Usar um grafo de particionado no Azure Cosmos DB
APLICA-SE A: ![]() Gremlin
Gremlin
Um dos principais recursos da API para Gremlin no Azure Cosmos DB é a capacidade de lidar com gráficos de grande escala por meio de dimensionamento horizontal. Os contêineres podem ser dimensionados independentemente em termos de armazenamento e rendimento. Você pode criar contêineres no Azure Cosmos DB que podem ser dimensionados automaticamente para armazenar dados de um gráfico. Os dados são balanceados automaticamente com base na chave de partição especificada.
O particionamento é feito internamente se se espera que o contêiner armazene mais de 20 GB de tamanho ou se você quiser alocar mais de 10.000 unidades de solicitação por segundo (RUs). Os dados são automaticamente particionados com base na chave de partição especificada. A chave de partição é necessária se você criar contêineres gráficos a partir do portal do Azure ou das versões 3.x ou superiores dos drivers Gremlin. A chave de partição não é necessária se você usar versões 2.x ou inferiores dos drivers Gremlin.
Os mesmos princípios gerais do mecanismo de particionamento do Azure Cosmos DB aplicam-se com algumas otimizações específicas de gráficos descritas abaixo.
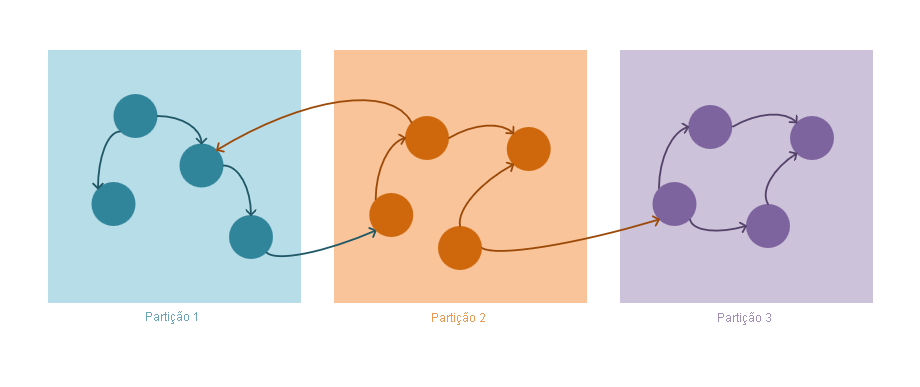
Mecanismo de particionamento de gráficos
As diretrizes a seguir descrevem como a estratégia de particionamento no Azure Cosmos DB opera:
Ambos os vértices e arestas são armazenados como documentos JSON.
Os vértices requerem uma chave de partição. Essa chave determinará em qual partição o vértice será armazenado através de um algoritmo de hash. O nome da propriedade da chave de partição é definido ao criar um novo contêiner e tem um formato:
/partitioning-key-name.As bordas serão armazenadas com seu vértice de origem. Em outras palavras, para cada vértice, sua chave de partição define onde eles são armazenados junto com suas bordas de saída. Essa otimização é feita para evitar consultas entre partições ao usar a
out()cardinalidade em consultas gráficas.As arestas contêm referências aos vértices para os quais apontam. Todas as arestas são armazenadas com as chaves de partição e IDs dos vértices para os quais estão apontando. Esse cálculo faz com que todas as
out()consultas de direção sejam sempre uma consulta particionada com escopo, e não uma consulta cega entre partições.As consultas de gráfico precisam especificar uma chave de partição. Para aproveitar ao máximo o particionamento horizontal no Azure Cosmos DB, a chave de partição deve ser especificada quando um único vértice é selecionado, sempre que possível. A seguir estão as consultas para selecionar um ou vários vértices em um gráfico particionado:
/ide/labelnão são suportados como chaves de partição para um contêiner na API para Gremlin.Selecionando um vértice por ID e, em seguida , usando a
.has()etapa para especificar a propriedade da chave de partição:g.V('vertex_id').has('partitionKey', 'partitionKey_value')Selecionando um vértice especificando uma tupla incluindo o valor da chave de partição e o ID:
g.V(['partitionKey_value', 'vertex_id'])Selecionando um conjunto de vértices com seus IDs e especificando uma lista de valores de chave de partição:
g.V('vertex_id0', 'vertex_id1', 'vertex_id2', …).has('partitionKey', within('partitionKey_value0', 'partitionKey_value01', 'partitionKey_value02', …)Usando a estratégia Partition no início de uma consulta e especificando uma partição para o escopo do restante da consulta Gremlin:
g.withStrategies(PartitionStrategy.build().partitionKey('partitionKey').readPartitions('partitionKey_value').create()).V()
Práticas recomendadas ao usar um gráfico particionado
Use as seguintes diretrizes para garantir o desempenho e a escalabilidade ao usar gráficos particionados com contêineres ilimitados:
Sempre especifique o valor da chave de partição ao consultar um vértice. Obter vértice de uma partição conhecida é uma maneira de alcançar o desempenho. Todas as operações de adjacência subsequentes sempre terão como escopo uma partição, uma vez que as bordas contêm ID de referência e chave de partição para seus vértices de destino.
Use a direção de saída ao consultar bordas sempre que possível. Como mencionado acima, as arestas são armazenadas com seus vértices de origem na direção de saída. Assim, as chances de recorrer a consultas entre partições são minimizadas quando os dados e consultas são projetados com esse padrão em mente. Pelo contrário, a
in()consulta será sempre uma consulta fan-out cara.Escolha uma chave de partição que distribuirá uniformemente os dados entre as partições. Esta decisão depende fortemente do modelo de dados da solução. Leia mais sobre como criar uma chave de partição apropriada em Particionamento e dimensionar no Azure Cosmos DB.
Otimize consultas para obter dados dentro dos limites de uma partição. Uma estratégia de particionamento ideal seria alinhada aos padrões de consulta. As consultas que obtêm dados de uma única partição fornecem o melhor desempenho possível.
Próximos passos
Em seguida, você pode continuar a ler os seguintes artigos:
- Saiba mais sobre Particionar e dimensionar no Azure Cosmos DB.
- Saiba mais sobre o suporte Gremlin na API para Gremlin.
- Saiba mais sobre a Introdução à API para Gremlin.