Configurar a coleta de dados e a otimização de custos no Container insights usando a regra de coleta de dados
Este artigo descreve como configurar a coleta de dados no Container insights usando a regra de coleta de dados (DCR) para seu cluster Kubernetes. Isso inclui configurações predefinidas para otimizar seus custos. Uma DCR é criada quando você integra um cluster ao Container insights. Esse DCR é usado pelo agente conteinerizado para definir a coleta de dados para o cluster.
O DCR é usado principalmente para configurar a coleta de dados de desempenho e inventário e para configurar a otimização de custos.
A configuração específica que você pode executar com o DCR inclui:
- Habilite/desabilite a coleta e a filtragem de namespace para dados de desempenho e inventário.
- Definir intervalo de coleta para dados de desempenho e inventário
- Ativar/desativar a coleção Syslog
- Selecionar esquema de log
Importante
A configuração completa da coleta de dados no Container insights pode exigir a edição do DCR e do ConfigMap para o cluster, uma vez que cada método permite a configuração de um conjunto diferente de configurações.
Consulte Configurar a coleta de dados no Container insights usando o ConfigMap para obter uma lista de configurações e o processo para configurar a coleta de dados usando o ConfigMap. Os clientes não devem excluir ou editar manualmente seu recurso DCR.
Pré-requisitos
- Os clusters AKS devem usar uma identidade gerenciada atribuída pelo sistema ou pelo usuário. Se o cluster estiver usando uma entidade de serviço, você deverá atualizá-lo para usar uma identidade gerenciada atribuída pelo sistema ou uma identidade gerenciada atribuída pelo usuário.
Configurar a recolha de dados
O DCR que é criado quando você habilita Insights de contêiner é chamado MSCI-cluster-region-cluster-name><><. Você pode exibi-lo no portal do Azure selecionando a opção Regras de Coleta de Dados no menu Monitor no portal do Azure. Em vez de modificar diretamente o DCR, você deve usar um dos métodos descritos abaixo para configurar a coleta de dados. Consulte Parâmetros de coleta de dados para obter detalhes sobre as diferentes configurações disponíveis usadas por cada método.
Aviso
A experiência padrão do Container insights depende de todos os fluxos de dados existentes. A remoção de um ou mais fluxos padrão torna a experiência de insights do contêiner indisponível, e você precisa usar outras ferramentas, como painéis do Grafana e consultas de log para analisar os dados coletados.
Você pode usar o portal do Azure para habilitar a otimização de custos em seu cluster existente depois que o Container insights tiver sido habilitado, ou você pode habilitar o Container insights no cluster junto com a otimização de custos.
Selecione o cluster no portal do Azure.
Selecione a opção Insights na seção Monitoramento do menu.
Se o Container insights já tiver sido habilitado no cluster, selecione o botão Configurações de monitoramento . Caso contrário, selecione Configurar o Azure Monitor e consulte Habilitar monitoramento em seu cluster Kubernetes com o Azure Monitor para obter detalhes sobre como habilitar o monitoramento.
Para Kubernetes habilitados para AKS e Arc, selecione Usar identidade gerenciada se ainda não tiver migrado o cluster para autenticação de identidade gerenciada.
Selecione uma das predefinições de custo descritas em Predefinições de custo.
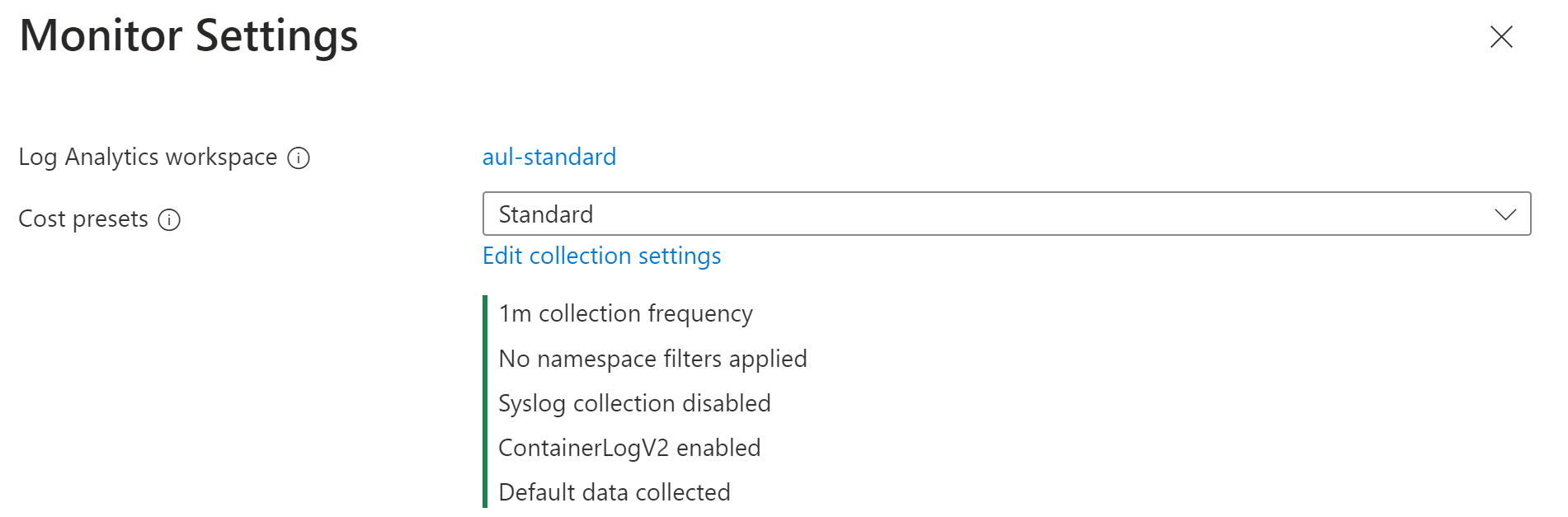
Se quiser personalizar as configurações, clique em Editar configurações de coleção. Consulte Parâmetros de coleta de dados para obter detalhes sobre cada configuração. Para Dados coletados, consulte Dados coletados abaixo.
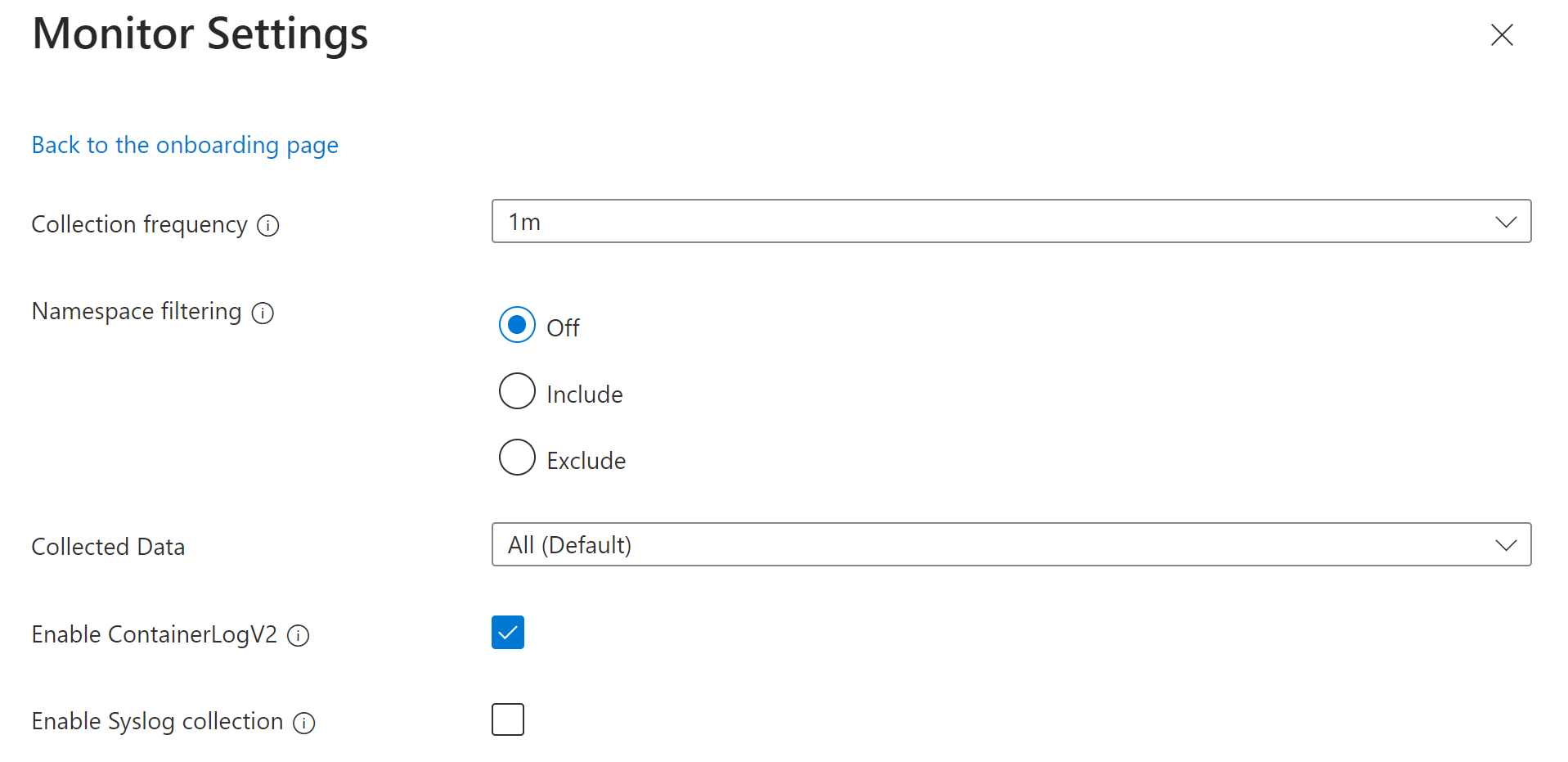
Clique em Configurar para salvar as configurações.



Predefinições de custo
Ao usar o portal do Azure para configurar a otimização de custos, você pode selecionar entre as seguintes configurações predefinidas. Você pode selecionar um deles ou fornecer suas próprias configurações personalizadas. Por padrão, o Container insights usa a predefinição Padrão .
| Predefinição de custo | Frequência da recolha | Filtros de namespace | Coleção Syslog | Dados recolhidos |
|---|---|---|---|---|
| Standard | 1 milh | Nenhuma | Não ativado | Todas as tabelas de insights de contêiner padrão |
| Custo otimizado | 5 metros | Exclui kube-system, gatekeeper-system, azure-arc | Não ativado | Todas as tabelas de insights de contêiner padrão |
| Syslog | 1 milh | Nenhuma | Ativado por predefinição | Todas as tabelas de insights de contêiner padrão |
| Logs e eventos | 1 milh | Nenhuma | Não ativado | ContainerLog/ContainerLogV2 KubeEvents KubePodInventory |
Dados recolhidos
A opção Dados coletados permite selecionar as tabelas que são preenchidas para o cluster. Este é o equivalente ao streams parâmetro ao executar a configuração com CLI ou ARM. Se você selecionar qualquer opção diferente de Todos (Padrão), a experiência de insights do contêiner ficará indisponível e você deverá usar o Grafana ou outros métodos para analisar os dados coletados.

