Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O Azure Backup fornece um conjunto de métricas integradas via Azure Monitor que lhe permitem monitorizar o estado dos seus backups. Também permite configurar regras de alerta que são ativadas quando as métricas ultrapassam limites definidos.
O Backup do Azure oferece os seguintes recursos principais:
- Capacidade de visualizar métricas prontas a usar relacionadas com backup e restaurar a saúde dos seus itens de backup, juntamente com as tendências associadas
- Capacidade de criar regras de alerta personalizadas nestas métricas para monitorizar eficientemente o estado dos seus itens de backup
- Capacidade de rotear alertas de métricas disparados para diferentes canais de notificação suportados pelo Azure Monitor, como email, ITSM, webhook, aplicativos lógicos e assim por diante.
Saiba mais sobre as métricas do Azure Monitor.
Cenários suportados
Suporta métricas incorporadas para os seguintes tipos de carga de trabalho:
- Azure VM, bases de dados SQL em Azure VM
- Bancos de dados SAP HANA na VM do Azure
- Ficheiros do Azure
- Manchas Azuis.
As métricas para o tipo de carga de trabalho de instância HANA atualmente não são suportadas.
As métricas podem ser visualizadas para todos os cofres de Recovery Services em cada região e subscrição de cada vez. A visualização de métricas para um âmbito mais amplo no portal Azure atualmente não é suportada. Os mesmos limites também se aplicam à configuração das regras de alerta métrico.
Métricas suportadas
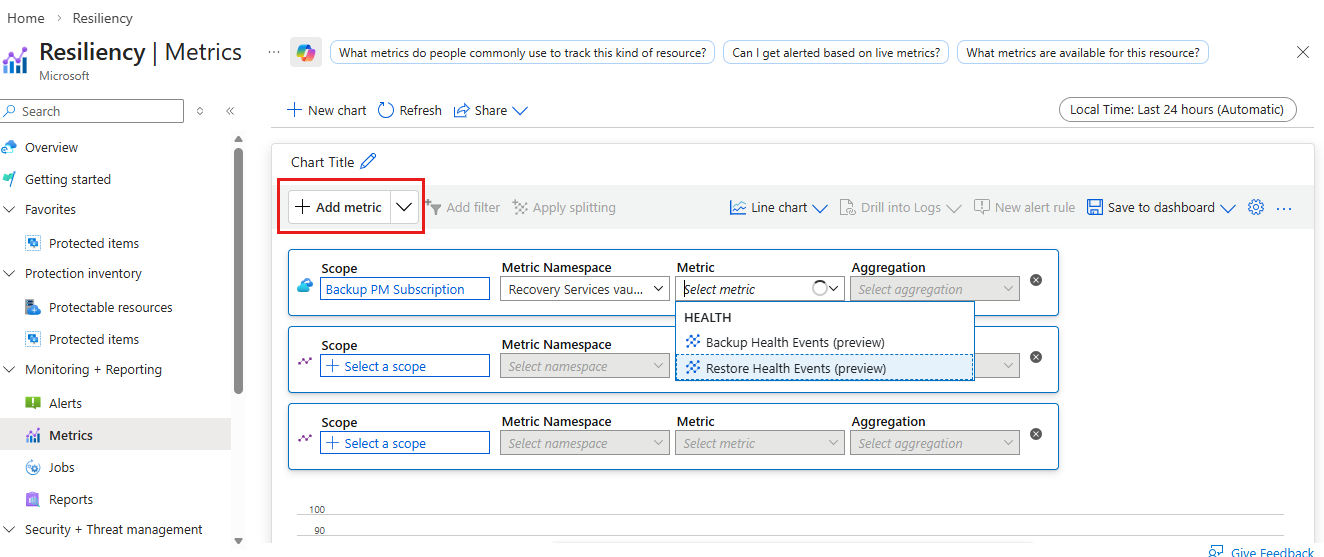
Atualmente, o Azure Backup suporta as seguintes métricas:
Eventos de Saúde de Backup: O valor desta métrica representa a contagem de eventos relacionados com a saúde do trabalho de backup, que foram registados para o cofre durante um período específico. Quando um trabalho de backup é concluído, o serviço Azure Backup cria um evento de integridade do backup. Com base no estado da tarefa (como bem-sucedida ou falhada), as dimensões associadas ao evento variam.
Restaurar Eventos de Saúde: O valor desta métrica representa a contagem de eventos de saúde relacionados com a restauração da saúde do emprego, que foram disparados para o cofre dentro de um tempo específico. Quando um trabalho de restauro é concluído, o serviço Azure Backup cria um evento de restauração de saúde. Com base no estado do trabalho (como sucesso ou falhado), as dimensões associadas ao evento variam.
Note
Suportamos apenas Restore Health Events para cargas de trabalho do Azure Blobs, pois os backups são contínuos e não há aqui noção de trabalhos de backup.
Por padrão, as contagens são exibidas ao nível do cofre. Para visualizar as contagens de um item de backup específico e do estado da tarefa, pode filtrar as métricas em qualquer uma das dimensões suportadas.
A tabela seguinte lista as dimensões que as métricas de Eventos de Saúde de Backup e Eventos de Saúde de Restauração suportam.
| Nome da Dimensão | Description |
|---|---|
| ID da fonte de dados | O ID único da fonte de dados associada ao trabalho.
Para backup de bases de dados SQL AG, o campo ID da fonte de dados está vazio, pois não existe fonte de dados (VM) nesses cenários. Para visualizar métricas para uma determinada base de dados dentro de um AG, utilize o campo ID de Instância de Backup . |
| Tipo de fonte de dados | O tipo de fonte de dados associada ao trabalho. Seguem-se os tipos de fonte de dados suportados:
|
| ID da Instância de Backup | O ID ARM da instância de backup associada ao trabalho. Por exemplo, /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/testRG/providers/Microsoft.RecoveryServices/vaults/testVault/backupFabrics/Azure/protectionContainers/IaasVMContainer;iaasvmcontainerv2;testRG;testVM/protectedItems/VM;iaasvmcontainerv2;testRG;testVM |
| Nome da Instância de Backup | Nome amigável da instância de backup para facilitar a legibilidade. É do formato {protectedContainerName};{backupItemFriendlyName}. Por exemplo, testStorageAccount;testFileShare |
| Estado de saúde | Representa a saúde do item de reserva após a conclusão do trabalho. Pode assumir um dos seguintes valores: Saudável, Transitório Não Saudável, Persistente Pouco Saudável, Transitório Degradado, Persistente Degradado.
|
Ver métricas no portal Azure
Para visualizar métricas no portal Azure, siga os passos abaixo:
No portal Azure, vai a Resiliência>Monitorização + Relatórios>Métricas.
Em alternativa, pode ir ao Cofre de Serviços de Recuperação ou Azure Monitor, e selecionar Métricas.
Para filtrar as métricas, selecione o seguinte tipo de dados:
- Scope
- Subscrição (só pode ser selecionada uma de cada vez)
- Cofre dos Serviços de Recuperação/ Cofre de Backup como tipo de recurso
- Location
Note
- Se fores a Métricas do Cofre dos Serviços de Recuperação/ Cofre de Backup, o âmbito da métrica está pré-selecionado.
- A seleção do tipo de recurso cofre de Serviços de Recuperação/ cofre de backup permite-lhe acompanhar as métricas embutidas relacionadas com o backup - eventos de integridade de backup e eventos de integridade de restauração.
- Atualmente, o âmbito para visualizar métricas está disponível para todos os cofres de Serviços de Recuperação numa determinada subscrição e região. Por exemplo, todos os cofres dos Serviços de Recuperação no Leste dos EUA no TestSubscription1.
Selecione um cofre ou um grupo de cofres para os quais queira visualizar métricas.
Atualmente, o âmbito máximo para visualizar métricas é: todos os cofres dos Serviços de Recuperação numa região e numa assinatura específicas. Por exemplo, os cofres de Todos os Serviços de Recuperação no Leste dos EUA no TestSubscription1.
Selecione uma métrica para visualizar Eventos de Saúde de Backup ou Restaurar Eventos de Saúde.
Isto gera um gráfico que mostra a contagem de eventos de saúde para o(s) cofre(s). Pode ajustar o intervalo de tempo e a granularidade da agregação usando os filtros no topo do ecrã.
Para filtrar métricas por diferentes dimensões, clique no botão Adicionar Filtro e selecione os valores das dimensões relevantes.
- Por exemplo, se quiser ver contagens de eventos de saúde apenas para backups de VMs Azure, adicione um filtro
Datasource Type = Microsoft.Compute/virtualMachines. - Para visualizar eventos de saúde para uma determinada fonte de dados ou instância de backup dentro do cofre, use os filtros de ID de fonte de dados/ID de instância de backup.
- Para visualizar eventos de saúde apenas para backups falhados, use um filtro no HealthStatus, selecionando os valores correspondentes a estado de saúde doente ou degradado.
- Por exemplo, se quiser ver contagens de eventos de saúde apenas para backups de VMs Azure, adicione um filtro


Gerenciar alertas
Para visualizar os seus alertas de métrica acionados, siga estes passos:
- No portal do Azure, vá para Resiliência>>Alertas.
- Filtragem por Tipo de Sinal = , Métrica e Tipo de Alerta = Configurado.
- Clique num alerta para ver mais detalhes sobre o alerta e alterar o seu estado.
Note
O alerta tem dois campos - Condição do Monitor (disparado/resolvido) e Estado de Alerta (Novo/Reconhecido/Fechado).
- Estado de alerta: Pode editar este campo (como mostrado na captura de ecrã abaixo).
- Condição do monitor: Não pode editar este campo. Este campo é mais utilizado em cenários onde o próprio serviço resolve o alerta. Por exemplo, o comportamento de auto-resolução em alertas métricos utiliza o campo de condição Monitor para resolver um alerta.
Alertas de fontes de dados e alertas globais
Com base na configuração das regras de alerta, o alerta disparado aparece no painel Alertas em Resiliência.
Aprenda a visualizar e filtrar alertas.
Note
Atualmente, no caso de alertas de restauração de blob, os alertas aparecem nos alertas da fonte de dados apenas se selecionar ambas as dimensões - datasourceId e datasourceType ao criar a regra de alerta. Se nenhuma dimensão for selecionada, os alertas aparecerão em alertas globais.
Aceder a métricas de forma programática
Pode usar os diferentes clientes programáticos, como PowerShell, CLI ou REST API, para aceder à funcionalidade de métricas. Consulte a documentação da API REST do Azure Monitor para mais detalhes.
Exemplos de cenários de alerta
Dispara um único alerta se todas as cópias de segurança ativadas de um cofre forem bem-sucedidas nas últimas 24 horas
Regra de Alerta: Dispare um alerta se houver Eventos < de Saúde de Reserva 1 nas últimas 24 horas para:
Dimensões["EstadoDeSaúde"]!= "Saudável"
Emitir um alerta após cada falha de tarefa de backup
Regra de Alerta: Gere um alerta se os Eventos de Saúde de Backup forem > 0 nos últimos 5 minutos, para:
- Dimensões["EstadoDeSaúde"]!= "Saudável"
- Dimensions["DatasourceId"]= "Todos os valores atuais e futuros"
Dispare um alerta se houver falhas consecutivas de backup para o mesmo item nas últimas 24 horas
Regra de Alerta: Dispare um alerta se houver Eventos > de Saúde de Reserva 1 nas últimas 24 horas para:
- Dimensões["EstadoDeSaúde"]!= "Saudável"
- Dimensions["DatasourceId"]= "Todos os valores atuais e futuros"
Dispare um alerta se nenhum trabalho de backup foi executado para um item nas últimas 24 horas
<:
Dimensions["DatasourceId"]= "Todos os valores atuais e futuros"