Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
A atividade HDInsight MapReduce num pipeline de Azure Data Factory ou Synapse Analytics invoca o programa MapReduce no seu próprio ou em cluster HDInsight on-demand. Este artigo baseia-se no artigo de atividades de transformação de dados, que apresenta uma visão geral da transformação de dados e das atividades de transformação suportadas.
Para saber mais, leia os artigos introdutórios para Azure Data Factory e Synapse Analytics, e faça o tutorial: Tutorial: transformar dados antes de ler este artigo.
Consulte Pig e Hive para obter detalhes sobre como executar scripts Pig/Hive em um cluster HDInsight a partir de um pipeline usando as atividades do Pig e do Hive do HDInsight.
Adicionar uma atividade MapReduce do HDInsight a um pipeline com a interface de utilizador
Para usar uma atividade MapReduce do HDInsight em um pipeline, conclua as seguintes etapas:
Pesquise por MapReduce no painel Atividades do pipeline e arraste uma atividade MapReduce para a tela do pipeline.
Selecione a nova atividade MapReduce na tela se ainda não estiver selecionada.
Selecione a guia HDI Cluster para selecionar ou criar um novo serviço ligado a um cluster HDInsight que será usado para executar a atividade MapReduce.
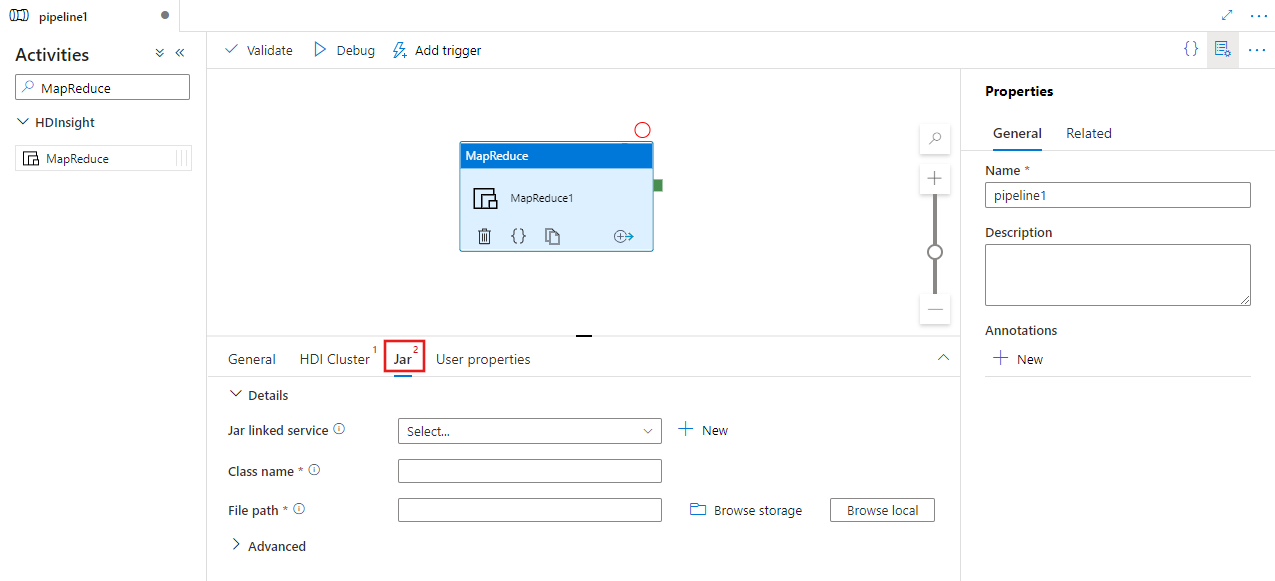
Selecione o separador Jar para selecionar ou criar um novo serviço ligado ao Jar a uma conta Azure Storage que irá alojar o seu script. Especifique um nome de classe a ser executado lá e um caminho de arquivo dentro do local de armazenamento. Você também pode configurar detalhes avançados, incluindo a localização das bibliotecas Jar, configuração de depuração e argumentos e parâmetros a serem passados para o script.
Sintaxe
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Detalhes da sintaxe
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| nome | Nome da atividade | Sim |
| descrição | Texto que descreve para que serve a atividade | Não |
| tipo | Para MapReduce Activity, o tipo de atividade é HDinsightMapReduce | Sim |
| nome do serviço ligado | Referência ao cluster HDInsight registrado como um serviço vinculado. Para saber mais sobre esse serviço vinculado, consulte o artigo Serviços vinculados de computação. | Sim |
| className | Nome da classe a ser executada | Sim |
| jarLinkedService | Referência a um Azure Storage Linked Service usado para armazenar os ficheiros Jar. Apenas os serviços ligados Azure Blob Storage e ADLS Gen2 são suportados aqui. Se não especificar este Serviço Ligado, é utilizado o Serviço Ligado do Azure Storage definido no Serviço Ligado HDInsight. | Não |
| jarFilePath | Forneça o caminho para os ficheiros Jar armazenados no Azure Storage referido pelo jarLinkedService. O nome do arquivo diferencia maiúsculas de minúsculas. | Sim |
| Jarlibs | Matriz de cadeias de caracteres do caminho para os ficheiros da biblioteca Jar referenciados pelo trabalho armazenado no Azure Storage definido em jarLinkedService. O nome do arquivo diferencia maiúsculas de minúsculas. | Não |
| getDebugInfo | Especifica quando os ficheiros de registo são copiados para o Azure Storage usado pelo cluster HDInsight (ou) especificado pelo jarLinkedService. Valores permitidos: Nenhum, Sempre ou Falha. Valor padrão: Nenhum. | Não |
| Argumentos | Especifica uma matriz de argumentos para um trabalho Hadoop. Os argumentos são passados como argumentos de linha de comando para cada tarefa. | Não |
| define | Especifique parâmetros como pares chave/valor para referência dentro do script Hive. | Não |
Exemplo
Você pode usar a Atividade MapReduce do HDInsight para executar qualquer arquivo jar do MapReduce em um cluster HDInsight. No exemplo de definição JSON de um pipeline a seguir, a Atividade do HDInsight é configurada para executar um arquivo JAR Mahout.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
Você pode especificar quaisquer argumentos para o programa MapReduce na seção argumentos . Durante a execução, aparecem alguns argumentos extras (por exemplo: mapreduce.job.tags) do framework MapReduce. Para diferenciar seus argumentos com os argumentos MapReduce, considere usar a opção e o valor como argumentos, conforme mostrado no exemplo a seguir (-s,--input,--output etc., são opções imediatamente seguidas por seus valores).
Conteúdos relacionados
Consulte os seguintes artigos que explicam como transformar dados de outras maneiras: