Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
O Azure Cosmos DB para PostgreSQL não tem mais suporte para novos projetos. Não use este serviço para novos projetos. Em vez disso, use um destes dois serviços:
Use o Azure Cosmos DB para NoSQL para obter uma solução de banco de dados distribuído projetada para cenários de alta escala com um SLA (contrato de nível de serviço) de disponibilidade de 99.999%, dimensionamento automático instantâneo e failover automático em várias regiões.
Use a funcionalidade de Clusters Elásticos do Azure para PostgreSQL para PostgreSQL fragmentado, utilizando a extensão Citus de código aberto.
Neste tutorial, você usa o Azure Cosmos DB para PostgreSQL para aprender a:
- Criar um cluster
- Use o utilitário psql para criar um esquema
- Particionar tabelas pelos nós
- Gerar dados de exemplo
- Executar agregações
- Consultar dados brutos e agregados
- Dados de expiração
Pré-requisitos
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Criar um cluster
Entre no portal do Azure e siga estas etapas para criar um cluster do Azure Cosmos DB para PostgreSQL:
Aceda a Criar um cluster do Azure Cosmos DB para PostgreSQL no portal do Azure.
No formulário de Criação de um cluster do Azure Cosmos DB para PostgreSQL:
Preencha as informações no separador Básicas.
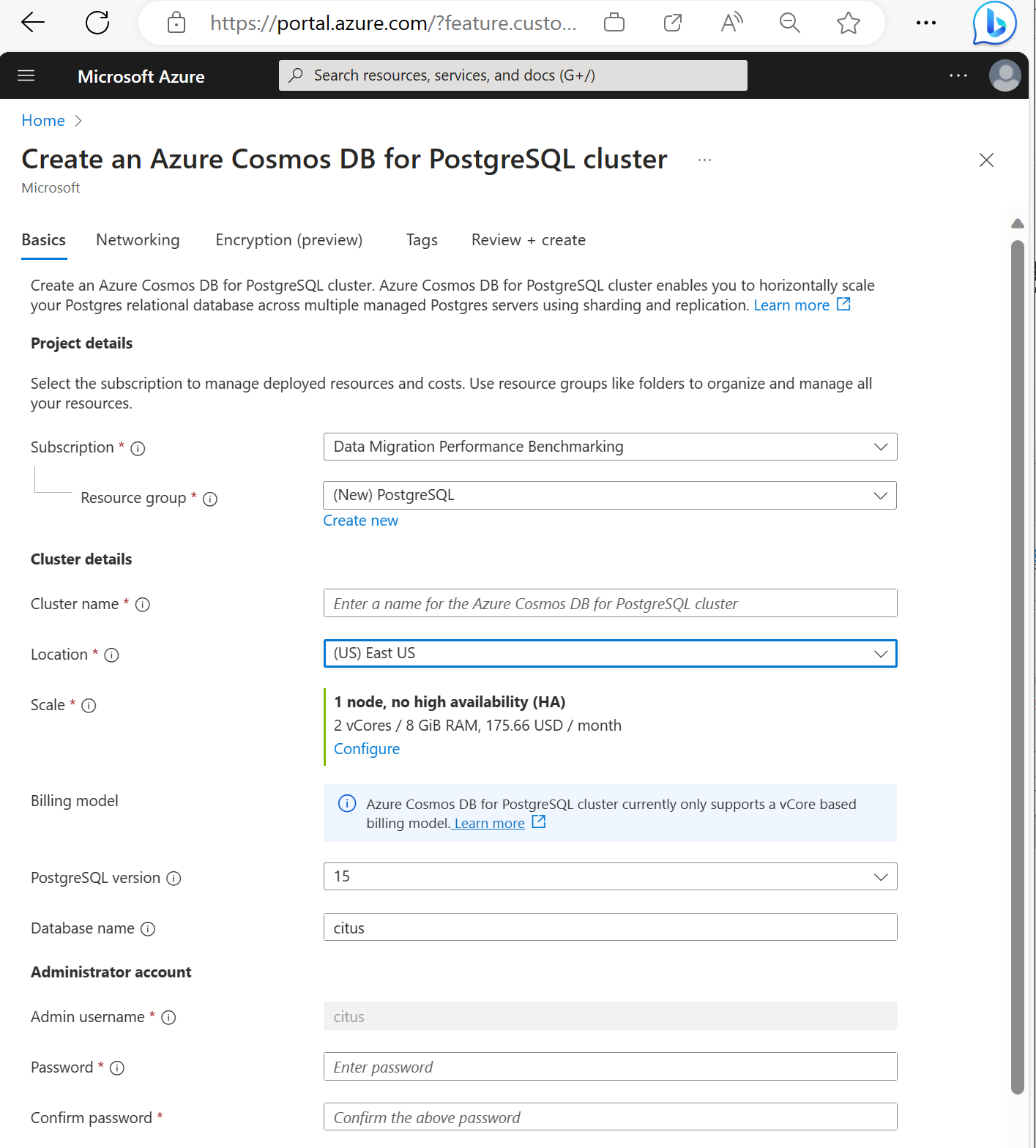
A maioria das opções são autoexplicativas, mas tenha em atenção:
- O nome do cluster determina o nome DNS que seus aplicativos usam para se conectar, no formato
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Você pode escolher uma versão principal do PostgreSQL, como a 15. O Azure Cosmos DB para PostgreSQL sempre suporta a versão mais recente do Citus para a versão principal selecionada do Postgres.
- O nome de utilizador do administrador deve ser o valor
citus. - Você pode deixar o nome do banco de dados em seu valor padrão 'citus' ou definir seu único nome de banco de dados. Não é possível renomear o banco de dados após o provisionamento do cluster.
- O nome do cluster determina o nome DNS que seus aplicativos usam para se conectar, no formato
Selecione Next : Networking na parte inferior da tela.
Na tela Rede, selecione Permitir acesso público dos serviços e recursos do Azure dentro do Azure a este cluster.
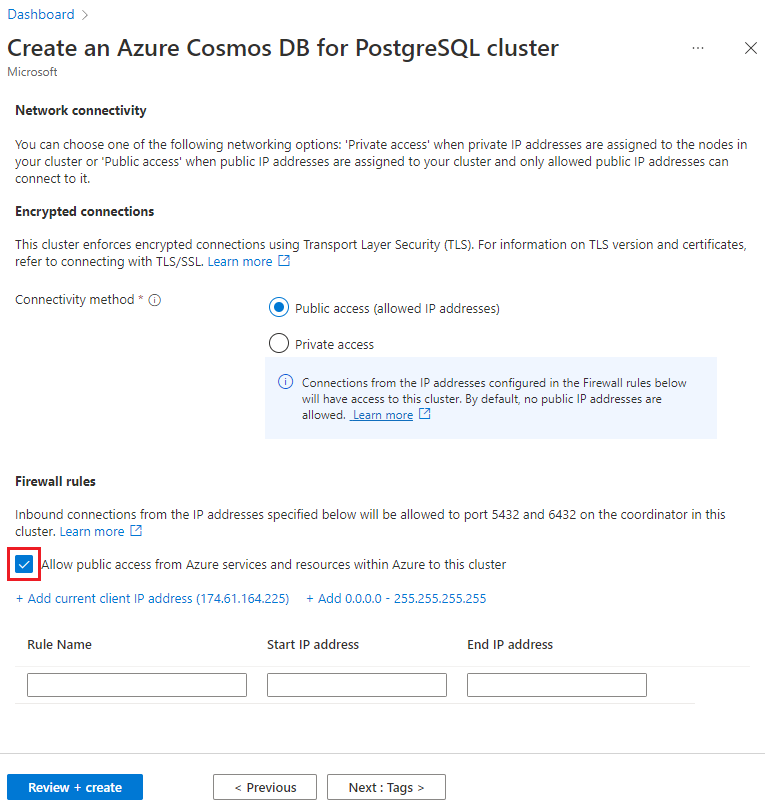
Selecione Analisar + criar e, quando a validação passar, selecione Criar para criar o cluster.
O aprovisionamento demora alguns minutos. A página redireciona para a monitorização da implementação. Quando o estado é alterado de Implementação a decorrer para A implementação está concluída, selecione Aceder ao recurso.
Use o utilitário psql para criar um esquema
Uma vez conectado ao Azure Cosmos DB para PostgreSQL usando psql, você pode concluir algumas tarefas básicas. Este tutorial guia o leitor pela ingestão de dados de tráfego das análises da web e, em seguida, agrega os dados para fornecer painéis em tempo real com base nesses dados.
Vamos criar uma tabela que consumirá todos os nossos dados brutos de tráfego da web. Execute os seguintes comandos no terminal psql:
CREATE TABLE http_request (
site_id INT,
ingest_time TIMESTAMPTZ DEFAULT now(),
url TEXT,
request_country TEXT,
ip_address TEXT,
status_code INT,
response_time_msec INT
);
Também vamos criar uma tabela que manterá nossos agregados por minuto e uma tabela que manterá a posição do nosso último rollup. Execute os seguintes comandos no psql também:
CREATE TABLE http_request_1min (
site_id INT,
ingest_time TIMESTAMPTZ, -- which minute this row represents
error_count INT,
success_count INT,
request_count INT,
average_response_time_msec INT,
CHECK (request_count = error_count + success_count),
CHECK (ingest_time = date_trunc('minute', ingest_time))
);
CREATE INDEX http_request_1min_idx ON http_request_1min (site_id, ingest_time);
CREATE TABLE latest_rollup (
minute timestamptz PRIMARY KEY,
CHECK (minute = date_trunc('minute', minute))
);
Você pode ver as tabelas recém-criadas na lista de tabelas agora com este comando psql:
\dt
Particionar tabelas pelos nós
Uma implantação do Azure Cosmos DB para PostgreSQL armazena linhas de tabela em nós diferentes com base no valor de uma coluna designada pelo usuário. Esta "coluna de distribuição" indica como os dados são fragmentados entre os nós.
Vamos definir a coluna de distribuição para ser site_id, a chave de fragmentação. No psql, execute estas funções:
SELECT create_distributed_table('http_request', 'site_id');
SELECT create_distributed_table('http_request_1min', 'site_id');
Importante
Distribuir tabelas ou usar fragmentação baseada em esquema é necessário para aproveitar os recursos de desempenho do Azure Cosmos DB para PostgreSQL. Se você não distribuir tabelas ou esquemas, os nós de trabalho não poderão ajudar a executar consultas envolvendo seus dados.
Gerar dados de exemplo
Agora, nosso cluster deve estar pronto para ingerir alguns dados. Podemos executar o seguinte localmente a partir da nossa psql conexão para inserir dados continuamente.
DO $$
BEGIN LOOP
INSERT INTO http_request (
site_id, ingest_time, url, request_country,
ip_address, status_code, response_time_msec
) VALUES (
trunc(random()*32), clock_timestamp(),
concat('http://example.com/', md5(random()::text)),
('{China,India,USA,Indonesia}'::text[])[ceil(random()*4)],
concat(
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2)
)::inet,
('{200,404}'::int[])[ceil(random()*2)],
5+trunc(random()*150)
);
COMMIT;
PERFORM pg_sleep(random() * 0.25);
END LOOP;
END $$;
A consulta insere aproximadamente oito linhas a cada segundo. As linhas são armazenadas em diferentes nós de trabalho, conforme indicado pela coluna de distribuição, site_id.
Nota
Deixe a consulta de geração de dados em execução e abra uma segunda conexão psql para os comandos restantes neste tutorial.
Query
O Azure Cosmos DB para PostgreSQL permite que vários nós processem consultas em paralelo para velocidade. Por exemplo, o banco de dados calcula agregados como "SUM" e "COUNT" em nós de processamento e combina os resultados numa resposta final.
Aqui está uma consulta para contar solicitações da Web por minuto, juntamente com algumas estatísticas. Tente executá-lo em psql e observe os resultados.
SELECT
site_id,
date_trunc('minute', ingest_time) as minute,
COUNT(1) AS request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
WHERE date_trunc('minute', ingest_time) > now() - '5 minutes'::interval
GROUP BY site_id, minute
ORDER BY minute ASC;
Acumulando dados
A consulta anterior funciona bem nos estágios iniciais, mas seu desempenho diminui à medida que seus dados são dimensionados. Mesmo com processamento distribuído, é mais rápido pré-calcular os dados do que recalculá-los repetidamente.
Podemos garantir que nosso painel permaneça rápido acumulando regularmente os dados brutos em uma tabela agregada. Você pode experimentar a duração da agregação. Usamos uma tabela de agregação por minuto, mas você pode dividir os dados em 5, 15 ou 60 minutos.
Para executar esse roll-up mais facilmente, vamos colocá-lo em uma função plpgsql. Execute esses comandos em psql para criar a rollup_http_request função.
-- initialize to a time long ago
INSERT INTO latest_rollup VALUES ('10-10-1901');
-- function to do the rollup
CREATE OR REPLACE FUNCTION rollup_http_request() RETURNS void AS $$
DECLARE
curr_rollup_time timestamptz := date_trunc('minute', now());
last_rollup_time timestamptz := minute from latest_rollup;
BEGIN
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
) SELECT
site_id,
date_trunc('minute', ingest_time),
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
-- roll up only data new since last_rollup_time
WHERE date_trunc('minute', ingest_time) <@
tstzrange(last_rollup_time, curr_rollup_time, '(]')
GROUP BY 1, 2;
-- update the value in latest_rollup so that next time we run the
-- rollup it will operate on data newer than curr_rollup_time
UPDATE latest_rollup SET minute = curr_rollup_time;
END;
$$ LANGUAGE plpgsql;
Com a nossa função implementada, execute-a para acumular os dados:
SELECT rollup_http_request();
E com nossos dados em um formulário pré-agregado, podemos consultar a tabela de rollup para obter o mesmo relatório anterior. Execute a seguinte consulta:
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
Expirando dados antigos
Os rollups tornam as consultas mais rápidas, mas ainda precisamos expirar dados antigos para evitar custos de armazenamento ilimitados. Decida por quanto tempo deseja manter os dados para cada granularidade e use consultas padrão para excluir dados expirados. No exemplo a seguir, decidimos manter dados brutos por um dia e agregações por minuto por um mês:
DELETE FROM http_request WHERE ingest_time < now() - interval '1 day';
DELETE FROM http_request_1min WHERE ingest_time < now() - interval '1 month';
Na produção, pode-se encapsular estas consultas numa função e chamá-la a cada minuto num trabalho cron.
Limpar recursos
Nas etapas anteriores, você criou recursos do Azure em um cluster. Se você não espera precisar desses recursos no futuro, exclua o cluster. Pressione o botão Delete na página Visão geral do cluster. Quando solicitado em uma página pop-up, confirme o nome do cluster e clique no botão Excluir final.
Próximos passos
Neste tutorial, você aprendeu como provisionar um cluster. Você se conectou a ele com psql, criou um esquema e distribuiu dados. Você aprendeu a consultar dados na forma bruta, agregar regularmente esses dados, consultar as tabelas agregadas e expirar dados antigos.
- Saiba mais sobre os tipos de nodos de cluster
- Determinar o melhor tamanho inicial para o cluster