Fala personalizada para contêineres de texto com o Docker
A fala personalizada para o contêiner de texto transcreve gravações de fala ou áudio em lote em tempo real com resultados intermediários. Você pode usar um modelo personalizado criado no portal de fala personalizado. Neste artigo, você aprenderá a baixar, instalar e executar um contêiner de fala para texto personalizado.
Para obter mais informações sobre pré-requisitos, validação de que um contêiner está em execução, execução de vários contêineres no mesmo host e execução de contêineres desconectados, consulte Instalar e executar contêineres de fala com o Docker.
Imagens de contentor
A imagem de contêiner de fala personalizada para texto para todas as versões e localidades suportadas pode ser encontrada no sindicato Microsoft Container Registry (MCR). Ele reside dentro do azure-cognitive-services/speechservices/ repositório e é chamado custom-speech-to-textde .

O nome da imagem de contêiner totalmente qualificada é, mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text. Anexe uma versão específica ou anexe :latest para obter a versão mais recente.
| Versão | Caminho |
|---|---|
| Mais Recente | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.6.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.6.0-amd64 |
Todas as tags, exceto latest, estão no seguinte formato e diferenciam maiúsculas de minúsculas:
<major>.<minor>.<patch>-<platform>-<prerelease>
Nota
O locale e voice para fala personalizada para contêineres de texto é determinado pelo modelo personalizado ingerido pelo contêiner.
As tags também estão disponíveis no formato JSON para sua conveniência. O corpo inclui o caminho do contêiner e a lista de tags. As tags não são classificadas por versão, mas "latest" são sempre incluídas no final da lista, conforme mostrado neste trecho:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
"2.10.0-amd64",
"2.11.0-amd64",
"2.12.0-amd64",
"2.12.1-amd64",
<--redacted for brevity-->
"latest"
]
}
Obter a imagem do contêiner com o docker pull
Você precisa dos pré-requisitos, incluindo o hardware necessário. Consulte também a alocação recomendada de recursos para cada contêiner de fala.
Use o comando docker pull para baixar uma imagem de contêiner do Microsoft Container Registry:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Nota
O locale e voice para contêineres de fala personalizados é determinado pelo modelo personalizado ingerido pelo contêiner.
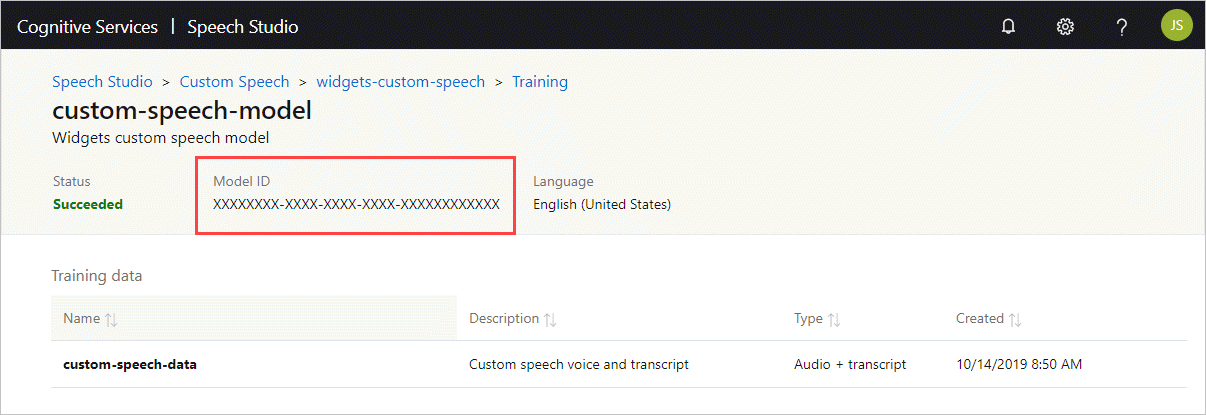
Obter o ID do modelo
Antes de executar o contêiner, você precisa saber a ID do modelo personalizado ou uma ID de modelo base. Ao executar o contêiner, você especifica uma das IDs de modelo a serem baixadas e usadas.
O modelo personalizado deve ser treinado usando o Speech Studio. Para obter informações sobre como obter a ID do modelo, consulte Ciclo de vida do modelo de fala personalizado.
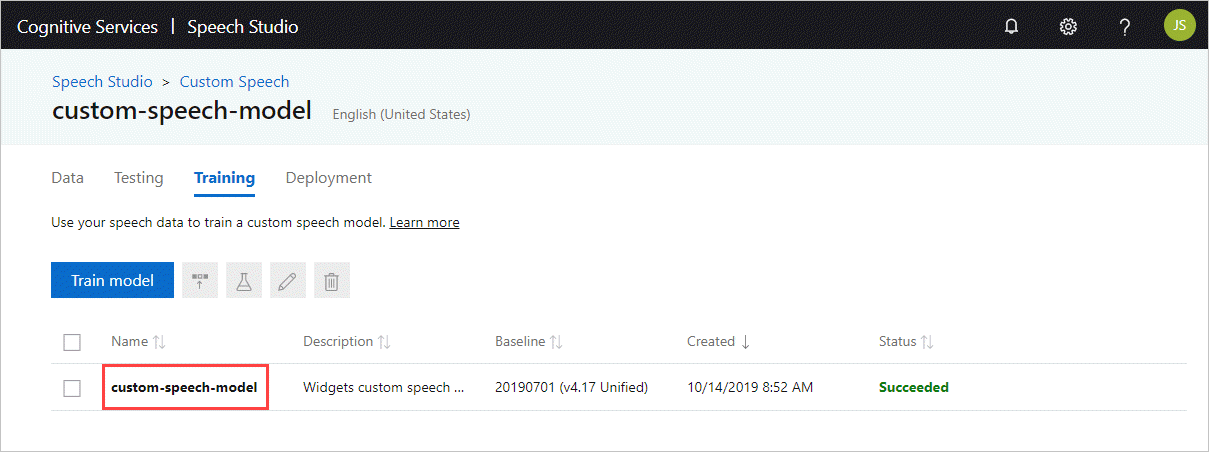
Obtenha a ID do modelo para usar como argumento para o ModelId parâmetro do docker run comando.
Download do modelo de exibição
Antes de executar o contêiner, você pode, opcionalmente, obter as informações de modelos de exibição disponíveis e optar por baixar esses modelos em seu contêiner de fala para texto para obter uma saída de exibição final altamente aprimorada. O download do modelo de exibição está disponível com o contêiner de fala personalizada para texto versão 3.1.0 e posterior.
Nota
Embora você use o docker run comando, o contêiner não é iniciado para serviço.
Você pode consultar ou baixar qualquer um ou todos esses tipos de modelo de exibição: Repontuação (Rescore), Pontuação (Punct), resegmentação (Resegment) e wfstitn (Wfstitn). Caso contrário, você pode usar a FullDisplay opção (com ou sem os outros tipos) para consultar ou baixar todos os tipos de modelos de exibição.
Defina o BaseModelLocale para consultar o modelo de exibição mais recente disponível na localidade de destino. Se você incluir vários tipos de modelo de exibição, o comando retornará os modelos de exibição mais recentes disponíveis para cada tipo. Por exemplo:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Defina o DisplayLocale para baixar o modelo de exibição mais recente disponível na localidade de destino. Ao definir DisplayLocaleo , você também deve especificar FullDisplay ou um subconjunto separado por espaço dos modelos de exibição. O comando baixa o modelo de exibição mais recente disponível para cada tipo especificado. Por exemplo:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Defina um parâmetro de ID de modelo para baixar um modelo de exibição específico: Repontuação (RescoreId), Pontuação (PunctId), resegmentação (ResegmentId) ou wfstitn (WfstitnId). Isso é semelhante a como você baixaria um modelo base através do ModelId parâmetro. Por exemplo, para baixar um modelo de exibição de repontuação, você pode usar o seguinte comando com o RescoreId parâmetro:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Nota
Se você definir mais de um parâmetro de consulta ou download, o comando priorizará nesta ordem: BaseModelLocale, ID do modelo e, em seguida DisplayLocale , (aplicável apenas para modelos de exibição).
Executar o contêiner com docker run
Use o comando docker run para executar o contêiner para serviço.
A tabela a seguir representa os vários docker run parâmetros e suas descrições correspondentes:
| Parâmetro | Description |
|---|---|
{VOLUME_MOUNT} |
A montagem do volume do computador host, que o Docker usa para persistir o modelo personalizado. Um exemplo é c:\CustomSpeech onde a c:\ unidade está localizada na máquina host. |
{MODEL_ID} |
A fala personalizada ou ID do modelo base. Para obter mais informações, consulte Obter a ID do modelo. |
{ENDPOINT_URI} |
O ponto de extremidade é necessário para medição e faturamento. Para obter mais informações, consulte argumentos de cobrança. |
{API_KEY} |
A chave API é necessária. Para obter mais informações, consulte argumentos de cobrança. |
Ao executar a fala personalizada para contêiner de texto, configure a porta, a memória e a CPU de acordo com os requisitos e recomendações personalizados de fala para contêiner de texto.
Aqui está um comando de exemplo docker run com valores de espaço reservado. Você deve especificar os VOLUME_MOUNTvalores , MODEL_ID, ENDPOINT_URIe API_KEY :
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Este comando:
- Executa uma fala personalizada para contêiner de texto a partir da imagem do contêiner.
- Aloca 4 núcleos de CPU e 8 GB de memória.
- Carrega a fala personalizada para o modelo de texto a partir da montagem de entrada de volume, por exemplo, C:\CustomSpeech.
- Expõe a porta TCP 5000 e aloca um pseudo-TTY para o contêiner.
- Faz o download do modelo dado o
ModelId(se não for encontrado na montagem do volume). - Se o modelo personalizado tiver sido baixado anteriormente, o
ModelIdserá ignorado. - Remove automaticamente o recipiente depois que ele sai. A imagem do contêiner ainda está disponível no computador host.
Para obter mais informações sobre docker run como contêineres de fala, consulte Instalar e executar contêineres de fala com o Docker.
Utilize o recipiente
Os contêineres de fala fornecem APIs de ponto de extremidade de consulta baseadas em websocket que são acessadas por meio do SDK de Fala e da CLI de Fala. Por padrão, o SDK de Fala e a CLI de Fala usam o serviço de Fala público. Para usar o contêiner, você precisa alterar o método de inicialização.
Importante
Ao usar o serviço de Fala com contêineres, certifique-se de usar a autenticação de host. Se você configurar a chave e a região, as solicitações irão para o serviço de Fala pública. Os resultados do serviço de Fala podem não ser os esperados. As solicitações de contêineres desconectados falharão.
Em vez de usar esta configuração de inicialização da nuvem do Azure:
var config = SpeechConfig.FromSubscription(...);
Use esta configuração com o host do contêiner:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
Em vez de usar esta configuração de inicialização da nuvem do Azure:
auto speechConfig = SpeechConfig::FromSubscription(...);
Use esta configuração com o host do contêiner:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
Em vez de usar esta configuração de inicialização da nuvem do Azure:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Use esta configuração com o host do contêiner:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
Em vez de usar esta configuração de inicialização da nuvem do Azure:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Use esta configuração com o host do contêiner:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
Em vez de usar esta configuração de inicialização da nuvem do Azure:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Use esta configuração com o host do contêiner:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
Em vez de usar esta configuração de inicialização da nuvem do Azure:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Use esta configuração com o host do contêiner:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
Em vez de usar esta configuração de inicialização da nuvem do Azure:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Use esta configuração com o host do contêiner:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
Em vez de usar esta configuração de inicialização da nuvem do Azure:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Use esta configuração com o ponto de extremidade do contêiner:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
Ao usar a CLI de fala em um contêiner, inclua a --host ws://localhost:5000/ opção. Você também deve especificar --key none para garantir que a CLI não tente usar uma chave de fala para autenticação. Para obter informações sobre como configurar a CLI de Fala, consulte Introdução à CLI de Fala do Azure AI.
Experimente o início rápido de fala para texto usando a autenticação de host em vez de chave e região.
Próximos passos
- Consulte a Visão geral dos contêineres de fala
- Revise configurar contêineres para obter definições de configuração
- Usar mais contêineres de IA do Azure