Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A:
![]() Cassandra
Cassandra
Este artigo descreve como funciona o particionamento no Azure Cosmos DB para Apache Cassandra.
A API para Cassandra usa particionamento para dimensionar as tabelas individuais em um espaço de chave para atender às necessidades de desempenho do seu aplicativo. As partições são formadas com base no valor de uma chave de partição associada a cada registro em uma tabela. Todos os registros em uma partição têm o mesmo valor de chave de partição. O Azure Cosmos DB gerencia de forma transparente e automática o posicionamento de partições entre os recursos físicos para satisfazer com eficiência as necessidades de escalabilidade e desempenho da tabela. À medida que os requisitos de taxa de transferência e armazenamento de um aplicativo aumentam, o Azure Cosmos DB move e equilibra os dados em um número maior de máquinas físicas.
Do ponto de vista do desenvolvedor, o particionamento se comporta da mesma maneira para o Azure Cosmos DB para Apache Cassandra como no Apache Cassandra nativo. No entanto, existem algumas diferenças nos bastidores.
Diferenças entre Apache Cassandra e Azure Cosmos DB
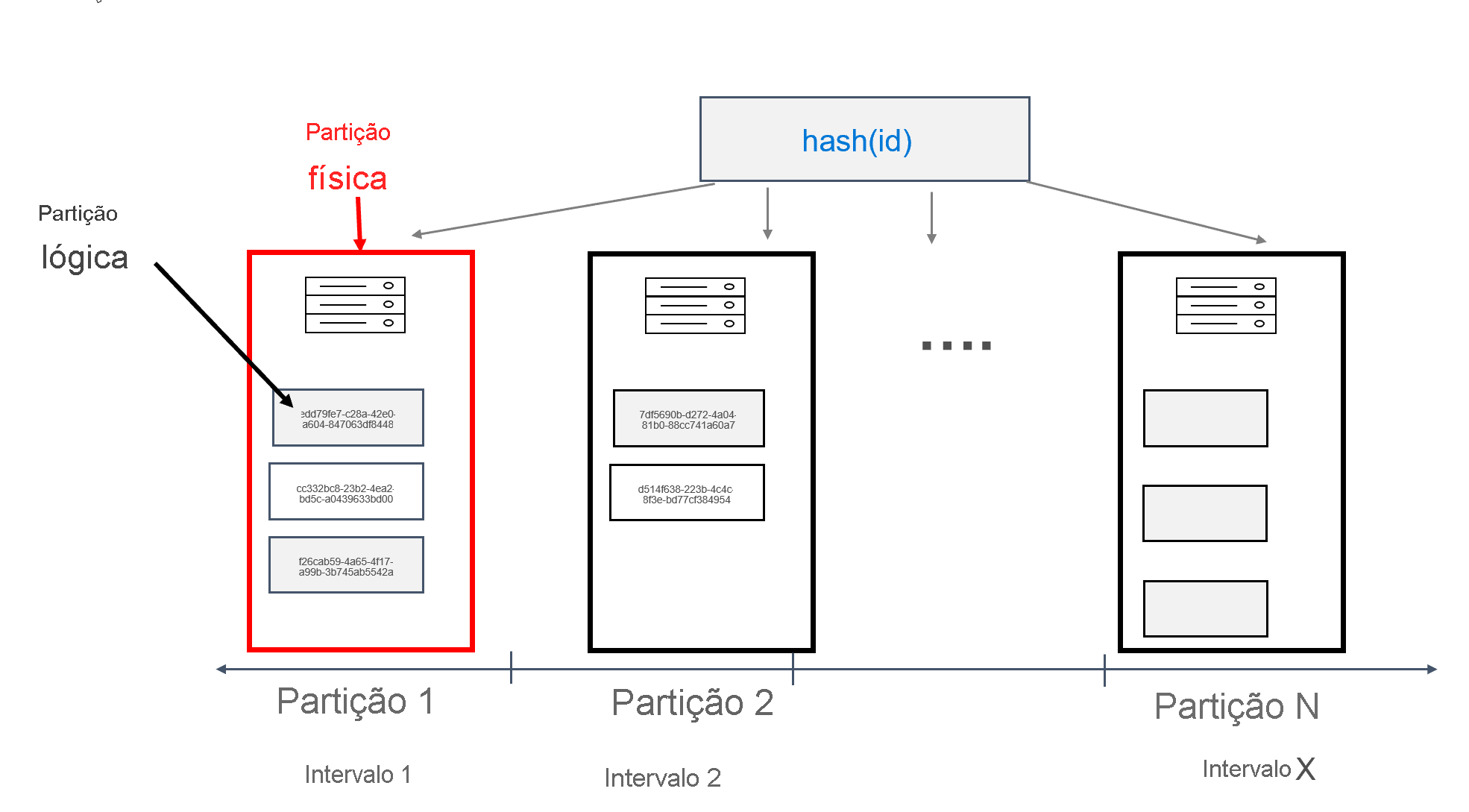
No Azure Cosmos DB, cada máquina na qual as partições são armazenadas é chamada de partição física. A partição física é semelhante a uma máquina virtual; uma unidade de computação dedicada ou um conjunto de recursos físicos. Cada partição armazenada nesta unidade de computação é referida como uma partição lógica no Azure Cosmos DB. Se você já está familiarizado com Apache Cassandra, você pode pensar em partições lógicas da mesma forma que você pensa em partições regulares em Cassandra.
O Apache Cassandra recomenda um limite de 100 MB no tamanho de um dado que pode ser armazenado em uma partição. A API para Cassandra para Azure Cosmos DB permite até 20 GB por partição lógica e até 30 GB de dados por partição física. No Azure Cosmos DB, ao contrário do Apache Cassandra, a capacidade de computação disponível na partição física é expressa usando uma única métrica chamada unidades de solicitação, que permite pensar em sua carga de trabalho em termos de solicitações (leituras ou gravações) por segundo, em vez de núcleos, memória ou IOPS. Isso pode tornar o planejamento de capacidade mais simples, uma vez que você entenda o custo de cada solicitação. Cada partição física pode ter até 10000 RUs de computação disponíveis. Você pode saber mais sobre as opções de escalabilidade lendo nosso artigo sobre escala elástica na API para Cassandra.
No Azure Cosmos DB, cada partição física consiste em um conjunto de réplicas, também conhecidas como conjuntos de réplicas, com pelo menos 4 réplicas por partição. Isso contrasta com o Apache Cassandra, onde é possível definir um fator de replicação de 1. No entanto, isso leva a baixa disponibilidade se o único nó com os dados cair. Na API para Cassandra há sempre um fator de replicação de 4 (quórum de 3). O Azure Cosmos DB gerencia automaticamente conjuntos de réplicas, enquanto eles precisam ser mantidos usando várias ferramentas no Apache Cassandra.
O Apache Cassandra tem um conceito de tokens, que são hashes de chaves de partição. Os tokens baseiam-se num hash murmur3 de 64 bytes, com valores que variam entre -2^63 e -2^63 - 1. Este intervalo é comumente referido como o "token ring" no Apache Cassandra. O token ring é distribuído em intervalos de tokens, e esses intervalos são divididos entre os nós presentes em um cluster Apache Cassandra nativo. A criação de partições do Azure Cosmos DB é implementada de forma semelhante, exceto que utiliza um algoritmo hash diferente e tem um token ring interno maior. No entanto, externamente expomos o mesmo intervalo de token que o Apache Cassandra, ou seja, -2^63 a -2^63 - 1.
Chave primária
Todas as tabelas na API para Cassandra devem ter um primary key definido. A sintaxe de uma chave primária é mostrada abaixo:
column_name cql_type_definition PRIMARY KEY
Suponha que queremos criar uma tabela de usuários, que armazena mensagens para diferentes usuários:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
Neste design, definimos o id campo como a chave primária. A chave primária funciona como o identificador do registro na tabela e também é usada como a chave de partição no Azure Cosmos DB. Se a chave primária for definida da maneira descrita anteriormente, haverá apenas um único registro em cada partição. Isso resultará em uma distribuição perfeitamente horizontal e escalável ao gravar dados no banco de dados e é ideal para casos de uso de pesquisa de chave-valor. O aplicativo deve fornecer a chave primária sempre que ler dados da tabela, para maximizar o desempenho de leitura.
Chave primária composta
Apache Cassandra também tem um conceito de compound keys. Um composto primary key consiste em mais de uma coluna, a primeira coluna é a partition key, e quaisquer colunas adicionais são a clustering keys. A sintaxe para a compound primary key é mostrada abaixo:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Suponha que queremos alterar o design acima e tornar possível recuperar mensagens de forma eficiente para um determinado usuário:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
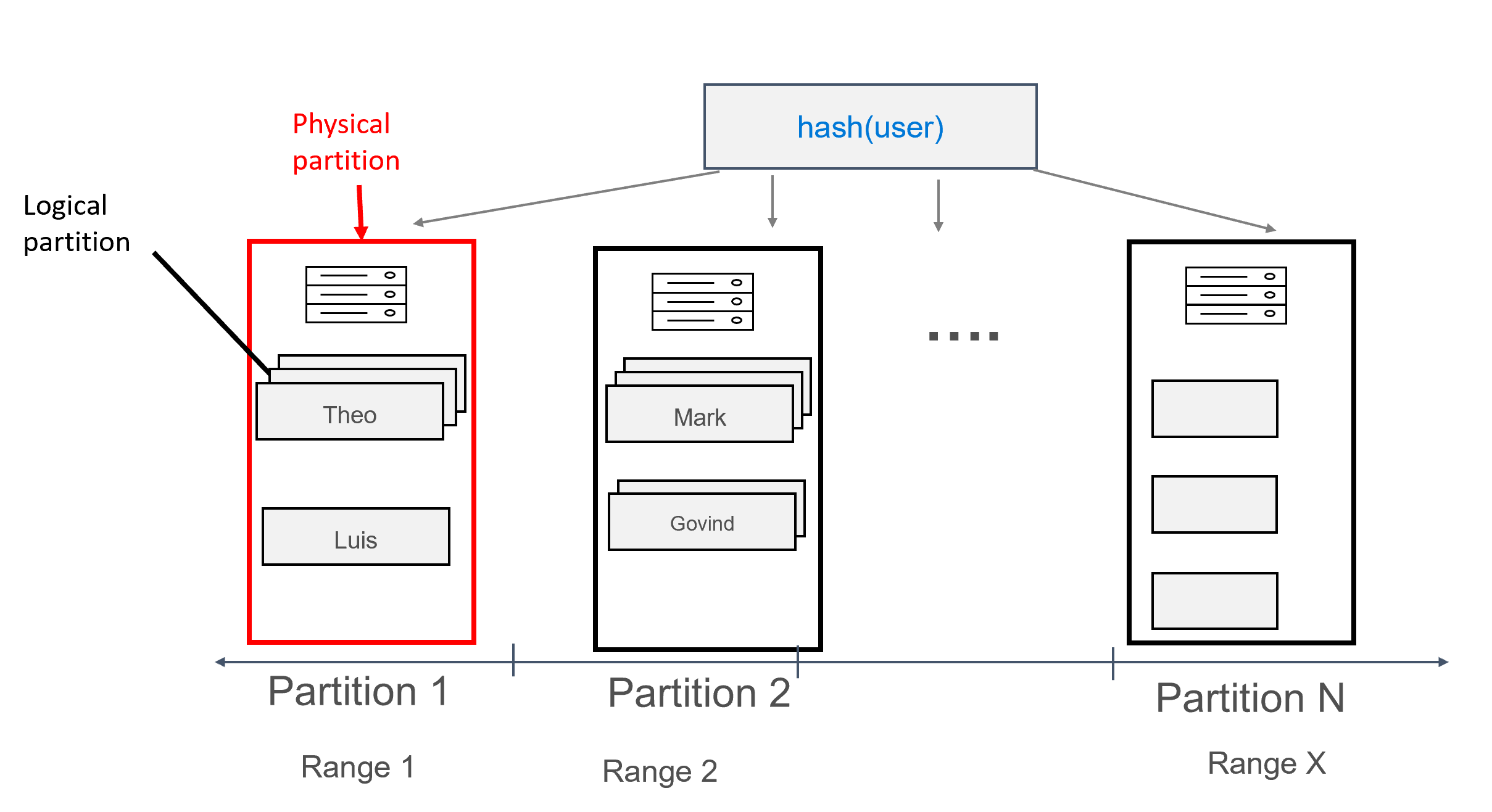
Neste design, agora estamos definindo user como a chave de partição e id como a chave de clustering. Você pode definir quantas chaves de clustering desejar, mas cada valor (ou uma combinação de valores) para a chave de clustering deve ser exclusivo para resultar em vários registros sendo adicionados à mesma partição, por exemplo:
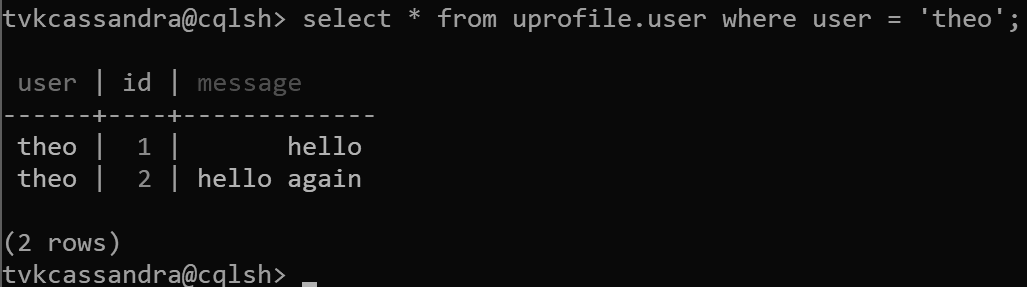
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Quando os dados são retornados, eles são classificados pela chave de clustering, como esperado no Apache Cassandra:
Aviso
Ao consultar dados em uma tabela que tenha uma chave primária composta, se você quiser filtrar a chave de partição e quaisquer outros campos não indexados além da chave de clustering, certifique-se de adicionar explicitamente um índice secundário na chave de partição:
CREATE INDEX ON uprofile.user (user);
O Azure Cosmos DB para Apache Cassandra não aplica índices a chaves de partição por padrão, e o índice nesse cenário pode melhorar significativamente o desempenho da consulta. Consulte o nosso artigo sobre indexação secundária para obter mais informações.
Com os dados modelados desta forma, vários registros podem ser atribuídos a cada partição, agrupados por usuário. Assim, podemos emitir uma consulta que é eficientemente roteada partition key pelo (neste caso, user) para obter todas as mensagens para um determinado usuário.
Chave de partição composta
As chaves de partição compostas funcionam essencialmente da mesma maneira que as chaves compostas, exceto que você pode especificar várias colunas como uma chave de partição composta. A sintaxe das chaves de partição compostas é mostrada abaixo:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Por exemplo, você pode ter o seguinte, onde a combinação exclusiva de e firstname formaria a chave de partição e lastname é a chave de id clustering:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Próximos passos
- Saiba mais sobre particionamento e dimensionamento horizontal no Azure Cosmos DB.
- Saiba mais sobre a taxa de transferência provisionada no Azure Cosmos DB.
- Saiba mais sobre a distribuição global no Azure Cosmos DB.