Monitorar máquinas virtuais com o Azure Monitor: Alertas
Este artigo faz parte do guia Monitorar máquinas virtuais e suas cargas de trabalho no Azure Monitor. Os alertas no Azure Monitor notificam proativamente sobre dados e padrões interessantes em seus dados de monitoramento. Não há regras de alerta pré-configuradas para máquinas virtuais, mas você pode criar suas próprias com base nos dados coletados do Azure Monitor Agent. Este artigo apresenta conceitos de alerta específicos para máquinas virtuais e regras de alerta comuns usadas por outros clientes do Azure Monitor.
Este cenário descreve como implementar o monitoramento completo do seu Azure e do ambiente de máquina virtual híbrida:
Para começar a monitorar sua primeira máquina virtual do Azure, consulte Monitorar máquinas virtuais do Azure.
Para habilitar rapidamente um conjunto recomendado de alertas, consulte Habilitar regras de alerta recomendadas para uma máquina virtual do Azure.
Importante
A maioria das regras de alerta tem um custo que depende do tipo de regra, de quantas dimensões ela inclui e da frequência com que é executada. Antes de criar regras de alerta, consulte a seção Regras de alerta em Preços do Azure Monitor.
Recolha de dados
As regras de alerta inspecionam dados que já foram coletados no Azure Monitor. Você precisa garantir que os dados estão sendo coletados para um cenário específico antes de criar uma regra de alerta. Consulte Monitorar máquinas virtuais com o Azure Monitor: coletar dados para obter orientação sobre como configurar a coleta de dados para vários cenários, incluindo todas as regras de alerta neste artigo.
Regras de alerta recomendadas
O Azure Monitor fornece um conjunto de regras de alerta recomendadas que você pode habilitar rapidamente para qualquer máquina virtual do Azure. Essas regras são um ótimo ponto de partida para o monitoramento básico. Mas, sozinhos, eles não fornecerão alertas suficientes para a maioria das implementações corporativas pelos seguintes motivos:
- Os alertas recomendados aplicam-se apenas a máquinas virtuais do Azure e não a máquinas híbridas.
- Os alertas recomendados incluem apenas métricas de host e não métricas ou logs de convidados. Essas métricas são úteis para monitorar a integridade da própria máquina. Mas eles oferecem visibilidade mínima das cargas de trabalho e dos aplicativos em execução na máquina.
- Os alertas recomendados estão associados a máquinas individuais que criam um número excessivo de regras de alerta. Em vez de confiar nesse método para cada máquina, consulte Dimensionamento de regras de alerta para estratégias de uso de um número mínimo de regras de alerta para várias máquinas.
Tipos de alerta
Os tipos mais comuns de regras de alerta no Azure Monitor são alertas de métrica e alertas de pesquisa de log. O tipo de regra de alerta que você cria para um cenário específico depende de onde os dados que você está alertando estão localizados.
Você pode ter casos em que os dados de um cenário de alerta específico estão disponíveis em Métricas e Logs. Em caso afirmativo, você precisa determinar qual tipo de regra usar. Você também pode ter flexibilidade na forma como coleta determinados dados e deixar que sua decisão de tipo de regra de alerta oriente sua decisão pelo método de coleta de dados.
Alertas de métricas
Usos comuns para alertas métricos:
- Alertar quando uma determinada métrica exceder um limite. Um exemplo é quando a CPU de uma máquina está em alta.
Fontes de dados para alertas métricos:
- Métricas de host para máquinas virtuais do Azure, que são coletadas automaticamente
- Métricas coletadas pelo Azure Monitor Agent do sistema operacional convidado
Alertas de pesquisa de registo
Usos comuns para alertas de pesquisa de log:
- Alerte quando um determinado evento ou padrão de eventos do log de eventos do Windows ou Syslog for encontrado. Essas regras de alerta geralmente medem as linhas da tabela retornadas da consulta.
- Alerta com base em um cálculo de dados numéricos em várias máquinas. Essas regras de alerta normalmente medem o cálculo de uma coluna numérica nos resultados da consulta.
Fontes de dados para alertas de pesquisa de log:
- Todos os dados coletados em um espaço de trabalho do Log Analytics
Dimensionamento de regras de alerta
Como você pode ter muitas máquinas virtuais que exigem o mesmo monitoramento, não precisa criar regras de alerta individuais para cada uma. Você também deseja garantir que haja diferentes estratégias para limitar o número de regras de alerta que você precisa gerenciar, dependendo do tipo de regra. Cada uma dessas estratégias depende da compreensão do recurso de destino da regra de alerta.
Regras de alerta de métricas
As máquinas virtuais oferecem suporte a várias regras de alerta de métricas de recursos, conforme descrito em Monitorar vários recursos. Esse recurso permite criar uma única regra de alerta de métrica que se aplica a todas as máquinas virtuais em um grupo de recursos ou assinatura dentro da mesma região.
