Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
A migração de bancos de dados de alto desempenho de nível Exadata para a nuvem está se tornando cada vez mais um imperativo para os clientes da Microsoft. Os pacotes de software da cadeia de suprimentos normalmente definem a barra alta devido às intensas demandas de E/S de armazenamento com uma carga de trabalho mista de leitura e gravação impulsionada por um único nó de computação. A infraestrutura do Azure em combinação com os Arquivos NetApp do Azure é capaz de atender às necessidades dessa carga de trabalho altamente exigente. Este artigo apresenta um exemplo de como essa demanda foi atendida para um cliente e como o Azure pode atender às demandas de suas cargas de trabalho críticas da Oracle.
Desempenho Oracle em escala empresarial
Ao explorar os limites superiores de desempenho, é importante reconhecer e reduzir quaisquer restrições que possam distorcer falsamente os resultados. Por exemplo, se a intenção for provar os recursos de desempenho de um sistema de armazenamento, o cliente deve idealmente ser configurado para que a CPU não se torne um fator atenuante antes que os limites de desempenho de armazenamento sejam atingidos. Para esse fim, os testes começaram com o tipo de instância E104ids_v5, pois essa VM vem equipada não apenas com uma interface de rede de 100 Gbps, mas com um limite de saída igualmente grande (100 Gbps).
Os testes ocorreram em duas fases:
- A primeira fase concentrou-se nos testes usando a ferramenta SLOB2 (Silly Little Oracle Benchmark) de Kevin Closson, agora padrão da indústria - versão 2.5.4. O objetivo é direcionar o máximo possível de E/S Oracle de uma máquina virtual (VM) para vários volumes do Azure NetApp Files e, em seguida, expandir usando mais bancos de dados para demonstrar o dimensionamento linear.
- Depois de testar os limites de escala, nossos testes mudaram para o E96ds_v5 mais barato, mas quase tão capaz, para uma fase de testes do cliente usando uma verdadeira carga de trabalho de aplicativos da cadeia de suprimentos e dados do mundo real.
Desempenho de ampliação SLOB2
Os gráficos a seguir capturam o perfil de desempenho de uma única VM E104ids_v5 do Azure executando um único banco de dados Oracle 19c utilizando oito volumes de Arquivos NetApp do Azure com oito endpoints de armazenamento. Os volumes estão distribuídos em três grupos de discos ASM: dados, log e arquivamento. Cinco volumes foram alocados para o grupo de discos de dados, dois volumes para o grupo de discos de log e um volume para o grupo de discos de arquivamento. Todos os resultados capturados ao longo deste artigo foram coletados usando regiões do Azure de produção e serviços ativos do Azure de produção.
Para implementar o Oracle em máquinas virtuais no Azure utilizando vários volumes do Azure NetApp Files em diferentes pontos de extremidade de armazenamento, use o grupo de volumes de aplicação para Oracle.
Arquitetura de host único
O diagrama a seguir mostra a arquitetura em que os testes foram realizados; observe o banco de dados Oracle distribuído por vários volumes e pontos de extremidade do Azure NetApp Files.

Entrada/saída de armazenamento para um único host
O diagrama a seguir apresenta uma carga de trabalho de 100% selecionada aleatoriamente com uma taxa de acertos no buffer do banco de dados de aproximadamente 8%. O SLOB2 foi capaz de gerar aproximadamente 850.000 solicitações de E/S por segundo, mantendo uma latência de evento de leitura sequencial de arquivo de banco de dados de submilissegundos. Com um tamanho de bloco de banco de dados de 8K que equivale a aproximadamente 6.800 MiB/s de taxa de transferência de armazenamento.

Capacidade de transferência de um só anfitrião
O diagrama a seguir demonstra que, para cargas de trabalho de E/S sequenciais com uso intensivo de largura de banda, como verificações de tabela completa ou atividades de RMAN, os Arquivos NetApp do Azure podem fornecer os recursos completos de largura de banda da própria VM E104ids_v5.

Observação
Como a instância de computação está no máximo teórico de sua largura de banda, adicionar simultaneidade de aplicativo adicional resulta apenas em maior latência do lado do cliente. Isso resulta em cargas de trabalho SLOB2 excedendo o prazo de conclusão pretendido, portanto, a contagem de threads foi limitada a seis.
Desempenho de expansão SLOB2
Os gráficos a seguir capturam o perfil de desempenho de três VMs E104ids_v5 Azure, cada uma executando um único banco de dados Oracle 19c e cada uma com seu próprio conjunto de volumes de Arquivos NetApp do Azure e um layout de grupo de discos ASM idêntico, conforme descrito na seção Aumentar o desempenho. Os gráficos mostram que, com o Azure NetApp Files em configuração multivolume/multi-ponto, o desempenho escala facilmente com consistência e previsibilidade.
Arquitetura multi-host
O diagrama a seguir mostra a arquitetura contra a qual o teste foi concluído; observe os três bancos de dados Oracle espalhados por vários volumes e pontos de extremidade do Azure NetApp Files. Os endpoints podem ser dedicados a um único host, conforme mostrado com o Oracle VM 1, ou compartilhados entre hosts, como mostrado com o Oracle VM2 e o Oracle VM 3.

