Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
A organização de dados na data factory permite-lhe construir mash-ups interativos de Power Query nativamente no ADF e depois executá-los em escala dentro de um pipeline ADF.
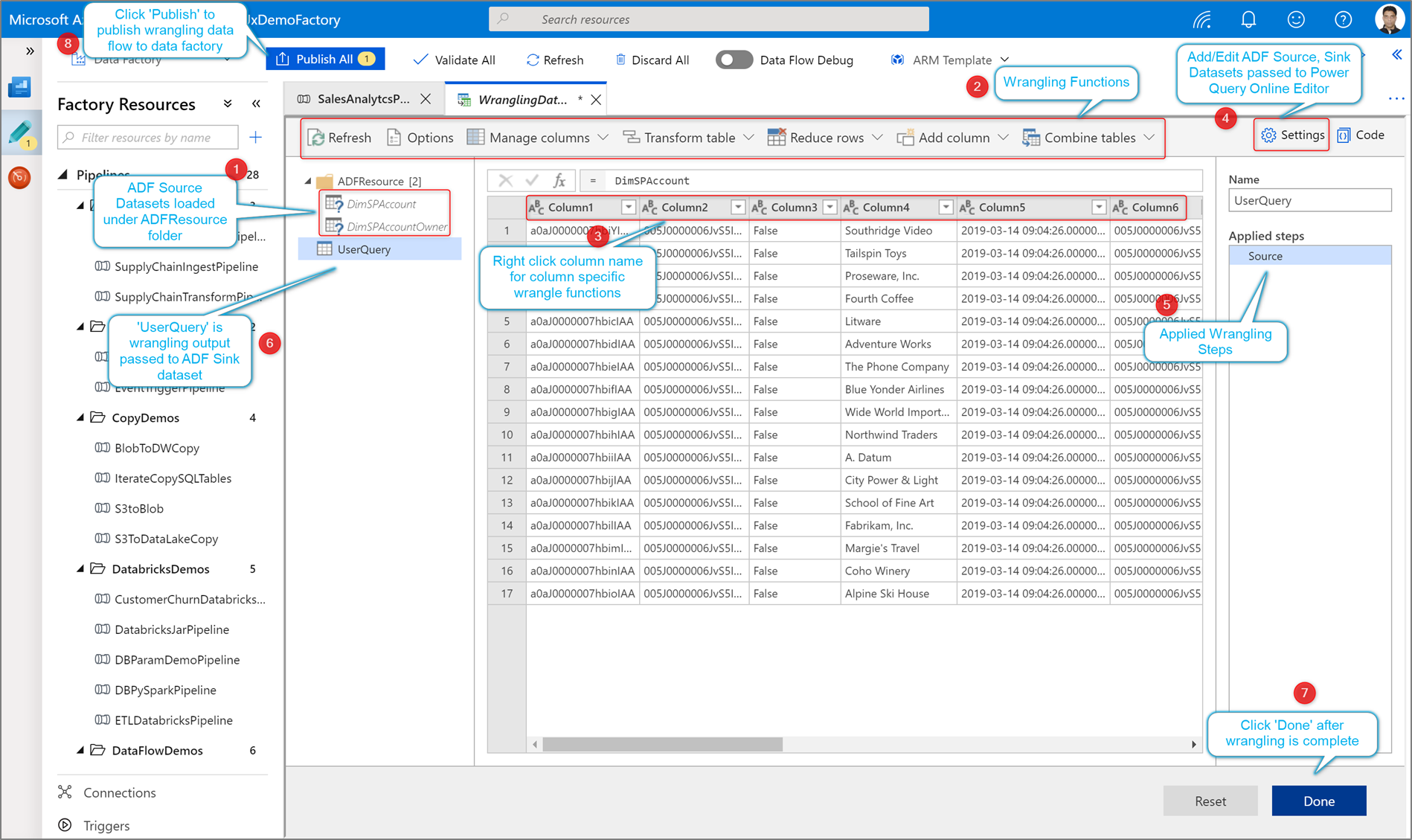
Criar uma atividade Power Query
Existem duas formas de criar uma Power Query no Azure Data Factory. Uma forma é clicar no ícone mais e selecionar Power Query no painel de recursos da fábrica.
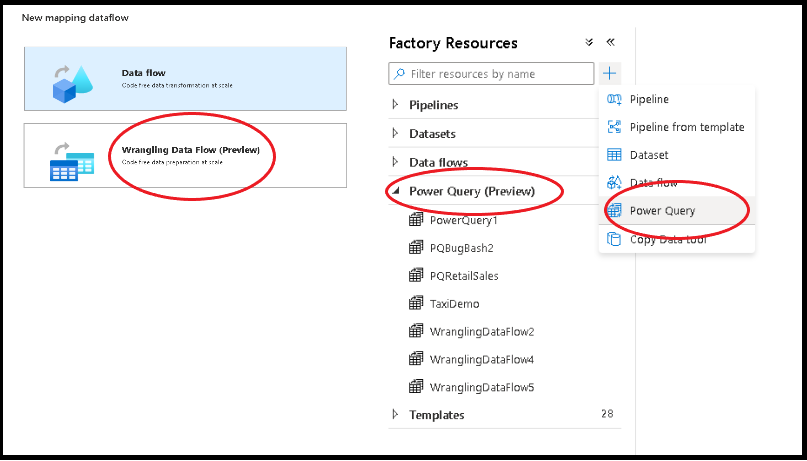
O outro método está no painel de atividades do quadro de pipeline. Abra o acordeão Power Query e arraste a atividade Power Query para a tela.
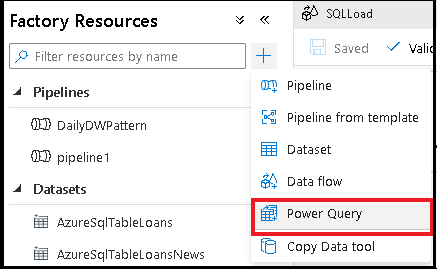
Crie uma atividade de manipulação de dados no Power Query
Adicione um conjunto de dados de origem para o seu mash-up do Power Query. Você pode escolher um conjunto de dados existente ou criar um novo. Depois de guardar o mash-up, pode criar um pipeline, adicionar a atividade de transformação de dados do Power Query ao pipeline e selecionar um conjunto de dados de destino para indicar ao Azure Data Factory onde os seus dados devem ser armazenados. Embora você possa escolher um ou mais conjuntos de dados de origem, apenas um coletor é permitido no momento. A escolha de um conjunto de dados de coletor é opcional, mas pelo menos um conjunto de dados de origem é necessário.
Clique em Create para abrir o editor de mashups Power Query Online.
Primeiro, você escolherá uma fonte de conjunto de dados para o editor de mashup.
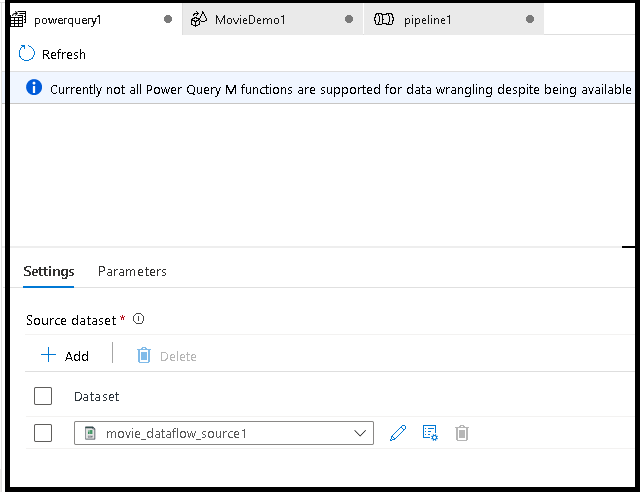
Depois de terminares de construir o teu Power Query, podes guardá-lo e depois criar um pipeline. Você precisa adicionar o mashup como uma atividade na sua pipeline. É quando irá criar/selecionar o conjunto de dados de destino para armazenar os seus dados. Você também pode definir as propriedades do conjunto de dados de destino clicando no segundo botão no lado direito do conjunto de dados de destino. Lembre-se de alterar a "opção de partição" em "Otimizar" para "Partição única" se você quiser apenas obter um único arquivo de saída.
Crie a sua Power Query de wrangling usando preparação de dados sem código. Para obter a lista de funções disponíveis, consulte funções de transformação. O ADF traduz o script M num script de fluxo de dados para que possa executar o seu Power Query em grande escala usando o ambiente Spark do Azure Data Factory.
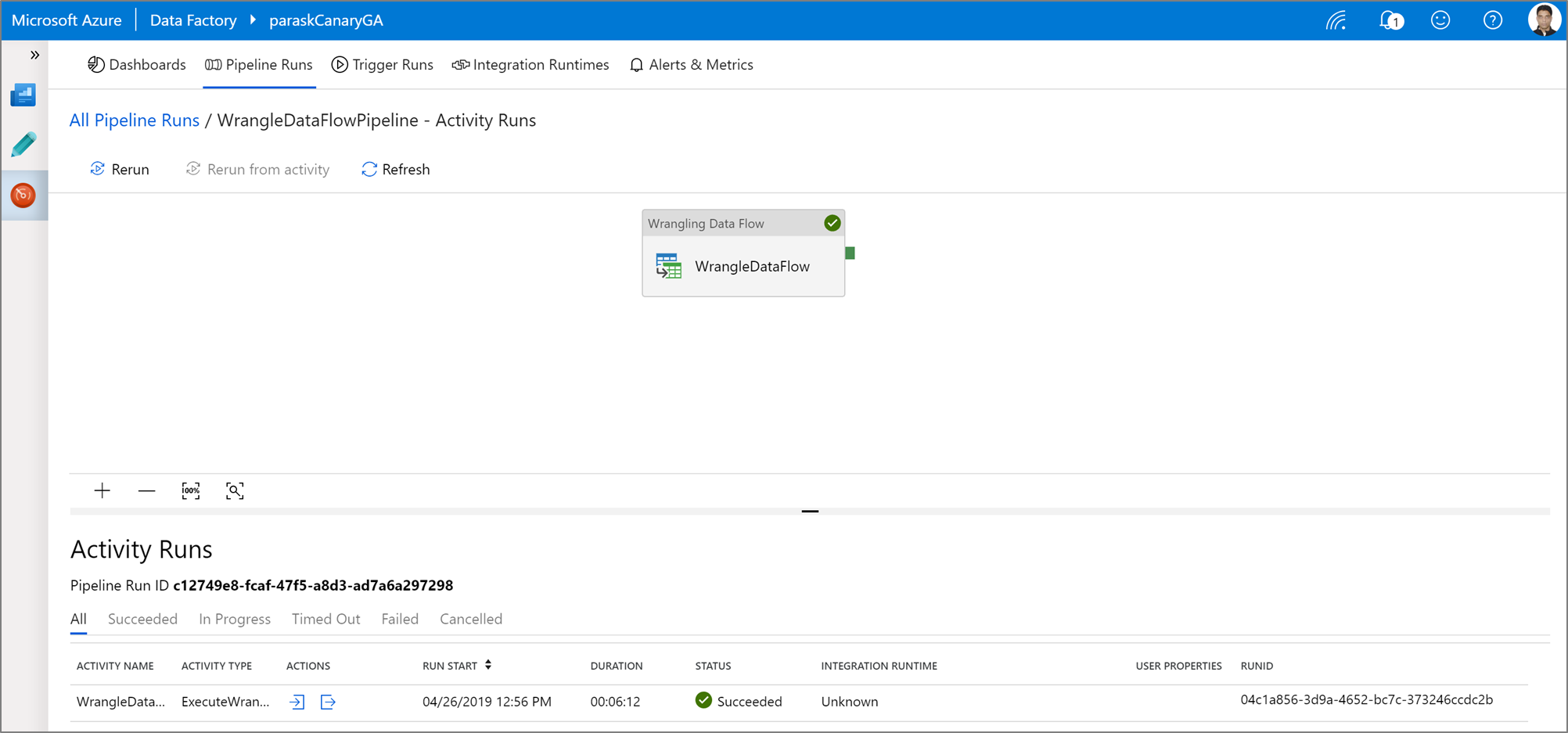
Execução e monitorização de uma atividade de organização de dados no Power Query
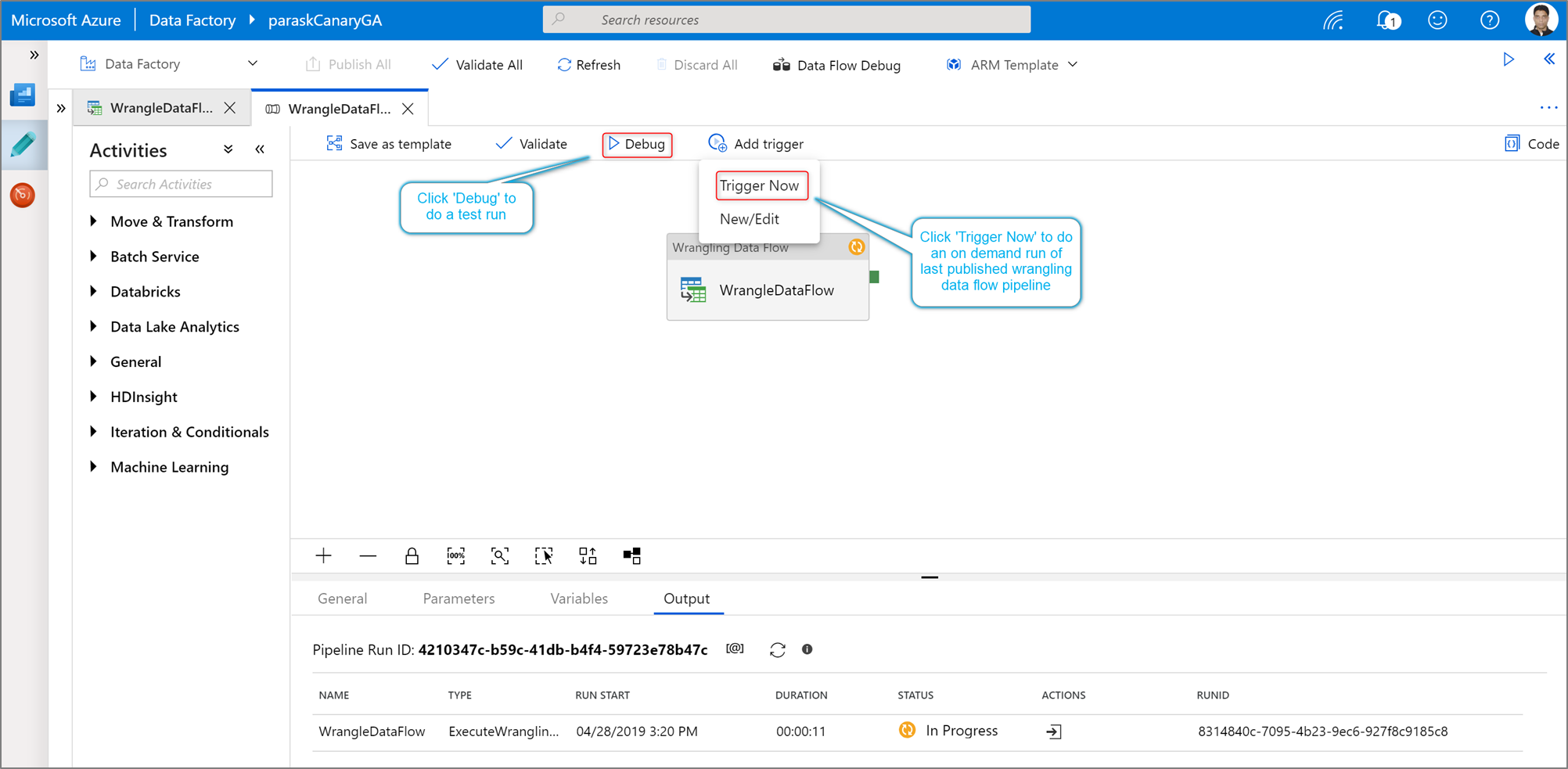
Para executar uma execução de depuração de pipeline de uma atividade Power Query, clique em Debug na canvas de pipeline. Depois de publicar seu pipeline, o Trigger agora executa uma execução sob demanda do último pipeline publicado. Os pipelines do Power Query podem ser agendados utilizando todos os gatilhos existentes do Azure Data Factory.
Vai ao separador Monitor para visualizar a saída de uma execução de atividade Power Query desencadeada.
Conteúdos relacionados
Saiba como criar um fluxo de dados de mapeamento.