Usar o Azure Data Factory para migrar dados de um cluster Hadoop local para o Armazenamento do Azure
APLICA-SE A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
O Azure Data Factory fornece um mecanismo de desempenho, robusto e econômico para migrar dados em escala do HDFS local para o armazenamento de Blob do Azure ou para o Azure Data Lake Storage Gen2.
O Data Factory oferece duas abordagens básicas para migrar dados do HDFS local para o Azure. Você pode selecionar a abordagem com base no seu cenário.
- Modo DistCp do Data Factory (recomendado): no Data Factory, você pode usar o DistCp (cópia distribuída) para copiar arquivos como estão para o armazenamento de Blob do Azure (incluindo cópia em estágios) ou para o Azure Data Lake Store Gen2. Use o Data Factory integrado ao DistCp para aproveitar um cluster poderoso existente para obter a melhor taxa de transferência de cópia. Você também obtém o benefício de agendamento flexível e uma experiência de monitoramento unificada do Data Factory. Dependendo da configuração do Data Factory, a atividade de cópia constrói automaticamente um comando DistCp, envia os dados para o cluster Hadoop e monitora o status da cópia. Recomendamos o modo Data Factory DistCp para migrar dados de um cluster Hadoop local para o Azure.
- Modo de tempo de execução de integração nativa do Data Factory: o DistCp não é uma opção em todos os cenários. Por exemplo, em um ambiente de Redes Virtuais do Azure, a ferramenta DistCp não oferece suporte ao emparelhamento privado do Azure ExpressRoute com um ponto de extremidade de rede virtual do Armazenamento do Azure. Além disso, em alguns casos, você não deseja usar o cluster Hadoop existente como um mecanismo para migrar dados para não colocar cargas pesadas no cluster, o que pode afetar o desempenho de trabalhos ETL existentes. Em vez disso, você pode usar o recurso nativo do tempo de execução de integração do Data Factory como o mecanismo que copia dados do HDFS local para o Azure.
Este artigo fornece as seguintes informações sobre ambas as abordagens:
- Desempenho
- Resiliência de cópia
- Segurança da rede
- Arquitetura de solução de alto nível
- Melhores práticas de implementação
Desempenho
No modo DistCp do Data Factory, a taxa de transferência é a mesma que se você usar a ferramenta DistCp independentemente. O modo Data Factory DistCp maximiza a capacidade do cluster Hadoop existente. Você pode usar o DistCp para grandes cópias entre clusters ou intraclusters.
O DistCp usa o MapReduce para efetuar sua distribuição, tratamento e recuperação de erros e emissão de relatórios. Ele expande uma lista de arquivos e diretórios em entrada para mapeamento de tarefas. Cada tarefa copia uma partição de arquivo especificada na lista de origem. Você pode usar o Data Factory integrado ao DistCp para criar pipelines para utilizar totalmente a largura de banda da rede, IOPS de armazenamento e largura de banda para maximizar a taxa de transferência de movimentação de dados para seu ambiente.
O modo de tempo de execução de integração nativa do Data Factory também permite paralelismo em diferentes níveis. Você pode usar o paralelismo para utilizar totalmente a largura de banda da rede, IOPS de armazenamento e largura de banda para maximizar a taxa de transferência de movimentação de dados:
- Uma única atividade de cópia pode tirar proveito de recursos de computação escaláveis. Com um tempo de execução de integração auto-hospedado, você pode dimensionar manualmente a máquina ou expandir para várias máquinas (até quatro nós). Uma única atividade de cópia particiona seu conjunto de arquivos em todos os nós.
- Uma única atividade de cópia lê e grava no armazenamento de dados usando vários threads.
- O fluxo de controle do Data Factory pode iniciar várias atividades de cópia em paralelo. Por exemplo, você pode usar um loop For Each.
Para obter mais informações, consulte o guia de desempenho da atividade de cópia.
Resiliência
No modo DistCp do Data Factory, você pode usar diferentes parâmetros de linha de comando DistCp (por exemplo, -iignorar falhas ou -updategravar dados quando o arquivo de origem e o arquivo de destino diferem em tamanho) para diferentes níveis de resiliência.
No modo de tempo de execução de integração nativa do Data Factory, em uma única execução de atividade de cópia, o Data Factory tem um mecanismo de repetição interno. Ele pode lidar com um certo nível de falhas transitórias nos armazenamentos de dados ou na rede subjacente.
Ao fazer cópias binárias do HDFS local para o armazenamento de Blob e do HDFS local para o Data Lake Store Gen2, o Data Factory executa automaticamente o checkpoint em grande medida. Se a execução de uma atividade de cópia falhar ou atingir o tempo limite, em uma nova tentativa subsequente (certifique-se de que a contagem de tentativas seja > 1), a cópia será retomada a partir do último ponto de falha em vez de começar no início.
Segurança da rede
Por padrão, o Data Factory transfere dados do HDFS local para o armazenamento de Blob ou o Azure Data Lake Storage Gen2 usando uma conexão criptografada pelo protocolo HTTPS. O HTTPS fornece criptografia de dados em trânsito e evita escutas e ataques man-in-the-middle.
Como alternativa, se você não quiser que os dados sejam transferidos pela Internet pública, para maior segurança, você pode transferir dados por um link de emparelhamento privado via Rota Expressa.
Arquitetura de soluções
Esta imagem mostra a migração de dados através da Internet pública:
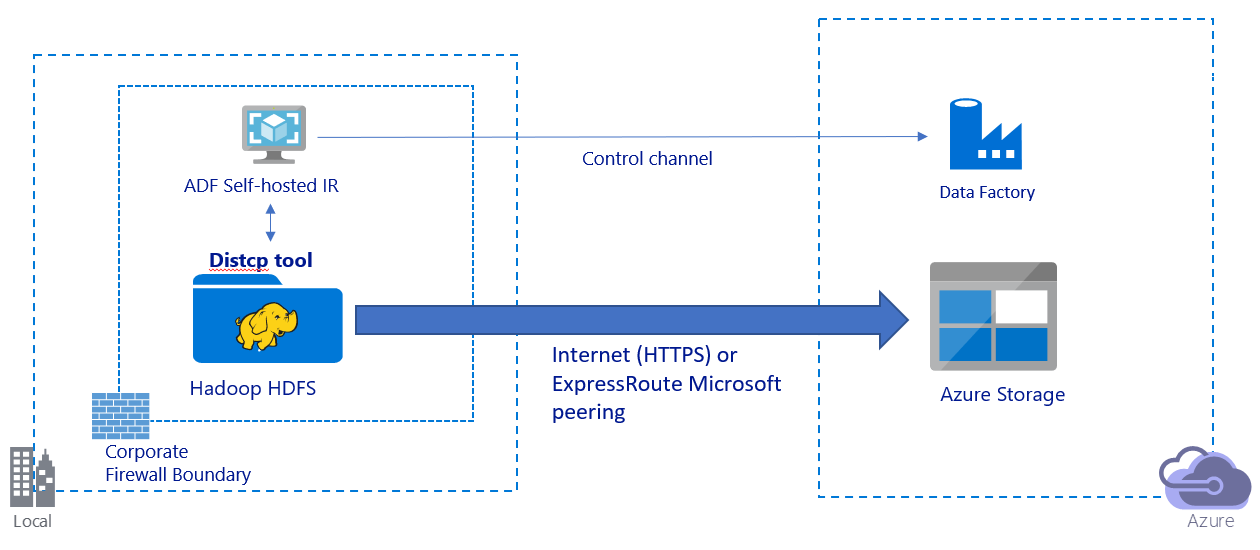
- Nesta arquitetura, os dados são transferidos de forma segura usando HTTPS através da Internet pública.
- Recomendamos o uso do modo Data Factory DistCp em um ambiente de rede pública. Você pode aproveitar um poderoso cluster existente para obter a melhor taxa de transferência de cópia. Você também obtém o benefício do agendamento flexível e da experiência de monitoramento unificada do Data Factory.
- Para essa arquitetura, você deve instalar o tempo de execução de integração auto-hospedado do Data Factory em uma máquina Windows atrás de um firewall corporativo para enviar o comando DistCp ao cluster Hadoop e monitorar o status da cópia. Como a máquina não é o mecanismo que moverá dados (apenas para fins de controle), a capacidade da máquina não afeta a taxa de transferência da movimentação de dados.
- Os parâmetros existentes do comando DistCp são suportados.
Esta imagem mostra a migração de dados através de um link privado:
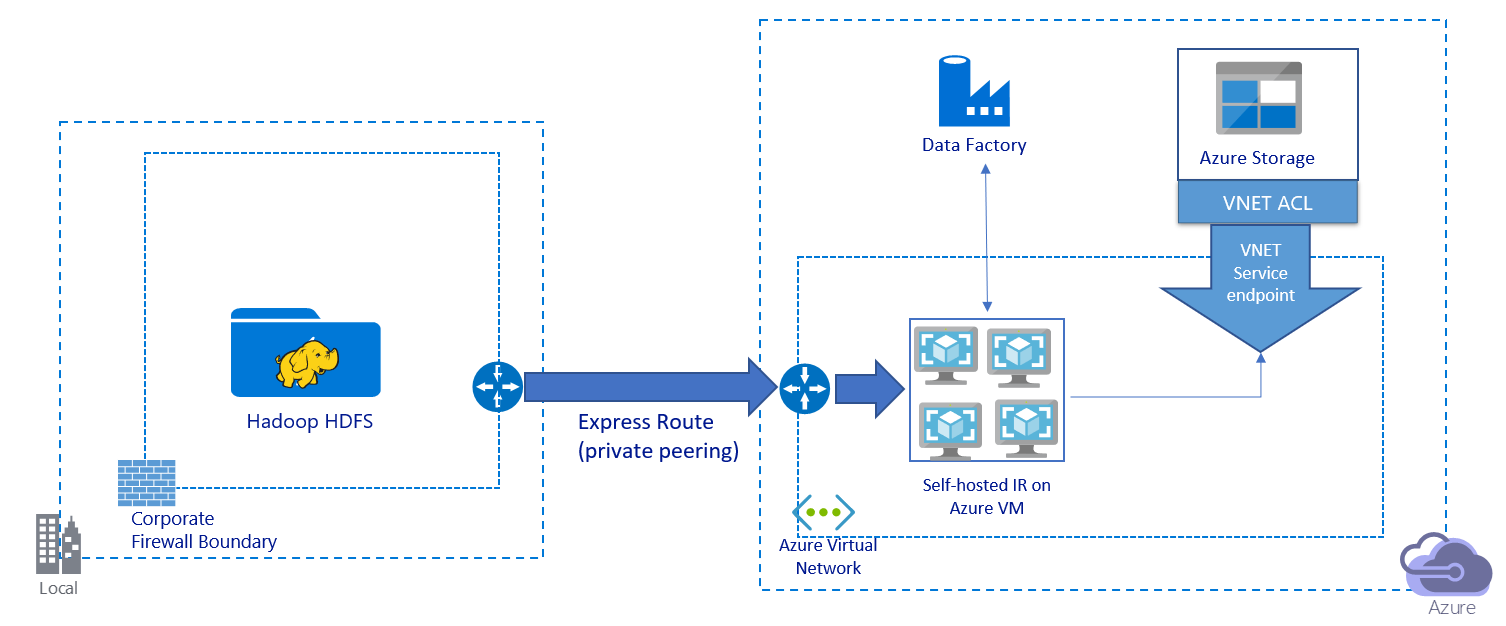
- Nessa arquitetura, os dados são migrados por um link de emparelhamento privado por meio da Rota Expressa do Azure. Os dados nunca passam pela internet pública.
- A ferramenta DistCp não oferece suporte ao emparelhamento privado da Rota Expressa com um ponto de extremidade de rede virtual do Armazenamento do Azure. Recomendamos que você use o recurso nativo do Data Factory por meio do tempo de execução de integração para migrar os dados.
