Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Muitas vezes, ao processar dados para trabalhos de ETL, você precisará alterar os nomes das colunas antes de escrever os resultados. Às vezes, isso é necessário para alinhar os nomes das colunas a um esquema de destino bem conhecido. Outras vezes, talvez seja necessário definir nomes de colunas em tempo de execução com base em esquemas em evolução. Neste tutorial, você aprenderá a usar fluxos de dados para definir nomes de colunas para seus arquivos de destino e tabelas de banco de dados dinamicamente usando arquivos e parâmetros de configuração externos.
Se você é novo no Azure Data Factory, consulte Introdução ao Azure Data Factory.
Pré-requisitos
- Subscrição do Azure. Se você não tiver uma assinatura do Azure, crie uma conta gratuita do Azure antes de começar.
- Conta de armazenamento do Azure. Você usa o armazenamento ADLS como fonte e destino de dados. Se você não tiver uma conta de armazenamento, consulte Criar uma conta de armazenamento do Azure para conhecer as etapas para criar uma.
Criar uma fábrica de dados
Nesta etapa, você cria um data factory e abre o Data Factory UX para criar um pipeline no data factory.
- Abra o Microsoft Edge ou o Google Chrome. Atualmente, a interface do usuário do Data Factory é suportada apenas nos navegadores Microsoft Edge e Google Chrome.
- No menu à esquerda, selecione Criar um recurso>Integration>Data Factory
- Na página Novo Data Factory, em Nome, insira ADFTutorialDataFactory
- Selecione a assinatura do Azure na qual você deseja criar o data factory.
- Para o Grupo de Recursos, execute uma das seguintes etapas:
- Selecione Usar existente e selecione um grupo de recursos existente na lista suspensa.
- Selecione Criar novo e insira o nome de um grupo de recursos. Para saber mais sobre grupos de recursos, consulte Usar grupos de recursos para gerenciar seus recursos do Azure.
- Em Versão, selecione V2.
- Em Local, selecione um local para o data factory. Só aparecem na lista pendente as localizações que são suportadas. Os armazenamentos de dados (por exemplo, Armazenamento do Azure e Banco de Dados SQL) e os cálculos (por exemplo, Azure HDInsight) usados pelo data factory podem estar em outras regiões.
- Selecione Criar.
- Após a conclusão da criação, você verá o aviso na Central de notificações. Selecione Ir para o recurso para navegar até a página do Data factory.
- Selecione Author & Monitor para iniciar a interface do usuário do Data Factory em uma guia separada.
Criar um pipeline com uma atividade de fluxo de dados
Nesta etapa, você criará um pipeline que contém uma atividade de fluxo de dados.
Na página inicial do ADF, selecione Criar pipeline.
Na guia Geral da pipeline, digite DeltaLake para Nome da pipeline.
Na barra superior do ambiente de fábrica, ative o interruptor de depuração do Fluxo de Dados. O modo de depuração permite testes interativos da lógica de transformação em um cluster Spark ao vivo. Os clusters de Fluxo de Dados levam de 5 a 7 minutos para aquecer e os usuários são recomendados a ativar a depuração primeiro se planejarem fazer o desenvolvimento do Fluxo de Dados. Para obter mais informações, consulte Modo de depuração.
No painel Atividades , expanda o acordeão Mover e Transformar . Arraste e solte a atividade Fluxo de Dados do painel para a tela do pipeline.
No pop-up Adicionando fluxo de dados , selecione Criar novo fluxo de dados e nomeie seu fluxo de dados como DynaCols. Selecione Concluir quando terminar.
Criar mapeamento dinâmico de colunas em fluxos de dados
Para este tutorial, vamos usar um arquivo de classificação de filmes de exemplo e renomear alguns dos campos na origem para um novo conjunto de colunas de destino que podem mudar ao longo do tempo. Os conjuntos de dados que você criará abaixo devem apontar para este arquivo CSV de filmes em sua conta de armazenamento Blob Storage ou ADLS Gen2. Baixe o arquivo de filmes aqui e armazene o arquivo em sua conta de armazenamento do Azure.
Objetivos do tutorial
Você aprenderá a definir dinamicamente nomes de colunas usando um fluxo de dados
- Crie um conjunto de dados de origem para o arquivo CSV de filmes.
- Crie um conjunto de dados de pesquisa para um arquivo de configuração JSON de mapeamento de campo.
- Converta as colunas da origem para os nomes das colunas de destino.
Iniciar a partir de uma tela de fluxo de dados em branco
Primeiro, vamos configurar o ambiente de fluxo de dados para cada um dos mecanismos descritos abaixo para dados de aterrissagem no ADLS Gen2.
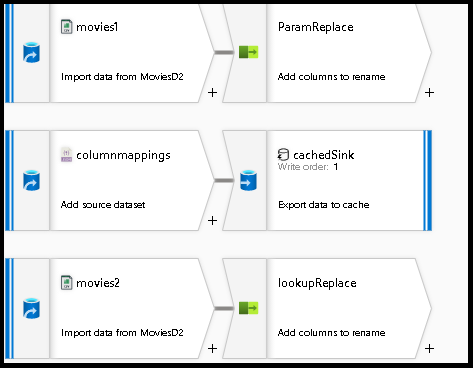
Selecione a transformação de origem e chame-a
movies1de .Selecione o novo botão ao lado do conjunto de dados no painel inferior.
Escolha Blob ou ADLS Gen2, dependendo de onde você armazenou o arquivo moviesDB.csv acima.
Adicione uma segunda fonte, que usaremos para originar o arquivo JSON de configuração para procurar mapeamentos de campo.
Chame isso de
columnmappings.Para o conjunto de dados, aponte para um novo arquivo JSON que armazenará uma configuração para mapeamento de coluna. Você pode colar o no arquivo JSON para este exemplo de tutorial:
[ {"prevcolumn":"title","newcolumn":"movietitle"}, {"prevcolumn":"year","newcolumn":"releaseyear"} ]Defina esta configuração de origem como
array of documents.Adicione uma terceira fonte e chame-a
movies2de . Configure isso exatamente da mesma forma quemovies1o .
Mapeamento de coluna parametrizado
Neste primeiro cenário, você definirá nomes de colunas de saída em seu fluxo de dados definindo o mapeamento de colunas com base na correspondência de campos de entrada com um parâmetro que é uma matriz de cadeia de caracteres de colunas e corresponderá a cada índice de matriz com a posição ordinal da coluna de entrada. Ao executar esse fluxo de dados de um pipeline, você poderá definir nomes de colunas diferentes em cada execução de pipeline enviando esse parâmetro de matriz de cadeia de caracteres para a atividade de fluxo de dados.
Volte para o designer de fluxo de dados e edite o fluxo de dados criado acima.
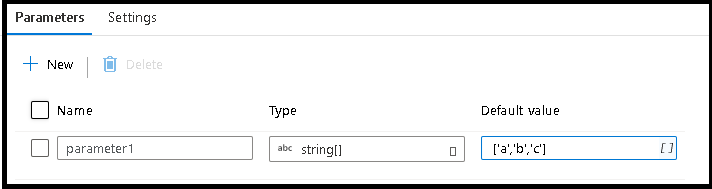
Selecione na guia de parâmetros
Crie um novo parâmetro e escolha o tipo de dados de matriz de cadeia de caracteres
Para o valor padrão, insira
['a','b','c']Use a fonte superior
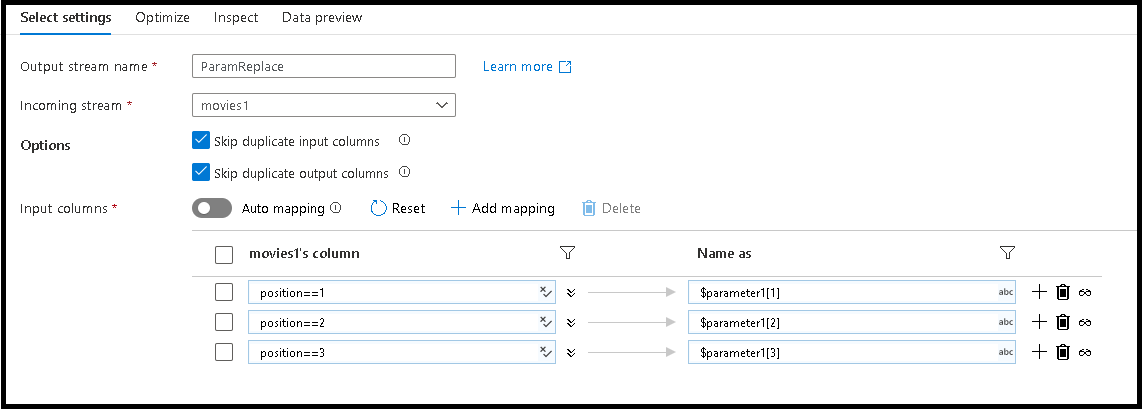
movies1para modificar os nomes das colunas para mapear para esses valores de matrizAdicione uma transformação Selecionar. A transformação Select será usada para mapear colunas de entrada para novos nomes de colunas para saída.
Vamos alterar os três primeiros nomes de coluna para os novos nomes definidos no parâmetro
Para fazer isso, adicione três entradas de mapeamento baseadas em regras no painel inferior
Para a primeira coluna, a regra de correspondência será
position==1e o nome será$parameter1[1]Siga o mesmo padrão para as colunas 2 e 3
Selecione nas guias Inspecionar e Visualizar dados da transformação Selecionar para exibir os novos valores
(a,b,c)de nome de coluna substituir os nomes originais das colunas de filmes, títulos, gêneros
Criar uma pesquisa em cache de mapeamentos de colunas externas
Em seguida, criaremos um coletor em cache para uma pesquisa posterior. O cache lerá um arquivo de configuração JSON externo que pode ser usado para renomear colunas dinamicamente em cada execução de pipeline do seu fluxo de dados.
- Volte para o designer de fluxo de dados e edite o fluxo de dados criado acima. Adicione uma transformação Sink à
columnmappingsorigem. - Defina o tipo de coletor como
Cache. - Em Configurações, escolha
prevcolumncomo a coluna principal.
Procurar nomes de colunas do coletor armazenado em cache
Agora que você armazenou o conteúdo do arquivo de configuração na memória, pode mapear dinamicamente os nomes das colunas de entrada para novos nomes de colunas de saída.
- Volte para o designer de fluxo de dados e edite o fluxo de dados criado acima. Selecione a transformação de
movies2origem. - Adicione uma transformação Selecionar. Desta vez, usaremos a transformação Select para renomear nomes de colunas com base no nome de destino no arquivo de configuração JSON que está sendo armazenado no coletor armazenado em cache.
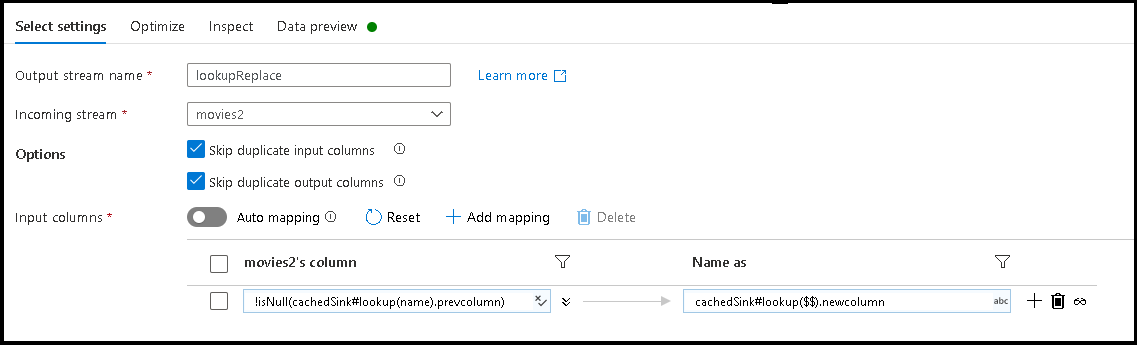
- Adicione um mapeamento baseado em regras. Para a Condição de correspondência, use esta fórmula:
!isNull(cachedSink#lookup(name).prevcolumn). - Para o nome da coluna de saída, use esta fórmula:
cachedSink#lookup($$).newcolumn. - O que fizemos foi encontrar todos os nomes de coluna que correspondem à
prevcolumnpropriedade do arquivo de configuração JSON externo e renomear cada correspondência para o novonewcolumnnome. - Selecione nas guias Visualização de dados e Inspecionar na transformação Selecionar e agora você verá os novos nomes de coluna do arquivo de mapeamento externo.
Conteúdos relacionados
- O pipeline concluído deste tutorial pode ser descarregado aqui
- Saiba mais sobre coletores de fluxo de dados.