Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Azure Data Lake Storage é uma solução de data lake altamente escalável e económica para análise de big data. Ele combina o poder de um sistema de arquivos de alto desempenho com grande escala e economia para ajudá-lo a reduzir seu tempo de insight. O Data Lake Storage Gen2 estende as capacidades do Armazenamento de Blobs do Azure e está otimizado para cargas de trabalho analíticas.
O Azure Data Explorer integra-se com o Armazenamento de Blobs do Azure e o Azure Data Lake Storage (Gen1 e Gen2), proporcionando acesso rápido, em cache e indexado aos dados armazenados em armazenamento externo. Pode analisar e consultar dados sem ingestão prévia no Azure Data Explorer. Você também pode consultar dados externos ingeridos e não ingeridos simultaneamente. Para mais informações, veja como criar uma tabela externa usando o assistente da interface web Azure Data Explorer. Para uma breve visão geral, consulte tabelas externas.
Sugestão
O melhor desempenho de consulta exige a ingestão de dados no Azure Data Explorer. A capacidade de consultar dados externos sem ingestão prévia só deve ser usada para dados históricos ou dados que raramente são consultados. Otimize o desempenho da consulta de dados externos para obter os melhores resultados.
Criar uma tabela externa
Digamos que você tenha muitos arquivos CSV contendo informações históricas sobre produtos armazenados em um armazém e queira fazer uma análise rápida para encontrar os cinco produtos mais populares do ano passado. Neste exemplo, os arquivos CSV têm a seguinte aparência:
| Data e Hora | ID do Produto | Descrição do Produto |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | Disquete DS/HD de 3,5 polegadas |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 Sintetizador |
| ... | ... | ... |
Os ficheiros são armazenados em armazenamento Blob do Azure mycompanystorage num contentor denominado archivedproducts, particionado por data:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Para executar uma consulta KQL diretamente nestes ficheiros CSV, use o comando .create external table para definir uma tabela externa em Azure Data Explorer. Para obter mais informações sobre opções de comando de criação de tabela externa, consulte comandos de tabela externa.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
A tabela externa está agora visível no painel esquerdo da interface web do Azure Data Explorer:
Permissões de tabela externa
Analise as seguintes permissões de tabela:
- O usuário do banco de dados pode criar uma tabela externa. O criador da tabela torna-se automaticamente o administrador da tabela.
- O administrador de cluster, banco de dados ou tabela pode editar uma tabela existente.
- Qualquer usuário ou leitor de banco de dados pode consultar uma tabela externa.
Consultando uma tabela externa
Uma vez definida uma tabela externa, a external_table() função pode ser usada para se referir a ela. O resto da consulta é padrão Kusto Query Language.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Consultando dados externos e ingeridos juntos
Você pode consultar tabelas externas e tabelas de dados ingeridas dentro da mesma consulta. Podes join ou union a tabela externa com outros dados de Azure Data Explorer, servidores SQL ou outras fontes. Use a let( ) statement para atribuir um nome abreviado a uma referência de tabela externa.
No exemplo abaixo, Products é uma tabela de dados ingeridos e ArchivedProducts é uma tabela externa que definimos:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Consultando formatos de dados hierárquicos
Azure Data Explorer permite consultar formatos hierárquicos, como JSON, Parquet, Avro e ORC. Para mapear o esquema de dados hierárquicos para um esquema de tabela externa (se for diferente), use comandos de mapeamentos de tabela externa. Por exemplo, se você quiser consultar arquivos de log JSON com o seguinte formato:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "aaaabbbb-0000-cccc-1111-dddd2222eeee",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "bbbbcccc-1111-dddd-2222-eeee3333ffff",
"method": "GetFileList"
}
}
...
A definição da tabela externa tem esta aparência:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Defina um mapeamento JSON que mapeie campos de dados para campos de definição de tabela externos:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
Quando você consulta a tabela externa, o mapeamento é invocado e os dados relevantes mapeados para as colunas da tabela externa:
external_table('ApiCalls') | take 10
Para saber mais sobre sintaxe de mapeamento, veja mapeamentos de dados.
Consultar tabela externa TaxiRides no cluster de ajuda
Use o cluster de testes chamado help para experimentar diferentes capacidades Azure Data Explorer. O cluster de ajuda contém uma definição de tabela externa para um conjunto de dados de táxi da cidade de Nova York contendo bilhões de corridas de táxi.
Criar tabela externa TaxiRides
Esta seção mostra a consulta usada para criar a tabela externa TaxiRides no cluster de ajuda . Uma vez que já criou esta tabela, pode ignorar esta secção e ir diretamente para consultar os dados da tabela externa do TaxiRides.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
Pode encontrar a tabela TaxiRides criada olhando para o painel esquerdo da interface web do Azure Data Explorer.
Consultar dados da tabela externa TaxiRides
Iniciar sessão em https://dataexplorer.azure.com/clusters/help/databases/Samples.
Consultar tabela externa TaxiRides sem particionamento
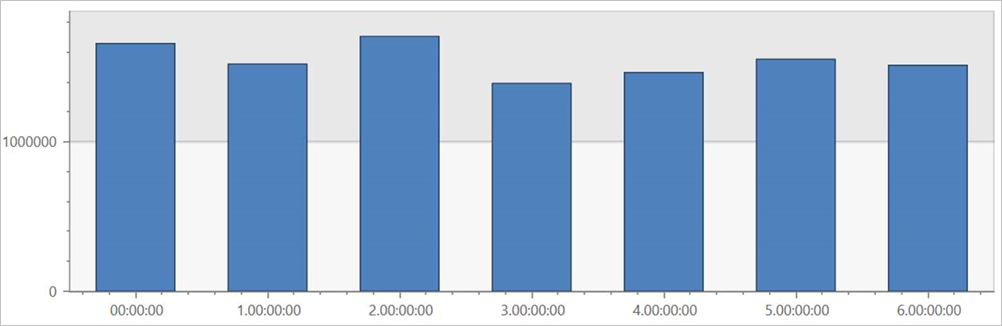
Execute esta consulta na tabela externa TaxiRides para mostrar as viagens para cada dia da semana, em todo o conjunto de dados.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Esta consulta mostra o dia mais movimentado da semana. Como os dados não são particionados, a consulta pode levar até vários minutos para retornar os resultados.
Consultar tabela externa TaxiRides utilizando particionamento
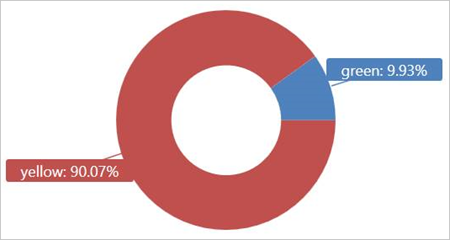
Execute esta consulta na tabela externa TaxiRides para mostrar os tipos de táxi (amarelo ou verde) usados em janeiro de 2017.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Essa consulta usa particionamento, que otimiza o tempo e o desempenho da consulta. A consulta filtra em uma coluna particionada (pickup_datetime) e retorna resultados em alguns segundos.
Você pode escrever outras consultas para executar na tabela externa TaxiRides e saber mais sobre os dados.
Otimize o desempenho da sua consulta
Otimize o desempenho da consulta no lago usando as seguintes práticas recomendadas para consultar dados externos.
Formato dos dados
- Use um formato colunar para consultas analíticas, pelos seguintes motivos:
- Apenas as colunas relevantes para uma consulta podem ser lidas.
- As técnicas de codificação de colunas podem reduzir significativamente o tamanho dos dados.
- Azure Data Explorer suporta os formatos colunares Parquet e ORC. Sugerimos o formato Parquet devido à sua implementação otimizada.
Região Azure
Verifica se os dados externos estão na mesma região do Azure que o teu cluster Azure Data Explorer. Essa configuração reduz o custo e o tempo de busca de dados.
Tamanho do ficheiro
O tamanho ideal do ficheiro é de centenas de Mb (até 1 GB) por ficheiro. Evite muitos arquivos pequenos que exigem sobrecarga desnecessária, como processo de enumeração de arquivos mais lento e uso limitado do formato colunar. O número de ficheiros deve ser maior do que o número de núcleos de CPU no seu cluster Azure Data Explorer.
Compressão
Use a compactação para reduzir a quantidade de dados que estão sendo buscados no armazenamento remoto. Para o formato Parquet, use o mecanismo de compressão interno do Parquet que compacta grupos de colunas separadamente, permitindo lê-los separadamente. Para validar o uso do mecanismo de compactação, verifique se os arquivos são nomeados da seguinte forma: <filename>.gz.parquet ou <filename.snappy.parquet> e não <filename>.parquet.gz.
Particionamento
Organize seus dados usando partições de "pasta" que permitem que a consulta ignore caminhos irrelevantes. Ao planejar o particionamento, considere o tamanho do arquivo e os filtros comuns em suas consultas, como carimbo de data/hora ou ID de locatário.
Tamanho da VM
Selecione SKUs de VM com mais núcleos e maior taxa de transferência de rede (a memória é menos importante). Para mais informações, consulte Selecione o SKU de VM correto para o seu cluster de Azure Data Explorer.