Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
A atividade Jar do Azure Databricks num pipeline executa um Spark Jar no teu cluster do Azure Databricks. Este artigo baseia-se no artigo de atividades de transformação de dados, que apresenta uma visão geral da transformação de dados e das atividades de transformação suportadas. Azure Databricks é uma plataforma gerida para executar o Apache Spark.
Para uma introdução e demonstração de onze minutos desta funcionalidade, veja o seguinte vídeo:
Adicione uma atividade Jar para Azure Databricks a um pipeline com interface gráfica de usuário.
Para usar uma atividade Jar para Azure Databricks num pipeline, complete os seguintes passos:
Pesquise por Jar no painel de Atividades do pipeline e arraste uma atividade Jar para a tela do pipeline.
Selecione a nova atividade Jar na tela, se ainda não estiver selecionada.
Selecione o separador Azure Databricks para selecionar ou criar um novo serviço ligado Azure Databricks que execute a atividade Jar.
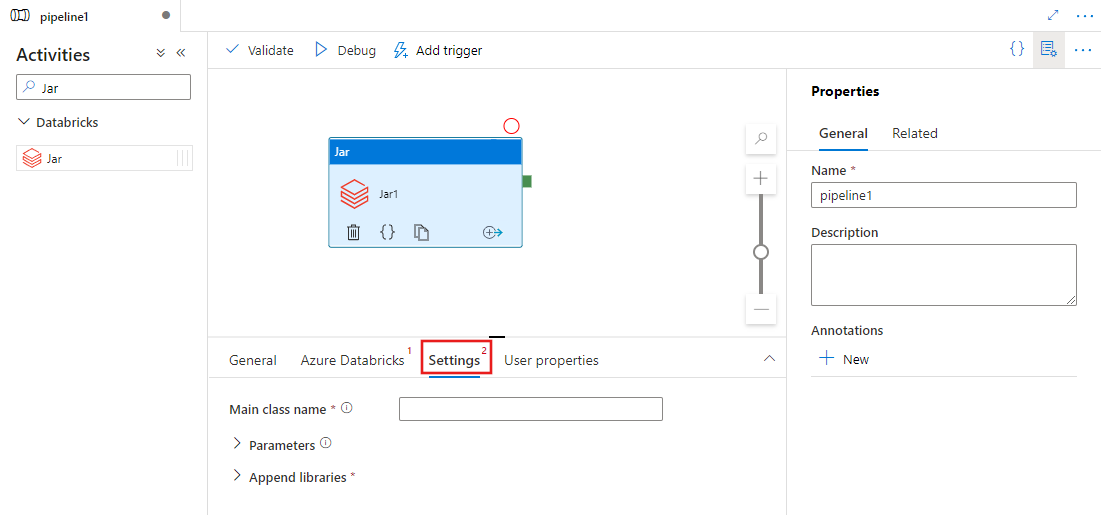
Selecione o separador Settings e especifique um nome de classe a ser executado no Azure Databricks, parâmetros opcionais a serem passados para o Jar e bibliotecas a instalar no cluster para executar o trabalho.
Definição de atividade do Databricks Jar
Aqui está a definição JSON de exemplo de uma atividade Databricks Jar:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Propriedades de atividade do Databricks Jar
A tabela a seguir descreve as propriedades JSON usadas na definição JSON:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| nome | Nome da atividade no pipeline. | Sim |
| descrição | Texto que descreve o que a atividade faz. | Não |
| tipo | Para Databricks Jar Activity, o tipo de atividade é DatabricksSparkJar. | Sim |
| nome do serviço ligado | Nome do Serviço Vinculado Databricks no qual a atividade Jar é executada. Para saber mais sobre esse serviço vinculado, consulte o artigo Serviços vinculados de computação. | Sim |
| mainClassName | O nome completo da classe que contém o método principal a ser executado. Essa classe deve estar contida em um JAR fornecido como uma biblioteca. Um arquivo JAR pode conter várias classes. Cada uma das classes pode conter um método principal. | Sim |
| parâmetros | Parâmetros que serão passados para o método principal. Esta propriedade é uma matriz de cadeias de caracteres. | Não |
| bibliotecas | Uma lista de bibliotecas a serem instaladas no cluster que executará o trabalho. Pode ser uma matriz de <string, objeto> | Sim (pelo menos um contendo o método mainClassName) |
Nota
Problema conhecido - Ao usar o mesmo cluster interativo para executar atividades simultâneas do Databricks Jar (sem reinicialização do cluster), há um problema conhecido no Databricks, onde os parâmetros da 1ª atividade também serão usados pelas seguintes atividades. O que resulta em parâmetros incorretos serem passados para os trabalhos subsequentes. Para atenuar isso, use um cluster de tarefas.
Bibliotecas suportadas para atividades do Databricks
Na definição de atividade Databricks anterior, você especificou estes tipos de biblioteca: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Para obter mais informações, consulte a documentação do Databricks para tipos de biblioteca.
Como carregar uma biblioteca no Databricks
Você pode usar a interface do usuário da área de trabalho:
Usar a interface de utilizador do espaço de trabalho Databricks
Para obter o caminho dbfs da biblioteca adicionada usando a interface do usuário, você pode usar a CLI do Databricks.
Normalmente, as bibliotecas Jar são armazenadas em dbfs:/FileStore/jars ao usar a interface do usuário. Você pode listar tudo através da CLI: databricks fs ls dbfs:/FileStore/job-jars
Ou você pode usar a CLI do Databricks:
Usar CLI do Databricks (etapas de instalação)
Como exemplo, para copiar um JAR para dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
Conteúdos relacionados
Para uma introdução e demonstração de onze minutos desta funcionalidade, veja o vídeo.