Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
Este quickstart descreve como usar o SDK .NET para criar um Azure Data Factory. O pipeline que você cria nesta fábrica de dados copia dados de uma pasta para outra num armazenamento de blobs do Azure. Para um tutorial sobre como transformar dados usando Azure Data Factory, veja Tutorial: Transformar dados usando Spark.
Pré-requisitos
subscrição do Azure
Se não tiver uma subscrição Azure, crie uma conta gratuita antes de começar.
Funções do Azure
Para criar as instâncias do Data Factory, a conta de utilizador que usa para iniciar sessão no Azure deve ser membro da função contribuidor ou proprietário, ou administrador da subscrição do Azure. Para ver as permissões que tem na subscrição, vá ao portal Azure, selecione o seu nome de utilizador no canto superior direito, selecione "... Ícone " para mais opções, e depois seleciona Minhas permissões. Se tiver acesso a várias subscrições, selecione a subscrição apropriada.
Para criar e gerenciar recursos filho para o Data Factory - incluindo conjuntos de dados, serviços vinculados, pipelines, gatilhos e tempos de execução de integração - os seguintes requisitos são aplicáveis:
- Para criar e gerir recursos filhos no portal Azure, deve pertencer ao papel Data Factory Contributor ao nível do grupo de recursos ou superior.
- Para criar e gerenciar recursos filho com o PowerShell ou o SDK, a função de colaborador no nível de recurso ou acima é suficiente.
Para obter instruções de exemplo sobre como adicionar um utilizador a uma função, veja o artigo Adicionar funções.
Para obter mais informações, veja os artigos seguintes:
conta de armazenamento do Azure
Você utiliza uma conta Azure Storage de uso geral (especificamente armazenamento Blob) como armazenamento de dados de origem e destino neste guia introdutório. Se não tiver uma conta de Azure Storage de uso geral, consulte Criar uma conta de armazenamento para criar uma.
Obter o nome da conta de armazenamento
Precisas do nome da tua conta do Azure Storage para esta introdução rápida. O procedimento a seguir fornece etapas para obter o nome da sua conta de armazenamento:
- Num navegador web, vai ao portal Azure e inicia sessão usando o teu nome de utilizador e palavra-passe Azure.
- No menu do portal Azure, selecione Todos os serviços, depois selecione Storage>Contas de Armazenamento. Você também pode pesquisar e selecionar Contas de armazenamento em qualquer página.
- Na página Contas de armazenamento, filtre a sua conta de armazenamento (se necessário) e selecione a sua conta de armazenamento.
Você também pode pesquisar e selecionar Contas de armazenamento em qualquer página.
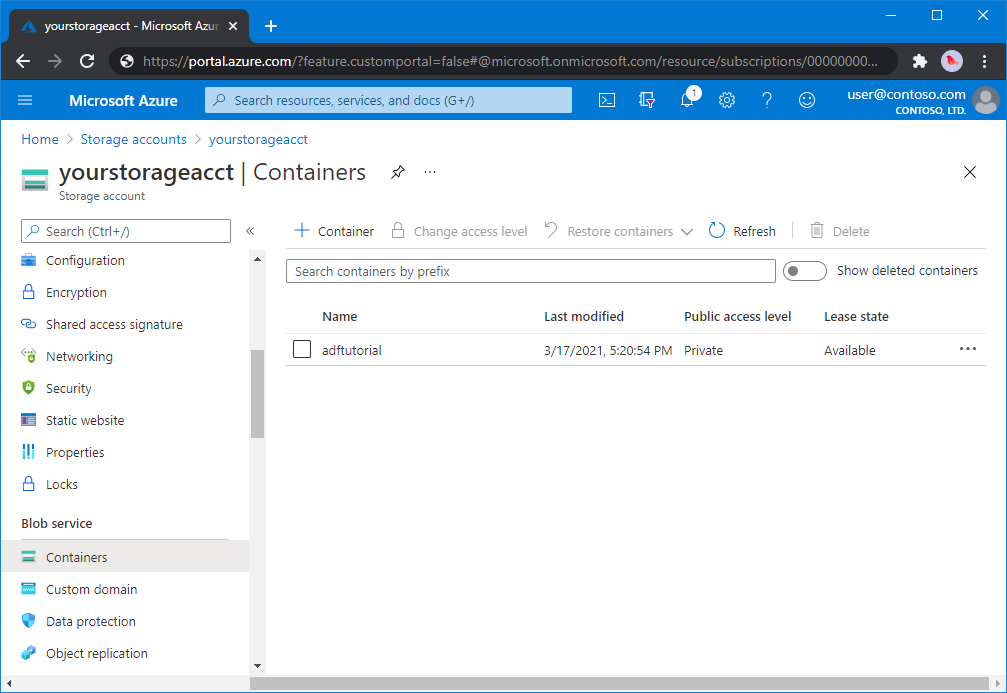
Criar um contentor de blobs
Nesta secção, crias um contentor de blob chamado adftutorial no armazenamento de Azure Blob.
Na página da conta de armazenamento, selecione Visão geral>de contêineres.
Na barra de ferramentas da página <Nome da conta> - Contentores, selecione Contentor.
Na caixa de diálogo Novo contentor, introduza adftutorial para o nome e selecione OK. A página <Nome da conta> - Contentores é atualizada para incluir adftutorial na lista de contentores.
Adicionar uma pasta de entrada e um arquivo para o contêiner de blob
Nesta seção, você cria uma pasta chamada input no contêiner criado e, em seguida, carrega um arquivo de exemplo para a pasta de entrada. Antes de começar, abra um editor de texto, como o Bloco de Notas, e crie um arquivo chamado emp.txt com o seguinte conteúdo:
John, Doe
Jane, Doe
Salve o arquivo na pasta C:\ADFv2QuickStartPSH . (Se a pasta ainda não existir, crie-a.) Depois regresse ao portal do Azure e siga estes passos:
Na página Nome da< conta> - Contêineres de onde você parou, selecione adftutorial na lista atualizada de contêineres.
- Se fechaste a janela ou fores a outra página, inicia sessão no portal Azure novamente.
- No menu do portal Azure, selecione Todos os serviços, depois selecione Storage>Contas de Armazenamento. Você também pode pesquisar e selecionar Contas de armazenamento em qualquer página.
- Selecione sua conta de armazenamento e, em seguida, selecione Containers>adftutorial.
Na barra de ferramentas da página do contêiner adftutorial , selecione Carregar.
Na página Carregar blob, selecione a caixa Arquivos e, em seguida, procure e selecione o arquivo emp.txt.
Expanda o título Avançado . A página agora é exibida como mostrado:
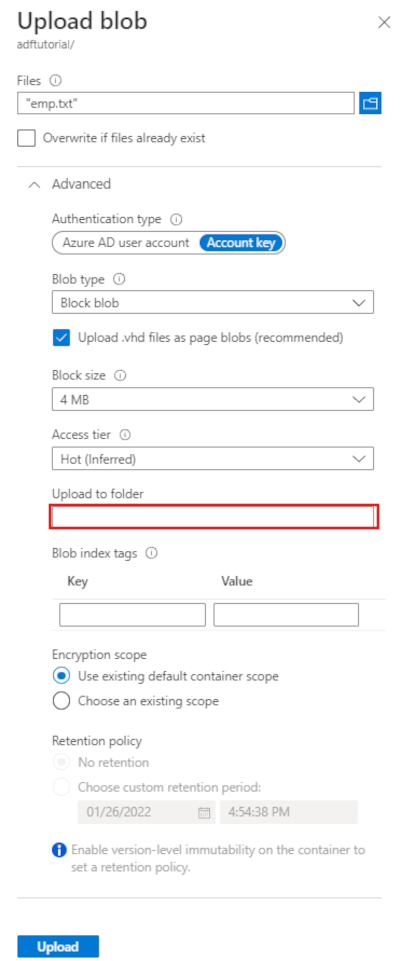
Na caixa Carregar para pasta, insira input.
Selecione o botão Carregar. Deverá ver o ficheiro emp.txt e o estado do carregamento na lista.
Selecione o ícone Fechar (um X) para fechar a página Carregar blob .
Mantenha a página do contêiner adftutorial aberta. Você o usa para verificar a saída no final deste início rápido.
Visual Studio
O guia neste artigo utiliza o Visual Studio 2019. Os procedimentos para o Visual Studio 2013, 2015 ou 2017 diferem ligeiramente.
Crie uma aplicação no Microsoft Entra ID
Nas secções de Como: Usar o portal para criar uma aplicação Microsoft Entra e um principal de serviço que possa aceder a recursos, siga as instruções para realizar estas tarefas:
- Em Cria uma aplicação Microsoft Entra, cria uma aplicação que represente a .NET aplicação que estás a criar neste tutorial. Para o URL de início de sessão, pode fornecer um URL fictício conforme mostrado no artigo (
https://contoso.org/exampleapp). - Em Obter valores para entrar, obtenha a ID do aplicativo e a ID do locatário e anote esses valores que você usa posteriormente neste tutorial.
- Em Certificados e segredos, obtenha a chave de autenticação e anote esse valor que você usa posteriormente neste tutorial.
- Em Atribuir o aplicativo a uma função, atribua o aplicativo à função de Colaborador no nível da assinatura para que o aplicativo possa criar fábricas de dados na assinatura.
Criar um projeto Visual Studio
De seguida, crie uma aplicação de consola C# .NET no Visual Studio:
- Lançar Visual Studio.
- Na janela Iniciar, selecione Criar um novo projeto>Consola App (.NET Framework). .NET versão 4.5.2 ou superior é necessária.
- Em Nome do Projeto, introduza ADFv2QuickStart.
- Selecione Create (Criar) para criar o projeto.
Instalar pacotes NuGet
Selecione Tools>NuGet Package Manager>Package Manager Consola.
No painel Package Manager Console, execute os seguintes comandos para instalar os pacotes. Para mais informações, consulte o Azure. ResourceManager.DataFactory Pacote NuGet.
Install-Package Azure.ResourceManager.DataFactory -IncludePrerelease Install-Package Azure.Identity
Criar uma fábrica de dados
Abra Program.cs e inclua as instruções a seguir para adicionar referências a namespaces.
using Azure; using Azure.Core; using Azure.Core.Expressions.DataFactory; using Azure.Identity; using Azure.ResourceManager; using Azure.ResourceManager.DataFactory; using Azure.ResourceManager.DataFactory.Models; using Azure.ResourceManager.Resources; using System; using System.Collections.Generic;Adicione o código seguinte ao método Principal que define as variáveis. Substitua os espaços reservados pelos seus próprios valores. Para uma lista das regiões do Azure em que o Data Factory está disponível atualmente, selecione as regiões que lhe interessam na página seguinte e depois expanda Analytics para localizar Data Factory: Produtos disponíveis por região. Os armazenamentos de dados (Azure Storage, Azure SQL Database e outros) e os computadores (HDInsight e outros) usados pela data factory podem estar noutras regiões.
// Set variables string tenantID = "<your tenant ID>"; string applicationId = "<your application ID>"; string authenticationKey = "<your authentication key for the application>"; string subscriptionId = "<your subscription ID where the data factory resides>"; string resourceGroup = "<your resource group where the data factory resides>"; string region = "<the location of your resource group>"; string dataFactoryName = "<specify the name of data factory to create. It must be globally unique.>"; string storageAccountName = "<your storage account name to copy data>"; string storageKey = "<your storage account key>"; // specify the container and input folder from which all files // need to be copied to the output folder. string inputBlobContainer = "<blob container to copy data from, e.g. containername>"; string inputBlobPath = "<path to existing blob(s) to copy data from, e.g. inputdir/file>"; //specify the contains and output folder where the files are copied string outputBlobContainer = "<blob container to copy data from, e.g. containername>"; string outputBlobPath = "<the blob path to copy data to, e.g. outputdir/file>"; // name of the Azure Storage linked service, blob dataset, and the pipeline string storageLinkedServiceName = "AzureStorageLinkedService"; string blobDatasetName = "BlobDataset"; string pipelineName = "Adfv2QuickStartPipeline";Adicione o código seguinte ao método Main que cria uma fábrica de dados.
ArmClient armClient = new ArmClient( new ClientSecretCredential(tenantID, applicationId, authenticationKey, new TokenCredentialOptions { AuthorityHost = AzureAuthorityHosts.AzurePublicCloud }), subscriptionId, new ArmClientOptions { Environment = ArmEnvironment.AzurePublicCloud } ); ResourceIdentifier resourceIdentifier = SubscriptionResource.CreateResourceIdentifier(subscriptionId); SubscriptionResource subscriptionResource = armClient.GetSubscriptionResource(resourceIdentifier); Console.WriteLine("Get an existing resource group " + resourceGroupName + "..."); var resourceGroupOperation = subscriptionResource.GetResourceGroups().Get(resourceGroupName); ResourceGroupResource resourceGroupResource = resourceGroupOperation.Value; Console.WriteLine("Create a data factory " + dataFactoryName + "..."); DataFactoryData dataFactoryData = new DataFactoryData(AzureLocation.EastUS2); var dataFactoryOperation = resourceGroupResource.GetDataFactories().CreateOrUpdate(WaitUntil.Completed, dataFactoryName, dataFactoryData); Console.WriteLine(dataFactoryOperation.WaitForCompletionResponse().Content); // Get the data factory resource DataFactoryResource dataFactoryResource = dataFactoryOperation.Value;
Criar um serviço ligado
Adicione o seguinte código ao método Main que cria um serviço ligado Azure Storage.
Os serviços ligados são criados numa fábrica de dados para ligar os seus arquivos de dados e serviços de computação a essa fábrica de dados. Neste Quickstart, só precisas de criar um serviço ligado do Azure Blob Storage tanto para a fonte de cópias como para a loja do sink; chama-se "AzureBlobStorageLinkedService" no exemplo.
// Create an Azure Storage linked service
Console.WriteLine("Create a linked service " + storageLinkedServiceName + "...");
AzureBlobStorageLinkedService azureBlobStorage = new AzureBlobStorageLinkedService()
{
ConnectionString = azureBlobStorageConnectionString
};
DataFactoryLinkedServiceData linkedServiceData = new DataFactoryLinkedServiceData(azureBlobStorage);
var linkedServiceOperation = dataFactoryResource.GetDataFactoryLinkedServices().CreateOrUpdate(WaitUntil.Completed, storageLinkedServiceName, linkedServiceData);
Console.WriteLine(linkedServiceOperation.WaitForCompletionResponse().Content);
Criar um conjunto de dados
Adicione o seguinte código ao método Main que cria um conjunto de dados de texto delimitado.
Você define um conjunto de dados que representa os dados a serem copiados de uma fonte para um coletor. Neste exemplo, este conjunto de dados de texto delimitado faz referência ao serviço ligado do Azure Blob Storage que criou na etapa anterior. O conjunto de dados usa dois parâmetros cujo valor é definido em uma atividade que consome o conjunto de dados. Os parâmetros são usados para construir o "container" e o "folderPath" apontando para onde os dados residem/estão armazenados.
// Create an Azure Blob dataset
DataFactoryLinkedServiceReference linkedServiceReference = new DataFactoryLinkedServiceReference(DataFactoryLinkedServiceReferenceType.LinkedServiceReference, storageLinkedServiceName);
DelimitedTextDataset delimitedTextDataset = new DelimitedTextDataset(linkedServiceReference)
{
DataLocation = new AzureBlobStorageLocation
{
Container = DataFactoryElement<string>.FromExpression("@dataset().container"),
FileName = DataFactoryElement<string>.FromExpression("@dataset().path")
},
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("container",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("path",new EntityParameterSpecification(EntityParameterType.String))
},
FirstRowAsHeader = false,
QuoteChar = "\"",
EscapeChar = "\\",
ColumnDelimiter = ","
};
DataFactoryDatasetData datasetData = new DataFactoryDatasetData(delimitedTextDataset);
var datasetOperation = dataFactoryResource.GetDataFactoryDatasets().CreateOrUpdate(WaitUntil.Completed, blobDatasetName, datasetData);
Console.WriteLine(datasetOperation.WaitForCompletionResponse().Content);
Criar uma canalização
Adicione o código seguinte ao método Main que cria um pipeline com uma atividade de cópia.
Neste exemplo, esse pipeline contém uma atividade e usa quatro parâmetros: o contêiner e o caminho do blob de entrada e o contêiner e o caminho do blob de saída. Os valores destes parâmetros são definidos quando o pipeline é acionado/executado. A atividade de cópia refere-se ao mesmo conjunto de dados de blobs criado no passo anterior como entrada e saída. Quando o conjunto de dados é usado como um conjunto de dados de entrada, o contêiner e o caminho de entrada são especificados. E, quando o conjunto de dados é usado como um conjunto de dados de saída, o contêiner e o caminho de saída são especificados.
// Create a pipeline with a copy activity
Console.WriteLine("Creating pipeline " + pipelineName + "...");
DataFactoryPipelineData pipelineData = new DataFactoryPipelineData()
{
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("inputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("inputPath",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputPath",new EntityParameterSpecification(EntityParameterType.String))
},
Activities =
{
new CopyActivity("CopyFromBlobToBlob",new DataFactoryBlobSource(),new DataFactoryBlobSink())
{
Inputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.inputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.inputPath\""))
}
}
},
Outputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.outputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.outputPath\""))
}
}
}
}
}
};
var pipelineOperation = dataFactoryResource.GetDataFactoryPipelines().CreateOrUpdate(WaitUntil.Completed, pipelineName, pipelineData);
Console.WriteLine(pipelineOperation.WaitForCompletionResponse().Content);
Criar uma execução do pipeline
Adicione o código seguinte ao método Main que aciona uma execução de pipeline.
Esse código também define valores dos parâmetros inputContainer, inputPath, outputContainer e outputPath especificados no pipeline com os valores reais dos caminhos de blob de origem e coletor.
// Create a pipeline run
Console.WriteLine("Creating pipeline run...");
Dictionary<string, BinaryData> parameters = new Dictionary<string, BinaryData>()
{
{ "inputContainer",BinaryData.FromObjectAsJson(inputBlobContainer) },
{ "inputPath",BinaryData.FromObjectAsJson(inputBlobPath) },
{ "outputContainer",BinaryData.FromObjectAsJson(outputBlobContainer) },
{ "outputPath",BinaryData.FromObjectAsJson(outputBlobPath) }
};
var pipelineResource = dataFactoryResource.GetDataFactoryPipeline(pipelineName);
var runResponse = pipelineResource.Value.CreateRun(parameters);
Console.WriteLine("Pipeline run ID: " + runResponse.Value.RunId);
Monitorizar a execução de um pipeline
Adicione o código seguinte ao método Main para verificar continuamente o estado até terminar de copiar os dados.
// Monitor the pipeline run Console.WriteLine("Checking pipeline run status..."); DataFactoryPipelineRunInfo pipelineRun; while (true) { pipelineRun = dataFactoryResource.GetPipelineRun(runResponse.Value.RunId.ToString()); Console.WriteLine("Status: " + pipelineRun.Status); if (pipelineRun.Status == "InProgress" || pipelineRun.Status == "Queued") System.Threading.Thread.Sleep(15000); else break; }Adicione o código a seguir ao método Main que recupera detalhes da execução da atividade de cópia, como o tamanho dos dados lidos ou gravados.
// Check the copy activity run details Console.WriteLine("Checking copy activity run details..."); var queryResponse = dataFactoryResource.GetActivityRun(pipelineRun.RunId.ToString(), new RunFilterContent(DateTime.UtcNow.AddMinutes(-10), DateTime.UtcNow.AddMinutes(10))); var enumerator = queryResponse.GetEnumerator(); enumerator.MoveNext(); if (pipelineRun.Status == "Succeeded") Console.WriteLine(enumerator.Current.Output); else Console.WriteLine(enumerator.Current.Error); Console.WriteLine("\nPress any key to exit..."); Console.ReadKey();
Executar o código
Crie e inicie a aplicação e, em seguida, confirme a execução do pipeline.
O console imprime o progresso da criação da fábrica de dados, do serviço conectado, dos conjuntos de dados, do pipeline e da execução do pipeline. Em seguida, ele verifica o status de execução do pipeline. Aguarde até ver os detalhes da execução da atividade de cópia, incluindo o tamanho dos dados de leitura/gravação. Depois usa ferramentas como Azure Storage Explorer para verificar se o(s) blob(s) estão copiados para "outputBlobPath" a partir do "inputBlobPath" conforme especificado nas variáveis.
Saída da amostra
Create a data factory quickstart-adf...
{
"name": "quickstart-adf",
"type": "Microsoft.DataFactory/factories",
"properties": {
"provisioningState": "Succeeded",
"version": "2018-06-01"
},
"location": "eastus2"
}
Create a linked service AzureBlobStorage...
{
"name": "AzureBlobStorage",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;",
"encryptedCredential": "<encryptedCredential>"
}
}
}
Creating dataset BlobDelimitedDataset...
{
"name": "BlobDelimitedDataset",
"type": "Microsoft.DataFactory/factories/datasets",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"type": "LinkedServiceReference",
"referenceName": "AzureBlobStorage"
},
"parameters": {
"container": {
"type": "String"
},
"path": {
"type": "String"
}
},
"typeProperties": {
"location": {
"container": {
"type": "Expression",
"value": "@dataset().container"
},
"type": "AzureBlobStorageLocation",
"fileName": {
"type": "Expression",
"value": "@dataset().path"
}
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\\",
"firstRowAsHeader": false
}
}
}
Creating pipeline Adfv2QuickStartPipeline...
{
"properties": {
"activities": [
{
"inputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.inputContainer",
"path": "@pipeline().parameters.inputPath"
}
}
],
"outputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.outputContainer",
"path": "@pipeline().parameters.outputPath"
}
}
],
"name": "CopyFromBlobToBlob",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
}
}
],
"parameters": {
"inputContainer": {
"type": "String"
},
"inputPath": {
"type": "String"
},
"outputContainer": {
"type": "String"
},
"outputPath": {
"type": "String"
}
}
}
}
Creating pipeline run...
Pipeline run ID: 3aa26ffc-5bee-4db9-8bac-ccbc2d7b51c1
Checking pipeline run status...
Status: InProgress
Status: Succeeded
Checking copy activity run details...
{
"dataRead": 1048,
"dataWritten": 1048,
"filesRead": 1,
"filesWritten": 1,
"sourcePeakConnections": 1,
"sinkPeakConnections": 1,
"copyDuration": 8,
"throughput": 1.048,
"errors": [],
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (East US 2)",
"usedDataIntegrationUnits": 4,
"billingReference": {
"activityType": "DataMovement",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
],
"totalBillableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
]
},
"usedParallelCopies": 1,
"executionDetails": [
{
"source": {
"type": "AzureBlobStorage"
},
"sink": {
"type": "AzureBlobStorage"
},
"status": "Succeeded",
"start": "2023-12-15T10:25:33.9991558Z",
"duration": 8,
"usedDataIntegrationUnits": 4,
"usedParallelCopies": 1,
"profile": {
"queue": {
"status": "Completed",
"duration": 5
},
"transfer": {
"status": "Completed",
"duration": 1,
"details": {
"listingSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"readingFromSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"writingToSink": {
"type": "AzureBlobStorage",
"workingDuration": 0
}
}
}
},
"detailedDurations": {
"queuingDuration": 5,
"transferDuration": 1
}
}
],
"dataConsistencyVerification": {
"VerificationResult": "NotVerified"
}
}
Press any key to exit...
Verificar a saída
O pipeline cria automaticamente a pasta de saída no contentor de blob adftutorial. Em seguida, ele copia o arquivo emp.txt da pasta de entrada para a pasta de saída.
- No portal Azure, na página do contentor adftutorial onde parou na secção Adicionar uma pasta de entrada e ficheiro para o contentor de blobs acima, selecione Refresh para ver a pasta de saída.
- Na lista de pastas, selecione saída.
- Confirme se o ficheiro emp.txt foi copiado para a pasta de saída.
Limpar recursos
Para excluir programaticamente o data factory, adicione as seguintes linhas de código ao programa:
Console.WriteLine("Deleting the data factory");
dataFactoryResource.Delete(WaitUntil.Completed);
Próximos passos
O pipeline neste exemplo copia dados de um local para outro num armazenamento de blob do Azure. Leia os tutoriais para saber como utilizar o Data Factory em mais cenários.