Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
A Azure Databricks Notebook Activity num pipeline executa um notebook Databricks no seu espaço de trabalho Azure Databricks. Este artigo baseia-se no artigo de atividades de transformação de dados, que apresenta uma visão geral da transformação de dados e das atividades de transformação suportadas. Azure Databricks é uma plataforma gerida para executar o Apache Spark.
Pode criar um caderno Databricks com um template ARM usando JSON, ou diretamente através da interface do Azure Data Factory Studio. Para uma explicação passo a passo sobre como criar uma atividade de caderno Databricks usando a interface de utilizador, consulte o tutorial Execute um caderno Databricks com a Atividade de Databricks em Azure Data Factory.
Adicionar uma atividade do Notebook para Azure Databricks a um pipeline com UI
Para usar uma atividade de Notebook do Azure Databricks num fluxo de trabalho, complete os seguintes passos:
Pesquise Notebook no painel de Atividades do pipeline e arraste uma atividade Notebook para a interface do pipeline.
Selecione a nova atividade do Bloco de Anotações na tela se ela ainda não estiver selecionada.
Selecione o separador Azure Databricks para selecionar ou criar um novo serviço associado Azure Databricks para executar a atividade de Notebook.

Selecione o separador Settings e especifique o caminho do caderno a ser executado no Azure Databricks, parâmetros base opcionais a serem passados para o caderno e quaisquer outras bibliotecas a instalar no cluster para executar o trabalho.
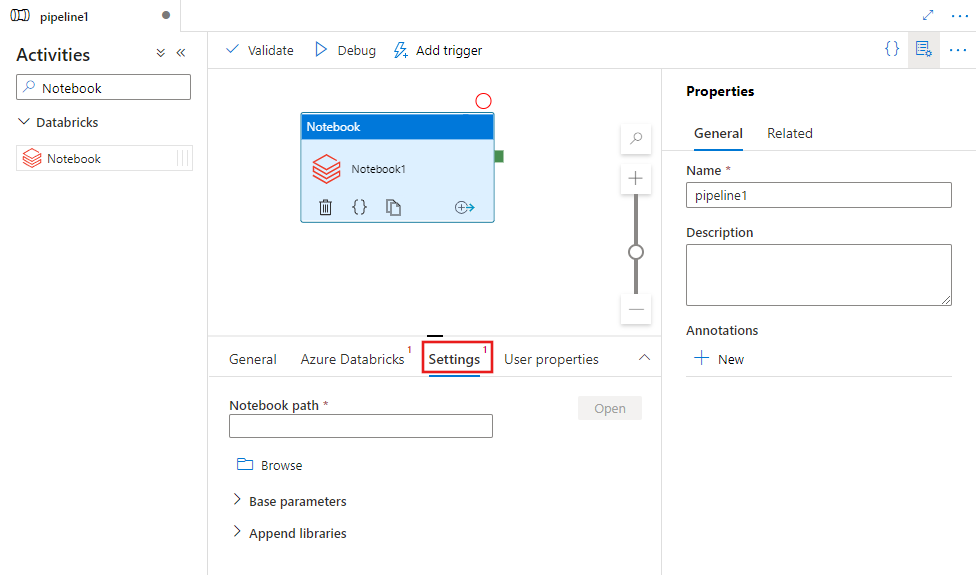
Definição de atividade do Databricks Notebook
Aqui está a definição JSON de exemplo de uma atividade de bloco de anotações Databricks:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Propriedades de atividade do Databricks Notebook
A tabela a seguir descreve as propriedades JSON usadas na definição JSON:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| nome | Nome da atividade no pipeline. | Sim |
| descrição | Texto que descreve o que a atividade faz. | Não |
| tipo | Para Databricks Notebook Activity, o tipo de atividade é DatabricksNotebook. | Sim |
| nome do serviço ligado | Nome do Serviço Ligado Databricks no qual o notebook Databricks é operado. Para saber mais sobre esse serviço vinculado, consulte o artigo Serviços vinculados de computação. | Sim |
| notebookPath | O caminho absoluto do notebook a ser executado no Espaço de Trabalho Databricks. Este caminho deve começar com uma barra. | Sim |
| baseParameters | Uma matriz de pares Chave-Valor. Os parâmetros de base podem ser usados para cada atividade executada. Se o bloco de notas utilizar um parâmetro não especificado, será utilizado o valor predefinido do bloco de notas. Encontre mais informações sobre parâmetros em Databricks Notebooks. | Não |
| bibliotecas | Uma lista de bibliotecas a serem instaladas no cluster que executará o trabalho. Pode ser uma matriz de <string, objeto>. | Não |
Bibliotecas suportadas para atividades do Databricks
Na definição de atividade do Databricks acima, você especifica estes tipos de biblioteca: jar, egg, whl, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Para obter mais informações, consulte a documentação do Databricks para tipos de biblioteca.
Passando parâmetros entre notebooks e pipelines
Você pode passar parâmetros para blocos de anotações usando a propriedade baseParameters na atividade databricks.
Em certos casos, pode ser necessário repassar certos valores do notebook de volta para o serviço, que podem ser usados para controlar o fluxo (verificações condicionais) no serviço ou ser consumidos por atividades a jusante (o limite de tamanho é de 2 MB).
No seu notebook, pode chamar dbutils.notebook.exit("returnValue") e o "returnValue" correspondente será retornado para o serviço.
Você pode consumir a saída no serviço usando expressões como
@{activity('databricks notebook activity name').output.runOutput}.Importante
Se você estiver passando o objeto JSON, poderá recuperar valores anexando nomes de propriedade. Exemplo:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Como carregar uma biblioteca no Databricks
Você pode usar a interface do usuário da área de trabalho:
Usar a interface de utilizador do espaço de trabalho Databricks
Para obter o caminho dbfs da biblioteca adicionada usando a interface do usuário, você pode usar a CLI do Databricks.
Normalmente, as bibliotecas Jar são armazenadas em dbfs:/FileStore/jars ao usar a interface do usuário. Você pode listar tudo através da CLI: databricks fs ls dbfs:/FileStore/job-jars
Ou você pode usar a CLI do Databricks:
Usar CLI do Databricks (etapas de instalação)
Como exemplo, para copiar um JAR para dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar