Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
O Azure Data Factory e também o Synapse Analytics suportam o desenvolvimento iterativo e a depuração de pipelines. Esses recursos permitem que você teste suas alterações antes de criar uma solicitação pull ou publicá-las no serviço.
Para uma introdução e demonstração de oito minutos desse recurso, assista ao seguinte vídeo:
Depurar um pipeline
À medida que você cria usando a tela de pipeline, você pode testar suas atividades usando o recurso Depurar . Quando você executa execuções de teste, não precisa publicar suas alterações no serviço antes de selecionar Depurar. Esse recurso é útil em cenários em que você deseja garantir que as alterações funcionem conforme o esperado antes de atualizar o fluxo de trabalho.
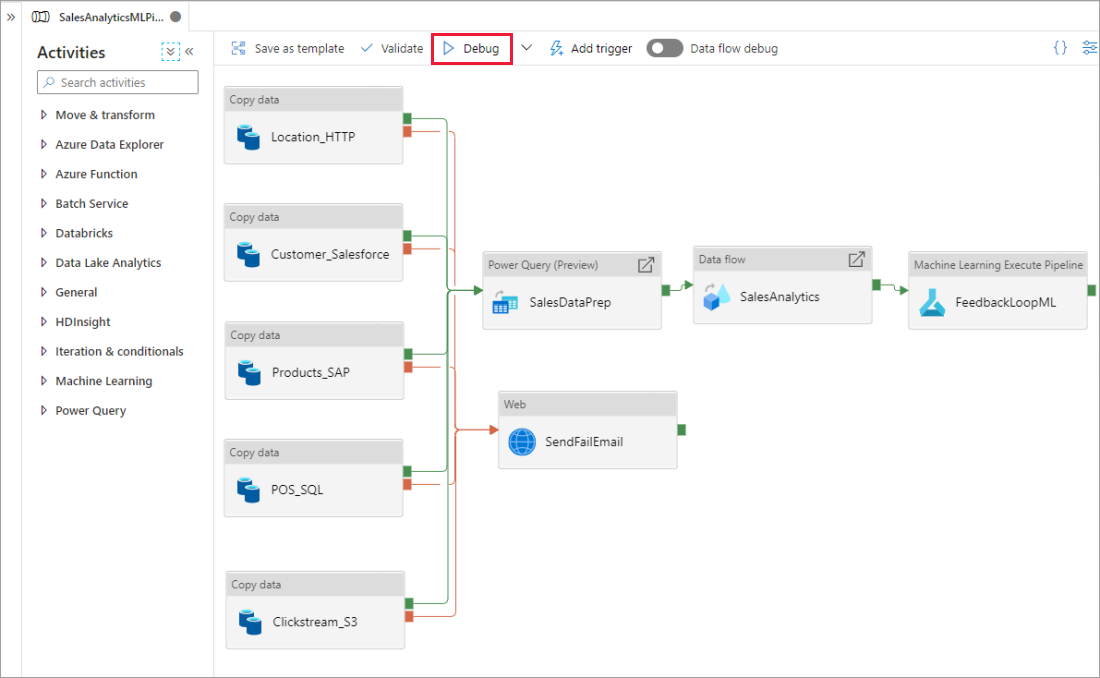
À medida que o pipeline está em execução, é possível ver os resultados de cada atividade na guia Saída da tela do pipeline.
Exiba os resultados de suas execuções de teste na janela Saída da tela do pipeline.
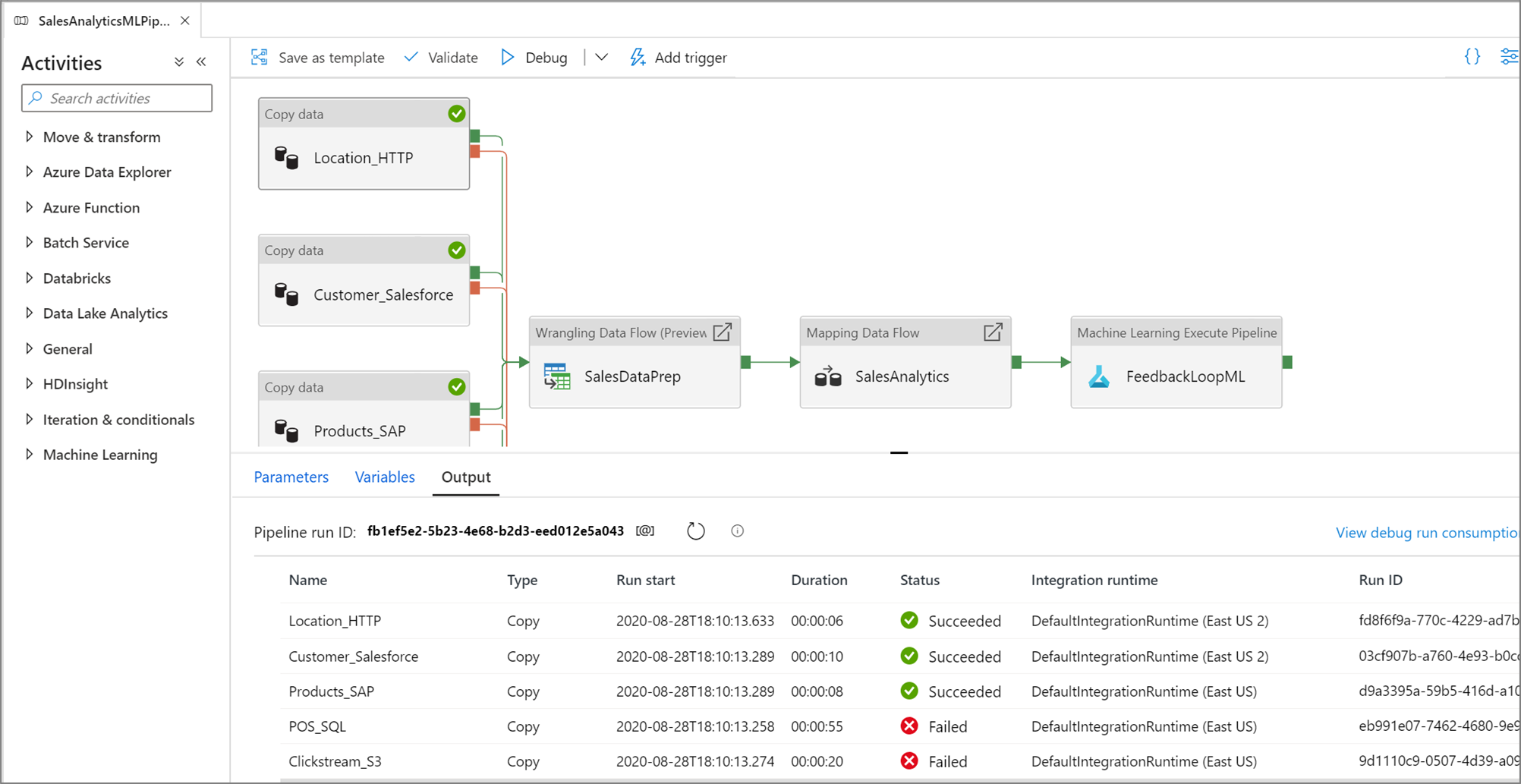
Depois que uma execução de teste for bem-sucedida, adicione mais atividades ao seu pipeline e continue a depuração de maneira iterativa. Você também pode Cancelar uma execução de teste enquanto ela estiver em andamento.
Importante
Selecionar Depurar aciona a execução do pipeline. Por exemplo, se o pipeline contiver atividade de cópia, a execução do teste copiará os dados da origem para o destino. Como resultado, recomendamos que você use pastas de teste em suas atividades de cópia e outras atividades ao depurar. Depois de debugado o pipeline, mude para as pastas reais para o uso habitual.
Definição de pontos de interrupção
O serviço permite que depure um pipeline até chegar a uma atividade específica na interface do pipeline. Coloque um ponto de interrupção na atividade até o qual você deseja testar e selecione Depurar. O serviço garante que o teste seja executado somente até a atividade do ponto de interrupção na tela do pipeline. Esse recurso Debug Until é útil quando você não deseja testar todo o pipeline, mas apenas um subconjunto de atividades dentro do pipeline.
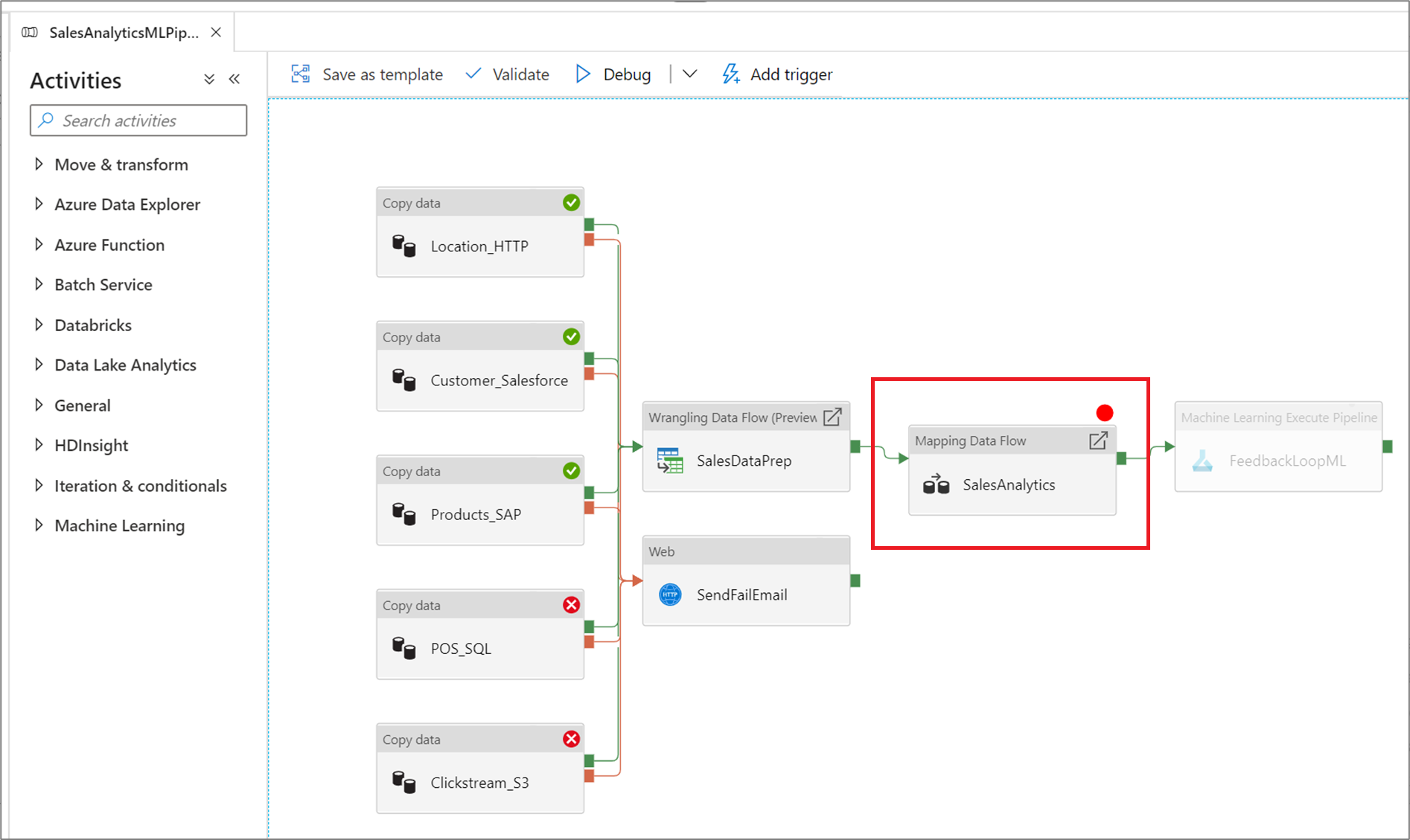
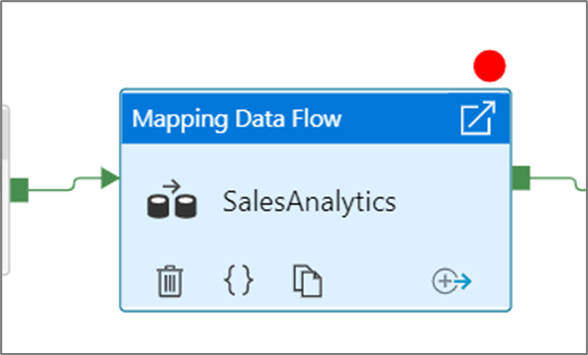
Para definir um ponto de interrupção, selecione um elemento na interface do pipeline. Uma opção Depurar até aparece como um círculo vermelho vazio no canto superior direito do elemento.
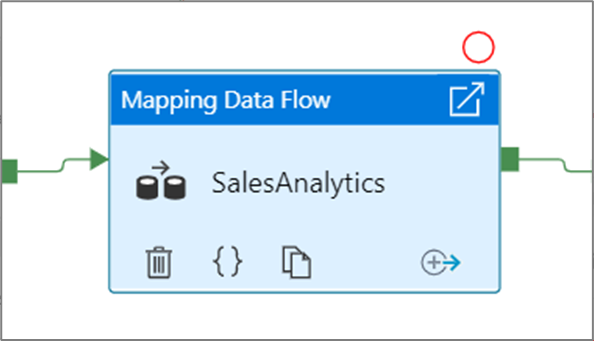
Depois de selecionar a opção Depurar até , ela muda para um círculo vermelho preenchido para indicar que o ponto de interrupção está habilitado.
Monitorização de execuções de depuração
Quando você executa uma execução de depuração de pipeline, os resultados aparecerão na janela Saída da tela de pipeline. A guia de saída conterá apenas a execução mais recente que ocorreu durante a sessão atual do navegador.
Para exibir uma vista histórica das execuções de depuração ou ver uma lista de todas as execuções de depuração ativas, pode aceder à experiência Monitor.
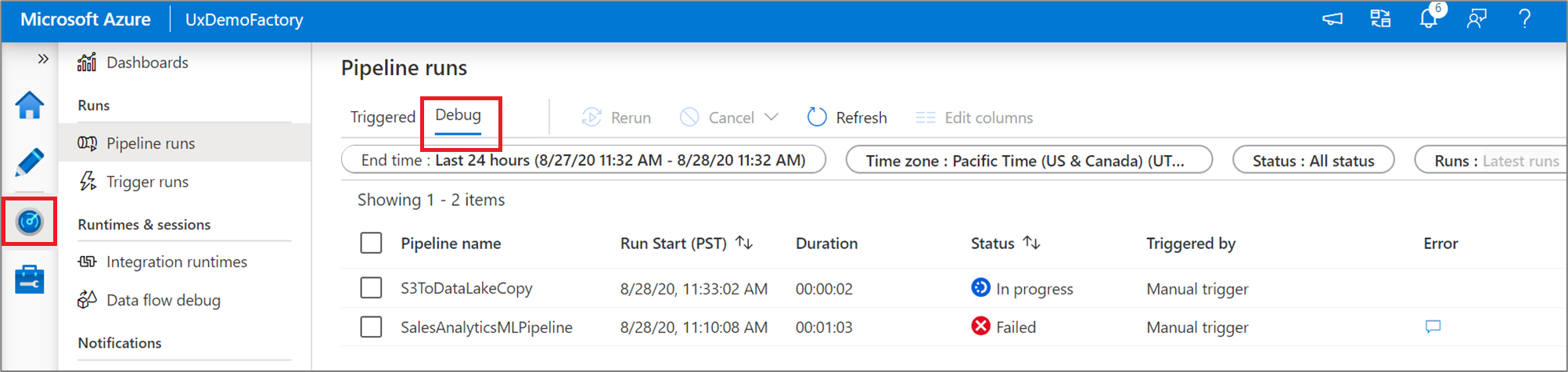
Nota
O serviço mantém o histórico de execução de depuração por apenas 15 dias.
Depurando fluxos de dados de mapeamento
O mapeamento de fluxos de dados permite criar uma lógica de transformação de dados sem código que é executada em escala. Ao criar sua lógica, você pode ativar uma sessão de depuração para trabalhar interativamente com seus dados usando um cluster do Spark ao vivo. Para saber mais, leia sobre o mapeamento do modo de depuração de fluxo de dados.
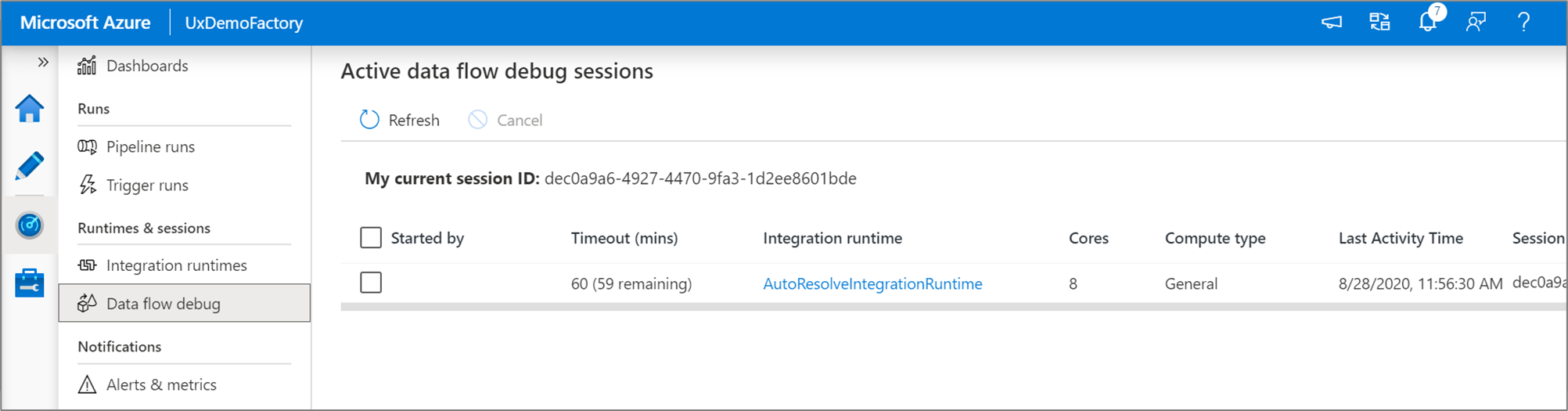
Você pode monitorizar sessões de depuração de fluxo de dados ativas na interface do Monitor.
A visualização de dados no designer de fluxo de dados e a depuração de fluxos de dados no pipeline destinam-se a funcionar melhor com pequenas amostras de dados. No entanto, se precisares de testar a tua lógica num pipeline ou fluxo de dados contra grandes quantidades de dados, aumenta o tamanho do Azure Integration Runtime usado na sessão de depuração com mais núcleos e um mínimo de computação de uso geral.
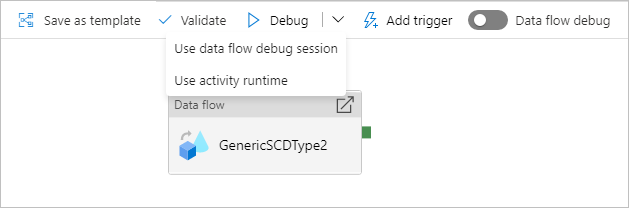
Depurando um pipeline com uma atividade de fluxo de dados
Ao executar um pipeline de depuração com um fluxo de dados, tem duas opções sobre quais recursos de computação usar. Você pode usar um cluster de debug existente ou criar um novo cluster just-in-time (sob demanda) para os seus fluxos de dados.
O uso de uma sessão de depuração existente reduzirá consideravelmente o tempo de inicialização do fluxo de dados, pois o cluster já está em execução, mas não é recomendado para cargas de trabalho complexas ou paralelas, pois pode falhar quando vários trabalhos são executados ao mesmo tempo.
O uso do tempo de execução da atividade criará um novo cluster usando as configurações especificadas no tempo de execução de integração de cada atividade de fluxo de dados. Isso permite que cada trabalho seja isolado e deve ser usado para cargas de trabalho complexas ou testes de desempenho. Também podes controlar o TTL no Azure IR para que os recursos do cluster usados para depuração continuem disponíveis nesse período para servir pedidos adicionais de tarefas.
Nota
Se tiver um pipeline com fluxos de dados a executar em paralelo ou fluxos de dados que precisam de ser testados com grandes conjuntos de dados, escolha "Usar Activity Runtime" para que o serviço possa usar o Integration Runtime que selecionou na atividade de fluxo de dados. Isso permitirá que os fluxos de dados sejam executados em vários clusters e pode acomodar suas execuções de fluxo de dados paralelo.
Conteúdos relacionados
Depois de testar suas alterações, promova-as para ambientes mais altos usando integração e implantação contínuas.