Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
O sistema de metadados Common Data Model (CDM) permite que os dados e o seu significado sejam facilmente partilhados entre aplicações e processos de negócio. Para saber mais, consulte a visão geral Common Data Model.
Nos pipelines Azure Data Factory e Synapse, os utilizadores podem transformar dados de entidades CDM tanto em forma de model.json como de manifesto armazenados em Azure Data Lake Store Gen2 (ADLS Gen2) usando fluxos de dados de mapeamento. Você também pode coletar dados no formato CDM usando referências de entidade CDM que colocarão seus dados no formato CSV ou Parquet em pastas particionadas.
Mapeando propriedades de fluxo de dados
O Common Data Model está disponível como um conjunto de dados inline no mapeamento de fluxos de dados tanto como fonte como sumidouro.
Nota
Ao escrever entidades CDM, você deve ter uma definição de entidade CDM existente (esquema de metadados) já definida para usar como referência. O coletor de fluxo de dados lerá esse arquivo de entidade CDM e importará o esquema para o coletor para mapeamento de campo.
Nota
Ao usar o CDM com Change Data Capture (CDC) em Fluxos de Dados, as atualizações são detetadas usando uma abordagem CDC baseada em arquivo orientada por carimbos de data/hora modificados pela última vez do arquivo.
Propriedades de origem
A tabela abaixo lista as propriedades suportadas por uma fonte CDM. Você pode editar essas propriedades na guia Opções de origem .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Formato | O formato deve ser cdm |
sim | cdm |
format |
| Formato dos metadados | Onde está localizada a referência da entidade aos dados. Se estiver usando o CDM versão 1.0, escolha manifesto. Se estiver usando uma versão do CDM anterior à 1.0, escolha model.json. | Sim |
'manifest' ou 'model' |
manifestType |
| Localização da raiz: recipiente | Nome do contêiner da pasta CDM | sim | String | Sistema de arquivos |
| Local da raiz: caminho da pasta | Localização da pasta raiz da pasta CDM | sim | String | folderPath |
| Arquivo de manifesto: caminho da entidade | Caminho da pasta da entidade dentro da pasta raiz | não | String | entityPath |
| Arquivo de manifesto: Nome do manifesto | Nome do arquivo de manifesto. O valor padrão é 'default' | Não | String | manifestName |
| Filtrar por última modificação | Opte por filtrar ficheiros com base na data em que foram alterados pela última vez | não | Carimbo de Data/Hora | modificadoApós modificadoAntes |
| Serviço vinculado de esquema | O serviço ligado onde o corpus está localizado | Sim, se estiver usando manifesto |
'adlsgen2' ou 'github' |
corpusLoja |
| Contêiner de referência de entidade | O corpus do contentor está em | sim, se usar manifesto e corpus no ADLS Gen2 | String | adlsgen2_fileSystem |
| Repositório de referência de entidade | Nome do repositório GitHub | Sim, se estiver a usar manifest e corpus no GitHub | String | github_repository |
| Sucursal de referência da entidade | Ramo do repositório GitHub | Sim, se estiver a usar manifest e corpus no GitHub | String | github_branch |
| Pasta Corpus | a localização da raiz do corpus | Sim, se estiver usando manifesto | String | corpusPath |
| Entidade Corpus | Caminho para a referência da entidade | sim | String | entidade |
| Não permitir que nenhum arquivo seja encontrado | Se verdadeiro, um erro não é lançado se nenhum arquivo for encontrado | não |
true ou false |
ignoreNoFilesFound |
Ao selecionar "Referência de entidade" nas transformações Origem e Coletor, você pode selecionar entre estas três opções para o local da referência de entidade:
- Local usa a entidade definida no arquivo de manifesto que já está sendo usado pelo serviço
- Personalizado solicitará que você aponte para um arquivo de manifesto de entidade que seja diferente do arquivo de manifesto que o serviço está usando
- O Standard utilizará uma referência de entidade da biblioteca padrão de entidades CDM mantida em
GitHub.
Configurações do coletor
- Aponte para o arquivo de referência de entidade CDM que contém a definição da entidade que você deseja escrever.
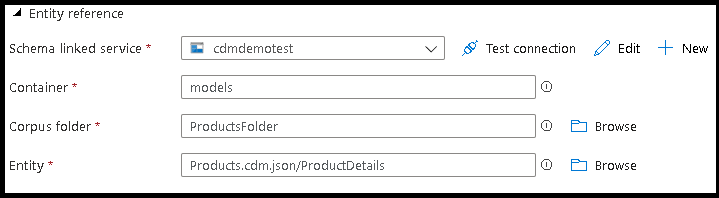
- Defina o caminho da partição e o formato dos arquivos de saída que você deseja que o serviço use para escrever suas entidades.
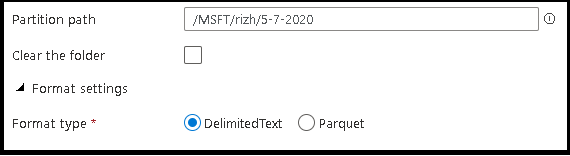
- Defina o local do arquivo de saída e o local e o nome do arquivo de manifesto.

Esquema de importação
O CDM só está disponível como um conjunto de dados embutido e, por padrão, não tem um esquema associado. Para obter metadados de coluna, clique no botão Importar esquema na guia Projeção . Isto permitir-lhe-á fazer referência aos nomes das colunas e aos tipos de dados especificados pelo corpus. Para importar o esquema, uma sessão de depuração de fluxo de dados deve estar ativa e você deve ter um arquivo de definição de entidade CDM existente para apontar.
Ao mapear colunas de fluxo de dados para propriedades de entidade na transformação Coletor, clique na guia "Mapeamento" e selecione "Importar esquema". O serviço lerá a referência de entidade que você apontou em suas opções de coletor, permitindo que você mapeie para o esquema CDM de destino.
Nota
Ao usar model.json tipo de fonte que se origina em fluxos de dados Power BI ou Power Platform, pode encontrar erros de "caminho de corpus é nulo ou vazio" da transformação de origem. Isso provavelmente se deve a problemas de formatação do caminho do local da partição no arquivo model.json. Para corrigir isso, execute as seguintes etapas:
- Abrir o arquivo model.json em um editor de texto
- Encontre as partições. Propriedade de localização
- Alterar "blob.core.windows.net" para "dfs.core.windows.net"
- Corrija qualquer codificação "%2F" no URL para "/"
- Se usar ADF Data Flows, os caracteres especiais no caminho do ficheiro de partição devem ser substituídos por valores alfanuméricos, ou então mudar para Azure Synapse Data Flows
Exemplo de script de fluxo de dados de origem CDM
source(output(
ProductSizeId as integer,
ProductColor as integer,
CustomerId as string,
Note as string,
LastModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
entity: 'Product.cdm.json/Product',
format: 'cdm',
manifestType: 'manifest',
manifestName: 'ProductManifest',
entityPath: 'Product',
corpusPath: 'Products',
corpusStore: 'adlsgen2',
adlsgen2_fileSystem: 'models',
folderPath: 'ProductData',
fileSystem: 'data') ~> CDMSource
Propriedades do lavatório
A tabela abaixo lista as propriedades suportadas por um coletor CDM. Você pode editar essas propriedades na guia Configurações .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Formato | O formato deve ser cdm |
sim | cdm |
format |
| Localização da raiz: recipiente | Nome do contêiner da pasta CDM | sim | String | Sistema de arquivos |
| Local da raiz: caminho da pasta | Localização da pasta raiz da pasta CDM | sim | String | folderPath |
| Arquivo de manifesto: caminho da entidade | Caminho da pasta da entidade dentro da pasta raiz | não | String | entityPath |
| Arquivo de manifesto: Nome do manifesto | Nome do arquivo de manifesto. O valor padrão é 'default' | Não | String | manifestName |
| Serviço vinculado de esquema | O serviço ligado onde o corpus está localizado | sim |
'adlsgen2' ou 'github' |
corpusLoja |
| Contêiner de referência de entidade | O corpus do contentor está em | sim, se corpus no ADLS Gen2 | String | adlsgen2_fileSystem |
| Repositório de referência de entidade | Nome do repositório GitHub | Sim, se corpus está no GitHub | String | github_repository |
| Sucursal de referência da entidade | Ramo do repositório GitHub | Sim, se corpus está no GitHub | String | github_branch |
| Pasta Corpus | a localização da raiz do corpus | sim | String | corpusPath |
| Entidade Corpus | Caminho para a referência da entidade | sim | String | entidade |
| Caminho da partição | Local onde a partição será gravada | não | String | partitionPath |
| Limpar a pasta | Se a pasta de destino for limpa antes da gravação | não |
true ou false |
truncar |
| Tipo de formato | Opte por especificar o formato do parquet | não |
parquet se especificado |
subformato |
| Delimitador de coluna | Se estiver escrevendo em DelimitedText, como delimitar colunas | Sim, se escrever para DelimitedText | String | columnDelimiter |
| Primeira linha como cabeçalho | Se estiver usando DelimitedText, se os nomes das colunas forem adicionados como um cabeçalho | não |
true ou false |
columnNamesAsHeader |
Exemplo de script de fluxo de dados do coletor CDM
O script de fluxo de dados associado é:
CDMSource sink(allowSchemaDrift: true,
validateSchema: false,
entity: 'Product.cdm.json/Product',
format: 'cdm',
entityPath: 'ProductSize',
manifestName: 'ProductSizeManifest',
corpusPath: 'Products',
partitionPath: 'adf',
folderPath: 'ProductSizeData',
fileSystem: 'cdm',
subformat: 'parquet',
corpusStore: 'adlsgen2',
adlsgen2_fileSystem: 'models',
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CDMSink
Conteúdos relacionados
Crie uma transformação de origem no mapeamento do fluxo de dados.