Como modelar e criar partições de dados no Azure Cosmos DB com um exemplo do mundo real
APLICA-SE A: ![]() NoSQL
NoSQL
Este artigo baseia-se em vários conceitos do Azure Cosmos DB, como modelagem de dados, particionamento e taxa de transferência provisionada, para demonstrar como lidar com um exercício de design de dados do mundo real.
Se você costuma trabalhar com bancos de dados relacionais, provavelmente criou hábitos e intuições sobre como projetar um modelo de dados. Devido às restrições específicas, mas também aos pontos fortes exclusivos do Azure Cosmos DB, a maioria dessas práticas recomendadas não se traduz bem e pode arrastá-lo para soluções subótimas. O objetivo deste artigo é guiá-lo pelo processo completo de modelagem de um caso de uso do mundo real no Azure Cosmos DB, desde a modelagem de item até a colocalização de entidade e o particionamento de contêineres.
Transfira ou veja um código-fonte gerado pela comunidade que ilustra os conceitos deste artigo.
Importante
Um colaborador da comunidade contribuiu com este exemplo de código e a equipe do Azure Cosmos DB não oferece suporte à sua manutenção.
Cenário
Para este exercício, vamos considerar o domínio de uma plataforma de blogs onde os usuários podem criar posts. Os usuários também podem curtir e adicionar comentários a essas postagens.
Gorjeta
Destacamos algumas palavras em itálico, essas palavras identificam o tipo de "coisas" que nosso modelo terá que manipular.
Adicionando mais requisitos à nossa especificação:
- Uma primeira página exibe um feed de postagens criadas recentemente,
- Podemos buscar todas as publicações para um usuário, todos os comentários para uma publicação e todas as curtidas para uma publicação,
- As publicações são devolvidas com o nome de utilizador dos seus autores e uma contagem de quantos comentários e gostos têm,
- Comentários e curtidas também são retornados com o nome de usuário dos usuários que os criaram,
- Quando exibidas como listas, as publicações só precisam apresentar um resumo truncado de seu conteúdo.
Identificar os principais padrões de acesso
Para começar, damos alguma estrutura à nossa especificação inicial, identificando os padrões de acesso da nossa solução. Ao projetar um modelo de dados para o Azure Cosmos DB, é importante entender quais solicitações nosso modelo deve servir para garantir que o modelo atenda a essas solicitações de forma eficiente.
Para tornar o processo geral mais fácil de seguir, categorizamos essas diferentes solicitações como comandos ou consultas, tomando emprestado algum vocabulário do CQRS. No CQRS, comandos são solicitações de gravação (ou seja, intenções de atualizar o sistema) e consultas são solicitações somente leitura.
Aqui está a lista de solicitações que nossa plataforma expõe:
- [C1] Criar/editar um utilizador
- [Q1] Recuperar um usuário
- [C2] Criar/editar uma publicação
- [2ºT] Recuperar uma publicação
- [3ºT] Listar as postagens de um usuário de forma resumida
- [C3] Criar um comentário
- [4ºT] Listar os comentários de uma publicação
- [C4] Curtir uma publicação
- [Q5] Listar as curtidas de uma publicação
- [Q6] Listar os x posts mais recentes criados em forma curta (feed)
Nesta fase, não pensamos nos detalhes do que cada entidade (usuário, post etc.) contém. Esta etapa geralmente está entre as primeiras a serem abordadas ao projetar em uma loja relacional. Começamos com este passo primeiro porque temos que descobrir como essas entidades se traduzem em termos de tabelas, colunas, chaves estrangeiras etc. É muito menos uma preocupação com um banco de dados de documentos que não impõe nenhum esquema na gravação.
A principal razão pela qual é importante identificar nossos padrões de acesso desde o início, é porque essa lista de solicitações será nossa suíte de teste. Toda vez que iteramos nosso modelo de dados, analisamos cada uma das solicitações e verificamos seu desempenho e escalabilidade. Calculamos as unidades de solicitação consumidas em cada modelo e as otimizamos. Todos esses modelos usam a política de indexação padrão e você pode substituí-la indexando propriedades específicas, o que pode melhorar ainda mais o consumo e a latência da RU.
V1: Uma primeira versão
Começamos com dois recipientes: users e posts.
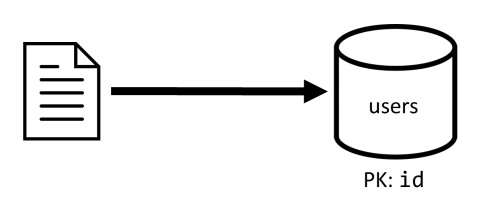
Contêiner de usuários
Este contêiner armazena apenas itens do usuário:
{
"id": "<user-id>",
"username": "<username>"
}
Nós particionamos esse contêiner por id, o que significa que cada partição lógica dentro desse contêiner contém apenas um item.
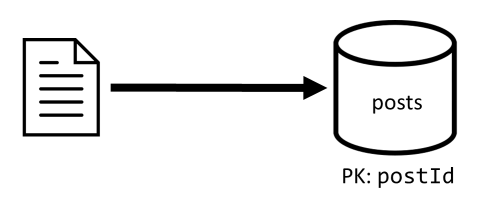
Contentor de postes
Esse contêiner hospeda entidades como postagens, comentários e curtidas:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Nós particionamos esse contêiner por postId, o que significa que cada partição lógica dentro desse contêiner contém um post, todos os comentários para esse post e todos os gostos para esse post.
Introduzimos uma type propriedade nos itens armazenados neste contêiner para distinguir entre os três tipos de entidades que esse contêiner hospeda.
Além disso, optamos por fazer referência a dados relacionados em vez de incorporá-los (verifique esta seção para obter detalhes sobre esses conceitos) porque:
- não há limite máximo para quantas publicações um usuário pode criar,
- os lugares podem ser arbitrariamente longos,
- não há limite máximo para quantos comentários e curtidas uma publicação pode ter,
- queremos poder adicionar um comentário ou um gosto a uma publicação sem ter de atualizar a publicação em si.
Qual é o desempenho do nosso modelo?
Agora é hora de avaliar o desempenho e a escalabilidade da nossa primeira versão. Para cada uma das solicitações identificadas anteriormente, medimos sua latência e quantas unidades de solicitação ela consome. Essa medição é feita em relação a um conjunto de dados fictícios contendo 100.000 usuários com 5 a 50 postagens por usuário, e até 25 comentários e 100 curtidas por postagem.
[C1] Criar/editar um utilizador
Esta solicitação é simples de implementar, pois acabamos de criar ou atualizar um item no users contêiner. Os pedidos bem espalhados por todas as partições graças à id chave de partição.
| Latência | Taxa RU | Desempenho |
|---|---|---|
7 em |
5.71 RU |
✅ |
[Q1] Recuperar um usuário
A recuperação de um usuário é feita lendo o item correspondente do users contêiner.
| Latência | Taxa RU | Desempenho |
|---|---|---|
2 em |
1 RU |
✅ |
[C2] Criar/editar uma publicação
Da mesma forma que [C1], só temos que escrever posts no contêiner.
| Latência | Taxa RU | Desempenho |
|---|---|---|
9 em |
8.76 RU |
✅ |
[2ºT] Recuperar uma publicação
Começamos por recuperar o documento correspondente do posts contentor. Mas isso não é suficiente, de acordo com nossa especificação, também temos que agregar o nome de usuário do autor do post, contagens de comentários e contagens de curtidas para o post. As agregações listadas exigem que mais 3 consultas SQL sejam emitidas.
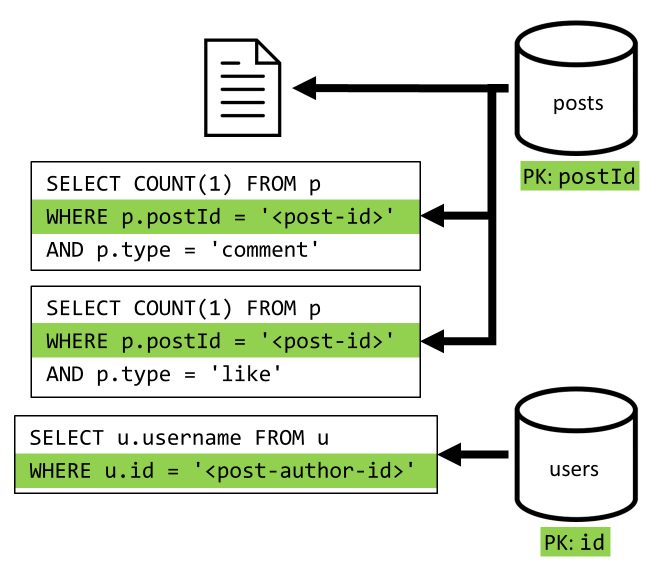
Cada um dos filtros mais consultas na chave de partição de seu respetivo contêiner, que é exatamente o que queremos maximizar o desempenho e a escalabilidade. Mas eventualmente temos que executar quatro operações para retornar um único post, então vamos melhorar isso em uma próxima iteração.
| Latência | Taxa RU | Desempenho |
|---|---|---|
9 em |
19.54 RU |
⚠ |
[3ºT] Listar as postagens de um usuário de forma resumida
Primeiro, temos que recuperar as postagens desejadas com uma consulta SQL que busca as postagens correspondentes a esse usuário específico. Mas também temos que emitir mais consultas para agregar o nome de usuário do autor e as contagens de comentários e curtidas.
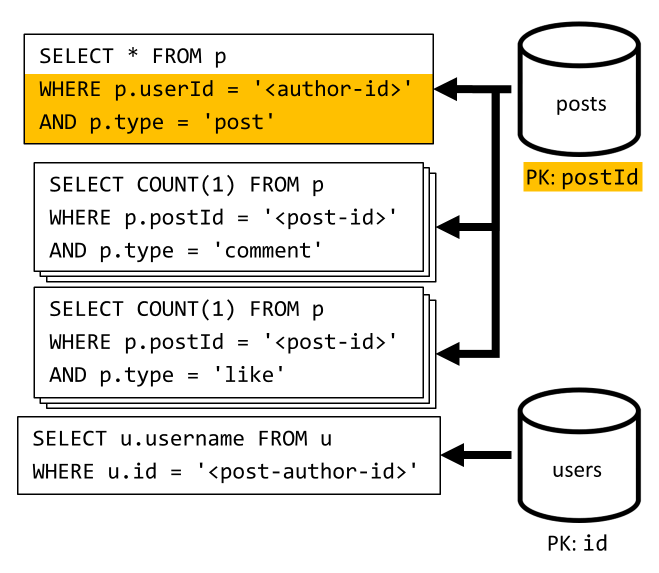
Esta implementação apresenta muitas desvantagens:
- as consultas que agregam as contagens de comentários e gostos têm de ser emitidas para cada publicação devolvida pela primeira consulta,
- A consulta principal não filtra a chave de partição do
postscontêiner, levando a uma distribuição e uma verificação de partição no contêiner.
| Latência | Taxa RU | Desempenho |
|---|---|---|
130 em |
619.41 RU |
⚠ |
[C3] Criar um comentário
Um comentário é criado escrevendo o item correspondente no posts contêiner.
| Latência | Taxa RU | Desempenho |
|---|---|---|
7 em |
8.57 RU |
✅ |
[4ºT] Listar os comentários de uma publicação
Começamos com uma consulta que busca todos os comentários para esse post e, mais uma vez, também precisamos agregar nomes de usuários separadamente para cada comentário.
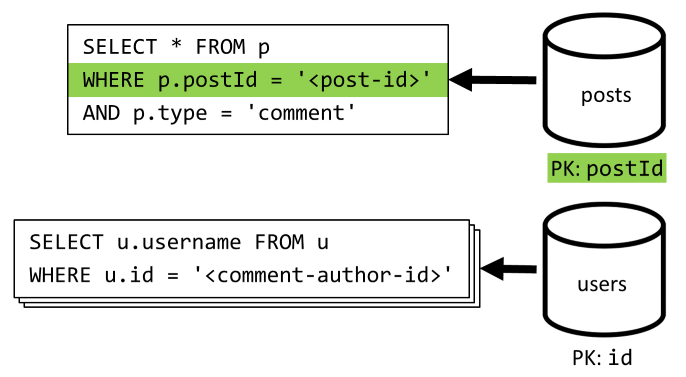
Embora a consulta principal filtre a chave de partição do contêiner, agregar os nomes de usuário separadamente penaliza o desempenho geral. Melhoramos isso mais tarde.
| Latência | Taxa RU | Desempenho |
|---|---|---|
23 em |
27.72 RU |
⚠ |
[C4] Curtir uma publicação
Assim como [C3], criamos o item correspondente no posts contêiner.
| Latência | Taxa RU | Desempenho |
|---|---|---|
6 em |
7.05 RU |
✅ |
[Q5] Listar as curtidas de uma publicação
Assim como [Q4], consultamos as curtidas dessa postagem e, em seguida, agregamos seus nomes de usuário.
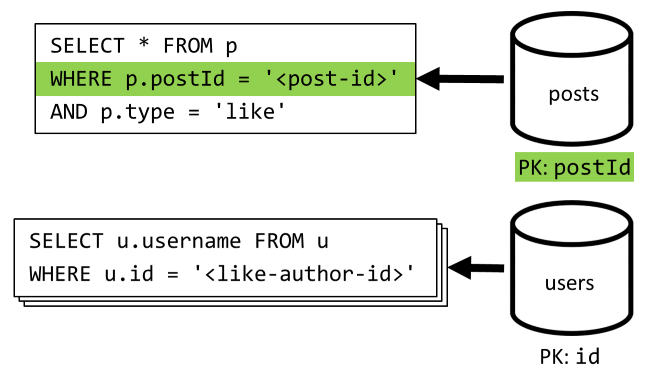
| Latência | Taxa RU | Desempenho |
|---|---|---|
59 em |
58.92 RU |
⚠ |
[Q6] Listar os x posts mais recentes criados em forma curta (feed)
Buscamos as postagens mais recentes consultando o posts contêiner classificado por data de criação decrescente e, em seguida, agregamos nomes de usuário e contagens de comentários e curtidas para cada uma das postagens.

Mais uma vez, nossa consulta inicial não filtra a chave de partição do contêiner, o que dispara uma distribuição dispendiosa posts . Este é ainda pior, pois visamos um conjunto de resultados maior e classificamos os resultados com uma ORDER BY cláusula, o que o torna mais caro em termos de unidades de solicitação.
| Latência | Taxa RU | Desempenho |
|---|---|---|
306 em |
2063.54 RU |
⚠ |
Refletindo sobre o desempenho da V1
Observando os problemas de desempenho que enfrentamos na seção anterior, podemos identificar duas classes principais de problemas:
- alguns pedidos requerem a emissão de várias consultas para recolher todos os dados de que necessitamos para devolver,
- Algumas consultas não filtram a chave de partição dos contêineres que segmentam, levando a uma distribuição que impede nossa escalabilidade.
Vamos resolver cada um desses problemas, começando pelo primeiro.
V2: Introdução à desnormalização para otimizar consultas de leitura
A razão pela qual temos que emitir mais solicitações em alguns casos é porque os resultados da solicitação inicial não contêm todos os dados que precisamos retornar. A desnormalização de dados resolve esse tipo de problema em nosso conjunto de dados ao trabalhar com um armazenamento de dados não relacional, como o Azure Cosmos DB.
No nosso exemplo, modificamos os itens da publicação para adicionar o nome de utilizador do autor da publicação, a contagem de comentários e a contagem de gostos:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Também modificamos itens de comentários e curtidas para adicionar o nome de usuário do usuário que os criou:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Desnormalizando a contagem de comentários e curtidas
O que queremos alcançar é que cada vez que adicionamos um comentário ou um gosto, também incrementamos o commentCount ou o likeCount no post correspondente. Como postId particiona nosso posts contêiner, o novo item (comentário ou like) e seu post correspondente ficam na mesma partição lógica. Como resultado, podemos usar um procedimento armazenado para executar essa operação.
Quando você cria um comentário ([C3]), em vez de apenas adicionar um novo item no posts contêiner, chamamos o seguinte procedimento armazenado nesse contêiner:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Este procedimento armazenado usa o ID da postagem e o corpo do novo comentário como parâmetros, então:
- recupera o post
- incrementa a
commentCount - substitui o cargo
- adiciona o novo comentário
Como os procedimentos armazenados são executados como transações atômicas, o valor commentCount e o número real de comentários sempre permanecem sincronizados.
Obviamente, chamamos um procedimento armazenado semelhante ao adicionar novas curtidas para incrementar o likeCount.
Desnormalizando nomes de usuário
Os nomes de usuário exigem uma abordagem diferente, pois os usuários não apenas ficam em partições diferentes, mas em um contêiner diferente. Quando temos que desnormalizar dados entre partições e contêineres, podemos usar o feed de alterações do contêiner de origem.
Em nosso exemplo, usamos o feed de alterações do users contêiner para reagir sempre que os usuários atualizam seus nomes de usuário. Quando isso acontece, propagamos a alteração chamando outro procedimento armazenado no posts contêiner:
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Este procedimento armazenado usa o ID do usuário e o novo nome de usuário do usuário como parâmetros, então:
- busca todos os itens correspondentes ao
userId(que podem ser postagens, comentários ou curtidas) - para cada um desses elementos
- substitui a seringa
userUsername - substitui o item
- substitui a seringa
Importante
Essa operação é cara porque requer que esse procedimento armazenado seja executado em cada partição do posts contêiner. Assumimos que a maioria dos utilizadores escolhe um nome de utilizador adequado durante a inscrição e nunca o altera, pelo que esta atualização será executada muito raramente.
Quais são os ganhos de desempenho da V2?
Vamos falar sobre alguns dos ganhos de desempenho da V2.
[2ºT] Recuperar uma publicação
Agora que nossa desnormalização está em vigor, só temos que buscar um único item para lidar com essa solicitação.
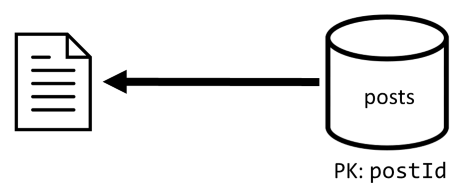
| Latência | Taxa RU | Desempenho |
|---|---|---|
2 em |
1 RU |
✅ |
[4ºT] Listar os comentários de uma publicação
Aqui, novamente, podemos poupar as solicitações extras que buscaram os nomes de usuário e acabar com uma única consulta que filtra na chave de partição.
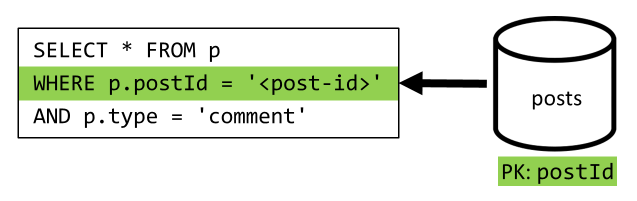
| Latência | Taxa RU | Desempenho |
|---|---|---|
4 em |
7.72 RU |
✅ |
[Q5] Listar as curtidas de uma publicação
Exatamente a mesma situação ao listar as curtidas.
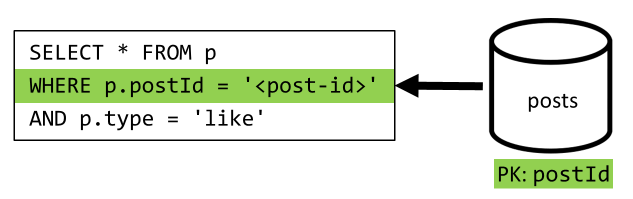
| Latência | Taxa RU | Desempenho |
|---|---|---|
4 em |
8.92 RU |
✅ |
V3: Certificando-se de que todas as solicitações são escaláveis
Ainda há duas solicitações que não otimizamos totalmente ao analisar nossas melhorias gerais de desempenho. Estes pedidos são [Q3] e [Q6]. São as solicitações que envolvem consultas que não filtram a chave de partição dos contêineres a que se destinam.
[3ºT] Listar as postagens de um usuário de forma resumida
Este pedido já beneficia das melhorias introduzidas na V2, o que poupa mais consultas.

Mas a consulta restante ainda não está filtrando na chave de partição do posts contêiner.
A maneira de pensar sobre esta situação é simples:
- Esta solicitação tem que filtrar o
userIdporque queremos buscar todas as postagens para um usuário específico. - Ele não funciona bem porque é executado contra o
postscontêiner, que não temuserIdparticionamento. - Afirmando o óbvio, resolveríamos nosso problema de desempenho executando essa solicitação em um contêiner particionado com
userId. - Acontece que já temos um recipiente assim: o
userscontêiner!
Assim, introduzimos um segundo nível de desnormalização, duplicando postes inteiros para o users contêiner. Ao fazer isso, efetivamente obtemos uma cópia de nossos posts, apenas particionados ao longo de uma dimensão diferente, tornando-os muito mais eficientes para recuperar por seus userId.
O users contêiner agora contém dois tipos de itens:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Neste exemplo:
- Introduzimos um
typecampo no item de utilizador para distinguir os utilizadores das publicações, - Também adicionamos um
userIdcampo no item de usuário, que é redundante com oidcampo, mas é necessário, pois o contêiner agora está particionadouserscomuserId(e nãoidcomo anteriormente)
Para conseguir essa desnormalização, usamos mais uma vez o feed de mudança. Desta vez, reagimos na alimentação de mudança do posts contêiner para despachar qualquer post novo ou atualizado para o users contêiner. E como as publicações de listagem não precisam retornar o conteúdo completo, podemos truncá-las no processo.
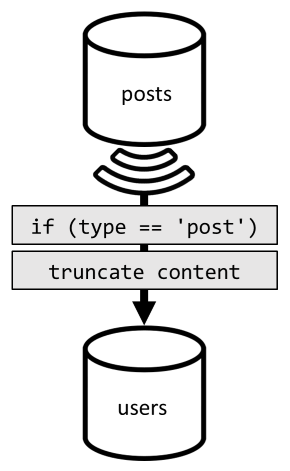
Agora podemos rotear nossa consulta para o users contêiner, filtrando a chave de partição do contêiner.

| Latência | Taxa RU | Desempenho |
|---|---|---|
4 em |
6.46 RU |
✅ |
[Q6] Listar os x posts mais recentes criados em forma curta (feed)
Temos que lidar com uma situação semelhante aqui: mesmo depois de poupar mais consultas deixadas desnecessárias pela desnormalização introduzida na V2, a consulta restante não filtra a chave de partição do contêiner:
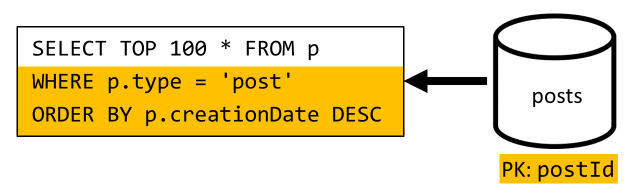
Seguindo a mesma abordagem, maximizar o desempenho e a escalabilidade dessa solicitação requer que ela atinja apenas uma partição. Apenas bater em uma única partição é concebível porque só temos que retornar um número limitado de itens. Para preencher a página inicial da nossa plataforma de blogs, só precisamos obter as 100 postagens mais recentes, sem a necessidade de paginar todo o conjunto de dados.
Assim, para otimizar este último pedido, introduzimos um terceiro contentor no nosso design, inteiramente dedicado a servir este pedido. Desnormalizamos nossos posts para esse novo feed contêiner:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
O type campo particiona este recipiente, que está sempre post em nossos itens. Isso garante que todos os itens nesse contêiner fiquem na mesma partição.
Para alcançar a desnormalização, basta nos conectar ao pipeline de alimentação de mudança que introduzimos anteriormente para despachar os postes para esse novo contêiner. Uma coisa importante a ter em mente é que precisamos ter certeza de que armazenamos apenas os 100 posts mais recentes; caso contrário, o conteúdo do contêiner pode crescer além do tamanho máximo de uma partição. Essa limitação pode ser implementada chamando um pós-gatilho toda vez que um documento é adicionado no contêiner:
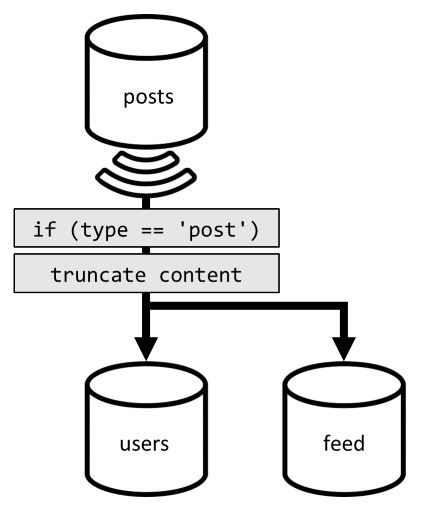
Aqui está o corpo do pós-gatilho que trunca a coleção:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
A etapa final é redirecionar nossa consulta para nosso novo feed contêiner:
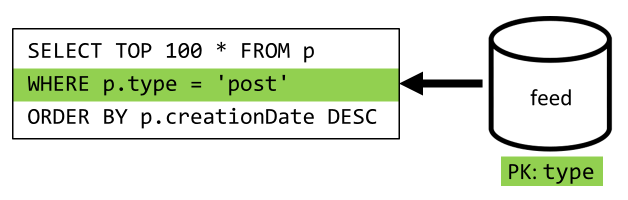
| Latência | Taxa RU | Desempenho |
|---|---|---|
9 em |
16.97 RU |
✅ |
Conclusão
Vamos dar uma olhada nas melhorias gerais de desempenho e escalabilidade que introduzimos nas diferentes versões do nosso design.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [Q1] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [2ºT] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [3ºT] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [4ºT] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
Otimizamos um cenário de leitura pesada
Você deve ter notado que concentramos nossos esforços para melhorar o desempenho de solicitações de leitura (consultas) em detrimento de solicitações de gravação (comandos). Em muitos casos, as operações de gravação agora desencadeiam a desnormalização subsequente por meio de feeds de mudança, o que as torna mais caras computacionalmente e mais longas para se materializar.
Justificamos esse foco no desempenho de leitura pelo fato de que uma plataforma de blogs (como a maioria dos aplicativos sociais) é de leitura pesada. Uma carga de trabalho de leitura pesada indica que a quantidade de solicitações de leitura que ela tem que atender geralmente é maior do que o número de solicitações de gravação. Portanto, faz sentido tornar as solicitações de gravação mais caras de executar, a fim de permitir que as solicitações de leitura sejam mais baratas e tenham melhor desempenho.
Se olharmos para a otimização mais extrema que fizemos, [Q6] passou de 2000+ RUs para apenas 17 RUs, conseguimos isso desnormalizando posts a um custo de cerca de 10 RUs por item. Como serviríamos muito mais solicitações de feed do que criação ou atualizações de posts, o custo dessa desnormalização é insignificante, considerando a economia geral.
A desnormalização pode ser aplicada incrementalmente
As melhorias de escalabilidade que exploramos neste artigo envolvem a desnormalização e a duplicação de dados em todo o conjunto de dados. Deve-se notar que essas otimizações não precisam ser colocadas em prática no dia 1. As consultas que filtram em chaves de partição têm melhor desempenho em escala, mas as consultas entre partições podem ser aceitáveis se forem chamadas raramente ou em relação a um conjunto de dados limitado. Se você está apenas construindo um protótipo ou lançando um produto com uma base de usuários pequena e controlada, provavelmente pode poupar essas melhorias para mais tarde. O importante, então, é monitorar o desempenho do seu modelo para que você possa decidir se e quando é hora de trazê-los.
O feed de alterações que usamos para distribuir atualizações para outros contêineres armazena todas essas atualizações persistentemente. Essa persistência torna possível solicitar todas as atualizações desde a criação do contêiner e das visualizações desnormalizadas do bootstrap como uma operação única de recuperação, mesmo que seu sistema já tenha muitos dados.
Próximos passos
Após esta introdução à modelagem prática de dados e particionamento, você pode querer verificar os seguintes artigos para rever os conceitos que abordamos:
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários