Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
Esta documentação foi desativada e pode não ser atualizada. Os produtos, serviços ou tecnologias mencionados neste conteúdo não são mais suportados. Consulte Padrões de data/hora.
Os Date tipos de dados e Timestamp mudaram significativamente no Databricks Runtime 7.0. Este artigo descreve:
- O
Datetipo e o calendário associado. - O
Timestamptipo e como ele se relaciona com fusos horários. Ele também explica os detalhes da resolução de deslocamento de fuso horário e as mudanças sutis de comportamento na nova API de tempo em Java 8, usada pelo Databricks Runtime 7.0. - APIs para construir valores de data e hora.
- Armadilhas comuns e práticas recomendadas para colecionar objetos de data e hora no driver do Apache Spark.
Datas e calendários
A Date é uma combinação dos campos ano, mês e dia, como (ano=2012, mês=12, dia=31). No entanto, os valores dos campos ano, mês e dia têm restrições para garantir que o valor da data seja uma data válida no mundo real. Por exemplo, o valor do mês deve ser de 1 a 12, o valor do dia deve ser de 1 a 28,29,30, ou 31 (dependendo do ano e do mês), e assim por diante. O Date tipo não considera fusos horários.
Calendários
As restrições nos Date campos são definidas por um dos muitos calendários possíveis. Alguns, como o calendário lunar, são usados apenas em regiões específicas. Alguns, como o calendário juliano, são usados apenas na história. O padrão internacional de facto é o calendário gregoriano , que é usado em quase todo o mundo para fins civis. Foi introduzido em 1582 e foi estendido para suportar datas anteriores a 1582 também. Este calendário estendido é chamado de calendário gregoriano proléptico.
O Databricks Runtime 7.0 usa o calendário gregoriano proléptico, que já está sendo usado por outros sistemas de dados como pandas, R e Apache Arrow. Databricks Runtime 6.x e abaixo usou uma combinação do calendário juliano e gregoriano: para datas anteriores a 1582, o calendário juliano foi usado, para datas posteriores a 1582 o calendário gregoriano foi usado. Isso é herdado da API herdada java.sql.Date , que foi substituída no Java 8 pelo java.time.LocalDate, que usa o calendário gregoriano proléptico.
Marcas temporais e fusos horários
O Timestamp tipo estende o tipo Date com novos campos: hora, minuto, segundo (que pode ter uma parte fracionária) e um fuso horário global (escopo da sessão). Define um instante temporal concreto. Por exemplo, (ano=2012, mês=12, dia=31, hora=23, minuto=59, segundo=59.123456) com fuso horário da sessão UTC+01:00. Ao registar valores de timestamp em fontes de dados que não sejam de texto, como Parquet, os valores são apenas instantes (como timestamp em UTC) sem qualquer informação de fuso horário. Se escrever e ler um valor de timestamp com um fuso horário de sessão diferente, poderá ver valores diferentes nos campos de hora, minuto e segundo, mas será o mesmo instante exato no tempo.
Os campos hora, minuto e segundo têm intervalos padrão: 0 a 23 para horas e 0 a 59 para minutos e segundos. O Spark suporta segundos fracionados com precisão de até microssegundos. O intervalo válido para frações é de 0 a 999.999 microssegundos.
Em qualquer instante concreto, dependendo do fuso horário, você pode observar muitos valores diferentes de relógio de parede:
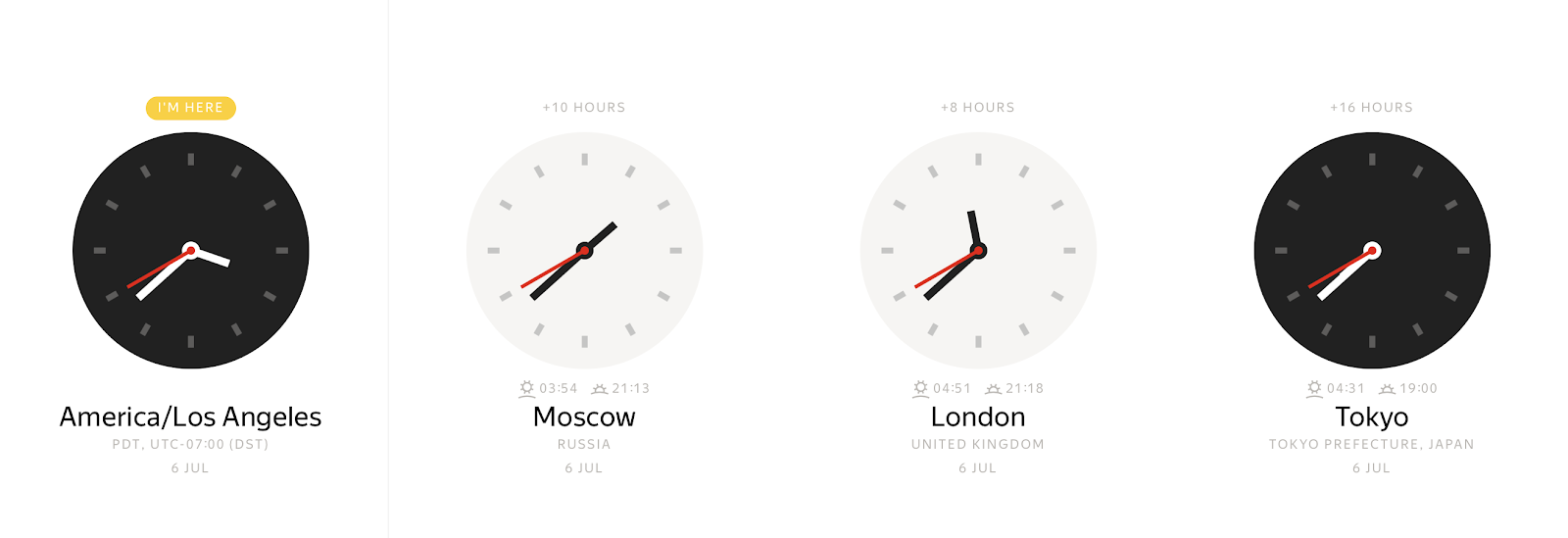
Por outro lado, um valor de relógio de parede pode representar muitos instantes de tempo diferentes.
O deslocamento de fuso horário permite vincular inequivocamente um carimbo de data/hora local a um instante de hora. Normalmente, as compensações de fuso horário são definidas como compensações em horas do Tempo Médio de Greenwich (GMT) ou UTC+0 (Tempo Universal Coordenado). Esta representação das informações de fuso horário elimina a ambiguidade, mas é inconveniente. A maioria das pessoas prefere apontar um local como America/Los_Angeles ou Europe/Paris. Este nível adicional de abstração dos desvios da zona torna a vida mais fácil, mas traz complicações. Por exemplo, agora você precisa manter um banco de dados de fuso horário especial para mapear nomes de fuso horário para deslocamentos. Como o Spark é executado na JVM, ele delega o mapeamento à biblioteca padrão Java, que carrega dados do Internet Assigned Numbers Authority Time Zone Database (IANA TZDB). Além disso, o mecanismo de mapeamento na biblioteca padrão do Java tem algumas nuances que influenciam o comportamento do Spark.
Desde o Java 8, o JDK expôs uma API diferente para manipulação de data e hora e resolução de deslocamento de fuso horário e o Databricks Runtime 7.0 usa essa API. Embora o mapeamento de nomes de fusos horários para deslocamentos tenha a mesma fonte, IANA TZDB, é implementado de maneira diferente no Java 8 e versões posteriores, em comparação com o Java 7.
Por exemplo, dê uma olhada em um timestamp antes do ano 1883 no fuso horário America/Los_Angeles: 1883-11-10 00:00:00. Este ano destaca-se de outros porque em 18 de novembro de 1883, todas as ferrovias norte-americanas mudaram para um novo sistema de tempo padrão. Usando a API de hora Java 7, você pode obter um deslocamento de fuso horário no carimbo de data/hora local como -08:00:
java.time.ZoneId.systemDefault
res0:java.time.ZoneId = America/Los_Angeles
java.sql.Timestamp.valueOf("1883-11-10 00:00:00").getTimezoneOffset / 60.0
res1: Double = 8.0
A API Java 8 equivalente retorna um resultado diferente:
java.time.ZoneId.of("America/Los_Angeles").getRules.getOffset(java.time.LocalDateTime.parse("1883-11-10T00:00:00"))
res2: java.time.ZoneOffset = -07:52:58
Antes de 18 de novembro de 1883, a hora do dia na América do Norte era um assunto local, e a maioria das cidades e vilas usava alguma forma de tempo solar local, mantido por um relógio bem conhecido (em um campanário da igreja, por exemplo, ou na janela de um joalheiro). É por isso que se observa um desfasamento de fuso horário tão peculiar.
O exemplo demonstra que as funções Java 8 são mais precisas e levam em conta dados históricos do IANA TZDB. Depois de mudar para a API de tempo Java 8, o Databricks Runtime 7.0 se beneficiou da melhoria automaticamente e tornou-se mais preciso na forma como resolve as compensações de fuso horário.
Databricks Runtime 7.0 também mudou para o calendário gregoriano proléptico para o tipo Timestamp. O padrão ISO SQL:2016 declara que o intervalo válido para carimbos de data/hora é de 0001-01-01 00:00:00 até 9999-12-31 23:59:59.999999. O Databricks Runtime 7.0 está totalmente em conformidade com o padrão e suporta todos os marcadores temporais neste intervalo. Em comparação com o Databricks Runtime 6.x e abaixo, observe os seguintes subintervalos:
-
0001-01-01 00:00:00..1582-10-03 23:59:59.999999. O Databricks Runtime 6.x e inferior usa o calendário juliano e não está em conformidade com o padrão. O Databricks Runtime 7.0 corrige o problema e aplica o calendário gregoriano proléptico em operações internas em carimbos de data/hora, como obter ano, mês, dia, etc. Devido a calendários diferentes, algumas datas que existem no Databricks Runtime 6.x e abaixo não existem no Databricks Runtime 7.0. Por exemplo, 1000-02-29 não é uma data válida porque 1000 não é um ano bissexto no calendário gregoriano. Além disso, o Databricks Runtime 6.x e inferior converte o nome do fuso horário em deslocamentos de zona incorretamente para este intervalo de tempo. -
1582-10-04 00:00:00..1582-10-14 23:59:59.999999. Este é um intervalo válido de carimbos de data/hora locais no Databricks Runtime 7.0, em contraste com as versões anteriores à 6.x do Databricks Runtime, onde tais carimbos de data/hora não existiam. -
1582-10-15 00:00:00..1899-12-31 23:59:59.999999. O Databricks Runtime 7.0 resolve deslocamentos de fuso horário corretamente usando dados históricos do IANA TZDB. Em comparação com o Databricks Runtime 7.0, o Databricks Runtime 6.x e abaixo pode resolver deslocamentos de zona de nomes de fuso horário incorretamente em alguns casos, como mostrado no exemplo anterior. -
1900-01-01 00:00:00..2036-12-31 23:59:59.999999. Tanto o Databricks Runtime 7.0 quanto o Databricks Runtime 6.x e abaixo estão em conformidade com o padrão ANSI SQL e usam o calendário gregoriano em operações de data-hora, como obter o dia do mês. -
2037-01-01 00:00:00..9999-12-31 23:59:59.999999. O Databricks Runtime 6.x e versões anteriores podem interpretar os desvios de fuso horário e os desvios de horário de verão de forma incorreta. Databricks Runtime 7.0 não o faz.
Um outro aspeto do mapeamento de nomes de fuso horário para deslocamentos é a sobreposição de carimbos de data/hora locais que pode acontecer devido ao horário de verão (DST) ou mudar para outro deslocamento de fuso horário padrão. Por exemplo, em 3 de novembro de 2019, 02:00:00, a maioria dos estados dos EUA virou os relógios para trás 1 hora para 01:00:00. A marca temporal 2019-11-03 01:30:00 America/Los_Angeles local pode ser mapeada para 2019-11-03 01:30:00 UTC-08:00 ou 2019-11-03 01:30:00 UTC-07:00. Se você não especificar o deslocamento e apenas definir o nome do fuso horário (por exemplo, 2019-11-03 01:30:00 America/Los_Angeles), o Databricks Runtime 7.0 usará o deslocamento anterior, normalmente correspondente a "verão". O comportamento diverge do Databricks Runtime 6.x e versões anteriores que utilizam o offset de inverno. No caso de uma lacuna, em que os relógios saltam para a frente, não há compensação válida. Para uma alteração típica do horário de verão de uma hora, o Spark move esses carimbos de data/hora para o próximo carimbo de data/hora válido correspondente ao horário de verão.
Como você pode ver nos exemplos anteriores, o mapeamento de nomes de fuso horário para compensações é ambíguo e não é um para um. Nos casos em que for possível, ao criar carimbos de data/hora, recomendamos especificar deslocamentos exatos de fuso horário, por exemplo 2019-11-03 01:30:00 UTC-07:00.
Carimbos temporais ANSI SQL e Spark SQL
O padrão ANSI SQL define dois tipos de marcadores de tempo.
-
TIMESTAMP WITHOUT TIME ZONEouTIMESTAMP: Carimbo de data/hora local como (YEAR,MONTH,DAY,HOUR,MINUTE,SECOND) Esses carimbos de data/hora não estão vinculados a nenhum fuso horário e são carimbos de data/hora de relógio de parede. -
TIMESTAMP WITH TIME ZONE: Carimbo de data/hora zoneado como (YEAR,MONTH,DAY,HOUR,MINUTE,SECOND,TIMEZONE_HOUR,TIMEZONE_MINUTE). Esses carimbos de data/hora representam um instante no fuso horário UTC + um deslocamento de fuso horário (em horas e minutos) associado a cada valor.
O deslocamento de fuso horário de a TIMESTAMP WITH TIME ZONE não afeta o ponto físico no tempo que o carimbo de data/hora representa, pois isso é totalmente representado pelo instante de hora UTC dado pelos outros componentes de carimbo de data/hora. Em vez disso, o deslocamento de fuso horário afeta apenas o comportamento padrão de um valor de carimbo de data/hora para exibição, extração de componentes de data/hora (por exemplo, EXTRACT) e outras operações que exigem conhecer um fuso horário, como adicionar meses a um carimbo de data/hora.
O Spark SQL define o tipo de carimbo de data/hora como TIMESTAMP WITH SESSION TIME ZONE, que é uma combinação dos campos (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, SESSION TZ) onde os campos de YEAR a SECOND identificam um momento no tempo no fuso horário UTC, e onde o fuso horário da sessão é obtido da configuração SQL spark.sql.session.timeZone. O fuso horário da sessão pode ser definido como:
- Deslocamento de zona
(+|-)HH:mm. Este formulário permite-lhe definir inequivocamente um ponto físico no tempo. - Nome do fuso horário na forma de ID
area/cityde região , comoAmerica/Los_Angeles. Esta forma de informação de fuso horário sofre de alguns dos problemas descritos anteriormente, como o conflito de marcas temporais locais. No entanto, cada instante de hora UTC é inequivocamente associado a um deslocamento de fuso horário para qualquer ID de região e, como resultado, cada carimbo de data/hora com um fuso horário baseado em ID de região pode ser inequivocamente convertido em um carimbo de data/hora com um deslocamento de zona. Por padrão, o fuso horário da sessão é definido como o fuso horário padrão da máquina virtual Java.
Spark TIMESTAMP WITH SESSION TIME ZONE é diferente de:
-
TIMESTAMP WITHOUT TIME ZONE, porque um valor desse tipo pode ser mapeado para vários instantes de tempo físicos, mas qualquer valor deTIMESTAMP WITH SESSION TIME ZONEé um instante de tempo físico concreto. O tipo SQL pode ser emulado usando um deslocamento de fuso horário fixo em todas as sessões, por exemplo, UTC+0. Nesse caso, podes considerar os marcadores temporais no UTC como marcadores locais. -
TIMESTAMP WITH TIME ZONE, porque de acordo com o padrão SQL, os valores de coluna do tipo podem ter diferentes deslocamentos de fuso horário. Isso não é suportado pelo Spark SQL.
Você deve observar que timestamps associados a um fuso horário global, cujo escopo é a sessão, não são algo recém-inventado pelo Spark SQL. RDBMSs, como Oracle, fornecem um tipo semelhante para marcações de tempo: TIMESTAMP WITH LOCAL TIME ZONE.
Construir datas e carimbos de hora
O Spark SQL fornece alguns métodos para construir valores de carimbo de data e hora:
- Construtores padrão sem parâmetros:
CURRENT_TIMESTAMP()eCURRENT_DATE(). - De outros tipos primitivos do Spark SQL, como
INT,LONGeSTRING - De tipos externos como datetime do Python ou classes Java
java.time.LocalDate/Instant. - Desserialização de fontes de dados como CSV, JSON, Avro, Parquet, ORC e assim por diante.
A função MAKE_DATE introduzida no Databricks Runtime 7.0 usa três parâmetros—YEAR, MONTH, e DAY—e constrói um valor de DATE. Todos os parâmetros de entrada são implicitamente convertidos para o INT tipo sempre que possível. A função verifica se as datas resultantes são datas válidas no calendário gregoriano proléptico, caso contrário, retorna NULL. Por exemplo:
spark.createDataFrame([(2020, 6, 26), (1000, 2, 29), (-44, 1, 1)],['Y', 'M', 'D']).createTempView('YMD')
df = sql('select make_date(Y, M, D) as date from YMD')
df.printSchema()
root
|-- date: date (nullable = true)
Para imprimir o conteúdo do DataFrame, chame a ação show(), que converte datas em strings nos executores e envia as strings para o driver, onde são exibidas no console.
df.show()
+-----------+
| date|
+-----------+
| 2020-06-26|
| null|
|-0044-01-01|
+-----------+
Da mesma forma, você pode construir valores de carimbo de data/hora usando as MAKE_TIMESTAMP funções. Como MAKE_DATE, ele executa a mesma validação para campos de data e, adicionalmente, aceita campos de tempo HORA (0-23), MINUTO (0-59) e SEGUNDO (0-60). SECOND tem o tipo Decimal(precisão = 8, escala = 6) porque os segundos podem ser passados com a parte fracionária até a precisão de microssegundos. Por exemplo:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30.123456), \
(1582, 10, 10, 0, 1, 2.0001), (2019, 2, 29, 9, 29, 1.0)],['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND'])
df.show()
+----+-----+---+----+------+---------+
|YEAR|MONTH|DAY|HOUR|MINUTE| SECOND|
+----+-----+---+----+------+---------+
|2020| 6| 28| 10| 31|30.123456|
|1582| 10| 10| 0| 1| 2.0001|
|2019| 2| 29| 9| 29| 1.0|
+----+-----+---+----+------+---------+
df.selectExpr("make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) as MAKE_TIMESTAMP")
ts.printSchema()
root
|-- MAKE_TIMESTAMP: timestamp (nullable = true)
Quanto às datas, imprima o conteúdo do ts DataFrame usando a ação show(). Da mesma forma, show() converte carimbos de data/hora em strings, mas agora leva em conta o fuso horário da sessão definido pela spark.sql.session.timeZone configuração SQL.
ts.show(truncate=False)
+--------------------------+
|MAKE_TIMESTAMP |
+--------------------------+
|2020-06-28 10:31:30.123456|
|1582-10-10 00:01:02.0001 |
|null |
+--------------------------+
O Spark não consegue criar o último timestamp porque esta data não é válida: 2019 não é um ano bissexto.
Você pode notar que não há informações de fuso horário no exemplo anterior. Nesse caso, o Spark retira um fuso horário da configuração SQL spark.sql.session.timeZone e o aplica nas invocações de função. Você também pode escolher um fuso horário diferente passando-o como o último parâmetro de MAKE_TIMESTAMP. Aqui está um exemplo:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30, 'UTC'),(1582, 10, 10, 0, 1, 2, 'America/Los_Angeles'), \
(2019, 2, 28, 9, 29, 1, 'Europe/Moscow')], ['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND', 'TZ'])
df = df.selectExpr('make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TZ) as MAKE_TIMESTAMP')
df = df.selectExpr("date_format(MAKE_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss VV') AS TIMESTAMP_STRING")
df.show(truncate=False)
+---------------------------------+
|TIMESTAMP_STRING |
+---------------------------------+
|2020-06-28 13:31:00 Europe/Moscow|
|1582-10-10 10:24:00 Europe/Moscow|
|2019-02-28 09:29:00 Europe/Moscow|
+---------------------------------+
Como demonstra o exemplo, o Spark leva em conta os fusos horários especificados, mas ajusta todos os carimbos de data/hora locais para o fuso horário da sessão. Os fusos horários originais passados para a MAKE_TIMESTAMP função são perdidos porque o tipo assume que todos os valores pertencem a um fuso TIMESTAMP WITH SESSION TIME ZONE horário e nem mesmo armazena um fuso horário por cada valor. De acordo com a definição do TIMESTAMP WITH SESSION TIME ZONE, o Spark armazena carimbos de data/hora locais no fuso horário UTC e utiliza o fuso horário da sessão ao extrair campos de data-hora ou converter os carimbos de data/hora em cadeias de caracteres.
Além disso, os carimbos de data/hora podem ser construídos a partir do tipo LONG usando fundição. Se uma coluna LONG contiver o número de segundos desde a época 1970-01-01 00:00:00Z, ela pode ser convertida em um Spark SQL TIMESTAMP:
select CAST(-123456789 AS TIMESTAMP);
1966-02-02 05:26:51
Infelizmente, essa abordagem não permite especificar a parte fracionária de segundos.
Outra maneira é construir datas e carimbos de data/hora a partir de valores do tipo STRING. Você pode fazer literais usando palavras-chave especiais:
select timestamp '2020-06-28 22:17:33.123456 Europe/Amsterdam', date '2020-07-01';
2020-06-28 23:17:33.123456 2020-07-01
Como alternativa, pode usar casting que pode aplicar para todos os valores numa coluna.
select cast('2020-06-28 22:17:33.123456 Europe/Amsterdam' as timestamp), cast('2020-07-01' as date);
2020-06-28 23:17:33.123456 2020-07-01
As cadeias de caracteres de carimbo de data/hora de entrada são interpretadas como carimbos de data/hora locais no fuso horário especificado ou no fuso horário da sessão se um fuso horário for omitido na cadeia de caracteres de entrada. Strings com padrões incomuns podem ser convertidas em timestamp usando a função to_timestamp(). Os padrões suportados são descritos em Padrões de data/hora para formatação e análise:
select to_timestamp('28/6/2020 22.17.33', 'dd/M/yyyy HH.mm.ss');
2020-06-28 22:17:33
Se você não especificar um padrão, a função se comportará de forma semelhante ao CAST.
Para facilidade de uso, o Spark SQL reconhece valores especiais de cadeia de caracteres em todos os métodos que suportam uma cadeia de caracteres e retornam um timestamp ou data.
-
epoché um alias para data1970-01-01ou timestamp1970-01-01 00:00:00Z. -
nowé a marca temporal ou data atual no fuso horário da sessão. Dentro de uma única consulta, ele sempre produz o mesmo resultado. -
todayé o início da data atual para oTIMESTAMPtipo ou apenas a data atual para oDATEtipo. -
tomorrowé o início do dia seguinte para carimbos de data/hora ou apenas o dia seguinte para tipoDATE. -
yesterdayé o dia anterior ao atual ou o início para o tipoTIMESTAMP.
Por exemplo:
select timestamp 'yesterday', timestamp 'today', timestamp 'now', timestamp 'tomorrow';
2020-06-27 00:00:00 2020-06-28 00:00:00 2020-06-28 23:07:07.18 2020-06-29 00:00:00
select date 'yesterday', date 'today', date 'now', date 'tomorrow';
2020-06-27 2020-06-28 2020-06-28 2020-06-29
O Spark permite criar Datasets a partir de coleções existentes de objetos externos no nível do driver e criar colunas dos tipos correspondentes. O Spark converte instâncias de tipos externos em representações internas semanticamente equivalentes. Por exemplo, para criar um Dataset com as colunas DATE e TIMESTAMP a partir de coleções Python, poderá usar:
import datetime
df = spark.createDataFrame([(datetime.datetime(2020, 7, 1, 0, 0, 0), datetime.date(2020, 7, 1))], ['timestamp', 'date'])
df.show()
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
O PySpark converte os objetos de data-hora do Python em representações internas do Spark SQL no lado do driver usando o fuso horário do sistema, que pode ser diferente da configuração spark.sql.session.timeZonede fuso horário da sessão do Spark. Os valores internos não contêm informações sobre o fuso horário original. As operações futuras sobre os valores de data e carimbo de data/hora paralelizados levam em consideração apenas o fuso horário definido nas sessões do Spark SQL, de acordo com a TIMESTAMP WITH SESSION TIME ZONE definição do tipo.
De maneira semelhante, o Spark reconhece os seguintes tipos como tipos de data e hora externos nas APIs Java e Scala:
-
java.sql.Dateejava.time.LocalDatecomo tipos externos para oDATEtipo -
java.sql.Timestampejava.time.Instantpara tipoTIMESTAMP.
Há uma diferença entre java.sql.* e java.time.* tipos.
java.time.LocalDate e java.time.Instant foram adicionados em Java 8, e os tipos são baseados no calendário gregoriano proléptico – o mesmo calendário que é usado pelo Databricks Runtime 7.0 e superior.
java.sql.Date e java.sql.Timestamp tem outro calendário por baixo – o calendário híbrido (Juliano + Gregoriano desde 1582-10-15), que é o mesmo que o calendário legado usado pelo Databricks Runtime 6.x e abaixo. Devido aos diferentes sistemas de calendário, o Spark tem que executar operações adicionais durante as conversões para representações internas do Spark SQL e rebasear datas/carimbos de data/hora de entrada de um calendário para outro. A operação de rebase implica uma ligeira sobrecarga para carimbos de data/hora modernos após o ano de 1900 e pode ser ainda mais significativa para carimbos de data/hora antigos.
O exemplo a seguir mostra como criar marcadores temporais a partir de coleções Scala. O primeiro exemplo constrói um java.sql.Timestamp objeto a partir de uma cadeia de caracteres. O valueOf método interpreta as cadeias de caracteres de entrada como um carimbo de data/hora local no fuso horário padrão da JVM, que pode ser diferente do fuso horário da sessão do Spark. Se você precisar construir instâncias de java.sql.Timestamp ou java.sql.Date em fuso horário específico, dê uma olhada em java.text.SimpleDateFormat (e seu método setTimeZone) ou java.util.Calendar.
Seq(java.sql.Timestamp.valueOf("2020-06-29 22:41:30"), new java.sql.Timestamp(0)).toDF("ts").show(false)
+-------------------+
|ts |
+-------------------+
|2020-06-29 22:41:30|
|1970-01-01 03:00:00|
+-------------------+
Seq(java.time.Instant.ofEpochSecond(-12219261484L), java.time.Instant.EPOCH).toDF("ts").show
+-------------------+
| ts|
+-------------------+
|1582-10-15 11:12:13|
|1970-01-01 03:00:00|
+-------------------+
Da mesma forma, você pode criar uma DATE coluna a partir de coleções de java.sql.Date ou java.sql.LocalDate. A paralelização de java.sql.LocalDate instâncias é totalmente independente da sessão do Spark ou dos fusos horários padrão da JVM, mas o mesmo não acontece com a paralelização de java.sql.Date instâncias. Há nuances:
-
java.sql.Dateinstâncias representam datas locais no fuso horário padrão da JVM no driver. - Para conversões corretas para valores Spark SQL, o fuso horário padrão da JVM no driver e nos executores deve ser o mesmo.
Seq(java.time.LocalDate.of(2020, 2, 29), java.time.LocalDate.now).toDF("date").show
+----------+
| date|
+----------+
|2020-02-29|
|2020-06-29|
+----------+
Para evitar problemas relacionados com o calendário e fuso horário, recomendamos tipos java.sql.LocalDate/Instant Java 8 como tipos externos na paralelização de coleções Java/Scala de data e hora ou datas.
Colete datas e carimbos temporais
A operação inversa de paralelização é recolher datas e marcas temporais dos executores de volta para o controlador e devolver uma coleção de tipos externos. No exemplo acima, pode puxar o DataFrame de volta para o driver usando a ação collect().
df.collect()
[Row(timestamp=datetime.datetime(2020, 7, 1, 0, 0), date=datetime.date(2020, 7, 1))]
O Spark transfere valores internos das colunas de datas e timestamps como instantes de tempo no fuso horário UTC dos executores para o driver. As conversões para objetos datetime Python são realizadas no driver, utilizando o fuso horário do sistema, e não o fuso horário da sessão Spark SQL.
collect() é diferente da show() ação descrita na seção anterior.
show() usa o fuso horário da sessão para converter timestamps em cadeias de caracteres e recolhe as cadeias de caracteres resultantes no driver.
Nas APIs Java e Scala, o Spark executa as seguintes conversões por padrão:
- Os valores do Spark SQL
DATEsão convertidos em instâncias dojava.sql.Date. - Os valores do Spark SQL
TIMESTAMPsão convertidos em instâncias dojava.sql.Timestamp.
Ambas as conversões são executadas no fuso horário padrão da JVM no driver. Dessa forma, para ter os mesmos campos de data-hora que você pode obter usando Date.getDay(), getHour(), e assim por diante, e usando as funções DAYdo Spark SQL , HOURo fuso horário padrão da JVM no driver e o fuso horário da sessão nos executores devem ser os mesmos.
Da mesma forma que a criação de datas/carimbos de data/hora a partir de java.sql.Date/Timestamp, o Databricks Runtime 7.0 realiza o rebaseamento do calendário gregoriano proléptico para o calendário híbrido (Juliano + Gregoriano). Esta operação é quase gratuita para datas modernas (após o ano de 1582) e carimbos de data/hora (após o ano de 1900), mas pode trazer alguma sobrecarga para datas antigas e carimbos de data/hora.
Você pode evitar esses problemas relacionados ao calendário e pedir ao Spark para retornar java.time tipos, que foram adicionados desde o Java 8. Se você definir a configuração spark.sql.datetime.java8API.enabled do SQL como true, a Dataset.collect() ação retornará:
-
java.time.LocalDatepara o tipo Spark SQLDATE -
java.time.Instantpara o tipo Spark SQLTIMESTAMP
Agora, as conversões não sofrem com os problemas relacionados ao calendário porque os tipos Java 8 e Databricks Runtime 7.0 e superior são baseados no calendário gregoriano proléptico. A collect() ação não depende do fuso horário padrão da JVM. As conversões de timestamp não dependem de fuso horário. As conversões de data usam o fuso horário da sessão da configuração SQL spark.sql.session.timeZone. Por exemplo, considere um Dataset com DATE e TIMESTAMP colunas, com o fuso horário padrão da JVM definido como Europe/Moscow e o fuso horário da sessão definido como America/Los_Angeles.
java.util.TimeZone.getDefault
res1: java.util.TimeZone = sun.util.calendar.ZoneInfo[id="Europe/Moscow",...]
spark.conf.get("spark.sql.session.timeZone")
res2: String = America/Los_Angeles
df.show
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
A ação show() imprime o carimbo de data/hora à hora da sessão America/Los_Angeles, mas se se recolher Dataset, ele será convertido em java.sql.Timestamp e o método toString imprimirá Europe/Moscow:
df.collect()
res16: Array[org.apache.spark.sql.Row] = Array([2020-07-01 10:00:00.0,2020-07-01])
df.collect()(0).getAs[java.sql.Timestamp](0).toString
res18: java.sql.Timestamp = 2020-07-01 10:00:00.0
Na realidade, o carimbo de data/hora local 2020-07-01 00:00:00 corresponde a 2020-07-01T07:00:00Z na UTC. Você pode observar que, se você habilitar a API Java 8 e coletar o Dataset:
df.collect()
res27: Array[org.apache.spark.sql.Row] = Array([2020-07-01T07:00:00Z,2020-07-01])
Pode converter um objeto java.time.Instant para qualquer data/hora local, independentemente do fuso horário global da JVM. Esta é uma das vantagens de java.time.Instant sobre java.sql.Timestamp. O primeiro requer a alteração da configuração global da JVM, que afeta outros timestamps na mesma JVM. Portanto, se os seus aplicativos processarem datas ou timestamps em diferentes fusos horários, e os aplicativos não devem entrar em conflito entre si na recolha de dados para o controlador usando a API de Java ou Scala Dataset.collect(), recomendamos mudar para a API do Java 8 usando a configuração SQL spark.sql.datetime.java8API.enabled.