Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo aplica-se aos seguintes conectores: Amazon S3, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP e SFTP.
Importante
O serviço introduziu um novo modelo de conjunto de dados baseado em formato, consulte o artigo de formato correspondente com detalhes:
-
Formato Avro
-
Formato binário
-
Formato de texto delimitado
-
Formato JSON
-
Formato ORC
-
Formato Parquet
As configurações restantes mencionadas neste artigo ainda são suportadas como estão para compatibilidade com versões anteriores. Sugere-se que você use o novo modelo no futuro.
Formato de texto (legado)
Nota
Conheça o novo modelo no artigo Formato de texto delimitado. As seguintes configurações no conjunto de dados de armazenamento de dados baseado em arquivo ainda são suportadas como estão para compatibilidade com versões anteriores. Sugere-se que você use o novo modelo no futuro.
Se você quiser ler de um arquivo de texto ou gravar em um arquivo de texto, defina a type propriedade na format seção do conjunto de dados como TextFormat. Também pode especificar as seguintes propriedades opcionais na secção format. Veja a secção Exemplo de TextFormat sobre como configurar.
| Property | Description | Valores permitidos | Necessário |
|---|---|---|---|
| columnDelimiter | O caráter utilizado para separar colunas num ficheiro. Você pode considerar o uso de um caractere raro não imprimível que pode não existir em seus dados. Por exemplo, especifique "\u0001", que representa o início do título (SOH). | Só é permitido um caráter. O valor predefinido é a vírgula (“,”). Para usar um caractere Unicode, consulte Caracteres Unicode para obter o código correspondente para ele. |
Não |
| rowDelimiter | O caráter utilizado para separar linhas num ficheiro. | Só é permitido um caráter. O valor predefinido é um dos seguintes valores: ["\r\n", "\r", "\n"] na leitura e "\r\n" na escrita. | Não |
| escapeChar | O caráter especial utilizado para escapar a um delimitador de colunas no conteúdo do ficheiro de entrada. Não pode especificar simultaneamente o escapeChar e o quoteChar para uma tabela. |
Só é permitido um caráter. Não existem valores predefinidos. Exemplo: se você tiver vírgula (',') como delimitador de coluna, mas quiser ter o caractere vírgula no texto (exemplo: "Olá, mundo"), você pode definir '$' como o caractere de escape e usar a string "Hello$, world" na fonte. |
Não |
| quoteChar | O caráter utilizado para colocar um valor de cadeia entre aspas. Os delimitadores de colunas e linhas dentro dos carateres de aspas são tratados como parte do valor de cadeia. Esta propriedade é aplicável a conjuntos de dados de entrada e de saída. Não pode especificar simultaneamente o escapeChar e o quoteChar para uma tabela. |
Só é permitido um caráter. Não existem valores predefinidos. Por exemplo, se você tiver vírgula (',') como delimitador de coluna, mas quiser ter um caractere de vírgula no texto (exemplo: <Olá, mundo>), você pode definir " (aspas duplas) como o caractere de aspas e usar a cadeia de caracteres "Olá, mundo" na fonte. |
Não |
| nullValue | Um ou mais carateres utilizados para representar um valor nulo. | Um ou mais carateres. Os valores predefinidos são "\N" e "NULL" na leitura e "\N" na escrita. | Não |
| encodingName | Especifique o nome de codificação. | Um nome de codificação válido. Veja Encoding.EncodingName Property. Exemplo: windows-1250 ou shift_jis. O valor predefinido é UTF-8. | Não |
| firstRowAsHeader | Especifica se a primeira linha é considerada um cabeçalho. Para um conjunto de dados de entrada, o serviço lê a primeira linha como um cabeçalho. Para um conjunto de dados de saída, o serviço grava a primeira linha como um cabeçalho. Veja Cenários para utilizar firstRowAsHeader e skipLineCount em cenários de exemplo. |
True Falso (predefinição) |
Não |
| skipLineCount | Indica o número de linhas não vazias a serem ignoradas ao ler dados de arquivos de entrada. Se as propriedades skipLineCount e firstRowAsHeader forem especificadas simultaneamente, as linhas são ignoradas primeiro e, em seguida, as informações de cabeçalho são lidas a partir do ficheiro de entrada. Veja Cenários para utilizar firstRowAsHeader e skipLineCount em cenários de exemplo. |
Número inteiro | Não |
| treatEmptyAsNull | Especifica se as cadeias nulas ou vazias são tratadas como valor nulo durante a leitura de dados a partir de um ficheiro de entrada. |
Verdadeiro (predefinição) False |
Não |
Exemplo de TextFormat
Na seguinte definição JSON para um conjunto de dados, algumas das propriedades opcionais são especificadas.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
Para utilizar um escapeChar em vez de quoteChar, substitua a linha por quoteChar com o seguinte escapeChar:
"escapeChar": "$",
Cenários para utilizar firstRowAsHeader e skipLineCount
- Está a copiar de uma origem de não ficheiro para um ficheiro de texto e quer adicionar uma linha de cabeçalho com os metadados de esquema (por exemplo: esquema SQL). Especifique
firstRowAsHeadercomo verdadeiro no conjunto de dados de saída deste cenário. - Está a copiar de um ficheiro de texto que contém uma linha de cabeçalho para um sink de não ficheiro e quer remover essa linha. Especifique
firstRowAsHeadercomo verdadeiro no conjunto de dados de entrada. - Está a copiar de um ficheiro de texto e quer ignorar algumas linhas no início que não contêm dados nem informações de cabeçalho. Especifique
skipLineCountpara indicar o número de linhas a ignorar. Se o resto do ficheiro contiver uma linha de cabeçalho, também pode especificarfirstRowAsHeader. Se as propriedadesskipLineCountefirstRowAsHeaderforem especificadas simultaneamente, as linhas são ignoradas primeiro e, em seguida, as informações de cabeçalho são lidas a partir do ficheiro de entrada
Formato JSON (legado)
Nota
Conheça o novo modelo do artigo em formato JSON. As seguintes configurações no conjunto de dados de armazenamento de dados baseado em arquivo ainda são suportadas como estão para compatibilidade com versões anteriores. Sugere-se que você use o novo modelo no futuro.
Para importar/exportar um arquivo JSON no estado em que se encontra para/do Azure Cosmos DB, consulte a seção Importar/exportar documentos JSON no artigo Mover dados de/para o Azure Cosmos DB.
Se você quiser analisar os arquivos JSON ou gravar os dados no formato JSON, defina a typeformat propriedade na seção como JsonFormat. Também pode especificar as seguintes propriedades opcionais na secção format. Veja a secção Exemplo de JsonFormat sobre como configurar.
| Property | Descrição | Obrigatório |
|---|---|---|
| filePattern | Indica o padrão dos dados armazenados em cada ficheiro JSON. Os valores permitidos são setOfObjects e arrayOfObjects. O valor predefinido é setOfObjects. Veja a secção Padrões de ficheiro JSON para obter detalhes sobre estes padrões. | Não |
| jsonNodeReference | Se quiser iterar e extrair dados dos objetos dentro de um campo de matriz com o mesmo padrão, especifique o caminho JSON dessa matriz. Essa propriedade é suportada somente ao copiar dados de arquivos JSON. | Não |
| jsonPathDefinition | Especifique a expressão de caminho do JSON para cada mapeamento de colunas com um nome de coluna personalizado (começar com letra minúscula). Essa propriedade é suportada somente ao copiar dados de arquivos JSON, e você pode extrair dados de objeto ou matriz. Para os campos no objeto raiz, comece com a raiz $; para os campos dentro da matriz escolhida pela propriedade jsonNodeReference, comece a partir do elemento de matriz. Veja a secção Exemplo de JsonFormat sobre como configurar. |
Não |
| encodingName | Especifique o nome de codificação. Para obter a lista de nomes de codificação válidos, veja Propriedade Encoding.EncodingName. Exemplo: windows-1250 ou shift_jis. O valor predefinido é UTF-8. | Não |
| nestingSeparator | Caráter utilizado para separar níveis de aninhamento. O valor predefinido é “.” (ponto). | Não |
Nota
Para o caso de aplicação cruzada de dados na matriz em várias linhas (caso 1 -> amostra 2 em exemplos JsonFormat), você só pode optar por expandir uma única matriz usando a propriedade jsonNodeReference.
Padrões de ficheiro JSON
A atividade de cópia pode analisar os seguintes padrões de arquivos JSON:
Tipo I: setOfObjects
Cada ficheiro contém um único objeto ou múltiplos objetos delimitados por linha/concatenados. Quando esta opção está selecionada num conjunto de dados de saída, a atividade de cópia produz um único ficheiro JSON com cada objeto por linha (delimitados por linha).
Exemplo de JSON de objeto único
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }Exemplo de JSON delimitado por linha
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}Exemplo de JSON concatenado
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Tipo II: arrayOfObjects
Cada ficheiro contém uma matriz de objetos.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Exemplo de JsonFormat
Caso 1: Copiar dados de ficheiros JSON
Exemplo 1: extrair dados de objeto e matriz
Neste exemplo, espera-se que um objeto JSON de raiz mapeie para um registo individual no resultado de tabela. Se tiver um ficheiro JSON com o seguinte conteúdo:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
e quiser copiá-lo para uma tabela do SQL do Azure no formato seguinte mediante a extração de dados de objetos e da matriz:
| ID | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
O conjunto de dados de entrada com o tipo JsonFormat é definido da seguinte forma: (definição parcial com apenas as partes relevantes). Mais especificamente:
- A secção
structuredefine os nomes de colunas personalizados e o tipo de dados correspondente enquanto converte em dados tabulares. Esta secção é opcional, exceto se precisar de fazer o mapeamento de colunas. Para obter mais informações, consulte Mapear colunas do conjunto de dados de origem para colunas do conjunto de dados de destino. -
jsonPathDefinitionespecifica o caminho JSON para cada coluna que indica de onde extrair os dados. Para copiar dados da matriz, você pode usararray[x].propertypara extrair o valor da propriedade dada doxthobjeto ou pode usararray[*].propertypara localizar o valor de qualquer objeto que contenha essa propriedade.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
Exemplo 2: aplicar transversalmente múltiplos objetos com o mesmo padrão da matriz
Neste exemplo, espera-se transformar um objeto JSON de raiz em vários registos no resultado de tabela. Se tiver um ficheiro JSON com o seguinte conteúdo:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
e quiser copiá-lo para uma tabela SQL do Azure no seguinte formato, ao simplificar os dados no interior da matriz e ao cruzá-los com as informações de raiz comuns:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
O conjunto de dados de entrada com o tipo JsonFormat é definido da seguinte forma: (definição parcial com apenas as partes relevantes). Mais especificamente:
- A secção
structuredefine os nomes de colunas personalizados e o tipo de dados correspondente enquanto converte em dados tabulares. Esta secção é opcional, exceto se precisar de fazer o mapeamento de colunas. Para obter mais informações, consulte Mapear colunas do conjunto de dados de origem para colunas do conjunto de dados de destino. -
jsonNodeReferenceindica iterar e extrair dados dos objetos com o mesmo padrão em matrizorderlines. -
jsonPathDefinitionespecifica o caminho JSON para cada coluna que indica de onde extrair os dados. Neste exemplo,ordernumber, , ecityestão sob objeto raiz com caminho JSON começando com$., enquantoorder_pdeorder_pricesão definidos com caminho derivado do elemento array sem$.orderdate.
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
Tenha em atenção os seguintes pontos:
- Se o
structureejsonPathDefinitionnão estiverem definidos no conjunto de dados, a Atividade de cópia detetará o esquema do primeiro objeto e nivelará todo o objeto. - Se a entrada JSON tiver uma matriz, a Atividade de Cópia, por predefinição, converte todo o valor de matriz numa cadeia. Pode optar por extrair dados da cadeia através de
jsonNodeReferencee/oujsonPathDefinition, ou ignorá-la ao não especificá-la emjsonPathDefinition. - Se existirem nomes duplicados ao mesmo nível, a Atividade de Cópia escolhe o último.
- Os nomes das propriedades são sensíveis às maiúsculas e minúsculas. Duas propriedades que tenham o mesmo nome, mas maiúsculas/minúsculas diferentes, são tratadas como duas propriedades separadas.
Caso 2: Escrever dados no ficheiro JSON
Se você tiver a seguinte tabela no Banco de dados SQL:
| ID | order_date | order_price | ordenar por |
|---|---|---|---|
| 1 | 20170119 | 2000 | David |
| 2 | 20170120 | 3500 | José |
| 3 | 20170121 | 4000 | João |
e para cada registro, você espera gravar em um objeto JSON no seguinte formato:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
O conjunto de dados de saída com o tipo JsonFormat é definido da seguinte forma: (definição parcial com apenas as partes relevantes). Mais especificamente, structure a seção define os nomes de propriedade personalizados no arquivo nestingSeparator de destino (o padrão é ".") são usados para identificar a camada de aninhamento a partir do nome. Esta secção é opcional, exceto se quiser alterar o nome da propriedade para o equiparar ao nome da coluna de origem ou aninhar algumas das propriedades.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Formato Parquet (legado)
Nota
Conheça o novo modelo do artigo em formato Parquet. As seguintes configurações no conjunto de dados de armazenamento de dados baseado em arquivo ainda são suportadas como estão para compatibilidade com versões anteriores. Sugere-se que você use o novo modelo no futuro.
Se você quiser analisar os arquivos Parquet ou gravar os dados no formato Parquet, defina a formattype propriedade como ParquetFormat. Não precisa de especificar quaisquer propriedades na secção Formato no âmbito da secção typeProperties. Exemplo:
"format":
{
"type": "ParquetFormat"
}
Tenha em conta os seguintes pontos:
- Não há suporte para tipos de dados complexos (MAP, LIST).
- Não há suporte para espaço em branco no nome da coluna.
- O ficheiro Parquet tem as seguintes opções relacionadas com a compressão: NENHUM, SNAPPY, GZIP e LZO. O serviço suporta a leitura de dados do arquivo Parquet em qualquer um desses formatos compactados, exceto LZO - ele usa o codec de compressão nos metadados para ler os dados. No entanto, ao gravar em um arquivo Parquet, o serviço escolhe SNAPPY, que é o padrão para o formato Parquet. De momento, não existem opções para contornar este comportamento.
Importante
Para cópia habilitada pelo Self-hosted Integration Runtime, por exemplo, entre armazenamentos de dados locais e na nuvem, se você não estiver copiando arquivos do Parquet como estão, precisará instalar o JRE 8 de 64 bits (Java Runtime Environment) ou o OpenJDK em sua máquina IR. Veja o parágrafo a seguir com mais detalhes.
Para cópia executada em IR auto-hospedado com serialização/desserialização de arquivo Parquet, o serviço localiza o tempo de execução Java verificando, em primeiro lugar, o registro (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) para JRE, se não for encontrado, em segundo lugar, verificando a variável JAVA_HOME de sistema para OpenJDK.
- Para usar o JRE: O IR de 64 bits requer o JRE de 64 bits. Você pode encontrá-lo aqui.
- Para usar o OpenJDK: ele é suportado desde a versão 3.13 do IR. Empacote o jvm.dll com todos os outros assemblies necessários do OpenJDK na máquina IR auto-hospedada e defina a variável de ambiente do sistema JAVA_HOME de acordo.
Gorjeta
Se você copiar dados de/para o formato Parquet usando o Self-hosted Integration Runtime e clicar no erro "Ocorreu um erro ao invocar java, message: java.lang.OutOfMemoryError:Java heap space", você pode adicionar uma variável _JAVA_OPTIONS de ambiente na máquina que hospeda o IR auto-hospedado para ajustar o tamanho de heap min/max para a JVM para habilitar essa cópia e, em seguida, executar novamente o pipeline.
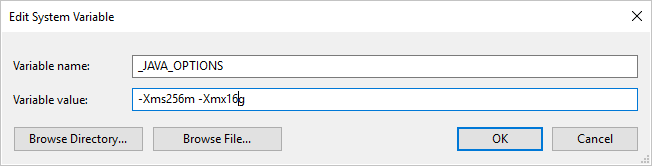
Exemplo: definir variável _JAVA_OPTIONS com valor -Xms256m -Xmx16g. O sinalizador Xms especifica o pool de alocação de memória inicial para uma Java Virtual Machine (JVM), enquanto Xmx especifica o pool máximo de alocação de memória. Isso significa que a JVM será iniciada com Xms quantidade de memória e poderá usar um máximo de Xmx quantidade de memória. Por padrão, o serviço usa min 64MB e max 1G.
Mapeamento de tipo de dados para arquivos Parquet
| Tipo de dados de serviço provisório | Parquet Tipo Primitivo | Tipo Original de Parquet (Desserialização) | Tipo Original de Parquet (Serialize) |
|---|---|---|---|
| Boolean | Boolean | N/A | N/A |
| SByte | Int32 | Int8 | Int8 |
| Byte | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/binário | UInt64 | Decimal |
| Única | Float | N/A | N/A |
| Duplo | Duplo | N/A | N/A |
| Decimal | Binário | Decimal | Decimal |
| String | Binário | UTF8 | UTF8 |
| DateTime | Int96 | N/A | N/A |
| TimeSpan | Int96 | N/A | N/A |
| DateTimeOffset | Int96 | N/A | N/A |
| Matriz de Bytes | Binário | N/A | N/A |
| GUID | Binário | UTF8 | UTF8 |
| Char | Binário | UTF8 | UTF8 |
| CharArray | Não suportado | N/A | N/A |
Formato ORC (legado)
Nota
Conheça o novo modelo do artigo em formato ORC. As seguintes configurações no conjunto de dados de armazenamento de dados baseado em arquivo ainda são suportadas como estão para compatibilidade com versões anteriores. Sugere-se que você use o novo modelo no futuro.
Se você quiser analisar os arquivos ORC ou gravar os dados no formato ORC, defina a formattype propriedade como OrcFormat. Não precisa de especificar quaisquer propriedades na secção Formato no âmbito da secção typeProperties. Exemplo:
"format":
{
"type": "OrcFormat"
}
Tenha em conta os seguintes pontos:
- Não há suporte para tipos de dados complexos (STRUCT, MAP, LIST, UNION).
- Não há suporte para espaço em branco no nome da coluna.
- O ficheiro ORC tem três opções relacionadas com a compressão: NENHUM, ZLIB, SNAPPY. O serviço suporta a leitura de dados do arquivo ORC em qualquer um desses formatos compactados. Utiliza o codec de compressão existente nos metadados para ler os dados. No entanto, ao gravar em um arquivo ORC, o serviço escolhe ZLIB, que é o padrão para ORC. De momento, não existem opções para contornar este comportamento.
Importante
Para cópia habilitada pelo Self-hosted Integration Runtime, por exemplo, entre armazenamentos de dados locais e na nuvem, se você não estiver copiando arquivos ORC como estão, precisará instalar o JRE 8 de 64 bits (Java Runtime Environment) ou o OpenJDK em sua máquina IR. Veja o parágrafo a seguir com mais detalhes.
Para cópia executada em IR auto-hospedado com serialização/desserialização de arquivo ORC, o serviço localiza o tempo de execução Java verificando primeiro o registro (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) para JRE, se não for encontrado, em segundo lugar verificando a variável JAVA_HOME de sistema para OpenJDK.
- Para usar o JRE: O IR de 64 bits requer o JRE de 64 bits. Você pode encontrá-lo aqui.
- Para usar o OpenJDK: ele é suportado desde a versão 3.13 do IR. Empacote o jvm.dll com todos os outros assemblies necessários do OpenJDK na máquina IR auto-hospedada e defina a variável de ambiente do sistema JAVA_HOME de acordo.
Mapeamento de tipo de dados para arquivos ORC
| Tipo de dados de serviço provisório | Tipos de ORC |
|---|---|
| Boolean | Boolean |
| SByte | Byte |
| Byte | Curto |
| Int16 | Curto |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | Longo |
| Int64 | Longo |
| UInt64 | String |
| Única | Float |
| Duplo | Duplo |
| Decimal | Decimal |
| String | String |
| DateTime | Carimbo de Data/Hora |
| DateTimeOffset | Carimbo de Data/Hora |
| TimeSpan | Carimbo de Data/Hora |
| Matriz de Bytes | Binário |
| GUID | String |
| Char | Char(1) |
Formato AVRO (legado)
Nota
Conheça o novo modelo do artigo em formato Avro. As seguintes configurações no conjunto de dados de armazenamento de dados baseado em arquivo ainda são suportadas como estão para compatibilidade com versões anteriores. Sugere-se que você use o novo modelo no futuro.
Se você quiser analisar os arquivos Avro ou gravar os dados no formato Avro, defina a formattype propriedade como AvroFormat. Não precisa de especificar quaisquer propriedades na secção Formato no âmbito da secção typeProperties. Exemplo:
"format":
{
"type": "AvroFormat",
}
Para usar o formato Avro em uma tabela do Hive, você pode consultar o tutorial do Apache Hive.
Tenha em conta os seguintes pontos:
- Não há suporte para tipos de dados complexos (registros, enums, matrizes, mapas, uniões e fixos).
Suporte de compressão (legado)
O serviço suporta compactar/descompactar dados durante a cópia. Quando você especifica compression a propriedade em um conjunto de dados de entrada, a atividade de cópia lê os dados compactados da fonte e os descompacta, e quando você especifica a propriedade em um conjunto de dados de saída, a atividade de cópia compacta e grava dados no coletor. Aqui estão alguns cenários de exemplo:
- Leia dados compactados GZIP de um blob do Azure, descompacte-os e grave dados de resultados no Banco de Dados SQL do Azure. Você define o conjunto de dados de Blob do Azure de entrada com a
compressiontypepropriedade como GZIP. - Leia dados de um arquivo de texto simples do Sistema de Arquivos local, compacte-o usando o formato GZip e grave os dados compactados em um blob do Azure. Você define um conjunto de dados de Blob do Azure de saída com a
compressiontypepropriedade como GZip. - Leia .zip arquivo do servidor FTP, descompacte-o para obter os arquivos internos e coloque esses arquivos no Repositório Azure Data Lake. Você define um conjunto de dados FTP de entrada com a
compressiontypepropriedade como ZipDeflate. - Leia um dado compactado com GZIP de um blob do Azure, descompacte-o, compacte-o usando BZIP2 e grave dados de resultado em um blob do Azure. Você define o conjunto de dados de Blob do Azure de entrada com
compressiontypedefinido como GZIP e o conjunto de dados de saída comcompressiontypedefinido como BZIP2.
Para especificar a compactação para um conjunto de dados, use a propriedade compression no JSON do conjunto de dados como no exemplo a seguir:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
A seção de compressão tem duas propriedades:
Tipo: o codec de compressão, que pode ser GZIP, Deflate, BZIP2 ou ZipDeflate. Observe que, ao usar a atividade de cópia para descompactar o(s) arquivo(s) ZipDeflate e gravar no armazenamento de dados do coletor baseado em arquivo, os arquivos serão extraídos para a pasta:
<path specified in dataset>/<folder named as source zip file>/.Nível: a taxa de compressão, que pode ser Ótima ou Mais Rápida.
Mais rápido: A operação de compressão deve ser concluída o mais rápido possível, mesmo que o arquivo resultante não seja compactado de forma ideal.
Ideal: A operação de compressão deve ser compactada de forma ideal, mesmo que a operação demore mais tempo para ser concluída.
Para obter mais informações, consulte o tópico Nível de compactação.
Nota
As configurações de compactação não são suportadas para dados no AvroFormat, OrcFormat ou ParquetFormat. Ao ler arquivos nesses formatos, o serviço deteta e usa o codec de compactação nos metadados. Ao gravar em arquivos nesses formatos, o serviço escolhe o codec de compactação padrão para esse formato. Por exemplo, ZLIB para OrcFormat e SNAPPY para ParquetFormat.
Tipos de ficheiro e formatos de compressão não suportados
Você pode usar os recursos de extensibilidade para transformar arquivos que não são suportados. Duas opções incluem o Azure Functions e tarefas personalizadas usando o Azure Batch.
Você pode ver um exemplo que usa uma função do Azure para extrair o conteúdo de um arquivo tar. Para obter mais informações, consulte Atividade do Azure Functions.
Você também pode criar essa funcionalidade usando uma atividade dotnet personalizada. Mais informações estão disponíveis aqui
Conteúdos relacionados
Aprenda os formatos de ficheiro e compressões suportados mais recentes em Formatos de ficheiro e compressões suportados.