Comece com os alertas recomendados e crie uma regra correspondente para cada um usando sua assinatura ou um grupo de recursos como o recurso de destino. Você precisa criar regras duplicadas para cada região se tiver máquinas em várias regiões.
Ao identificar requisitos para mais regras de alerta de métricas, siga essa mesma estratégia usando uma assinatura ou grupo de recursos como recurso de destino para:
- Minimize o número de regras de alerta que você precisa gerenciar.
- Certifique-se de que eles são aplicados automaticamente a quaisquer máquinas novas.
Regras de alerta de pesquisa de log
Se você definir o recurso de destino de uma regra de alerta de pesquisa de log para uma máquina específica, as consultas serão limitadas aos dados associados a essa máquina, o que lhe dará alertas individuais para ela. Esta disposição requer uma regra de alerta separada para cada máquina.
Se você definir o recurso de destino de uma regra de alerta de pesquisa de log para um espaço de trabalho do Log Analytics, terá acesso a todos os dados nesse espaço de trabalho. Por esse motivo, você pode alertar sobre dados de todas as máquinas no grupo de trabalho com uma única regra. Esta disposição dá-lhe a opção de criar um único alerta para todas as máquinas. Em seguida, você pode usar dimensões para criar um alerta separado para cada máquina.
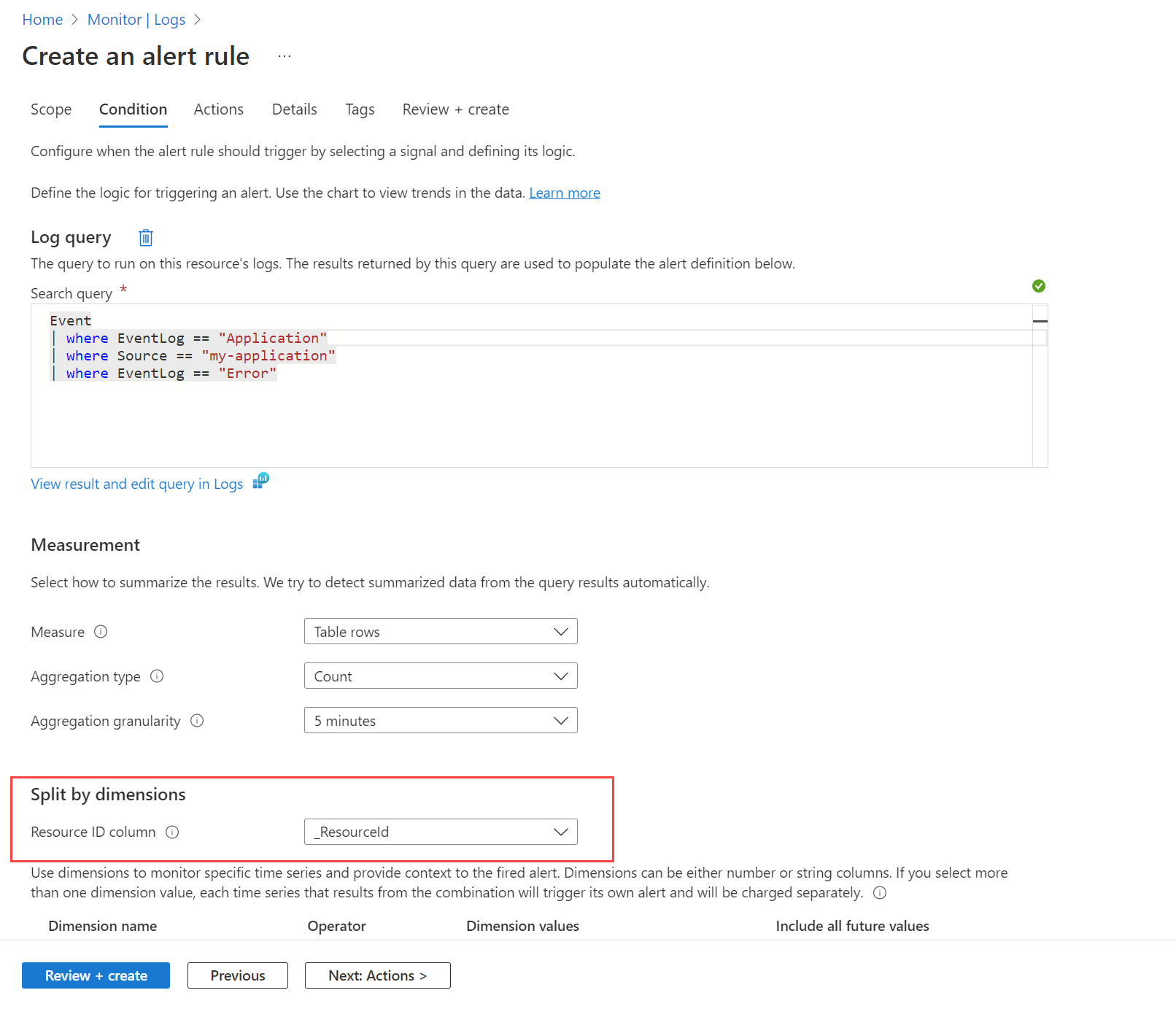
Por exemplo, talvez você queira alertar quando um evento de erro é criado no log de eventos do Windows por qualquer máquina. Primeiro, você precisa criar uma regra de coleta de dados conforme descrito em Coletar eventos e contadores de desempenho de máquinas virtuais com o Azure Monitor Agent para enviar esses eventos para a Event tabela no espaço de trabalho do Log Analytics. Em seguida, você cria uma regra de alerta que consulta essa tabela usando o espaço de trabalho como o recurso de destino e a condição mostrada na imagem a seguir.
A consulta retorna um registro para quaisquer mensagens de erro em qualquer máquina. Use a opção Dividir por dimensões e especifique _ResourceId para instruir a regra a criar um alerta para cada máquina se várias máquinas forem retornadas nos resultados.
Dimensões
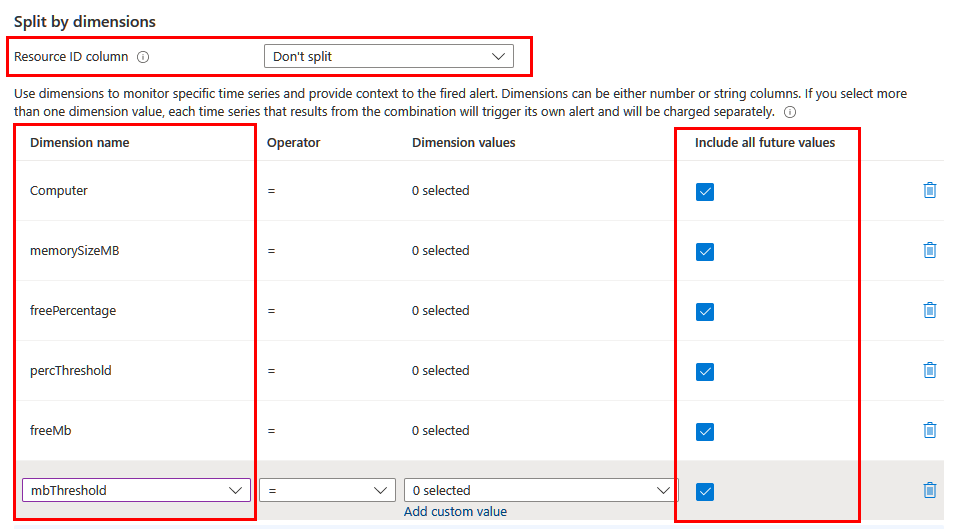
Dependendo das informações que você deseja incluir no alerta, talvez seja necessário dividir usando dimensões diferentes. Nesse caso, certifique-se de que as dimensões necessárias sejam projetadas na consulta usando o operador project ou extend . Defina o campo da coluna ID do recurso como Não dividir e inclua todas as dimensões significativas na lista. Certifique-se de que a opção Incluir todos os valores futuros está selecionada para que qualquer valor retornado da consulta seja incluído.
Limiares dinâmicos
Outro benefício do uso de regras de alerta de pesquisa de log é a capacidade de incluir lógica complexa na consulta para determinar o valor limite. Você pode codificar o limite, aplicá-lo a todos os recursos ou calculá-lo dinamicamente com base em algum campo ou valor calculado. O limiar só é aplicado aos recursos de acordo com condições específicas. Por exemplo, você pode criar um alerta com base na memória disponível, mas apenas para máquinas com uma determinada quantidade de memória total.
Regras de alertas comuns
A seção a seguir lista regras de alerta comuns para máquinas virtuais no Azure Monitor. Detalhes para alertas métricos e alertas de pesquisa de log são fornecidos para cada um. Para obter orientação sobre o tipo de alerta a ser usado, consulte Tipos de alerta. Se não estiver familiarizado com o processo de criação de regras de alerta no Azure Monitor, consulte as instruções para criar uma nova regra de alerta.
Nota
Os detalhes dos alertas de pesquisa de log fornecidos aqui estão usando dados coletados usando o VM Insights, que fornece um conjunto de contadores de desempenho comuns para o sistema operacional cliente. Esse nome é independente do tipo de sistema operacional.
Disponibilidade da máquina
Um dos requisitos de monitoramento mais comuns para uma máquina virtual é criar um alerta se ela parar de ser executada. O melhor método é criar uma regra de alerta de métrica no Azure Monitor usando a métrica de disponibilidade da VM, que está atualmente em visualização pública. Para obter um passo a passo sobre essa métrica, consulte Criar regra de alerta de disponibilidade para a máquina virtual do Azure.
Uma regra de alerta é limitada a um sinal de registro de atividades. Portanto, para cada condição, uma regra de alerta deve ser criada. Por exemplo, "inicia ou para a máquina virtual" requer duas regras de alerta. No entanto, para ser alertado quando a VM é reiniciada, apenas uma regra de alerta é necessária.
Conforme descrito em Regras de alerta de dimensionamento, crie uma regra de alerta de disponibilidade usando uma assinatura ou grupo de recursos como recurso de destino. A regra se aplica a várias máquinas virtuais, incluindo novas máquinas criadas após a regra de alerta.
Batimento cardíaco do agente
A pulsação do agente é ligeiramente diferente do alerta de indisponibilidade da máquina porque depende do Agente do Azure Monitor para enviar uma pulsação. A pulsação do agente pode alertá-lo se a máquina estiver em execução, mas o agente não estiver respondendo.
Regras de alerta de métricas
Uma métrica chamada Heartbeat é incluída em cada espaço de trabalho do Log Analytics. Cada máquina virtual conectada a esse espaço de trabalho envia um valor de métrica de pulsação a cada minuto. Como o computador é uma dimensão na métrica, você pode disparar um alerta quando qualquer computador não enviar uma pulsação. Defina o tipo de Agregação como Contagem e o valor de Limite para corresponder à granularidade da Avaliação.
Regras de alerta de pesquisa de log
Os alertas de pesquisa de log usam a tabela Heartbeat, que deve ter um registro de pulsação a cada minuto de cada máquina.
Use uma regra com a seguinte consulta:
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
Alertas da CPU
Esta seção descreve alertas de CPU.
Regras de alerta de métricas
| Destino | Metric |
|---|---|
| Host | Percentagem de CPU (incluída nos alertas recomendados) |
| Convidado do Windows | \Informações do processador(_Total)% Tempo do processador |
| Convidado Linux | CPU/usage_ative |
Regras de alerta de pesquisa de log
Utilização da CPU
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Alertas de memória
Esta seção descreve alertas de memória.
Regras de alerta de métricas
| Destino | Metric |
|---|---|
| Host | Bytes de memória disponíveis (visualização) (incluídos nos alertas recomendados) |
| Convidado do Windows | \Memória% de bytes comprometidos em uso \Memory\Available Bytes |
| Convidado Linux | mem/disponível mem/available_percent |
Regras de alerta de pesquisa de log
Memória disponível em MB
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Memória disponível em percentagem
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
Alertas de disco
Esta seção descreve alertas de disco.
Regras de alerta de métricas
| Destino | Metric |
|---|---|
| Convidado do Windows | \Disco lógico(_Total)% de espaço livre \Disco lógico(_Total)\Megabytes livres |
| Convidado Linux | disco/livre disco/free_percent |
Regras de alerta de pesquisa de log
Disco lógico usado - todos os discos em cada computador
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Disco lógico usado - discos individuais
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
IOPS de disco lógico
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Taxa de dados do disco lógico
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Alertas de rede
Regras de alerta de métricas
| Destino | Metric |
|---|---|
| Host | Rede no total, total de saída da rede (incluído nos alertas recomendados) |
| Convidado do Windows | \Interface de Rede\Bytes Enviados/s \Disco lógico(_Total)\Megabytes livres |
| Convidado Linux | disco/livre disco/free_percent |
Regras de alerta de pesquisa de log
Bytes de interfaces de rede recebidos - todas as interfaces
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Bytes de interfaces de rede recebidos - interfaces individuais
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Bytes de interfaces de rede enviados - todas as interfaces
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Bytes de interfaces de rede enviados - interfaces individuais
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Eventos Windows e Linux
O exemplo a seguir cria um alerta quando um evento específico do Windows é criado. Ele usa uma regra de alerta de medição métrica para criar um alerta separado para cada computador.
Crie uma regra de alerta em um evento específico do Windows. Este exemplo mostra um evento no log do aplicativo. Especifique um limiar de 0 e violações consecutivas superiores a 0.
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)Crie uma regra de alerta em eventos Syslog com uma gravidade específica. O exemplo a seguir mostra eventos de autorização de erro. Especifique um limiar de 0 e violações consecutivas superiores a 0.
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
Contadores de desempenho personalizados
Crie um alerta sobre o valor máximo de um contador.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by ComputerCrie um alerta sobre o valor médio de um contador.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer
Próximos passos
Analisar dados de monitoramento coletados para máquinas virtuais
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários