Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo explica como criar um recurso de computação atribuído a um grupo usando o modo de acesso dedicado .
O modo de acesso de grupo dedicado permite que os usuários obtenham a eficiência operacional de um cluster de modo de acesso padrão e, ao mesmo tempo, suportem com segurança idiomas e cargas de trabalho que não são suportados pelo modo de acesso padrão, como Databricks Runtime for ML, RDD APIs e R.
Requerimentos
Para usar o modo de acesso de grupo dedicado:
- O espaço de trabalho deve estar habilitado para o Catálogo Unity.
- Você deve usar o Databricks Runtime 15.4 ou superior.
- O grupo atribuído deve ter permissões de
CAN MANAGEnuma pasta no espaço de trabalho onde pode manter cadernos, experimentos de ML e outros artefatos de trabalho usados pelo cluster do grupo.
O que é o modo de acesso dedicado?
O modo de acesso dedicado é a versão mais recente do modo de acesso de utilizador único. Com acesso dedicado, um recurso de computação pode ser atribuído a um único usuário ou grupo, permitindo apenas que o(s) usuário(s) atribuído(s) acesse(m) o recurso de computação.
Quando um usuário está conectado a um recurso de computação dedicado a um grupo (um cluster de grupo), as permissões do usuário reduzem automaticamente o escopo para as permissões do grupo, permitindo que o usuário compartilhe o recurso com segurança com os outros membros do grupo.
Criar um recurso de computação dedicado a um grupo
- No seu espaço de trabalho Azure Databricks, vá a Compute e clique em Create compute.
- Expanda a seção Avançado .
- Em Modo de acesso, clique em Manual e selecione Dedicado (anteriormente: Usuário único) no menu suspenso.
- No campo
Usuário único ou grupo, selecione o grupo que deseja atribuir a este recurso. - Configure as outras configurações de computação desejadas e clique em Criar.
Práticas recomendadas para gerenciar clusters de grupo
Como as permissões de usuário têm como escopo o grupo ao usar clusters de grupo, o Databricks recomenda a criação de uma pasta /Workspace/Groups/<groupName> para cada grupo que você planeja usar com um cluster de grupo. Em seguida, atribua permissões CAN MANAGE à pasta para o grupo. Isso permite que os grupos evitem erros de permissão. Todos os blocos de anotações e ativos de espaço de trabalho do grupo devem ser gerenciados na pasta do grupo.
Você também deve modificar as seguintes cargas de trabalho para serem executadas em clusters de grupo:
- MLflow: Certifique-se de executar o notebook a partir da pasta do grupo ou executar
mlflow.set_tracking_uri("/Workspace/Groups/<groupName>"). - AutoML: defina o parâmetro opcional
experiment_dircomo“/Workspace/Groups/<groupName>”para os seus processos AutoML. -
dbutils.notebook.run: Verifique se o grupo tem permissãoREADno bloco de anotações em execução.
Comportamento de gestão de permissões em agrupamentos de grupo
Todos os comandos, consultas e outras ações executadas em um cluster de grupo usam as permissões atribuídas ao grupo, não o usuário individual.
As permissões de usuário individuais não podem ser impostas porque todos os membros do grupo têm acesso total às APIs do Spark e ao ambiente de computação compartilhado. Se as permissões baseadas no usuário fossem aplicadas, um membro poderia consultar dados restritos e outro membro sem acesso ainda poderia recuperar os resultados por meio do ambiente compartilhado. Portanto, o próprio grupo, não o usuário que é membro do grupo, deve ter as permissões necessárias para executar a ação com êxito.
Por exemplo, o grupo precisa de permissão explícita para consultar uma tabela, acessar um escopo ou segredo secreto, usar uma credencial de conexão do Catálogo Unity, acessar uma pasta Git ou criar um objeto de espaço de trabalho.
Exemplo de permissões de grupo
Quando você cria um objeto de dados usando o cluster de grupo, o grupo é atribuído como proprietário do objeto.
Por exemplo, se tiveres um computador portátil anexado a um grupo de cluster e executares o seguinte comando:
use catalog main;
create schema group_cluster_group_schema;
Em seguida, execute esta consulta para verificar o proprietário do esquema:
describe schema group_cluster_group_schema;
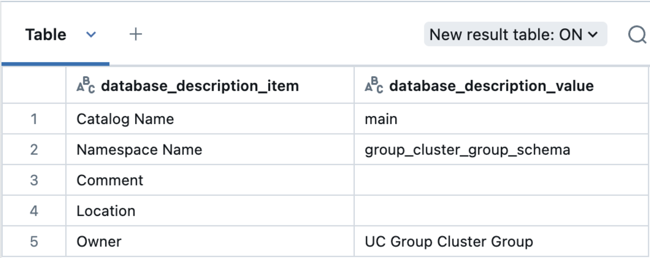
Grupo de auditoria dedicado à atividade de computação
Há duas identidades principais envolvidas quando um cluster de grupo executa uma carga de trabalho:
- O usuário que está executando a carga de trabalho no cluster de grupo
- O grupo cujas permissões são usadas para executar as ações reais da carga de trabalho
A tabela do sistema de log de auditoria registra essas identidades sob os seguintes parâmetros:
-
identity_metadata.run_by: O usuário de autenticação que executa a ação -
identity_metadata.run_as: O grupo de autorização cujas permissões são usadas para a ação.
A consulta de exemplo a seguir extrai os metadados de identidade para uma ação executada com o cluster de grupo:
select action_name, event_time, user_identity.email, identity_metadata
from system.access.audit
where user_identity.email = "uc-group-cluster-group" AND service_name = "unityCatalog"
order by event_time desc limit 100;
Consulte a referência da tabela do sistema de log de auditoria para obter exemplos de consultas. Consulte Referência da tabela do sistema de log de auditoria.
Limitações conhecidas
O acesso a grupos dedicados tem as seguintes limitações:
- Os trabalhos criados usando a API e o SDK não podem receber acesso ao grupo. Isso ocorre porque o parâmetro do trabalho
run_assuporta apenas um único utilizador ou principal de serviço. - Os trabalhos que usam o Git falharão porque o diretório temporário que o trabalho usa para extrair o repositório Git não permite escrita. Em vez disso , use pastas Git .
- As tabelas do sistema de linhagem não registram o
identity_metadata.run_as(o grupo autorizador) ouidentity_metadata.run_by(o usuário de autenticação) para cargas de trabalho executadas em um cluster de grupo. - Os logs de auditoria entregues ao armazenamento do cliente não registam o
identity_metadata.run_as(grupo autorizador) ou oidentity_metadata.run_by(utilizador autenticador) para cargas de trabalho executadas em um cluster de grupo. Você deve usar a tabelasystem.access.auditpara exibir os metadados de identidade. - Quando anexado a um cluster de grupo, o Catalog Explorer não filtra por ativos acessíveis apenas ao grupo.
- Os gerentes de grupo que não são membros do grupo não podem criar, editar ou excluir clusters de grupo. Apenas os administradores do espaço de trabalho e os membros do grupo podem fazê-lo.
- Se um grupo for renomeado, você deverá atualizar manualmente todas as políticas de computação que fazem referência ao nome do grupo.
- Não há suporte para clusters de grupo para espaços de trabalho com ACLs desabilitadas (isWorkspaceAclsEnabled == false) devido à falta inerente de segurança e controles de acesso a dados quando as ACLs de espaço de trabalho estão desabilitadas.
- O
%runcomando e outras ações executadas no contexto do bloco de anotações sempre usam as permissões do usuário em vez das permissões do grupo. Isso ocorre porque essas ações são manipuladas pelo ambiente do bloco de anotações, não pelo ambiente do cluster. Comandos alternativos, comodbutils.notebook.run()são executados no cluster e, portanto, usam as permissões do grupo. - A
is_member(<group>)função retornafalsequando invocada em um cluster de grupo porque o grupo não é um membro de si mesmo. Para verificar corretamente a filiação em ambos os grupos e outros modos de acesso, useis_member(<group>) OR current_user() == <group>. - Não há suporte para a criação e acesso a pontos de extremidade de serviço de modelo.
- Não há suporte para a criação e acesso a pontos de extremidade ou índices de pesquisa vetorial.
- A exclusão de arquivos e pastas não é suportada em clusters de grupo.
- A interface do usuário de carregamento de arquivo não oferece suporte a clusters de grupo.