ao configurar o Grupo de Failover de Instância para que os dados binários sejam lidos do arquivo e copiados para a CR. Os arquivos cert não são necessários após a criação do grupo de failover.(b) Se estiver usando
kubectl, copie e cole diretamente os dados binários da CR da instância gerenciada no arquivo yaml que será usado para criar o Grupo de Failover de Instância.Utilizando a alínea a) acima:
Crie o arquivo de certificado de espelhamento para a instância principal:
az sql mi-arc get-mirroring-cert --name <primaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sExemplo:
az sql mi-arc get-mirroring-cert --name sqlprimary --cert-file $HOME/sqlcerts/sqlprimary.pem --k8s-namespace my-namespace --use-k8sConecte-se ao cluster secundário e crie o arquivo de certificado de espelhamento para instância secundária:
az sql mi-arc get-mirroring-cert --name <secondaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sExemplo:
az sql mi-arc get-mirroring-cert --name sqlsecondary --cert-file $HOME/sqlcerts/sqlsecondary.pem --k8s-namespace my-namespace --use-k8sDepois que os arquivos de certificado de espelhamento forem criados, copie o certificado da instância secundária para um caminho compartilhado/local no cluster de instância primária e vice-versa.
Crie o recurso de grupo de failover em ambos os sites.
Nota
Verifique se as instâncias SQL têm nomes diferentes para sites primários e secundários, e o
shared-namevalor deve ser idêntico em ambos os sites.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for primary failover group resource> --mi <local SQL managed instance name> --role primary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<secondary IP> --partner-mirroring-cert-file <secondary.pem> --k8s-namespace <namespace> --use-k8sExemplo:
az sql instance-failover-group-arc create --shared-name myfog --name primarycr --mi sqlinstance1 --role primary --partner-mi sqlinstance2 --partner-mirroring-url tcp://10.20.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance2.pem --k8s-namespace my-namespace --use-k8sNa instância secundária, execute o seguinte comando para configurar o recurso personalizado do grupo de failover. Neste caso, o deve apontar para um caminho que tenha o arquivo de certificado de espelhamento gerado a partir da instância primária,
--partner-mirroring-cert-fileconforme descrito em 3(a) acima.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for secondary failover group resource> --mi <local SQL managed instance name> --role secondary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<primary IP> --partner-mirroring-cert-file <primary.pem> --k8s-namespace <namespace> --use-k8sExemplo:
az sql instance-failover-group-arc create --shared-name myfog --name secondarycr --mi sqlinstance2 --role secondary --partner-mi sqlinstance1 --partner-mirroring-url tcp://10.10.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance1.pem --k8s-namespace my-namespace --use-k8s
Recuperar o estado de integridade do grupo de failover do Azure
As informações sobre o grupo de failover, como função primária, função secundária e o status de integridade atual, podem ser exibidas no recurso personalizado no site primário ou secundário.
Execute o comando abaixo no site primário e/ou secundário para listar o recurso personalizado dos grupos de failover:
kubectl get fog -n <namespace>
Descreva o recurso personalizado para recuperar o status do grupo de failover, da seguinte maneira:
kubectl describe fog <failover group cr name> -n <namespace>
Operações do grupo de ativação pós-falha
Depois que o grupo de failover é configurado entre as instâncias gerenciadas, diferentes operações de failover podem ser executadas, dependendo das circunstâncias.
Os possíveis cenários de failover são:
As instâncias em ambos os locais estão em estado íntegro e um failover precisa ser executado:
- execute um failover manual do primário para o secundário sem perda de dados definindo
role=secondaryno SQL MI primário.
- execute um failover manual do primário para o secundário sem perda de dados definindo
O site primário não está íntegro/inacessível e um failover precisa ser executado:
- a Instância Gerenciada SQL primária habilitada pelo Azure Arc está inativa/não íntegra/inacessível
- a Instância Gerenciada SQL secundária habilitada pelo Azure Arc precisa ser promovida à força para primária com potencial perda de dados
- quando a Instância Gerenciada SQL primária original habilitada pelo Azure Arc voltar a ficar online, ela será relatada como
Primaryfunção e estado não íntegro e precisará ser forçada a umasecondaryfunção para que possa ingressar no grupo de failover e os dados possam ser sincronizados.
Failover manual (sem perda de dados)
Use az sql instance-failover-group-arc update ... o grupo de comandos para iniciar um failover do primário para o secundário. Todas as transações pendentes na instância geoprimária são replicadas para a instância geosecundária antes do failover.
Modo conectado diretamente
Execute o seguinte comando para iniciar um failover manual, no direct modo conectado usando APIs ARM:
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <primary instance> --role secondary --resource-group <resource group>
Exemplo:
az sql instance-failover-group-arc update --name myfog --mi sqlmi1 --role secondary --resource-group myresourcegroup
Modo conectado indiretamente
Execute o seguinte comando para iniciar um failover manual, no indirect modo conectado usando APIs do kubernetes:
az sql instance-failover-group-arc update --name <name of failover group resource> --role secondary --k8s-namespace <namespace> --use-k8s
Exemplo:
az sql instance-failover-group-arc update --name myfog --role secondary --k8s-namespace my-namespace --use-k8s
Failover forçado com perda de dados
Na circunstância em que a instância geoprimária se torna indisponível, os comandos a seguir podem ser executados na instância de DR geosecundária para promover a primária com um failover forçado incorrendo em perda potencial de dados.
Na instância de DR geosecundária, execute o seguinte comando para promovê-la à função principal, com perda de dados.
Nota
Se o foi configurado como sync, ele precisa ser redefinido para async quando o --partner-sync-mode secundário é promovido a primário.
Modo conectado diretamente
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <instance> --role force-primary-allow-data-loss --resource-group <resource group> --partner-sync-mode async
Exemplo:
az sql instance-failover-group-arc update --name myfog --mi sqlmi2 --role force-primary-allow-data-loss --resource-group myresourcegroup --partner-sync-mode async
Modo conectado indiretamente
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-primary-allow-data-loss --partner-sync-mode async
Quando a instância geoprimária estiver disponível, execute o comando abaixo para trazê-la para o grupo de failover e sincronizar os dados:
Modo conectado diretamente
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <old primary instance> --role force-secondary --resource-group <resource group>
Modo conectado indiretamente
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-secondary
Opcionalmente, o --partner-sync-mode pode ser configurado de volta ao sync modo, se desejado.
Operações pós-failover
Depois de executar um failover do site primário para o site secundário, com ou sem perda de dados, talvez seja necessário fazer o seguinte:
- Atualize a cadeia de conexão para que seus aplicativos se conectem à instância gerenciada primária do Arc SQL recém-promovida
- Se você planeja continuar executando a carga de trabalho de produção fora do site secundário, atualize o para ou
LicenseIncludedBasePriceinicie o--license-typefaturamento dos vCores consumidos.