Otimizar Azure Data Lake Storage Gen1 para obter desempenho
Data Lake Storage Gen1 suporta o débito elevado para a análise intensiva de E/S e o movimento de dados. No Data Lake Storage Gen1, a utilização de todo o débito disponível – a quantidade de dados que podem ser lidos ou escritos por segundo – é importante para obter o melhor desempenho. Isto é conseguido ao efetuar o maior número possível de leituras e escritas em paralelo.
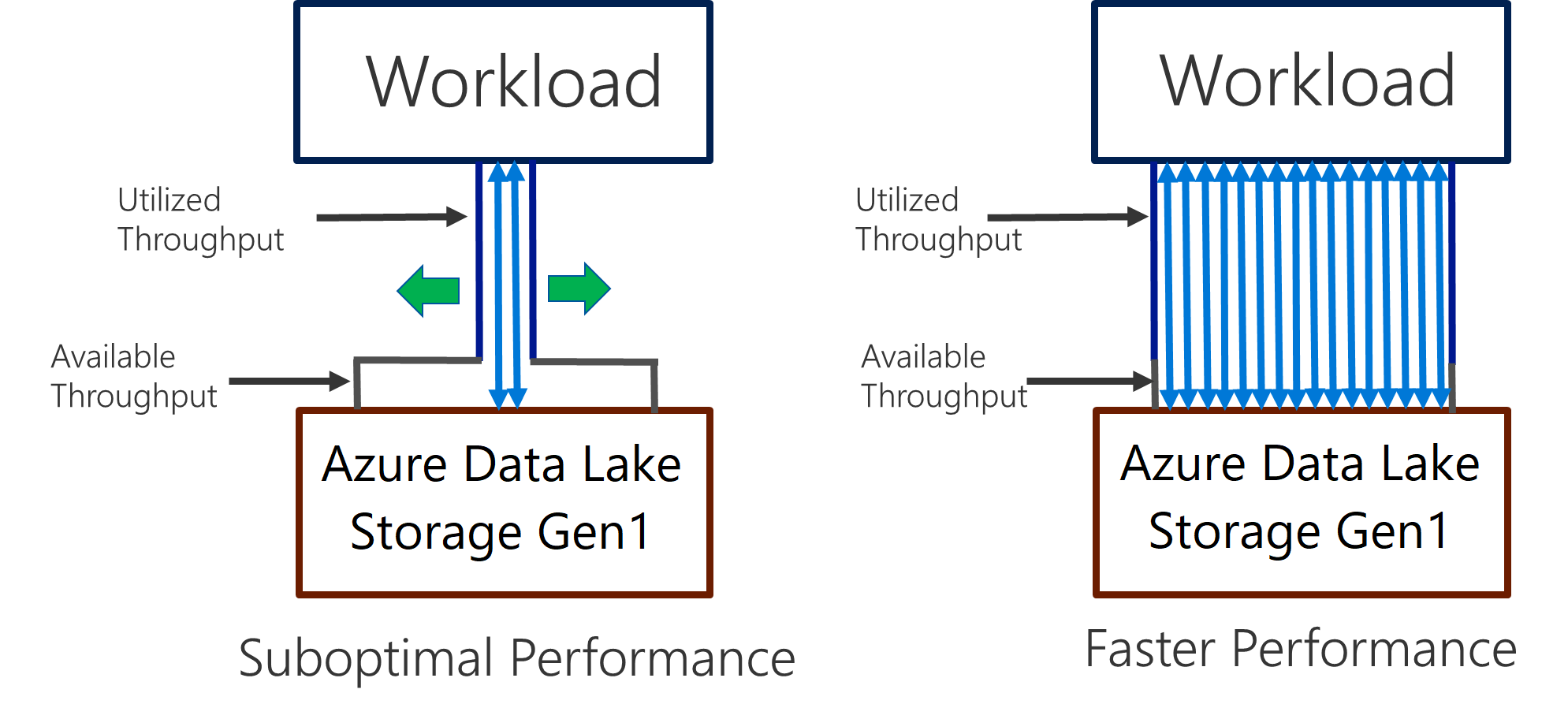
Data Lake Storage Gen1 pode dimensionar para fornecer o débito necessário para todos os cenários de análise. Por predefinição, uma conta Data Lake Storage Gen1 fornece automaticamente débito suficiente para satisfazer as necessidades de uma ampla categoria de casos de utilização. Para os casos em que os clientes se deparam com o limite predefinido, a conta Data Lake Storage Gen1 pode ser configurada para fornecer mais débito ao contactar o suporte da Microsoft.
Ingestão de dados
Ao ingerir dados de um sistema de origem para Data Lake Storage Gen1, é importante considerar que o hardware de origem, o hardware de rede de origem e a conectividade de rede para Data Lake Storage Gen1 podem ser o estrangulamento.
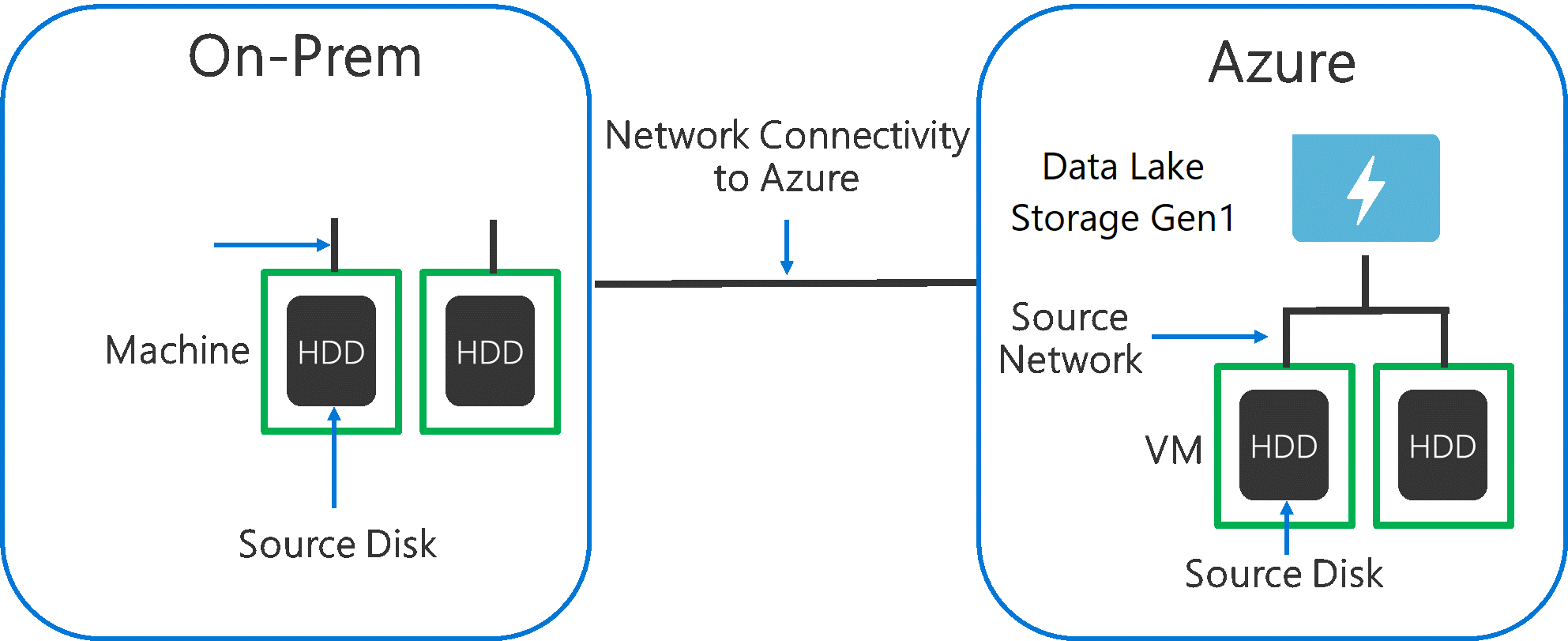
É importante garantir que o movimento de dados não é afetado por estes fatores.
Hardware de origem
Quer esteja a utilizar máquinas ou VMs no local no Azure, deve selecionar cuidadosamente o hardware adequado. Para Hardware de Disco de Origem, prefira SSDs a HDDs e escolha hardware de disco com spindles mais rápidos. Para Hardware de Rede de Origem, utilize as NICs mais rápidas possíveis. No Azure, recomendamos VMs do Azure D14 que tenham o hardware de rede e disco devidamente potente.
Conectividade de rede a Data Lake Storage Gen1
Por vezes, a conectividade de rede entre os dados de origem e Data Lake Storage Gen1 pode ser o estrangulamento. Quando os dados de origem estiverem no Local, considere utilizar uma ligação dedicada com o Azure ExpressRoute . Se os dados de origem estiverem no Azure, o desempenho será melhor quando os dados estiverem na mesma região do Azure que a conta Data Lake Storage Gen1.
Configurar ferramentas de ingestão de dados para paralelização máxima
Depois de abordar os estrangulamentos de conectividade de rede e hardware de origem, está pronto para configurar as ferramentas de ingestão. A tabela seguinte resume as principais definições de várias ferramentas de ingestão populares e fornece artigos de otimização de desempenho aprofundados para as mesmas. Para saber mais sobre que ferramenta utilizar para o seu cenário, visite este artigo.
| Ferramenta | Definições | Mais Detalhes |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Ligação |
| AdlCopy | Unidades de Data Lake Analytics do Azure | Ligação |
| DistCp | -m (mapper) | Ligação |
| Azure Data Factory | parallelCopies | Ligação |
| Sqoop | fs.azure.block.size, -m (mapper) | Ligação |
Estruturar o conjunto de dados
Quando os dados são armazenados em Data Lake Storage Gen1, o tamanho do ficheiro, o número de ficheiros e a estrutura da pasta afetam o desempenho. A secção seguinte descreve as melhores práticas nestas áreas.
Tamanho dos ficheiros
Normalmente, os motores de análise como o HDInsight e o Azure Data Lake Analytics têm uma sobrecarga por ficheiro. Se armazenar os seus dados com tantos ficheiros pequenos, isto pode afetar negativamente o desempenho.
Em geral, organize os seus dados em ficheiros de tamanho maior para um melhor desempenho. Como regra de polegar, organize conjuntos de dados em ficheiros de 256 MB ou superiores. Em alguns casos, como imagens e dados binários, não é possível processá-los em paralelo. Nestes casos, é recomendado manter ficheiros individuais com menos de 2 GB.
Por vezes, os pipelines de dados têm um controlo limitado sobre os dados não processados que têm muitos ficheiros pequenos. Recomenda-se que tenha um processo de "cozinha" que gere ficheiros maiores para utilizar em aplicações a jusante.
Organizar dados de série temporal em pastas
Para cargas de trabalho do Hive e do ADLA, a poda de partições de dados de série temporal pode ajudar algumas consultas a ler apenas um subconjunto dos dados, o que melhora o desempenho.
Os pipelines que ingerem dados de série temporal colocam frequentemente os respetivos ficheiros com uma nomenclatura estruturada para ficheiros e pastas. Segue-se um exemplo comum que vemos para dados estruturados por data: \DataSet\YYYYY\MM\DD\datafile_YYYY_MM_DD.tsv.
Repare que as informações datetime são apresentadas como pastas e no nome do ficheiro.
Para data e hora, o seguinte é um padrão comum: \DataSet\YYYYY\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv.
Mais uma vez, a escolha que fizer com a pasta e a organização de ficheiros deve otimizar para os tamanhos de ficheiro maiores e um número razoável de ficheiros em cada pasta.
Otimizar tarefas intensivas de E/S em cargas de trabalho do Hadoop e do Spark no HDInsight
As tarefas enquadram-se numa das três categorias seguintes:
- CPU intensiva. Estas tarefas têm tempos de computação longos com tempos de E/S mínimos. Os exemplos incluem trabalhos de machine learning e processamento de linguagem natural.
- Memória intensiva. Estas tarefas utilizam muita memória. Os exemplos incluem o PageRank e as tarefas de análise em tempo real.
- E/S intensiva. Estes trabalhos passam a maior parte do tempo a fazer E/S. Um exemplo comum é uma tarefa de cópia que faz apenas operações de leitura e escrita. Outros exemplos incluem trabalhos de preparação de dados que leem inúmeros dados, efetuam alguma transformação de dados e, em seguida, escrevem os dados novamente no arquivo.
A seguinte documentação de orientação aplica-se apenas a tarefas intensivas de E/S.
Considerações gerais para um cluster do HDInsight
- Versões do HDInsight. Para obter o melhor desempenho, utilize a versão mais recente do HDInsight.
- Regiões. Coloque a conta Data Lake Storage Gen1 na mesma região que o cluster do HDInsight.
Um cluster do HDInsight é composto por dois nós principais e alguns nós de trabalho. Cada nó de trabalho fornece um número específico de núcleos e memória, que é determinado pelo tipo de VM. Ao executar uma tarefa, o YARN é o negociador de recursos que atribui a memória e os núcleos disponíveis para criar contentores. Cada contentor executa as tarefas necessárias para concluir a tarefa. Os contentores são executados em paralelo para processar tarefas rapidamente. Por conseguinte, o desempenho é melhorado ao executar o maior número possível de contentores paralelos.
Existem três camadas num cluster do HDInsight que podem ser otimizadas para aumentar o número de contentores e utilizar todo o débito disponível.
- Camada física
- Camada do YARN
- Camada da carga de trabalho
Camada física
Execute o cluster com mais nós e/ou VMs de tamanho maior. Um cluster maior irá permitir-lhe executar mais contentores YARN, conforme mostrado na imagem abaixo.

Utilize VMs com mais largura de banda de rede. A quantidade de largura de banda de rede pode ser um estrangulamento se existir menos largura de banda de rede do que Data Lake Storage Gen1 débito. Diferentes VMs terão diferentes tamanhos de largura de banda de rede. Escolha um tipo de VM que tenha a maior largura de banda de rede possível.
Camada do YARN
Utilize contentores YARN mais pequenos. Reduza o tamanho de cada contentor YARN para criar mais contentores com a mesma quantidade de recursos.
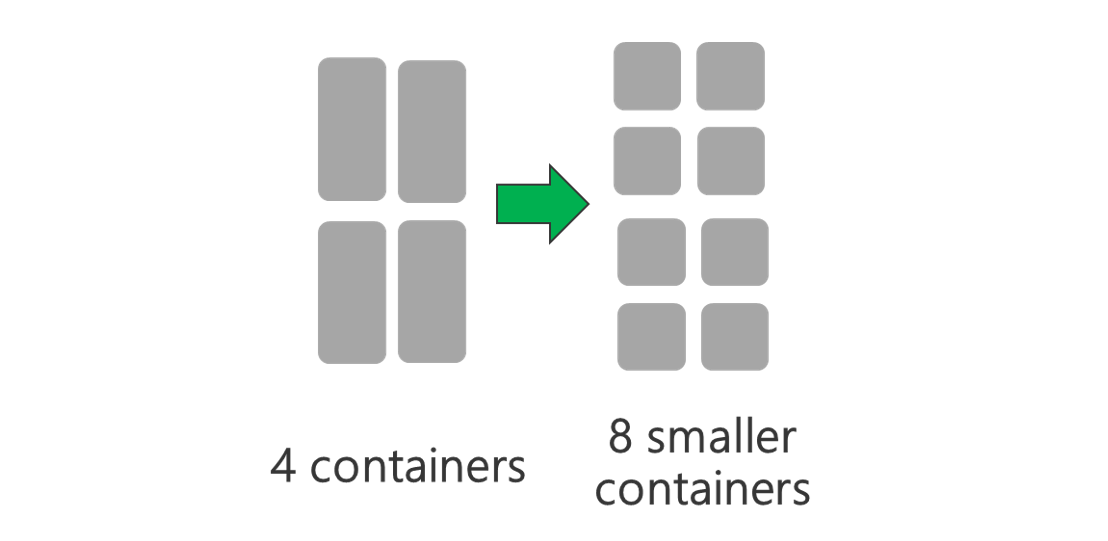
Consoante a carga de trabalho, será sempre necessário um tamanho mínimo de contentor yarn. Se escolher um contentor demasiado pequeno, as suas tarefas terão problemas de memória insuficiente. Normalmente, os contentores YARN não devem ser inferiores a 1 GB. É comum ver contentores YARN de 3 GB. Para algumas cargas de trabalho, poderá precisar de contentores YARN maiores.
Aumente os núcleos por contentor yarn. Aumente o número de núcleos alocados a cada contentor para aumentar o número de tarefas paralelas executadas em cada contentor. Isto funciona para aplicações como o Spark, que executam várias tarefas por contentor. Para aplicações como o Hive que executam um único thread em cada contentor, é melhor ter mais contentores do que mais núcleos por contentor.
Camada da carga de trabalho
Utilize todos os contentores disponíveis. Defina o número de tarefas para serem iguais ou maiores do que o número de contentores disponíveis para que todos os recursos sejam utilizados.
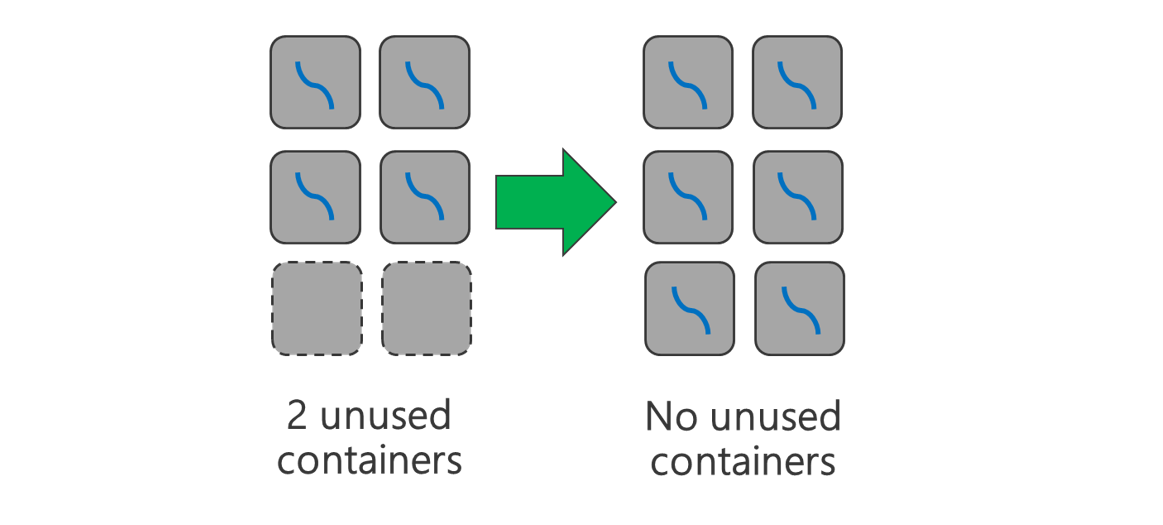
As tarefas falhadas são dispendiosas. Se cada tarefa tiver uma grande quantidade de dados para processar, a falha de uma tarefa resulta numa repetição dispendiosa. Portanto, é melhor criar mais tarefas, cada uma das quais processa uma pequena quantidade de dados.
Além das diretrizes gerais acima, cada aplicação tem diferentes parâmetros disponíveis para otimizar para essa aplicação específica. A tabela abaixo lista alguns dos parâmetros e ligações para começar a otimizar o desempenho de cada aplicação.
| Carga de trabalho | Parâmetro para definir tarefas |
|---|---|
| Spark no HDInsight |
|
| Hive no HDInsight |
|
| MapReduce no HDInsight |
|
| Storm no HDInsight |
|