Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
O Azure Cosmos DB para PostgreSQL está numa fase de reforma e já não é recomendado para novos projetos. Em vez disso, use um destes dois serviços:
Para cargas de trabalho PostgreSQL : utilize a funcionalidade Elastic Clusters do Azure Database For PostgreSQL para utilizar as funcionalidades de escalonamento horizontal e distribuição do PostgreSQL contidas na extensão open source Citus. Para orientações sobre migração, consulte migrar para Azure Database para PostgreSQL com Elastic Cluster.
Para cargas de trabalho NoSQL , utilize o Azure Cosmos DB para NoSQL como solução de base de dados distribuída que inclui um acordo de nível de serviço (SLA) de disponibilidade de 99,999%, escalabilidade automática instantânea e failover automático em múltiplas regiões.
Colocation significa armazenar informações relacionadas juntas nos mesmos nós. As consultas podem ser rápidas quando todos os dados necessários estão disponíveis sem qualquer tráfego de rede. Colocar dados relacionados em nós diferentes permite que as consultas sejam executadas de forma eficiente em paralelo em cada nó.
Colocalização de dados para tabelas distribuídas por hash
No Azure Cosmos DB para PostgreSQL, uma linha é armazenada em um fragmento se o hash do valor na coluna de distribuição estiver dentro do intervalo de hash do fragmento. Os fragmentos com o mesmo intervalo de hashes são sempre colocados no mesmo nó. As linhas com valores de coluna de distribuição iguais estão sempre no mesmo nó em todas as tabelas. O conceito de tabelas distribuídas por hash também é conhecido como fragmentação baseada em linha. Na fragmentação baseada em esquema, as tabelas dentro de um esquema distribuído são sempre colocalizadas.
Um exemplo prático de colocation
Considere as seguintes tabelas que podem fazer parte de um SaaS de análise web multilocatário.
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Agora, queremos responder a consultas que possam ser emitidas por um painel voltado para o cliente. Um exemplo de consulta é "Retornar o número de visitas na semana anterior para todas as páginas começando com '/blog' no locatário seis."
Se nossos dados estivessem em um único servidor PostgreSQL, poderíamos facilmente expressar nossa consulta usando o rico conjunto de operações relacionais oferecidas pelo SQL:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Enquanto o conjunto de trabalho para esta consulta couber na memória, uma tabela num único servidor é uma solução apropriada. Vamos considerar as oportunidades de dimensionar o modelo de dados com o Azure Cosmos DB para PostgreSQL.
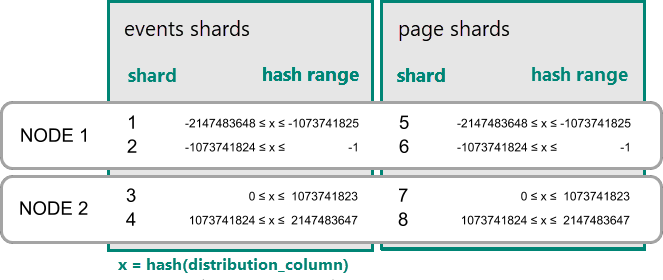
Distribuir tabelas por ID
As consultas de servidor único começam a diminuir à medida que o número de locatários e os dados armazenados para cada locatário crescem. O conjunto de trabalho deixa de caber na memória e a CPU transforma-se num ponto de estrangulamento.
Nesse caso, podemos fragmentar os dados em muitos nós usando o Azure Cosmos DB para PostgreSQL. A primeira e mais importante escolha que precisamos fazer quando decidimos fragmentar é a coluna de distribuição. Vamos começar com uma escolha ingênua de usar event_id para a tabela de eventos e page_id para a page tabela:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Quando os dados estão dispersos por diferentes trabalhadores, não podemos realizar uma junção como faríamos em um único nó PostgreSQL. Em vez disso, precisamos emitir duas perguntas:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Posteriormente, os resultados das duas etapas precisam ser combinados pelo aplicativo.
A execução das consultas deve consultar dados em fragmentos espalhados pelos nós.
Neste caso, a distribuição de dados cria desvantagens substanciais:
- Sobrecarga de consultar cada fragmento e executar várias consultas.
- Sobrecarga do Q1 retornando muitas linhas para o cliente.
- Q2 torna-se grande.
- A necessidade de escrever consultas em várias etapas requer alterações no aplicativo.
Os dados são dispersos, para que as consultas possam ser paralelizadas. Só é benéfico se a quantidade de trabalho que a consulta faz for substancialmente maior do que a sobrecarga de consultar muitos fragmentos.
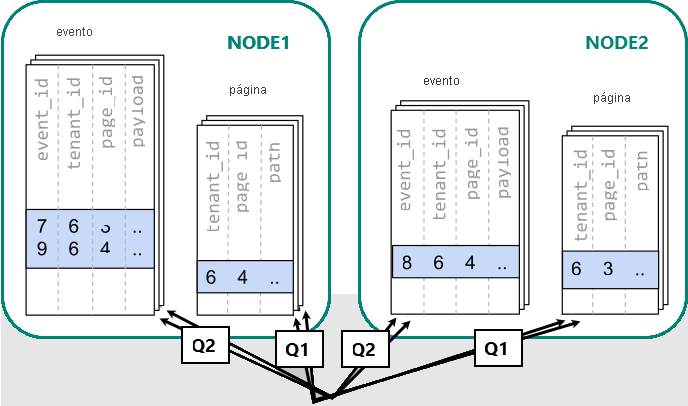
Distribuir tabelas por locatário
No Azure Cosmos DB para PostgreSQL, as linhas que partilham o mesmo valor na coluna de distribuição estão garantidamente no mesmo nó. Recomeçando, podemos criar as nossas tabelas com tenant_id como a coluna de distribuição.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Agora, o Azure Cosmos DB para PostgreSQL pode responder à consulta original de servidor único sem modificação (Q1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Devido ao filtro e associação em tenant_id, o Azure Cosmos DB para PostgreSQL sabe que toda a consulta pode ser respondida usando o conjunto de fragmentos colocalizados que contêm os dados para esse locatário específico. Um único nó do PostgreSQL pode responder à consulta numa única etapa.
Em alguns casos, consultas e esquemas de tabela devem ser alterados para incluir a ID do locatário em restrições exclusivas e condições de associação. Esta alteração é geralmente simples.
Próximos passos
- Veja como os dados dos inquilinos estão co-localizados no tutorial multitenant.