| Agrupamento | Tabelas | Notas |
|---|---|---|
| Tudo (padrão) | Todas as tabelas de insights de contêiner padrão | Necessário para habilitar as visualizações padrão do Container insights |
| Desempenho | Perf, InsightsMetrics | |
| Logs e eventos | ContainerLog ou ContainerLogV2, KubeEvents, KubePodInventory | Recomendado se você tiver ativado as métricas gerenciadas do Prometheus |
| Cargas de trabalho, implantações e HPAs | InsightsMetrics, KubePodInventory, KubeEvents, ContainerInventory, ContainerNodeInventory, KubeNodeInventory, KubeServices | |
| Volumes Persistentes | InsightsMetrics, KubePVInventory |
Parâmetros de recolha de dados
A tabela a seguir descreve as configurações de coleta de dados suportadas e o nome usado para cada uma para diferentes opções de integração.
| Nome | Descrição |
|---|---|
| Frequência da recolha CLI: intervalBRAÇO: dataCollectionInterval |
Determina a frequência com que o agente coleta dados. Os valores válidos são 1m - 30m em intervalos de 1m O valor padrão é 1m. Se o valor estiver fora do intervalo permitido, o padrão será 1 m. |
| Filtragem de namespace CLI: namespaceFilteringModeBRAÇO: namespaceFilteringModeForDataCollection |
Include: Coleta apenas dados dos valores no campo namespaces . Excluir: coleta dados de todos os namespaces, exceto os valores no campo namespaces . Desativado: ignora todas as seleções de namespace e coleta dados em todos os namespaces. |
| Filtragem de namespace CLI: namespacesBRAÇO: namespacesForDataCollection |
Matriz de namespaces Kubernetes separados por vírgulas para coletar dados de inventário e perf com base no namespaceFilteringMode. Por exemplo, namespaces = ["kube-system", "default"] com uma configuração Include coleta apenas esses dois namespaces. Com uma configuração Exclude , o agente coleta dados de todos os outros namespaces, exceto kube-system e default. Com uma configuração Off , o agente coleta dados de todos os namespaces, incluindo kube-system e default. Namespaces inválidos e não reconhecidos são ignorados. |
| Ativar ContainerLogV2 CLI: enableContainerLogV2BRAÇO: enableContainerLogV2 |
Sinalizador booleano para habilitar o esquema ContainerLogV2. Se definido como true, os logs stdout/stderr são ingeridos na tabela ContainerLogV2 . Caso contrário, os logs de contêiner são ingeridos na tabela ContainerLog , a menos que especificado de outra forma no ConfigMap. Ao especificar os fluxos individuais, você deve incluir a tabela correspondente para ContainerLog ou ContainerLogV2. |
| Dados Recolhidos CLI: streamsBRAÇO: streams |
Uma matriz de fluxos de tabela de informações de contêiner. Veja os fluxos suportados acima para mapeamento de tabela. |
Tabelas e métricas aplicáveis
As configurações de frequência de coleta e filtragem de namespace não se aplicam a todos os dados do Container insights. As tabelas a seguir listam as tabelas no espaço de trabalho do Log Analytics usado pelo Container insights e as métricas que ele coleta, juntamente com as configurações que se aplicam a cada um.
Nota
Esse recurso define as configurações de todas as tabelas de insights de contêiner, exceto ContainerLog e ContainerLogV2. Para definir as configurações dessas tabelas, atualize o ConfigMap descrito nas configurações de coleta de dados do agente.
| Nome da tabela | Intervalo? | Namespaces? | Observações |
|---|---|---|---|
| ContainerInventory | Sim | Sim | |
| ContainerNodeInventory | Sim | No | A configuração de coleta de dados para namespaces não é aplicável, pois o Nó Kubernetes não é um recurso com escopo de namespace |
| KubeNodeInventory | Sim | No | A configuração de coleta de dados para namespaces não é aplicável O nó Kubernetes não é um recurso com escopo de namespace |
| KubePodInventory | Sim | Sim | |
| KubePVInventory | Sim | Sim | |
| KubeServices | Sim | Sim | |
| KubeEvents | Não | Sim | A configuração de coleta de dados para intervalo não é aplicável aos Eventos do Kubernetes |
| Perf | Sim | Sim | A configuração de coleta de dados para namespaces não é aplicável para as métricas relacionadas ao Nó Kubernetes, pois o Nó Kubernetes não é um objeto com escopo de namespace. |
| InsightsMetrics | Sim | Sim | As configurações de coleta de dados só são aplicáveis para as métricas que coletam os seguintes namespaces: container.azm.ms/kubestate, container.azm.ms/pv e container.azm.ms/gpu |
| Espaço de nomes de métricas | Intervalo? | Namespaces? | Observações |
|---|---|---|---|
| Insights.container/nós | Sim | No | O nó não é um recurso com escopo de namespace |
| Insights.container/pods | Sim | Sim | |
| Insights.container/containers | Sim | Sim | |
| Insights.container/persistentvolumes | Sim | Sim |
Valores de fluxo
Ao especificar as tabelas a serem coletadas usando CLI ou ARM, você especifica um nome de fluxo que corresponde a uma tabela específica no espaço de trabalho do Log Analytics. A tabela a seguir lista o nome do fluxo para cada tabela.
Nota
Se você estiver familiarizado com a estrutura de uma regra de coleta de dados, os nomes de fluxo nesta tabela serão especificados na seção dataFlows do DCR.
| Fluxo | Tabela de informações do contêiner |
|---|---|
| Microsoft-ContainerInventory | ContainerInventory |
| Microsoft-ContainerLog | ContainerLog |
| Microsoft-ContainerLogV2 | ContainerLogV2 |
| Microsoft-ContainerNodeInventory | ContainerNodeInventory |
| Microsoft-InsightsMetrics | InsightsMetrics |
| Microsoft-KubeEventos | KubeEvents |
| Microsoft-KubeMonAgentEvents | KubeMonAgentEventos |
| Microsoft-KubeNodeInventory | KubeNodeInventory |
| Microsoft-KubePodInventory | KubePodInventory |
| Microsoft-KubePVInventory | KubePVInventory |
| Microsoft-KubeServices | KubeServices |
| Microsoft-Perf | Perf |
Impacto em visualizações e alertas
Se você estiver usando as tabelas acima para outros alertas ou gráficos personalizados, modificar suas configurações de coleta de dados pode degradar essas experiências. Se você estiver excluindo namespaces ou reduzindo a frequência de coleta de dados, revise seus alertas, painéis e pastas de trabalho existentes usando esses dados.
Para procurar alertas que façam referência a estas tabelas, execute a seguinte consulta do Azure Resource Graph:
resources
| where type in~ ('microsoft.insights/scheduledqueryrules') and ['kind'] !in~ ('LogToMetric')
| extend severity = strcat("Sev", properties["severity"])
| extend enabled = tobool(properties["enabled"])
| where enabled in~ ('true')
| where tolower(properties["targetResourceTypes"]) matches regex 'microsoft.operationalinsights/workspaces($|/.*)?' or tolower(properties["targetResourceType"]) matches regex 'microsoft.operationalinsights/workspaces($|/.*)?' or tolower(properties["scopes"]) matches regex 'providers/microsoft.operationalinsights/workspaces($|/.*)?'
| where properties contains "Perf" or properties contains "InsightsMetrics" or properties contains "ContainerInventory" or properties contains "ContainerNodeInventory" or properties contains "KubeNodeInventory" or properties contains"KubePodInventory" or properties contains "KubePVInventory" or properties contains "KubeServices" or properties contains "KubeEvents"
| project id,name,type,properties,enabled,severity,subscriptionId
| order by tolower(name) asc
Próximos passos
- Consulte Configurar a coleta de dados no Container insights usando o ConfigMap para configurar a coleta de dados usando o ConfigMap em vez do DCR.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários