Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
O Azure Cosmos DB para PostgreSQL está numa fase de reforma e já não é recomendado para novos projetos. Em vez disso, use um destes dois serviços:
Para cargas de trabalho PostgreSQL : utilize a funcionalidade Elastic Clusters do Azure Database For PostgreSQL para utilizar as funcionalidades de escalonamento horizontal e distribuição do PostgreSQL contidas na extensão open source Citus. Para orientações sobre migração, consulte migrar para Azure Database para PostgreSQL com Elastic Cluster.
Para cargas de trabalho NoSQL , utilize o Azure Cosmos DB para NoSQL como solução de base de dados distribuída que inclui um acordo de nível de serviço (SLA) de disponibilidade de 99,999%, escalabilidade automática instantânea e failover automático em múltiplas regiões.
Neste tutorial, você usa o Azure Cosmos DB para PostgreSQL para aprender a:
- Criar um cluster
- Use o utilitário psql para criar um esquema
- Distribuir tabelas por nós
- Importar dados de exemplo
- Consultar dados do locatário
- Partilhar dados entre inquilinos
- Personalizar o esquema por locatário
Pré-requisitos
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Criar um cluster
Entre no portal do Azure e siga estas etapas para criar um cluster do Azure Cosmos DB para PostgreSQL:
Vá para Criar um cluster do Azure Cosmos DB for PostgreSQL no portal do Azure.
No formulário Criar um cluster do Azure Cosmos DB para PostgreSQL:
Preencha as informações no separador Básicas.
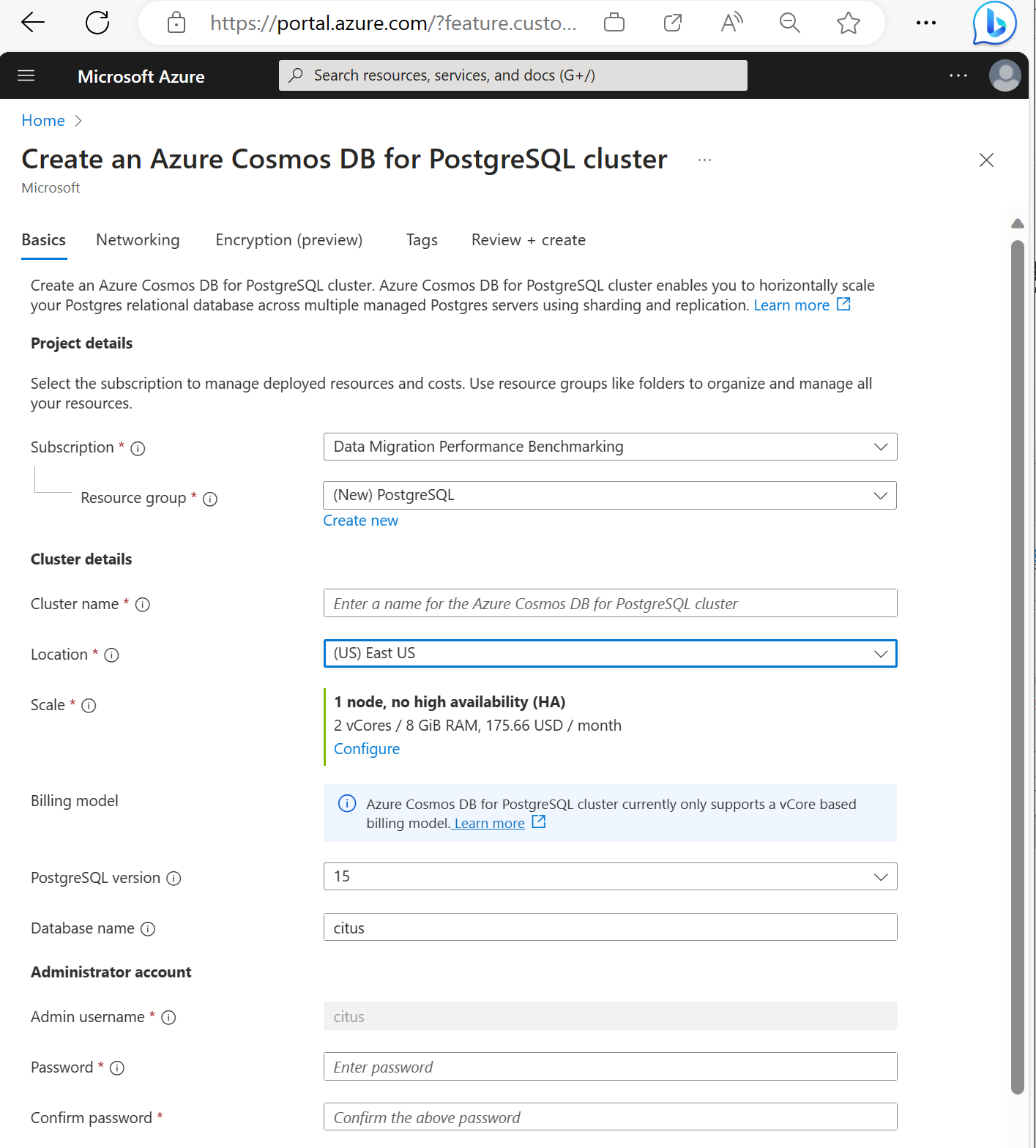
A maioria das opções são autoexplicativas, mas tenha em atenção:
- O nome do cluster determina o nome DNS que seus aplicativos usam para se conectar, no formato
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Você pode escolher uma versão principal do PostgreSQL, como a 15. O Azure Cosmos DB para PostgreSQL sempre suporta a versão mais recente do Citus para a versão principal selecionada do Postgres.
- O nome de utilizador do administrador deve ser o valor
citus. - Você pode deixar o nome do banco de dados em seu valor padrão 'citus' ou definir seu único nome de banco de dados. Não é possível renomear o banco de dados após o provisionamento do cluster.
- O nome do cluster determina o nome DNS que seus aplicativos usam para se conectar, no formato
Selecione Next : Networking na parte inferior da tela.
Na tela Rede, selecione Permitir acesso público dos serviços e recursos do Azure dentro do Azure a este cluster.
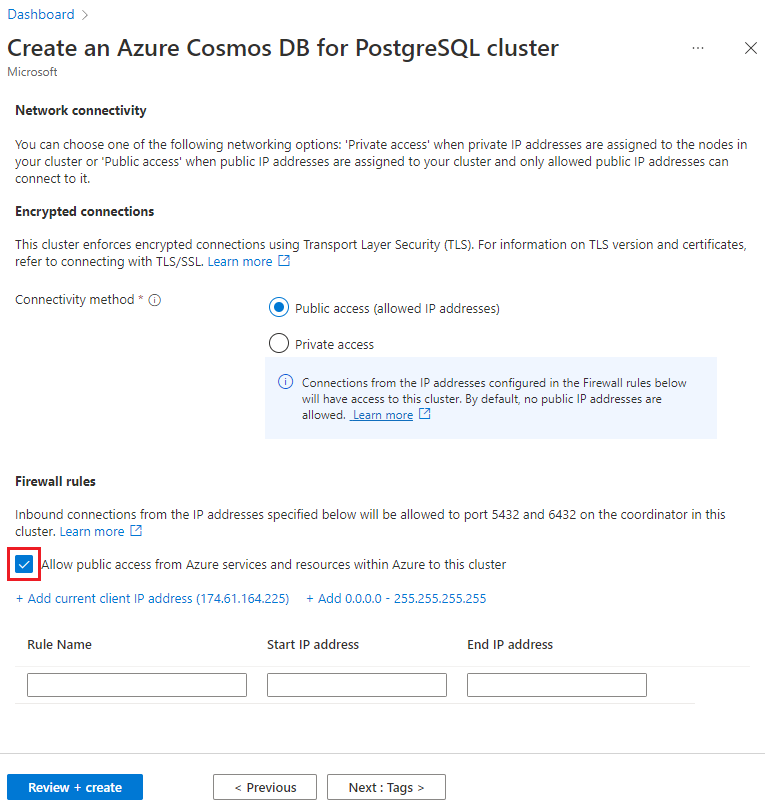
Selecione Analisar + criar e, quando a validação passar, selecione Criar para criar o cluster.
O aprovisionamento demora alguns minutos. A página redireciona para a monitorização da implementação. Quando o estado é alterado de Implementação a decorrer para A implementação está concluída, selecione Aceder ao recurso.
Use o utilitário psql para criar um esquema
Uma vez conectado ao Azure Cosmos DB para PostgreSQL usando psql, você pode concluir algumas tarefas básicas. Este tutorial orienta você na criação de um aplicativo Web que permite que os anunciantes acompanhem suas campanhas.
Várias empresas podem usar a aplicação, então vamos criar uma tabela para armazenar as empresas e outra para as suas campanhas. No console psql, execute estes comandos:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Cada campanha pagará para veicular anúncios. Adicione uma tabela para anúncios também, executando o seguinte código em psql após o código acima:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Por fim, acompanharemos as estatísticas sobre cliques e impressões de cada anúncio:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
Você pode ver as tabelas recém-criadas na lista de tabelas agora no psql executando:
\dt
Os aplicativos multilocatários podem impor exclusividade apenas por locatário, e é por isso que todas as chaves primária e estrangeira incluem o ID da empresa.
Distribuir tabelas por nós
Uma implantação do Azure Cosmos DB para PostgreSQL armazena linhas de tabela em nós diferentes com base no valor de uma coluna designada pelo usuário. Esta "coluna de distribuição" marca qual locatário possui quais linhas.
Vamos definir a coluna de distribuição como ID da empresa, o identificador do locatário. No psql, execute estas funções:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Importante
Distribuir tabelas ou usar fragmentação baseada em esquema é necessário para aproveitar os recursos de desempenho do Azure Cosmos DB para PostgreSQL. Se você não distribuir tabelas ou esquemas, os nós de trabalho não poderão ajudar a executar consultas envolvendo seus dados.
Importar dados de exemplo
Fora do psql agora, na linha de comando normal, baixe conjuntos de dados de exemplo:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
Volte ao psql e carregue em massa os dados. Certifique-se de executar psql no mesmo diretório onde você baixou os arquivos de dados.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
Esses dados vão agora ser distribuídos entre os nós de trabalho.
Consultar dados do locatário
Quando o aplicativo solicita dados para um único locatário, o banco de dados pode executar a consulta em um único nó de trabalho. As consultas de inquilino único são filtradas por um único ID de inquilino. Por exemplo, a consulta a seguir filtra company_id = 5 para anúncios e impressões. Tente executá-lo em psql para ver os resultados.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Partilhar dados entre inquilinos
Até agora, todas as tabelas foram distribuídas por company_id. No entanto, alguns dados não "pertencem" naturalmente a nenhum inquilino em particular, e podem ser compartilhados. Por exemplo, todas as empresas na plataforma de anúncios de exemplo podem querer obter informações geográficas para o seu público com base em endereços IP.
Crie uma tabela para armazenar informações geográficas compartilhadas. Execute os seguintes comandos no psql:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
Em seguida, torne geo_ips uma "tabela de referência" para armazenar uma cópia da tabela em cada nó de trabalho.
SELECT create_reference_table('geo_ips');
Carregue-o com dados de exemplo. Lembre-se de executar este comando em psql de dentro do diretório onde você baixou o conjunto de dados.
\copy geo_ips from 'geo_ips.csv' with csv
Unir a tabela de 'clicks' com 'geo_ips' é eficiente em todos os nós. Aqui está uma junção para encontrar os locais de todos que clicaram no anúncio 290. Tente executar a consulta em psql.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Personalizar o esquema por locatário
Cada inquilino pode precisar armazenar informações especiais que não são necessárias para outros. No entanto, todos os locatários compartilham uma infraestrutura comum com um esquema de banco de dados idêntico. Para onde podem ir os dados extras?
Um truque é usar um tipo de coluna aberta como o JSONB do PostgreSQL. Nosso esquema tem um campo JSONB em clicks chamado user_data.
Uma empresa (digamos empresa cinco), pode usar a coluna para rastrear se o usuário está em um dispositivo móvel.
Aqui está uma consulta para descobrir quem clica mais: visitantes móveis ou tradicionais.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
Podemos otimizar esta consulta para uma única empresa criando um índice parcial.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Mais geralmente, podemos criar índices GIN em cada chave e valor dentro da coluna.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Limpar recursos
Nas etapas anteriores, você criou recursos do Azure em um cluster. Se você não espera precisar desses recursos no futuro, exclua o cluster. Selecione o botão Excluir na página Visão geral do cluster. Quando solicitado numa janela pop-up, confirme o nome do cluster e selecione o botão Excluir final.
Próximos passos
Neste tutorial, você aprendeu como provisionar um cluster. Você se conectou a ele com psql, criou um esquema e distribuiu dados. Você aprendeu a consultar dados dentro e entre locatários e a personalizar o esquema por locatário.
- Saiba mais sobre os tipos de nós de cluster
- Determinar o melhor tamanho inicial para o cluster