Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
Neste tutorial, crias um Azure Data Factory com um pipeline que carrega dados delta de uma tabela no Azure SQL Database para o Azure Blob storage.
Vai executar os seguintes passos neste tutorial:
- Preparar o repositório de dados para armazenar o valor de marca d'água.
- Criar uma fábrica de dados.
- Criar serviços ligados.
- Crie conjuntos de dados de origem, de sumidouro e de marca d'água.
- Criar um pipeline.
- Executar o pipeline.
- Monitorizar a execução do pipeline.
- Rever resultados
- Adicionar mais dados à origem.
- Executar o pipeline novamente.
- Monitorizar a segunda execução do pipeline
- Rever os resultados da segunda execução
Descrição geral
Eis o diagrama de nível elevado da solução:

Eis os passos importantes para criar esta solução:
Selecione a coluna de marca d'água. Selecione uma coluna no arquivo de dados de origem, que pode ser utilizada para dividir os registos novos ou atualizados para cada execução. Normalmente, os dados nesta coluna selecionada (por exemplo, last_modify_time ou ID) continuam a aumentar quando as linhas são criadas ou atualizadas. O valor máximo nesta coluna é utilizado como limite de tamanho.
Prepare um armazenamento de dados para armazenar o valor da marca d'água. Neste tutorial, vai armazenar o valor de marca d'água numa base de dados SQL.
Crie um pipeline com o seguinte fluxo de trabalho:
O pipeline nesta solução tem as seguintes atividades:
- Crie duas atividades de Pesquisa. Utilize a primeira atividade Lookup para obter o último valor de marcador. Use a segunda atividade de pesquisa para recuperar o novo valor de marca d'água. Estes valores de marca de água são passados para a atividade de cópia.
- Crie uma atividade de cópia que copie linhas do armazenamento de dados de origem, com o valor da coluna de "watermark" maior do que o valor anterior e menor do que o novo valor. Em seguida, copia os dados delta do arquivo de dados de origem para um armazenamento de Blobs como um ficheiro novo.
- Crie uma atividade StoredProcedure, que atualiza o valor de marca d'água do pipeline que vai ser executado da próxima vez.
Se não tiver uma subscrição Azure, crie uma conta free antes de começar.
Pré-requisitos
- Azure SQL Database. Vai utilizar a base de dados como o arquivo de dados de origem. Se não tiver uma base de dados em Azure SQL Database, veja Criar uma base de dados em Azure SQL Database para os passos para criar uma.
- Azure Storage. Vai utilizar o armazenamento blob como armazenamento de destino. Se você não tiver uma conta de armazenamento, consulte Criar uma conta de armazenamento para conhecer as etapas para criar uma. Crie um contentor com o nome adftutorial.
Criar uma tabela de origem de dados na base de dados SQL
Abre o SQL Server Management Studio. No Gerenciador de Servidores, clique com o botão direito do mouse no banco de dados e escolha Nova Consulta.
Execute o seguinte comando SQL na sua base de dados SQL para criar uma tabela com o nome
data_source_tablecomo o repositório de fonte de dados.create table data_source_table ( PersonID int, Name varchar(255), LastModifytime datetime ); INSERT INTO data_source_table (PersonID, Name, LastModifytime) VALUES (1, 'aaaa','9/1/2017 12:56:00 AM'), (2, 'bbbb','9/2/2017 5:23:00 AM'), (3, 'cccc','9/3/2017 2:36:00 AM'), (4, 'dddd','9/4/2017 3:21:00 AM'), (5, 'eeee','9/5/2017 8:06:00 AM');Neste tutorial, vai utilizar LastModifytime como a coluna de limite de tamanho. Os dados no arquivo da origem de dados são apresentados na tabela seguinte:
PersonID | Name | LastModifytime -------- | ---- | -------------- 1 | aaaa | 2017-09-01 00:56:00.000 2 | bbbb | 2017-09-02 05:23:00.000 3 | cccc | 2017-09-03 02:36:00.000 4 | dddd | 2017-09-04 03:21:00.000 5 | eeee | 2017-09-05 08:06:00.000
Criar outra tabela na base de dados SQL para armazenar o valor de limite superior de tamanho
Execute o comando SQL seguinte na base de dados SQL para criar uma tabela com o nome
watermarktablee armazenar o valor de limite de tamanho:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Defina o valor predefinido do high watermark com o nome da tabela do armazenamento de dados de origem. Neste tutorial, o nome da tabela é data_source_table.
INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')Revise os dados na tabela
watermarktable.Select * from watermarktableSaída:
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
Criar um procedimento armazenado na base de dados SQL
Execute o comando seguinte para criar um procedimento armazenado na base de dados SQL:
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Criar uma fábrica de dados
Inicie o navegador web Microsoft Edge ou Google Chrome. Atualmente, o Data Factory UI é suportado apenas nos navegadores Microsoft Edge e Google Chrome.
No menu superior, selecione Criar um recurso>Analytics>Data Factory :
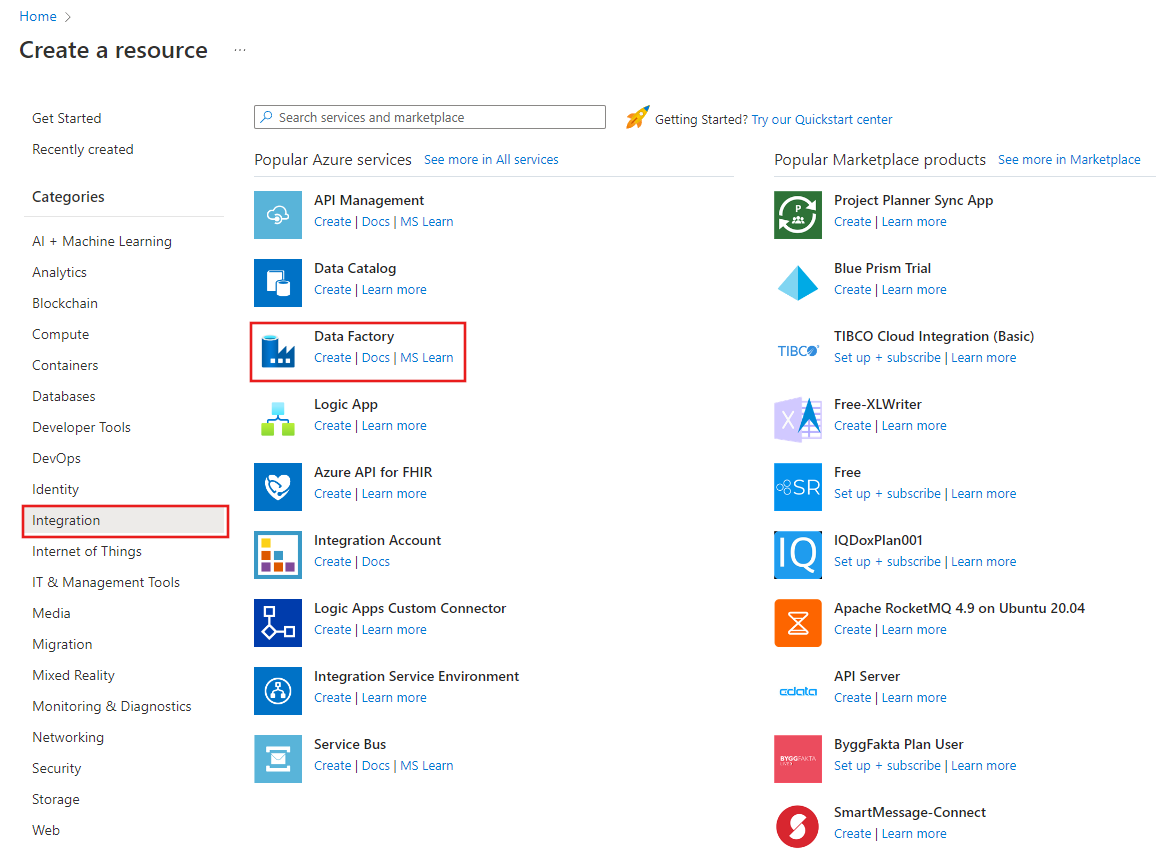
Na página Novo data factory, introduza ADFIncCopyTutorialDF para o nome.
O nome do Azure Data Factory deve ser globalmente único. Se vir um ponto de exclamação vermelho acompanhado pelo seguinte erro, altere o nome da Data Factory (por exemplo, "seuNomeADFIncCopyTutorialDF") e tente criar novamente. Consulte o artigo Data Factory - Regras de nomenclatura para obter regras de nomenclatura para artefatos do Data Factory.
O nome da fábrica de dados "ADFIncCopyTutorialDF" não está disponível
Selecione a sua Azure subscrição onde quer criar a fábrica de dados.
Para o Grupo de Recursos, execute uma das seguintes etapas:
Selecione Usar existente e selecione um grupo de recursos existente na lista suspensa.
Selecione Criar novo e insira o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, veja Using resource groups to manage your Azure resources.
Selecione V2 para a versão.
Selecione a localização para a fábrica de dados. Só são exibidas na lista drop-down as localizações que são suportadas. Os repositórios de dados (Azure Storage, Azure SQL Database, Azure SQL Managed Instance, entre outros) e os cálculos (HDInsight, etc.) usados pela data factory podem estar noutras regiões.
Clique em Criar.
Após a conclusão da criação, você verá a página Data Factory , conforme mostrado na imagem.
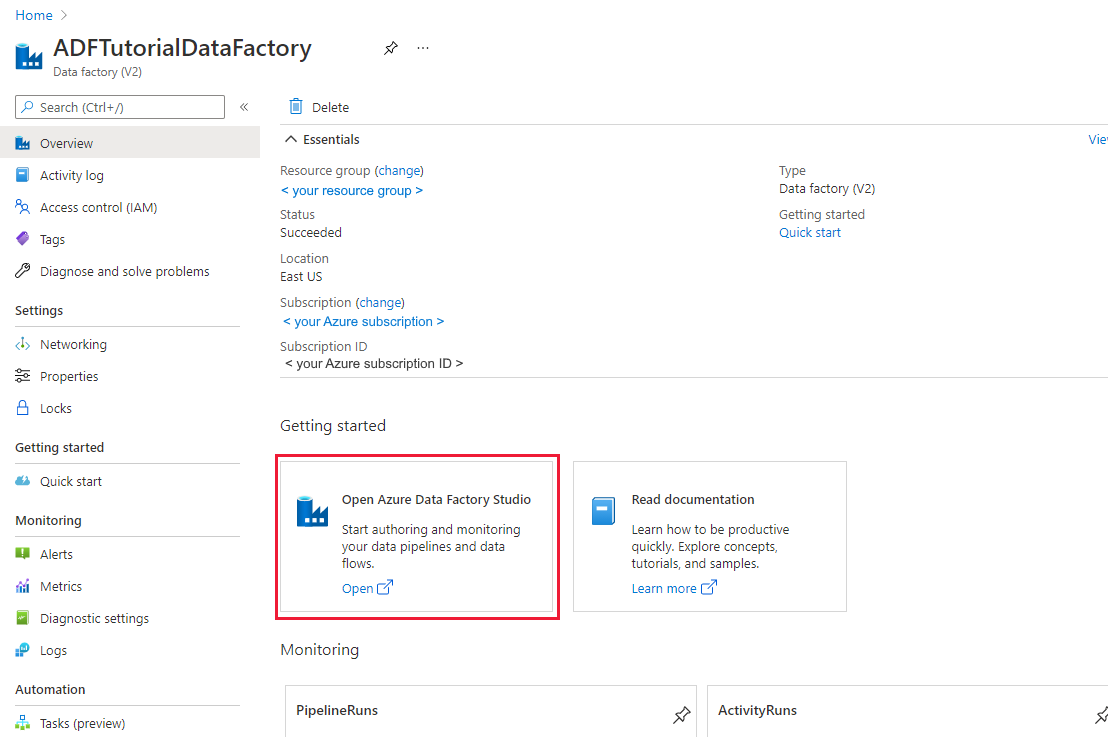
Selecione Open no bloco Open Azure Data Factory Studio para iniciar a interface de utilizador (UI) do Azure Data Factory num separador separado.
Criar um pipeline
Neste tutorial, crias um pipeline com duas atividades de Lookup, uma Copy activity e uma atividade StoredProcedure encadeadas num pipeline.
Na página inicial da interface do usuário do Data Factory, clique no bloco Orquestrar .
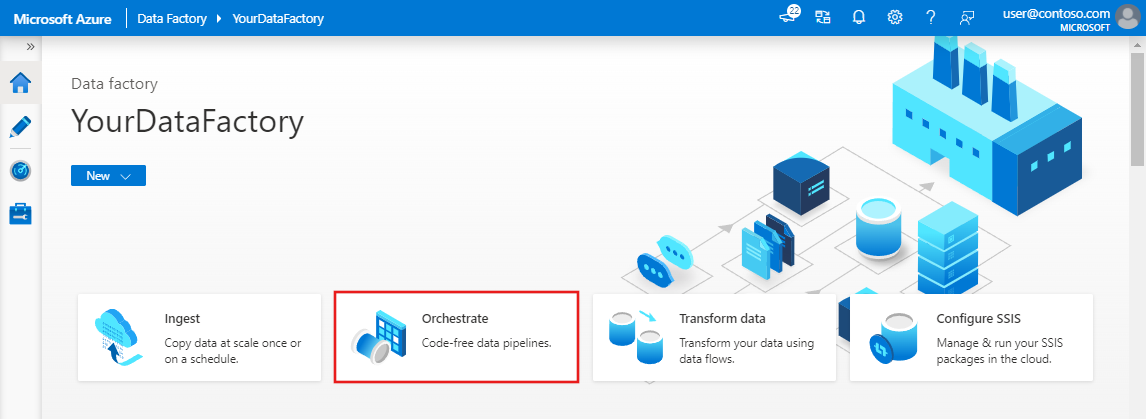
No painel Geral, em Propriedades, especifique IncrementalCopyPipeline para Name. Em seguida, feche o painel clicando no ícone Propriedades no canto superior direito.
Vamos adicionar a primeira atividade de Lookup para obter o valor do watermark antigo. Na caixa de ferramentas Atividades, desenvolva Geral e arraste e solte a atividade Pesquisa na interface de designer de pipeline. Altere o nome da atividade para LookupOldWaterMarkActivity.

Alterne para a guia Configurações e clique em + Novo para Conjunto de Dados de Origem. Nesta etapa, você cria um conjunto de dados para representar dados na tabela de marca d'água. Esta tabela contém a marca d'água antiga que foi utilizada na operação de cópia anterior.
Na janela Novo Conjunto de Dados, selecione Azure SQL Database e clique em Continue. Você verá uma nova janela aberta para o conjunto de dados.
Na janela Definir propriedades do conjunto de dados, insira WatermarkDataset para Name.
Para Serviço Vinculado, selecione Novo e siga as seguintes etapas:
Insira AzureSqlDatabaseLinkedService para Name.
Selecione o servidor para Nome do servidor.
Selecione o nome do banco de dados na lista suspensa.
Introduza o seu Nome de utilizador & Palavra-passe.
Para testar a conexão com o banco de dados SQL, clique em Testar conexão.
Clique em Concluir.
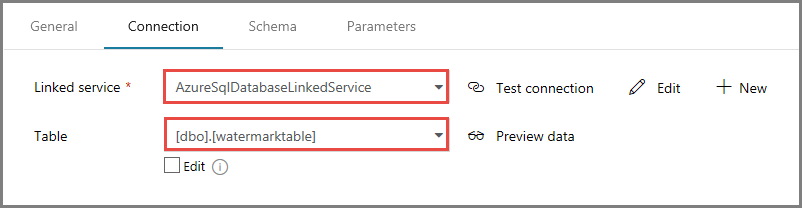
Confirme se AzureSqlDatabaseLinkedService está selecionado para Serviço vinculado.
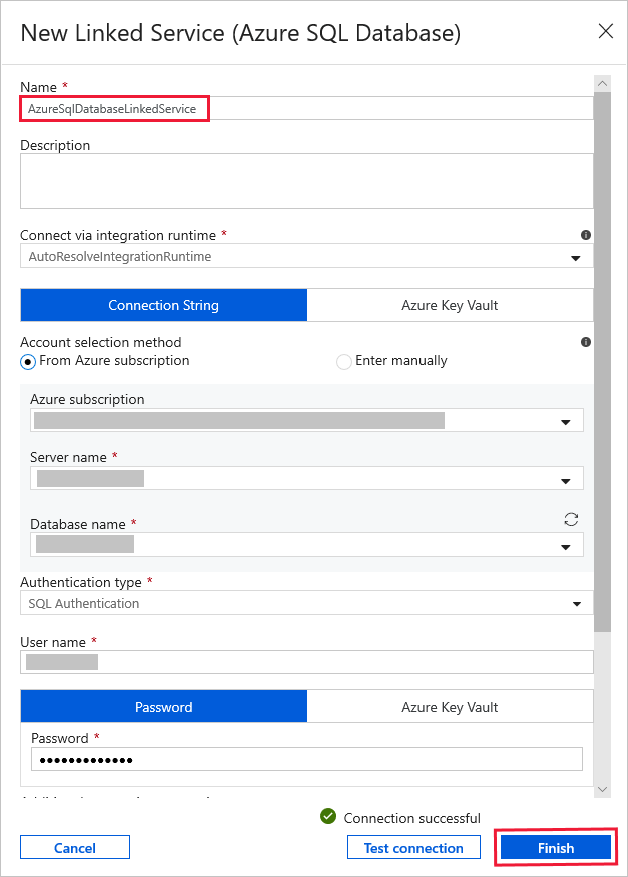
Selecione Concluir.
Na guia Conexão, selecione [dbo].[watermarktable] para Tabela. Se pretender pré-visualizar dados na tabela, clique em Pré-visualizar dados.
Clique no separador do pipeline, na parte superior, ou clique no nome do pipeline na vista de árvore, do lado esquerdo, para mudar para o editor do pipeline. Na janela de propriedades da atividade Pesquisa, confirme se WatermarkDataset está selecionado para o campo Conjunto de Dados de Origem .
Na caixa de ferramentas Atividades, expanda Geral, arraste e largue outra atividade Pesquisa na superfície do designer de pipeline e, na guia Geral da janela de propriedades, defina o nome como LookupNewWaterMarkActivity. Esta atividade Lookup obtém o novo valor de watermark da tabela com os dados de origem a serem copiados para o destino.
Na janela de propriedades da segunda atividade de Pesquisa , alterne para a guia Configurações e clique em Novo. Crie um dataset que aponte para a tabela de origem que contém o novo valor da marca d'água (valor máximo de LastModifyTime).
Na janela Novo Conjunto de Dados, selecione Azure SQL Database e clique em Continue.
Na janela Definir propriedades , digite SourceDataset para Name. Selecione AzureSqlDatabaseLinkedService para serviço vinculado.
Selecione [dbo].[data_source_table] para Tabela. Vai especificar uma consulta neste conjunto de dados mais adiante no tutorial. A consulta tem precedência sobre a tabela que especifica neste passo.
Selecione Concluir.
Clique no separador do pipeline, na parte superior, ou clique no nome do pipeline na vista de árvore, do lado esquerdo, para mudar para o editor do pipeline. Na janela de propriedades da atividade Pesquisa, confirme se SourceDataset está selecionado para o campo Conjunto de Dados de Origem .
Selecione Consulta para o campo Usar consulta e insira a seguinte consulta: você está selecionando apenas o valor máximo de LastModifytime no data_source_table. Por favor, certifique-se de que também verificou apenas a primeira linha.
select MAX(LastModifytime) as NewWatermarkvalue from data_source_table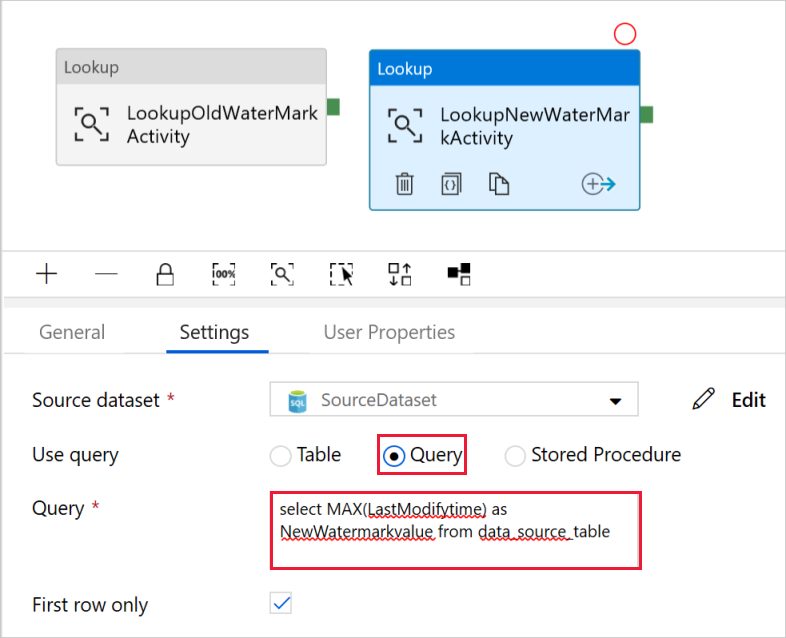
Na caixa de ferramentas Atividades, expanda Mover & Transformar e arraste e solte a atividade Copiar da mesma caixa de ferramentas, e defina o nome como IncrementalCopyActivity.
Ligue ambas as atividades de Pesquisa ao Copy activity arrastando o botão verde associado às atividades de Pesquisa para o Copy activity. Solte o botão do rato quando vires que a cor da borda da Copy activity muda para azul.
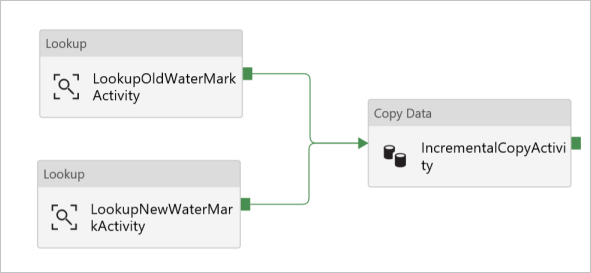
Selecione o Copy activity e confirme que vê as propriedades da atividade na janela Properties.
Alterne para a guia Origem na janela Propriedades e execute as seguintes etapas:
Selecione SourceDataset para o campo Source Dataset .
Selecione Consulta para o campo Usar consulta .
Insira a seguinte consulta SQL para o campo Consulta .
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'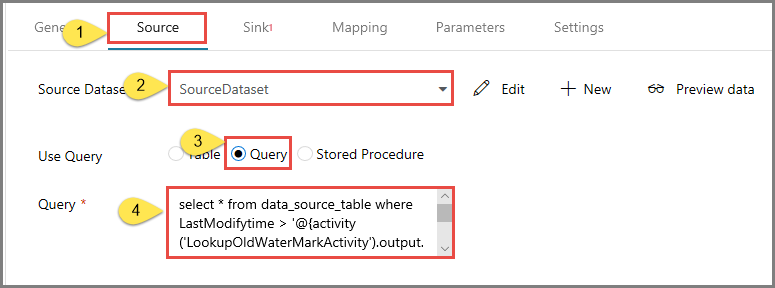
Alterne para a guia Coletor e clique em + Novo para o campo Conjunto de dados do coletor .
Neste tutorial, o sink data store é do tipo Azure Blob Storage. Portanto, selecione Azure Blob Storage e clique em Continue na janela Novo Conjunto de Dados.
Na janela Selecionar formato , selecione o tipo de formato dos dados e clique em Continuar.
Na janela Definir propriedades , digite SinkDataset para Name. Em Serviço Vinculado, selecione + Novo. Neste passo, cria uma ligação (serviço ligado) ao seu armazenamento de blobs Azure.
Na janela Novo Serviço Ligado (Azure Blob Storage), faça os seguintes passos:
- Insira AzureStorageLinkedService para Name.
- Selecione a sua conta Azure Storage para nome da conta de armazenamento.
- Testar Conexão e clique em Concluir.
Na janela Definir Propriedades , confirme se AzureStorageLinkedService está selecionado para Serviço vinculado. Em seguida, selecione Concluir.
Vá para a guia Conexão de SinkDataset e execute as seguintes etapas:
- Para o campo Caminho do arquivo , insira adftutorial/incrementalcopy. adftutorial é o nome do contêiner blob e incrementalcopy é o nome da pasta. Este fragmento considera que tem um contentor de blobs denominado adftutorial no seu armazenamento de blobs. Crie o contentor se ainda não existir ou defina-o como o nome de um contentor existente. Azure Data Factory cria automaticamente a pasta de saída incrementalcopy se esta não existir. Você também pode usar o botão Procurar para o caminho do ficheiro para navegar até uma pasta num contentor de blob.
- Para a parte Arquivo do campo Caminho do arquivo , selecione Adicionar conteúdo dinâmico [Alt+P] e insira
@CONCAT('Incremental-', pipeline().RunId, '.txt')na janela aberta. Em seguida, selecione Concluir. O nome do ficheiro é gerado dinamicamente através da expressão. Cada execução de um pipeline tem um ID único. A Copy activity usa o ID de execução para gerar o nome do ficheiro.
Alterne para o editor de pipeline clicando na guia pipeline na parte superior ou clicando no nome do pipeline na visualização em árvore à esquerda.
Na caixa de ferramentas Atividades, expanda Geral e arraste a atividade Procedimento Armazenado da caixa de ferramentas Atividades para a superfície de design do pipeline. Conecte a saída verde (Êxito) da atividade Copiar à atividade Procedimento armazenado .
Selecione Atividade de Procedimento Armazenado no designer de pipeline, altere o nome para StoredProceduretoWriteWatermarkActivity.
Alterne para a guia Conta SQL e selecione AzureSqlDatabaseLinkedService para serviço vinculado.
Alterne para a guia Procedimento Armazenado e siga as seguintes etapas:
Em Nome do procedimento armazenado, selecione usp_write_watermark.
Para especificar valores para os parâmetros do procedimento armazenado, clique em Importar parâmetro e insira os seguintes valores para os parâmetros:
Nome Tipo valor ÚltimaHoraDeModificação Data e Hora @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} Nome da Tabela Cordão @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName} 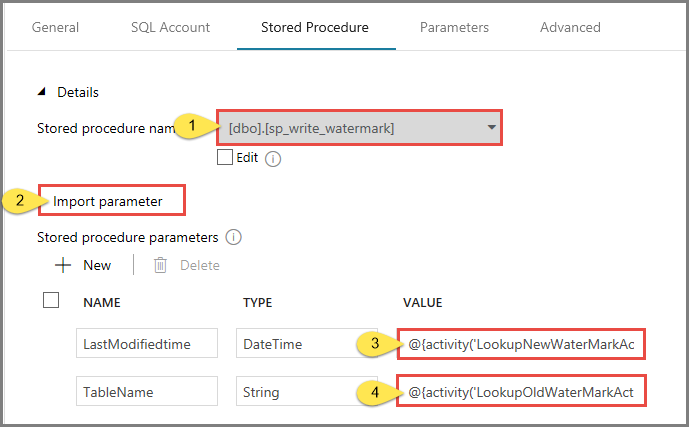
Para validar as configurações do pipeline, clique em Validar na barra de ferramentas. Confirme que não há erros de validação. Para fechar a janela Relatório de Validação de Pipeline , clique em >>.
Publique entidades (serviços ligados, conjuntos de dados e pipelines) no serviço Azure Data Factory selecionando o botão Publicar Tudo. Aguarde até ver uma mensagem a indicar que a publicação foi bem-sucedida.
Acionar uma execução de pipeline
Clique em Adicionar gatilho na barra de ferramentas e clique em Gatilho agora.
Na janela Pipeline Run , selecione Finish.
Monitorizar a execução do pipeline.
Mude para o separador Monitor do lado esquerdo. Você visualiza o estado da execução do pipeline que foi iniciada por um gatilho manual. Você pode usar links na coluna NOME DO PIPELINE para exibir detalhes da execução e executar novamente o pipeline.
Para ver as execuções de atividade associadas à execução do pipeline, selecione o link na coluna NOME DO PIPELINE . Para obter detalhes sobre a atividade executada, selecione o link Detalhes (ícone de óculos) na coluna NOME DA ATIVIDADE . Selecione Todas as Execuções de Pipelines no topo para voltar à visualização Execuções de Pipelines. Para atualizar a vista, selecione Atualizar.
Rever os resultados
Liga-te à tua conta Azure Storage usando ferramentas como Azure Storage Explorer. Verifique se um arquivo de saída foi criado na pasta incrementalcopy do contêiner adftutorial .
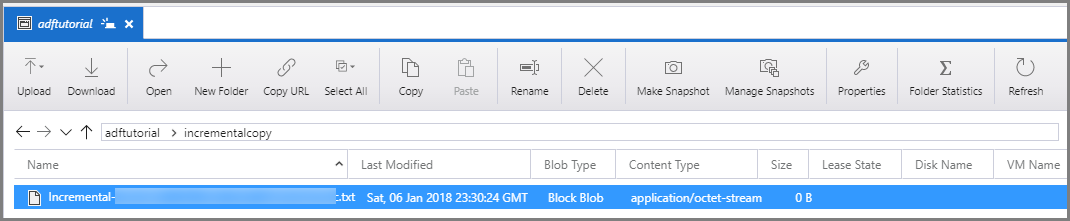
Abra o arquivo de saída e observe que todos os dados são copiados do data_source_table para o arquivo de blob.
1,aaaa,2017-09-01 00:56:00.0000000 2,bbbb,2017-09-02 05:23:00.0000000 3,cccc,2017-09-03 02:36:00.0000000 4,dddd,2017-09-04 03:21:00.0000000 5,eeee,2017-09-05 08:06:00.0000000Verifique o valor mais recente do
watermarktable. Verá que o valor da marca d'água foi atualizado.Select * from watermarktableA saída é:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-05 8:06:00.000 |
Adicionar mais dados à origem
Insira novos dados em seu banco de dados (armazenamento da fonte de dados).
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
Os dados atualizados na sua base de dados são:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
Iniciar outra execução de pipeline
Alterne para a guia Editar . Clique no pipeline na visualização em árvore se ele não estiver aberto no designer.
Clique em Adicionar gatilho na barra de ferramentas e clique em Gatilho agora.
Monitorizar a segunda execução do pipeline
Mude para o separador Monitor do lado esquerdo. Você visualiza o estado da execução do pipeline que foi iniciada por um gatilho manual. Você pode usar links na coluna NOME DO PIPELINE para exibir detalhes da atividade e executar novamente o pipeline.
Para ver as execuções de atividade associadas à execução do pipeline, selecione o link na coluna NOME DO PIPELINE . Para obter detalhes sobre a atividade executada, selecione o link Detalhes (ícone de óculos) na coluna NOME DA ATIVIDADE . Selecione Todas as Execuções de Pipelines no topo para voltar à visualização Execuções de Pipelines. Para atualizar a vista, selecione Atualizar.
Verificar a segunda saída
No armazenamento de blobs, verá que outro ficheiro foi criado. Neste tutorial, o novo nome de ficheiro é
Incremental-<GUID>.txt. Abra esse ficheiro e verá duas linhas de registos no mesmo.6,newdata,2017-09-06 02:23:00.0000000 7,newdata,2017-09-07 09:01:00.0000000Verifique o valor mais recente do
watermarktable. Verá que o valor da marca d’água foi atualizado novamente.Select * from watermarktableSaída de exemplo:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-07 09:01:00.000 |
Conteúdos relacionados
Neste tutorial, executou os passos seguintes:
- Preparar o repositório de dados para armazenar o valor de marca d'água.
- Criar uma fábrica de dados.
- Criar serviços ligados.
- Crie conjuntos de dados de origem, de sumidouro e de marca d'água.
- Criar um pipeline.
- Executar o pipeline.
- Monitorizar a execução do pipeline.
- Rever resultados
- Adicionar mais dados à origem.
- Executar o pipeline novamente.
- Monitorizar a segunda execução do pipeline
- Rever os resultados da segunda execução
Neste tutorial, o pipeline copiou dados de uma única tabela na Base de Dados SQL para o armazenamento Blob. Avance para o tutorial seguinte para aprender a copiar dados de várias tabelas numa base de dados SQL Server para a base de dados SQL.