E/S de armazenamento de vários hosts
O diagrama a seguir apresenta uma carga de trabalho de 100% selecionada aleatoriamente com uma taxa de acertos no buffer do banco de dados de aproximadamente 8%. O SLOB2 foi capaz de gerar aproximadamente 850.000 solicitações de E/S por segundo em todos os três hosts individualmente. O SLOB2 foi capaz de fazer isso enquanto processava simultaneamente um total coletivo de cerca de 2.500.000 solicitações de E/S por segundo, com cada host ainda mantendo uma latência inferior a um milissegundo para o evento de leitura sequencial de ficheiros de bases de dados. Com um tamanho de bloco de banco de dados de 8K, isso equivale a aproximadamente 20.000 MiB/s entre os três hosts.

Taxa de transferência de vários hosts
O diagrama a seguir demonstra que, para cargas de trabalho sequenciais, o Azure NetApp Files ainda pode fornecer toda a capacidade de largura de banda da própria VM E104ids_v5, mesmo quando ela é ampliada. O SLOB2 foi capaz de conduzir E/S totalizando mais de 30.000 MiB/s nos três hosts enquanto funcionava em paralelo.

Desempenho no mundo real
Depois que os limites de dimensionamento foram testados com SLOB2, os testes foram conduzidos com um pacote de aplicativos de cadeia de abastecimento do mundo real em conjunto com o Oracle em arquivos do Azure NetApp com excelentes resultados. Os dados a seguir do relatório Oracle Automatic Workload Repository (AWR) são uma visão destacada de como um trabalho crítico específico foi executado.
Esta base de dados possui atividade I/O significativa adicional em execução, além da carga de trabalho da aplicação, devido à funcionalidade de flashback estar ativada e possui um tamanho de bloco de base de dados de 16k. Na seção de perfil IO do relatório AWR, é evidente que há uma grande proporção de gravações em comparação com leituras.
| - | Ler e escrever por segundo | Leitura por segundo | Escrever por segundo |
|---|---|---|---|
| Total (MB) | 4,988.1 | 1,395.2 | 3,592.9 |
Apesar do evento de espera de leitura sequencial do arquivo db mostrar uma latência maior em 2,2 ms do que no teste SLOB2, esse cliente viu uma redução de quinze minutos no tempo de execução do trabalho vindo de um banco de dados RAC no Exadata para um banco de dados de instância única no Azure.
Restrições de recursos do Azure
Todos os sistemas acabam por atingir restrições de recursos, tradicionalmente conhecidas como pontos de estrangulamento. As cargas de trabalho de banco de dados, especialmente as altamente exigentes, como pacotes de aplicativos da cadeia de suprimentos, são entidades que consomem muitos recursos. Encontrar essas restrições de recursos e trabalhar com elas é vital para qualquer implantação bem-sucedida. Esta seção ilumina várias restrições que você pode esperar encontrar em tal ambiente e como trabalhar com elas. Em cada subseção, espere aprender as melhores práticas e a lógica por trás delas.
Máquinas virtuais
Esta seção detalha os critérios a serem considerados na seleção de VMs para melhor desempenho e a lógica por trás das seleções feitas para testes. Os Arquivos NetApp do Azure são um serviço NAS (Network Attached Storage, armazenamento conectado à rede), portanto, o dimensionamento adequado da largura de banda da rede é essencial para o desempenho ideal.
Conjuntos de Circuitos Integrados
O primeiro tópico de interesse é a seleção de chipsets. Certifique-se de que qualquer SKU de VM selecionada seja construída em um único chipset por motivos de consistência. A variante Intel de E_v5 VMs é executada em uma configuração Intel Xeon Platinum 8370C (Ice Lake) de terceira geração. Todas as VMs desta família vêm equipadas com uma única interface de rede de 100 Gbps. Em contraste, a série E_v3, mencionada a título de exemplo, é construída em quatro chipsets separados, com várias larguras de banda de rede física. Os quatro chipsets usados na família E_v3 (Broadwell, Skylake, Cascade Lake, Haswell) têm velocidades de processador diferentes, o que afeta as características de desempenho da máquina.
Leia atentamente a documentação do Azure Compute , prestando atenção às opções do chipset. Consulte também as práticas recomendadas de SKUs de VM do Azure para Arquivos NetApp do Azure. Selecionar uma VM com um único chipset é preferível para melhor consistência.
Largura de banda de rede disponível
É importante entender a diferença entre a largura de banda disponível da interface de rede VM e a largura de banda limitada aplicada em relação à mesma. Quando a documentação do Azure Compute fala sobre limites de largura de banda de rede, esses limites são aplicados apenas na saída (gravação). O tráfego de entrada (leitura) não é medido e, como tal, é limitado apenas pela largura de banda física da própria placa de interface de rede (NIC). A largura de banda de rede da maioria das VMs supera o limite de saída aplicado contra a máquina.
Como os volumes de Arquivos NetApp do Azure estão ligados à rede, o limite de saída pode ser interpretado como aplicado especificamente a gravações, enquanto a entrada é definida como leituras e cargas de trabalho semelhantes a leitura. Embora o limite de saída da maioria das máquinas seja maior do que a largura de banda de rede da NIC, o mesmo não pode ser dito para o E104_v5 usado nos testes deste artigo. O E104_v5 tem uma NIC de 100 Gbps com o limite de saída definido em 100 Gbps também. Em comparação, o E96_v5, com sua NIC de 100 Gbps, tem um limite de saída de 35 Gbps com entrada irrestrita a 100 Gbps. À medida que as VMs diminuem de tamanho, os limites de saída diminuem, mas a entrada permanece livre de limites logicamente impostos.
Os limites de saída abrangem toda a VM e são aplicados como tal em todas as cargas de trabalho baseadas em rede. Ao usar o Oracle Data Guard, todas as gravações são duplicadas nos logs de arquivo e devem ser levadas em consideração na avaliação dos limites de saída. Isso também é verdade para o log de arquivo com multidestino e para o RMAN, caso seja utilizado. Ao selecionar VMs, familiarize-se com ferramentas de linha de comando como ethtool, que expõem a configuração da NIC, pois o Azure não documenta as configurações da interface de rede.
Concorrência de rede
Os volumes de VMs do Azure e Arquivos NetApp do Azure vêm equipados com quantidades específicas de largura de banda. Como mostrado anteriormente, desde que uma VM tenha espaço suficiente para a CPU, uma carga de trabalho pode, em teoria, consumir a largura de banda disponibilizada para ela - ou seja, dentro dos limites da placa de rede e/ou limite de saída aplicado. Na prática, no entanto, a quantidade de taxa de transferência alcançável é baseada na simultaneidade da carga de trabalho na rede, ou seja, o número de fluxos de rede e pontos de extremidade de rede.
Leia a seção de limites de fluxo de rede do documento de largura de banda da rede VM para obter uma maior compreensão sobre. A conclusão: quanto mais fluxos de rede conectando o cliente ao armazenamento, mais rico será o desempenho potencial.
A Oracle suporta dois clientes NFS separados, Kernel NFS e Direct NFS (dNFS). O NFS do kernel, até tarde, suportava um único fluxo de rede entre dois pontos finais (computação – armazenamento). O NFS direto, o mais eficiente dos dois, suporta um número variável de fluxos de rede – os testes mostraram centenas de conexões exclusivas por ponto final – aumentando ou diminuindo conforme as demandas de carga. Devido ao dimensionamento dos fluxos de rede entre dois pontos finais, o Direct NFS é muito mais preferido do que o Kernel NFS e, como tal, a configuração recomendada. O grupo de produtos Arquivos NetApp do Azure não recomenda o uso do Kernel NFS com cargas de trabalho Oracle. Para obter mais informações, consulte os Benefícios do uso de arquivos NetApp do Azure com o Banco de Dados Oracle.
Simultaneidade de execução
Utilizar o Direct NFS, um único chipset para consistência, e compreender as restrições de largura de banda da rede só o leva até certo ponto. No final, o aplicativo impulsiona o desempenho. Provas de conceito usando SLOB2 e provas de conceito usando um pacote de aplicações da cadeia de abastecimento do mundo real contra dados reais de clientes foram capazes de aumentar significativamente a capacidade de processamento apenas porque as aplicações eram executadas simultaneamente; a primeira usando um número significativo de threads por esquema, a segunda usando várias conexões de múltiplos servidores de aplicações. Em resumo, a simultaneidade gera carga de trabalho, baixa simultaneidade - baixa taxa de transferência, alta simultaneidade - alta taxa de transferência, desde que a infraestrutura esteja pronta para suportar a mesma.
Rede acelerada
A rede acelerada permite a virtualização de entrada/saída de raiz única (SR-IOV) para uma VM, o que melhora muito o desempenho da rede. Este percurso de alto desempenho ignora o anfitrião no caminho de dados, o que reduz a latência, a instabilidade e a utilização da CPU das cargas de trabalho da rede mais exigentes nos tipos de VM suportadas. Ao implantar VMs por meio de utilitários de gerenciamento de configuração, como terraform ou linha de comando, lembre-se de que a rede acelerada não está habilitada por padrão. Para um desempenho ideal, habilite a rede acelerada. Note que o networking acelerado é ativado ou desativado para cada interface de rede. O recurso de rede acelerada é aquele que pode ser ativado ou desativado dinamicamente.
Observação
Este artigo contém referências ao termo SLAVE, um termo que a Microsoft já não utiliza. Quando o termo for removido do software, iremos removê-lo deste artigo.
Uma abordagem autoritativa para garantir que a rede acelerada esteja habilitada para uma NIC é através do terminal Linux. Se a rede acelerada estiver habilitada para uma NIC, uma segunda NIC virtual estará presente associada à primeira NIC. Esta segunda NIC é configurada pelo sistema com o SLAVE sinalizador ativado. Se nenhuma NIC estiver presente com o sinalizador SLAVE, a rede acelerada não estará habilitada para essa interface.
No cenário em que várias NICs são configuradas, você precisa determinar qual SLAVE interface está associada à NIC usada para montar o volume NFS. Adicionar placas de interface de rede à VM não tem efeito sobre o desempenho.
Use o processo a seguir para identificar o mapeamento entre a interface de rede configurada e sua interface virtual associada. Esse processo valida que a rede acelerada está habilitada para uma NIC específica em sua máquina Linux e exibe a velocidade de entrada física que a NIC pode alcançar.
- Execute o
ip acomando: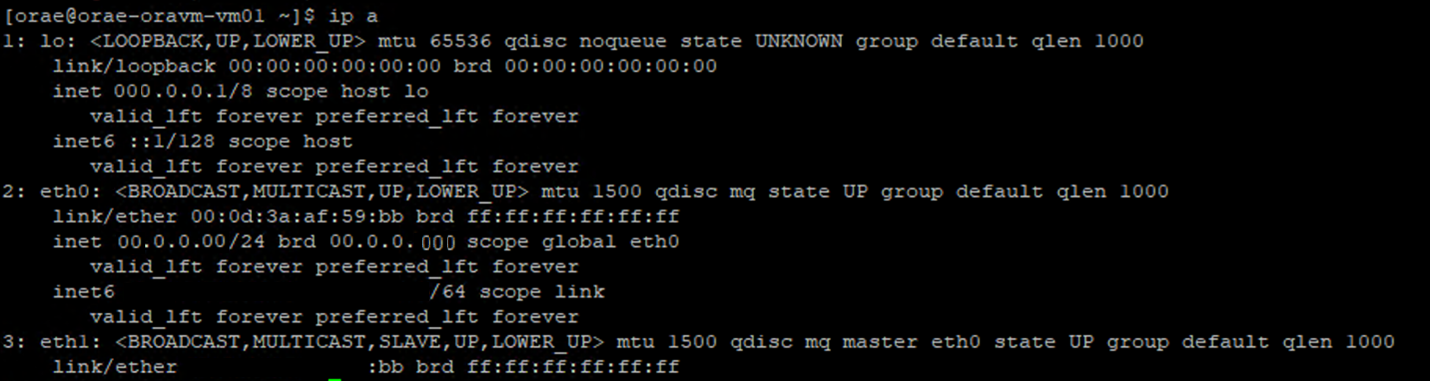
- Liste o
/sys/class/net/diretório da ID da NIC que você está verificando (eth0no exemplo) egreppara a palavra inferior:ls /sys/class/net/eth0 | grep lower lower_eth1 - Execute o comando
ethtoolno dispositivo ethernet identificado como o dispositivo mais abaixo na etapa precedente.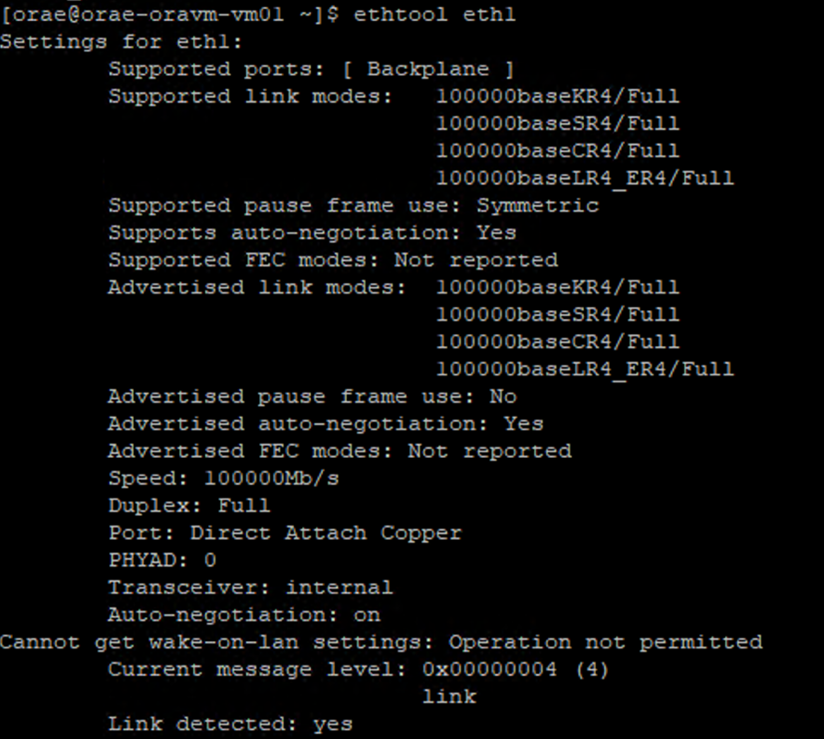
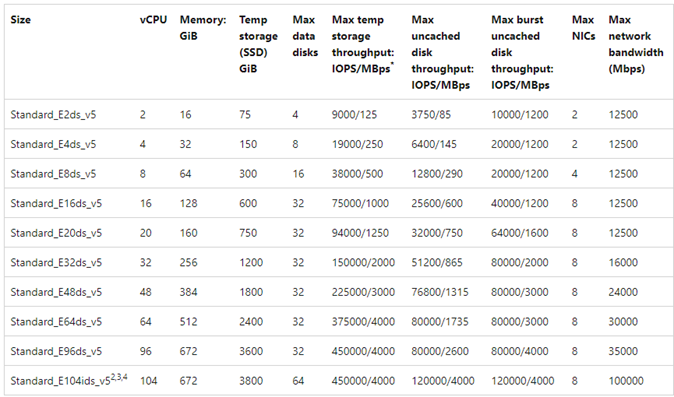
VM do Azure: limites de largura de banda de rede versus disco
É necessário um nível de especialização ao ler a documentação dos limites de desempenho da VM do Azure. Esteja atento a:
- A taxa de transferência de armazenamento temporário e os números IOPS referem-se aos recursos de desempenho do armazenamento efémero local ligado diretamente à máquina virtual.
- A taxa de transferência de discos não armazenados em cache e os valores de I/O referem-se especificamente aos Discos do Azure (Premium, Premium v2 e Ultra) e não afetam o armazenamento ligado à rede, como o Azure NetApp Files.
- Anexar NICs adicionais à VM não tem impacto nos limites de desempenho ou nos recursos de desempenho da VM (documentados e testados como verdadeiros).
- A largura de banda máxima da rede refere-se aos limites de saída (ou seja, gravações quando os Arquivos NetApp do Azure estão envolvidos) aplicados à largura de banda da rede VM. Nenhum limite de entrada (ou seja, leituras quando os Arquivos NetApp do Azure estão envolvidos) é aplicado. Com CPU suficiente, concorrência de rede suficiente e endpoints suficientemente ricos, uma VM poderia, teoricamente, direcionar o tráfego de entrada para os limites da NIC. Conforme mencionado na seção Largura de banda de rede disponível, use ferramentas como
ethtoolpara ver a largura de banda da placa de rede.
Um gráfico de exemplo é mostrado para referência:
Azure NetApp Files
O serviço de armazenamento primário do Azure Azure NetApp Files fornece uma solução de armazenamento totalmente gerenciada altamente disponível capaz de suportar as exigentes cargas de trabalho Oracle introduzidas anteriormente.
Como os limites do desempenho de armazenamento em expansão em um banco de dados Oracle são bem compreendidos, este artigo se concentra intencionalmente no desempenho de armazenamento em expansão. Dimensionar o desempenho do armazenamento implica dar a uma única instância Oracle acesso a muitos volumes do Azure NetApp Files onde esses volumes são distribuídos em vários pontos de extremidade de armazenamento.
Ao dimensionar uma carga de trabalho de banco de dados em vários volumes dessa forma, o desempenho do banco de dados fica desvinculado dos limites superiores de volume e ponto final. Com o armazenamento não impondo mais limitações de desempenho, a arquitetura da VM (limites de saída de CPU, NIC e VM) torna-se o ponto de estrangulamento a ser enfrentado. Conforme observado na seção VM, a seleção das instâncias E104ids_v5 e E96ds_v5 foi feita tendo isso em mente.
Se um banco de dados é colocado em um único grande volume de capacidade ou distribuído por vários volumes menores, o custo financeiro total é o mesmo. A vantagem de distribuir E/S por vários volumes e pontos finais ao contrário de um único volume e ponto final é evitar restrições de largura de banda - você pode aproveitar ao máximo o que paga.
Importante
Para implantar usando os Arquivos NetApp do Azure em uma multiple volume:multiple endpoint configuração, entre em contato com seu Especialista em Arquivos NetApp do Azure ou com o Arquiteto de Soluções na Nuvem para obter assistência.
Base de dados
A versão 19c do banco de dados Oracle é a versão atual de lançamento de longo prazo da Oracle e a usada para produzir todos os resultados de teste discutidos neste artigo.
Para obter o melhor desempenho, todos os volumes de banco de dados foram montados usando o Direct NFS, o Kernel NFS não é recomendado devido a restrições de desempenho. Para obter uma comparação de desempenho entre os dois clientes, consulte Desempenho do banco de dados Oracle em volumes únicos do Azure NetApp Files. Observe que todos os patches dNFS relevantes (Oracle Support ID 1495104) foram aplicados, assim como as práticas recomendadas descritas no relatório Oracle Databases on Microsoft Azure using Azure NetApp Files .
Embora o Oracle e o Azure NetApp Files ofereçam suporte a NFSv3 e NFSv4.1, como o NFSv3 é o protocolo mais maduro, geralmente é visto como tendo mais estabilidade e é a opção mais confiável para ambientes altamente sensíveis a interrupções. Os testes descritos neste artigo foram todos concluídos sobre NFSv3.
Importante
Alguns dos patches recomendados que a Oracle documenta no Support ID 1495104 são críticos para manter a integridade dos dados ao usar o dNFS. A aplicação de tais patches é fortemente aconselhada para ambientes de produção.
O gerenciamento automático de armazenamento (ASM) é suportado para volumes NFS. Embora normalmente associado ao armazenamento baseado em blocos, em que o ASM substitui o LVM (gerenciamento de volumes lógicos) e o sistema de arquivos, o ASM desempenha um papel valioso em cenários NFS de vários volumes e merece uma forte consideração. Uma das vantagens do ASM é a adição e o reequilíbrio on-line dinâmicos em volumes e endpoints NFS recém-adicionados, o que simplifica o gerenciamento e permite a expansão do desempenho e da capacidade à vontade. Embora o ASM por si só não aumente o desempenho de um banco de dados, seu uso evita arquivos quentes e a necessidade de manter manualmente a distribuição de arquivos - um benefício fácil de ver.
Uma configuração ASM sobre dNFS foi usada para produzir todos os resultados de teste discutidos neste artigo. O diagrama a seguir ilustra o layout do arquivo ASM nos volumes do Azure NetApp Files e a alocação de arquivos para os grupos de discos ASM.

Existem algumas limitações na utilização do ASM em volumes montados NFS do Azure NetApp Files, especialmente na gestão de instantâneos de armazenamento, que podem ser superadas com algumas considerações específicas de arquitetura. Entre em contato com seu especialista em Arquivos NetApp do Azure ou arquiteto de soluções de nuvem para obter uma análise aprofundada dessas considerações.
Ferramentas de teste sintéticas e sintonizáveis
Esta seção descreve a arquitetura de teste, os ajustáveis e os detalhes de configuração em detalhes. Enquanto a seção anterior é focada nas razões pelas quais as decisões de configuração são tomadas, esta seção se concentra especificamente no "quê" das decisões de configuração.
Implantação automatizada
- As VMs de banco de dados são implantadas usando scripts bash disponíveis no GitHub.
- O desenho e a distribuição de vários volumes e pontos de extremidade do Azure NetApp Files são realizados manualmente. Você precisa trabalhar com seu Especialista em Arquivos NetApp do Azure ou Arquiteto de Soluções na Nuvem para obter assistência.
- A instalação em grade, a configuração ASM, a criação e configuração do banco de dados e o ambiente SLOB2 em cada máquina são configurados usando o Ansible para consistência.
- As execuções de teste SLOB2 paralelas em vários hosts também são concluídas usando o Ansible para consistência e execução simultânea.
Configuração da VM
| Configuração | Valor |
|---|---|
| região do Azure | Europa Ocidental |
| SKU de VM | E104ids_v5 |
| Contagem de NIC | 1 NOTA: Adicionar vNICs não tem efeito na contagem do sistema |
| Máx largura de banda de rede de egresso (Mbps) | 100,000 |
| Armazenamento (SSD) temporário GiB | 3,800 |
Configuração do sistema
Todas as definições de configuração do sistema Oracle necessárias para a versão 19c foram implementadas de acordo com a documentação da Oracle.
Os seguintes parâmetros foram adicionados ao arquivo de /etc/sysctl.conf sistema Linux:
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp Files
Todos os volumes do Azure NetApp Files foram montados com as seguintes opções de montagem NFS.
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
Parâmetros do banco de dados
| Parâmetros | Valor |
|---|---|
db_cache_size |
2g |
large_pool_size |
2g |
pga_aggregate_target |
3g |
pga_aggregate_limit |
3g |
sga_target |
25gr |
shared_io_pool_size |
500m |
shared_pool_size |
5g |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
Configuração SLOB2
Toda a geração de carga de trabalho para teste foi concluída usando a ferramenta SLOB2 versão 2.5.4.
Quatorze esquemas SLOB2 foram carregados num tablespace Oracle padrão e executados, o que, em combinação com as definições listadas no arquivo de configuração do SLOB2, resultou num conjunto de dados SLOB2 de 7 TiB. As configurações a seguir refletem uma execução de leitura aleatória para SLOB2. O parâmetro de configuração SCAN_PCT=0 foi alterado para SCAN_PCT=100 durante o teste sequencial.
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
Para o teste de leitura aleatória, foram realizadas nove execuções do SLOB2. A contagem de threads foi aumentada em seis a cada iteração de teste, começando com um.
Para testes sequenciais, foram realizadas sete execuções SLOB2. A contagem de threads foi aumentada em dois com cada iteração de teste começando de uma. A contagem de threads foi limitada a seis devido ao alcance dos limites máximos de largura de banda da rede.
Métricas AWR
Todas as métricas de desempenho foram reportadas através do Oracle Automatic Workload Repository (AWR). A seguir estão as métricas apresentadas nos resultados:
- Taxa de transferência: a soma da taxa de transferência média de leitura e de escrita da seção Perfil de carga AWR
- Média de solicitações de E/S lidas na seção Perfil de carga do AWR
- tempo médio de espera do evento de espera de leitura sequencial do arquivo de banco de dados da seção Eventos de Espera em Primeiro Plano do AWR
Migração de sistemas projetados especificamente para a nuvem
O Oracle Exadata é um sistema projetado - uma combinação de hardware e software que é considerada a solução mais otimizada para executar cargas de trabalho Oracle. Embora a nuvem tenha vantagens significativas no esquema geral do mundo técnico, esses sistemas especializados podem parecer incrivelmente atraentes para aqueles que leram e visualizaram as otimizações que a Oracle construiu em torno de sua(s) carga de trabalho específica.
Quando se trata de executar o Oracle no Exadata, existem algumas razões comuns pelas quais o Exadata é escolhido:
- 1-2 cargas de trabalho de E/S intensivas que se ajustam naturalmente aos recursos do Exadata, e como essas cargas de trabalho exigem características significativas de engenharia do Exadata, os demais bancos de dados executados juntamente com elas foram consolidados no Exadata.
- Cargas de trabalho OLTP complicadas ou difíceis que precisam que o RAC seja utilizado para escalar e são difíceis de arquitetar com hardware proprietário sem um conhecimento profundo da otimização do Oracle, ou podem constituir uma dívida técnica que não pode ser otimizada.
- Exadata existente subutilizado com várias cargas de trabalho: isto ocorre devido a migrações anteriores, ao fim de vida de um Exadata anterior, ou devido ao desejo de trabalhar/testar um Exadata localmente.
É essencial que qualquer migração de um sistema Exadata seja entendida da perspetiva das cargas de trabalho e quão simples ou complexa pode ser a migração. Uma necessidade secundária é entender o motivo da compra da Exadata de uma perspetiva de status. As habilidades Exadata e RAC estão em maior demanda e podem ter impulsionado a recomendação de compra de uma pelas partes interessadas técnicas.
Importante
Não importa o cenário, a conclusão geral deve ser, para qualquer carga de trabalho de banco de dados proveniente de um Exadata, quanto mais recursos proprietários do Exadata forem usados, mais complexa será a migração e o planejamento. Os ambientes que não utilizam fortemente os recursos proprietários da Exadata têm oportunidades para um processo de migração e planejamento mais simples.
Há várias ferramentas que podem ser usadas para avaliar essas oportunidades de carga de trabalho:
- O repositório automático de carga de trabalho (AWR):
- Todos os bancos de dados Exadata são licenciados para usar relatórios AWR e recursos de desempenho e diagnóstico conectados.
- Está sempre ativo e coleta dados que podem ser usados para exibir informações históricas da carga de trabalho e avaliar o uso. Os valores de pico podem avaliar o alto uso no sistema,
- Relatórios AWR de janela maior podem avaliar a carga de trabalho geral, fornecendo informações valiosas sobre o uso de recursos e como migrar a carga de trabalho para não-Exadata de forma eficaz. Os relatórios AWR de pico, em contraste, são melhores para otimização de desempenho e solução de problemas.
- O relatório Global (RAC-Aware) AWR para Exadata também inclui uma seção específica do Exadata, que detalha o uso de recursos específicos do Exadata e fornece informações valiosas sobre cache flash, flash logging, IO e outros recursos por banco de dados e nó de célula.
Dissociação da Exadata
Ao identificar cargas de trabalho do Oracle Exadata para migrar para a nuvem, considere as seguintes perguntas e pontos de dados:
- A carga de trabalho está consumindo vários recursos do Exadata, além dos benefícios de hardware?
- Digitalizações inteligentes
- Índices de armazenamento
- Cache flash
- Registo rápido
- Compressão colunar híbrida
- A carga de trabalho usando o Exadata é descarregada de forma eficiente? Nos eventos de primeiro plano de tempo superior, qual é a proporção (mais de 10% de tempo de banco de dados) de carga de trabalho usando:
- Digitalização inteligente da tabela de células (ótima)
- Leitura física multibloco celular (menos otimizada)
- Leitura física de bloco único de célula (menos ideal)
- Compressão colunar híbrida (HCC/EHCC): Quais são as relações comprimidas vs. não comprimidas:
- O banco de dados está gastando mais de 10% do tempo do banco de dados na compactação e descompactação de dados?
- Inspecione os ganhos de desempenho de predicados ao usar a compactação em consultas: o valor obtido compensa em relação ao valor economizado com a compactação?
- E/S física da célula: Verifique as poupanças obtidas a partir de:
- a quantidade direcionada para o nó de banco de dados para equilibrar a CPU.
- Identificando o número de bytes retornados pelo Smart Scan. Esses valores podem ser subtraídos em IO para a porcentagem de leituras físicas de blocos únicos de células assim que esse processo migra do Exadata.
- Observe o número de leituras lógicas do cache. Determine se o cache flash será necessário em uma solução de IaaS na nuvem para a carga de trabalho.
- Compare o total de bytes físicos de leitura e gravação com a quantidade total executada no cache. A memória pode ser aumentada para eliminar os requisitos de leitura física (é comum que alguns reduzam o SGA para forçar o descarregamento do Exadata)?
- Em Estatísticas do Sistema, identifique quais objetos são impactados por qual estatística. Ao ajustar o SQL, a indexação adicional, o particionamento ou outros ajustes físicos podem otimizar drasticamente a carga de trabalho.
- Inspecione os parâmetros de inicialização em busca de sublinhado (_) ou parâmetros preteridos, o que deve ser justificado devido ao impacto no nível do banco de dados que eles podem estar causando no desempenho.
Configuração do servidor Exadata
No Oracle versão 12.2 e superior, uma adição específica da Exadata será incluída no relatório global do AWR. Este relatório tem seções que fornecem valor excecional para uma migração do Exadata.
Versão do Exadata e detalhes do sistema
Detalhes dos alertas do nó da célula
Discos Exadata não online
Dados atípicos para quaisquer estatísticas do sistema operativo Exadata
Amarelo/Rosa: Preocupante. O Exadata não está funcionando da melhor forma.
Vermelho: O desempenho da Exadata é afetado significativamente.
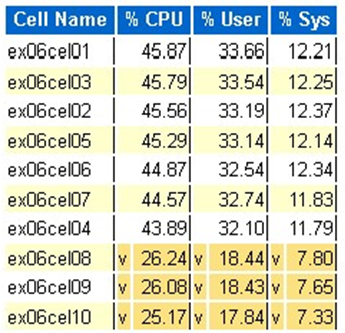
Estatística da CPU do Exadata OS: células superiores
- Estas estatísticas são recolhidas pelo SO nas células e não se restringem a esta base de dados ou instâncias
- A
ve um fundo amarelo escuro indicam um valor atípico abaixo do intervalo baixo - A
^e um fundo amarelo claro indicam um valor atípico acima da faixa alta - As principais células por percentagem de CPU são exibidas e estão em ordem decrescente de percentagem de CPU.
- Média: 39,34% CPU, 28,57% utilizador, 10,77% sistema
Leituras de bloco físico de célula única
Uso do cache Flash
Temp IO
Eficiência do cache colunar
Banco de dados superior por taxa de transferência de E/S
Embora as avaliações de dimensionamento possam ser realizadas, há algumas perguntas sobre as médias e os picos simulados que são incorporados a esses valores para grandes cargas de trabalho. Esta seção, encontrada no final de um relatório AWR, é excepcionalmente valiosa, pois mostra o uso médio de flash e disco dos 10 principais bancos de dados no Exadata. Embora muitos possam supor que desejam dimensionar bancos de dados para desempenho máximo na nuvem, isso não faz sentido para a maioria das implantações (mais de 95% está na faixa média; com um pico simulado calculado, o intervalo médio será maior que 98%). É importante pagar pelo que é necessário, mesmo para as cargas de trabalho de maior exigência da Oracle, e inspecionar os principais bancos de dados por IO Throughput pode ser esclarecedor para entender as necessidades de recursos para o banco de dados.
Oracle do tamanho certo usando o AWR no Exadata
Ao executar o planejamento de capacidade para sistemas locais, é natural ter uma sobrecarga significativa incorporada ao hardware. O hardware provisionado em excesso precisa atender à carga de trabalho Oracle por vários anos, independentemente das adições de carga de trabalho devido ao crescimento de dados, alterações de código ou upgrades.
Um dos benefícios da nuvem é dimensionar recursos em um host de VM e o armazenamento pode ser executado à medida que as demandas aumentam. Isso ajuda a conservar os custos de nuvem e os custos de licenciamento associados ao uso do processador (pertinente ao Oracle).
O dimensionamento correto envolve a remoção do hardware da migração lift-and-shift tradicional e o uso das informações de carga de trabalho fornecidas pelo Repositório Automático de Carga de Trabalho (AWR) da Oracle para migrar a carga de trabalho para computação e armazenamento especialmente concebidos para suportá-la na nuvem escolhida pelo cliente. O processo de dimensionamento correto garante que a arquitetura daqui para frente remova a dívida técnica da infraestrutura, a redundância de arquitetura que ocorreria se a duplicação do sistema local fosse replicada para a nuvem e implemente serviços de nuvem sempre que possível.
Os especialistas no assunto Microsoft Oracle estimaram que mais de 80% dos bancos de dados Oracle são provisionados em excesso e experimentam o mesmo custo ou economia indo para a nuvem se levarem o tempo necessário para dimensionar corretamente a carga de trabalho do banco de dados Oracle antes de migrar para a nuvem. Essa avaliação exige que os especialistas em banco de dados da equipe mudem sua mentalidade sobre como eles podem ter realizado o planejamento de capacidade no passado, mas vale a pena o investimento das partes interessadas na nuvem e na estratégia de nuvem do negócio.
Próximos passos
- Execute suas cargas de trabalho Oracle mais exigentes no Azure sem sacrificar o desempenho ou a escalabilidade
- Arquiteturas de solução usando arquivos NetApp do Azure - Oracle
- Projetar e implementar um banco de dados Oracle no Azure
- Ferramenta de estimativa para dimensionar cargas de trabalho Oracle para VMs IaaS do Azure
- Arquiteturas de referência para Oracle Database Enterprise Edition no Azure
- Compreender os grupos de volumes de aplicativos do Azure NetApp Files para SAP HANA