Gerencie dados históricos com a política de retenção
Importante
O Azure SQL Edge não suporta mais a plataforma ARM64.
Depois que a política de retenção de dados é definida para um banco de dados e a tabela subjacente, uma tarefa de temporizador de tempo em segundo plano é executada para remover quaisquer registros obsoletos da tabela habilitada para retenção de dados. A identificação de linhas correspondentes e sua remoção da tabela ocorrem de forma transparente, na tarefa em segundo plano agendada e executada pelo sistema. A condição de idade para as linhas da tabela é verificada filter_column com base na coluna especificada na definição da tabela. Se o período de retenção for definido como uma semana, por exemplo, as linhas da tabela elegíveis para limpeza satisfazem uma das seguintes condições:
- Se a coluna de filtro usar o tipo de dados DATETIMEOFFSET, a condição será
filter_column < DATEADD(WEEK, -1, SYSUTCDATETIME()) - Caso contrário, a condição é
filter_column < DATEADD(WEEK, -1, SYSDATETIME())
Fases de limpeza de retenção de dados
A operação de limpeza de retenção de dados consiste em duas fases:
- Descoberta: Nesta fase, a operação de limpeza identifica todas as tabelas dentro dos bancos de dados de usuários para criar uma lista para limpeza. O Discovery é executado uma vez por dia.
- Limpeza: nesta fase, a limpeza é executada em todas as tabelas com retenção de dados finita, identificadas na fase de descoberta. Se a operação de limpeza não puder ser executada em uma tabela, essa tabela será ignorada na execução atual e tentada novamente na próxima iteração. Os seguintes princípios são usados durante a limpeza:
- Se uma linha obsoleta for bloqueada por outra transação, essa linha será ignorada.
- A limpeza é executada com um tempo limite de bloqueio padrão de 5 segundos. Se os bloqueios não puderem ser adquiridos nas tabelas dentro da janela de tempo limite, a tabela será ignorada na execução atual e será repetida na próxima iteração.
- Se houver um erro durante a limpeza de uma tabela, essa tabela será ignorada e será coletada na próxima iteração.
Limpeza manual
Dependendo das configurações de retenção de dados em uma tabela e da natureza da carga de trabalho no banco de dados, é possível que o thread de limpeza automática não remova completamente todas as linhas obsoletas durante sua execução. Para permitir que os usuários removam manualmente linhas obsoletas, o sys.sp_cleanup_data_retention procedimento armazenado foi introduzido no Azure SQL Edge.
Este procedimento armazenado usa três parâmetros:
@schema_name: Nome do esquema proprietário da tabela. Obrigatório.@table_name: Nome da tabela para a qual a limpeza manual está sendo executada. Obrigatório.@rowcount: Variável de saída. Devolve o número de linhas limpas pela controladora de limpeza manual. Opcional.
Para obter mais informações, consulte sys.sp_cleanup_data_retention (Transact-SQL).
O exemplo a seguir mostra a execução da limpeza manual sp para tabela dbo.data_retention_table.
DECLARE @rowcnt BIGINT;
EXEC sys.sp_cleanup_data_retention 'dbo', 'data_retention_table', @rowcnt OUTPUT;
SELECT @rowcnt;
Como as linhas obsoletas são excluídas
O processo de limpeza depende do layout do índice da tabela. Uma tarefa em segundo plano é criada para executar a limpeza de dados obsoletos para todas as tabelas com período de retenção finito. A lógica de limpeza para o índice rowstore (heap ou B-tree) exclui a linha envelhecida em blocos menores (até 10.000), minimizando a pressão no log do banco de dados e no subsistema de E/S. Embora a lógica de limpeza utilize o índice de árvore B necessário, a ordem das exclusões para as linhas anteriores ao período de retenção não pode ser firmemente garantida. Em outras palavras, não dependa da ordem de limpeza em seus aplicativos.
Aviso
No caso de heaps e índices de árvore B, a retenção de dados executa uma consulta de exclusão nas tabelas subjacentes, que pode entrar em conflito com gatilhos de exclusão nas tabelas. Você deve remover gatilhos de exclusão das tabelas ou evitar o uso de retenção de dados em tabelas que tenham gatilhos DML de exclusão.
A tarefa de limpeza para os índices columnstore clusterizados remove grupos de linhas inteiros de uma só vez (normalmente contêm 1 milhão de linhas cada), o que é eficiente, especialmente quando os dados são gerados e envelhecem em um ritmo alto.
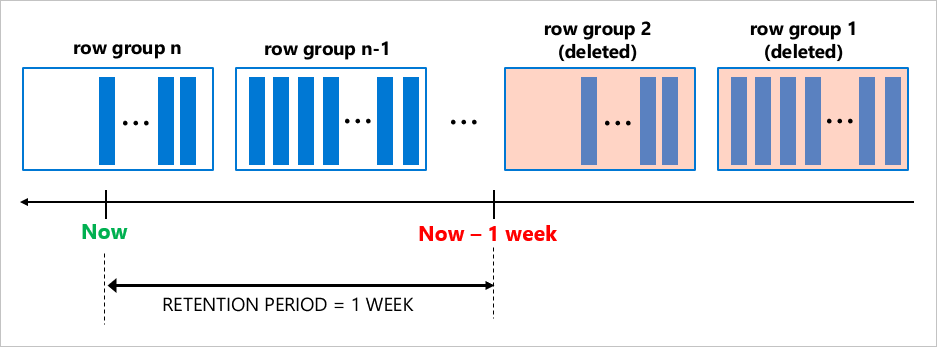
A excelente compactação de dados e a limpeza eficiente da retenção tornam os índices columnstore clusterizados uma escolha perfeita para cenários em que sua carga de trabalho gera rapidamente uma grande quantidade de dados.
Monitorar a limpeza da retenção de dados
As operações de limpeza da política de retenção de dados podem ser monitoradas usando Eventos Estendidos no SQL Edge do Azure. Para obter mais informações sobre eventos estendidos, consulte Visão geral de eventos estendidos.
Os seguintes Eventos Estendidos ajudam a controlar o estado das operações de limpeza.
| Name | Description |
|---|---|
| data_retention_task_started | Ocorre quando a tarefa em segundo plano para limpeza de tabelas com uma política de retenção é iniciada. |
| data_retention_task_completed | Ocorre quando a tarefa em segundo plano para limpeza de tabelas com uma política de retenção termina. |
| data_retention_task_exception | Ocorre quando a tarefa em segundo plano para limpeza de tabelas com uma política de retenção falha, fora do processo de limpeza de retenção específico para essas tabelas. |
| data_retention_cleanup_started | Ocorre quando o processo de limpeza de uma tabela com política de retenção de dados é iniciado. |
| data_retention_cleanup_exception | Ocorre quando o processo de limpeza de uma tabela com política de retenção falha. |
| data_retention_cleanup_completed | Ocorre quando o processo de limpeza de uma tabela com política de retenção de dados termina. |
Além disso, um novo tipo de buffer de anel nomeado foi adicionado à sys.dm_os_ring_buffers exibição de RING_BUFFER_DATA_RETENTION_CLEANUP gerenciamento dinâmico. Essa exibição pode ser usada para monitorar as operações de limpeza de retenção de dados.
Próximos passos
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários