Computação
A computação do Azure Databricks refere-se à seleção de recursos de computação disponíveis no espaço de trabalho do Azure Databricks. Os usuários precisam de acesso à computação para executar cargas de trabalho de engenharia de dados, ciência de dados e análise de dados, como pipelines de ETL de produção, análise de streaming, análise ad-hoc e aprendizado de máquina.
Os usuários podem se conectar à computação existente ou criar uma nova computação se tiverem as permissões adequadas.
Você pode visualizar a computação à qual tem acesso usando a seção Computação do espaço de trabalho:
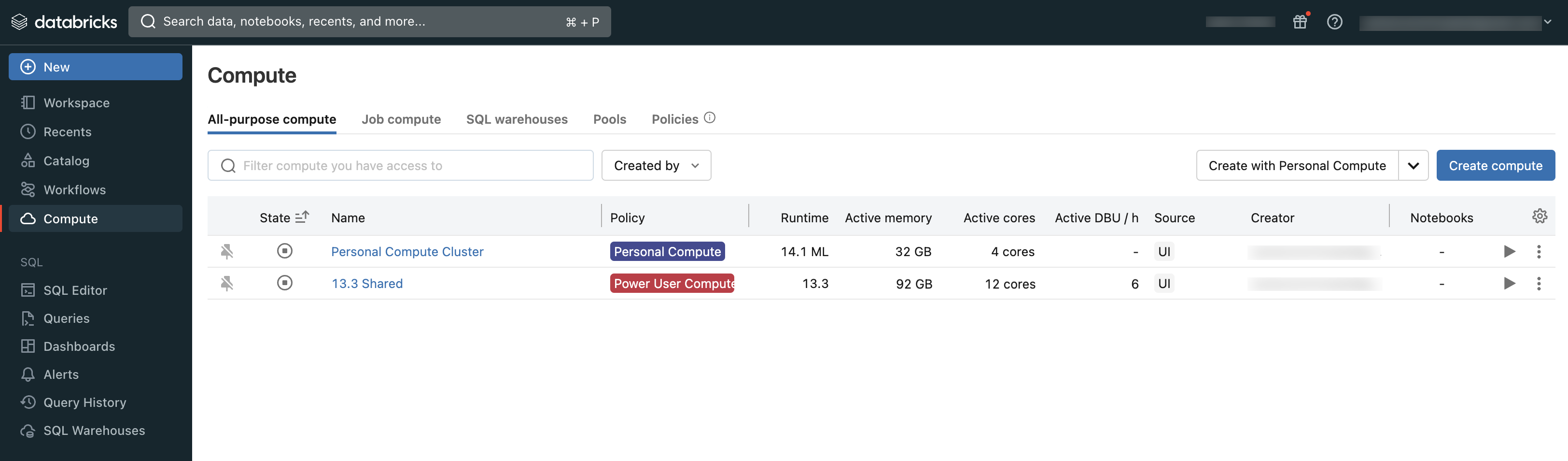
Tipos de computação
Estes são os tipos de computação disponíveis no Azure Databricks:
Computação sem servidor para notebook: computação escalável sob demanda usada para executar código SQL e Python em blocos de anotações.
Computação sem servidor para trabalhos: computação escalável e sob demanda usada para executar seus trabalhos do Databricks sem configurar e implantar a infraestrutura.
Computação multiuso: computação provisionada usada para analisar dados em notebooks. Você pode criar, encerrar e reiniciar essa computação usando a interface do usuário, CLI ou API REST.
Computação de trabalhos: computação provisionada usada para executar trabalhos automatizados. O agendador de tarefas do Azure Databricks cria automaticamente uma computação de trabalho sempre que um trabalho é configurado para ser executado em uma nova computação. A computação termina quando o trabalho é concluído. Não é possível reiniciar uma computação de trabalho. Consulte Configurar computação para trabalhos.
Pools de instâncias: calcule com instâncias ociosas e prontas para uso, usadas para reduzir os tempos de início e dimensionamento automático. Você pode criar essa computação usando a interface do usuário, CLI ou API REST.
Armazéns SQL sem servidor: computação elástica sob demanda usada para executar comandos SQL em objetos de dados no editor SQL ou blocos de anotações interativos. Você pode criar armazéns SQL usando a interface do usuário, CLI ou API REST.
Armazéns SQL clássicos: usados para executar comandos SQL em objetos de dados no editor SQL ou blocos de anotações interativos. Você pode criar armazéns SQL usando a interface do usuário, CLI ou API REST.
Os artigos nesta seção descrevem como trabalhar com recursos de computação usando a interface do usuário do Azure Databricks. Para outros métodos, consulte O que é a CLI do Databricks? e a referência da API REST do Databricks.
Databricks Runtime
Databricks Runtime é o conjunto de componentes principais que são executados em sua computação. O Databricks Runtime é uma configuração configurável em todos os fins de computação de trabalhos, mas selecionada automaticamente em armazéns SQL.
Cada versão do Databricks Runtime inclui atualizações que melhoram a usabilidade, o desempenho e a segurança da análise de big data. O Databricks Runtime em sua computação adiciona muitos recursos, incluindo:
- Delta Lake, uma camada de armazenamento de última geração construída sobre o Apache Spark que fornece transações ACID, layouts e índices otimizados e melhorias no mecanismo de execução para a construção de pipelines de dados. Veja O que é Delta Lake?.
- Bibliotecas Java, Scala, Python e R instaladas.
- Ubuntu e suas bibliotecas de sistema que o acompanham.
- Bibliotecas de GPU para clusters habilitados para GPU.
- Serviços do Azure Databricks que se integram com outros componentes da plataforma, como blocos de anotações, trabalhos e gerenciamento de cluster.
Para obter informações sobre o conteúdo de cada versão de tempo de execução, consulte as notas de versão.
Controle de versão em tempo de execução
As versões do Databricks Runtime são lançadas regularmente:
- As versões de suporte de longo prazo são representadas por um qualificador LTS (por exemplo, 3,5 LTS). Para cada versão principal, declaramos uma versão de recurso "canônica", para a qual fornecemos três anos completos de suporte. Consulte Ciclos de vida de suporte do Databricks para obter mais informações.
- As versões principais são representadas por um incremento no número da versão que precede o ponto decimal (o salto de 3,5 para 4,0, por exemplo). Eles são liberados quando há grandes alterações, algumas das quais podem não ser compatíveis com versões anteriores.
- As versões de recursos são representadas por um incremento no número da versão que segue o ponto decimal (o salto de 3,4 para 3,5, por exemplo). Cada versão principal inclui várias versões de recursos. As versões de recursos são sempre compatíveis com versões anteriores dentro de sua versão principal.