- Para essa arquitetura, você deve instalar o tempo de execução de integração auto-hospedado do Data Factory em uma VM do Windows em sua rede virtual do Azure. Você pode dimensionar manualmente sua VM ou expandir para várias VMs para utilizar totalmente suas IOPS ou largura de banda de rede e armazenamento.
- A configuração recomendada para começar para cada VM do Azure (com o tempo de execução de integração auto-hospedado do Data Factory instalado) é Standard_D32s_v3 com 32 vCPU e 128 GB de memória. Você pode monitorar o uso da CPU e da memória da VM durante a migração de dados para ver se precisa dimensionar a VM para obter um melhor desempenho ou reduzir a VM para reduzir custos.
- Você também pode expandir associando até quatro nós de VM a um único tempo de execução de integração auto-hospedado. Um único trabalho de cópia em execução em um tempo de execução de integração auto-hospedado particiona automaticamente o conjunto de arquivos e usa todos os nós da VM para copiar os arquivos em paralelo. Para alta disponibilidade, recomendamos que você comece com dois nós de VM para evitar um cenário de ponto único de falha durante a migração de dados.
- Quando você usa essa arquitetura, a migração inicial de dados de snapshot e a migração de dados delta estão disponíveis para você.
Melhores práticas de implementação
Recomendamos que você siga essas práticas recomendadas ao implementar a migração de dados.
Autenticação e gerenciamento de credenciais
- Para autenticar no HDFS, você pode usar o Windows (Kerberos) ou o Anonymous.
- Vários tipos de autenticação são suportados para se conectar ao armazenamento de Blob do Azure. É altamente recomendável usar identidades gerenciadas para recursos do Azure. Criadas com base em uma identidade do Data Factory gerenciada automaticamente no ID do Microsoft Entra, as identidades gerenciadas permitem configurar pipelines sem fornecer credenciais na definição de serviço vinculado. Como alternativa, você pode autenticar no armazenamento de Blob usando uma entidade de serviço, uma assinatura de acesso compartilhado ou uma chave de conta de armazenamento.
- Vários tipos de autenticação também são suportados para conexão com o Data Lake Storage Gen2. É altamente recomendável usar identidades gerenciadas para recursos do Azure, mas você também pode usar uma entidade de serviço ou uma chave de conta de armazenamento.
- Quando você não estiver usando identidades gerenciadas para recursos do Azure, é altamente recomendável armazenar as credenciais no Cofre de Chaves do Azure para facilitar o gerenciamento centralizado e a rotação de chaves sem modificar os serviços vinculados do Data Factory. Esta é também uma prática recomendada para CI/CD.
Migração inicial de dados de snapshot
No modo DistCp do Data Factory, você pode criar uma atividade de cópia para enviar o comando DistCp e usar parâmetros diferentes para controlar o comportamento inicial de migração de dados.
No modo de tempo de execução de integração nativa do Data Factory, recomendamos a partição de dados, especialmente quando você migra mais de 10 TB de dados. Para particionar os dados, use os nomes das pastas no HDFS. Em seguida, cada trabalho de cópia do Data Factory pode copiar uma partição de pasta de cada vez. Você pode executar vários trabalhos de cópia do Data Factory simultaneamente para uma melhor taxa de transferência.
Se algum dos trabalhos de cópia falhar devido a problemas transitórios de rede ou armazenamento de dados, você poderá executar novamente o trabalho de cópia com falha para recarregar essa partição específica do HDFS. Outros trabalhos de cópia que estão carregando outras partições não são afetados.
Migração de dados Delta
No modo DistCp do Data Factory, você pode usar o parâmetro -updatede linha de comando DistCp , gravar dados quando o arquivo de origem e o arquivo de destino diferem em tamanho, para migração de dados delta.
No modo de integração nativo do Data Factory, a maneira mais eficiente de identificar arquivos novos ou alterados do HDFS é usando uma convenção de nomenclatura particionada por tempo. Quando seus dados no HDFS foram particionados por tempo com informações de fatia de tempo no nome do arquivo ou pasta (por exemplo, /aaaa/mm/dd/file.csv), seu pipeline pode identificar facilmente quais arquivos e pastas copiar incrementalmente.
Como alternativa, se os dados no HDFS não estiverem particionados por tempo, o Data Factory poderá identificar arquivos novos ou alterados usando o valor LastModifiedDate . O Data Factory verifica todos os arquivos do HDFS e copia apenas arquivos novos e atualizados que tenham um carimbo de data/hora modificado pela última vez maior que um valor definido.
Se você tiver um grande número de arquivos no HDFS, a verificação inicial de arquivos pode levar muito tempo, independentemente de quantos arquivos correspondem à condição do filtro. Nesse cenário, recomendamos que você primeiro particione os dados usando a mesma partição usada para a migração inicial de instantâneo. Em seguida, a verificação de arquivos pode ocorrer em paralelo.
Estimativa de preço
Considere o seguinte pipeline para migrar dados do HDFS para o armazenamento de Blob do Azure:
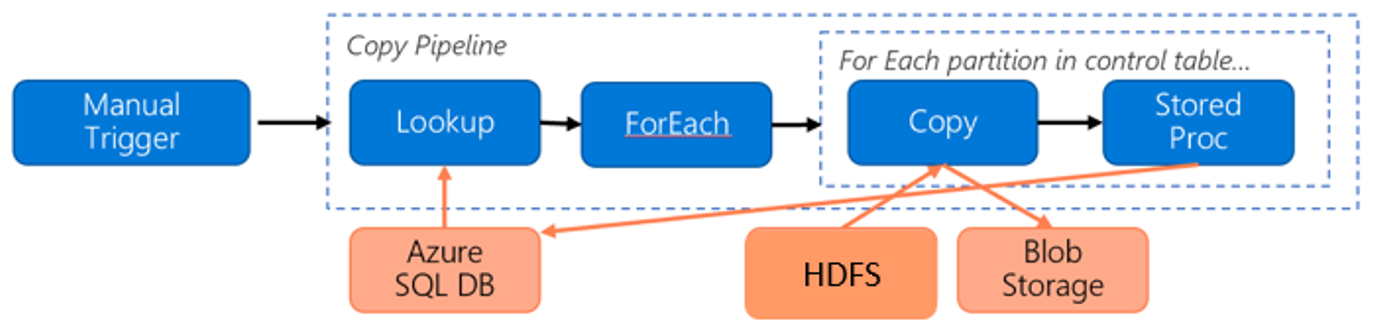
Vamos supor as seguintes informações:
- O volume total de dados é de 1 PB.
- Você migra dados usando o modo de tempo de execução de integração nativa do Data Factory.
- 1 PB é dividido em 1.000 partições e cada cópia move uma partição.
- Cada atividade de cópia é configurada com um tempo de execução de integração auto-hospedado associado a quatro máquinas e que atinge uma taxa de transferência de 500 MBps.
- A simultaneidade ForEach é definida como 4 e a taxa de transferência agregada é de 2 GBps.
- No total, são necessárias 146 horas para concluir a migração.
Aqui está o preço estimado com base em nossas suposições:
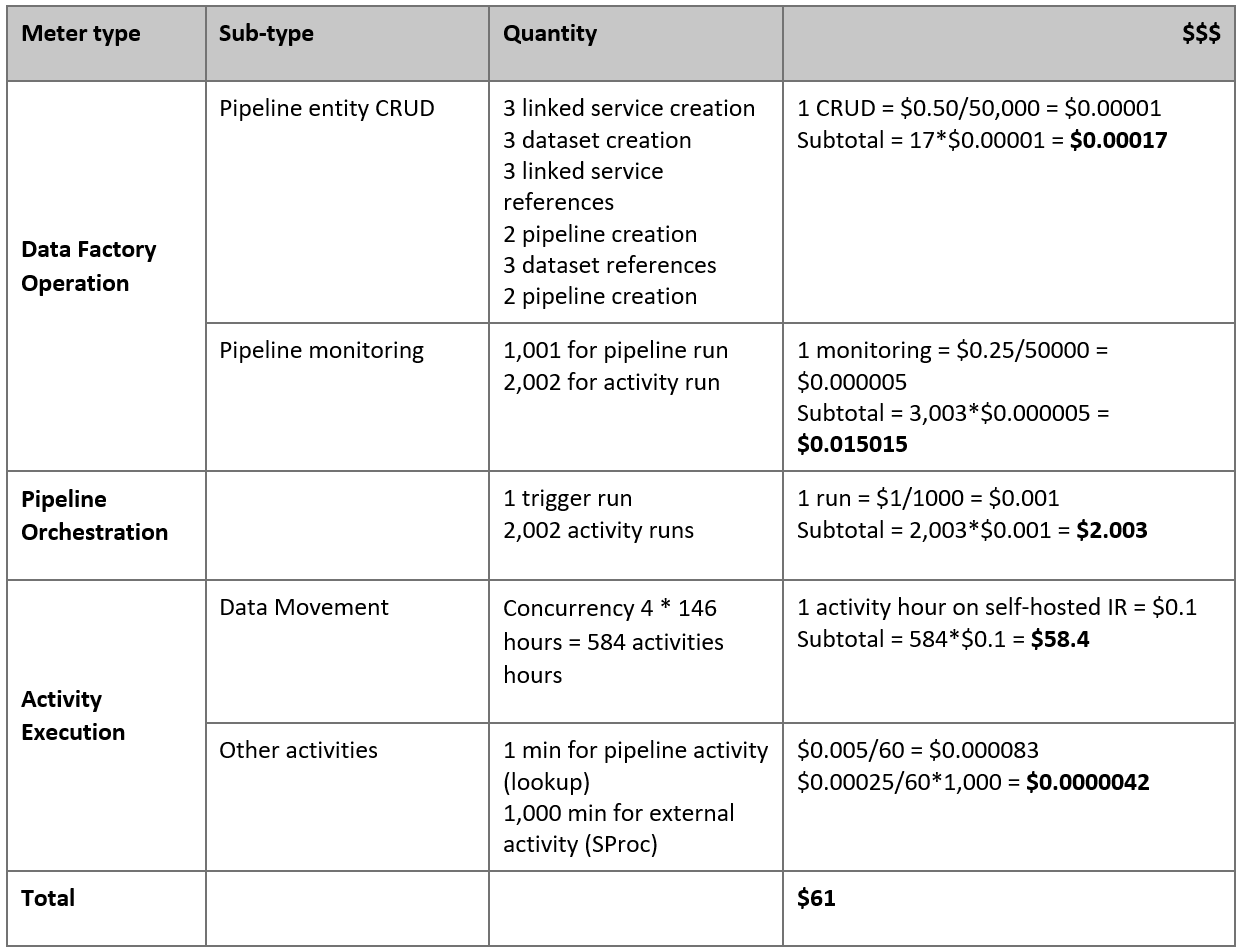
Nota
Este é um exemplo hipotético de preços. Seu preço real depende da taxa de transferência real em seu ambiente. O preço de uma VM do Windows do Azure (com o tempo de execução de integração auto-hospedado instalado) não está incluído.
Referências adicionais
- Conector HDFS
- Conector de armazenamento de Blob do Azure
- Conector do Azure Data Lake Storage Gen2
- Copiar guia de ajuste de desempenho da atividade
- Create and configure a self-hosted integration runtime (Criar e configurar um runtime de integração autoalojado)
- Elevada disponibilidade e escalabilidade do runtime de integração autoalojado
- Considerações sobre segurança de movimentação de dados
- Armazenar credenciais no Cofre da Chave do Azure
- Copiar um arquivo incrementalmente com base em um nome de arquivo particionado por tempo
- Copiar arquivos novos e alterados com base em LastModifiedDate
- Página de preços do Data Factory
Conteúdos relacionados
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários