Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Esta página explica como configurar o ambiente serverless para notebooks e tarefas de trabalho. Para portáteis, use o painel lateral Ambiente para selecionar um ambiente base, instalar dependências, configurar memória e aplicar políticas de uso. Para tarefas de trabalho, configura o ambiente quando crias ou editas uma tarefa.
Para expandir o painel lateral Ambiente, clique no botão ![]() à direita do bloco de notas.
à direita do bloco de notas.
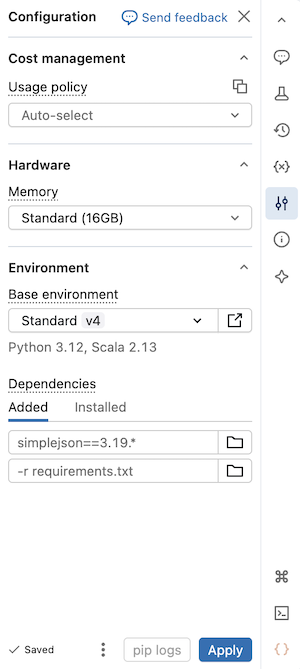
Selecione um ambiente base
Um ambiente base determina as bibliotecas pré-instaladas e a versão do ambiente disponível para o seu portátil serverless. O seletor de ambiente base no painel lateral de Ambiente é onde escolhes o teu ambiente. Para ver detalhes sobre cada versão de ambiente, consulte Versões de ambiente sem servidor. A Databricks recomenda usar a versão mais recente para obter as funcionalidades mais recentes do notebook.
O seletor de ambiente Base inclui as seguintes opções:
- Standard: O ambiente base serverless predefinido com bibliotecas fornecidas pelo Databricks.
- ML: Um ambiente base com os pacotes de Python e sistema do Databricks Runtime for Machine Learning pré-instalados. Utilize este ambiente para migrar cargas de trabalho clássicas do Databricks Runtime for Machine Learning para computação sem servidor. Ver ambiente base de ML.
- IA: Um ambiente base otimizado para IA com bibliotecas de machine learning (ML) pré-instaladas. Esta opção aparece apenas quando um acelerador (GPU) é selecionado.
-
Mais: Expande para mostrar opções adicionais:
- Versões anteriores de ambientes Standard, ML e IA.
- Personalizado: Especifique um ambiente personalizado usando um ficheiro YAML.
- Ambientes de espaço de trabalho: Lista todos os ambientes base compatíveis configurados para o seu espaço de trabalho por um administrador.
Para selecionar um ambiente base:
- Na interface do utilizador do caderno, clique no painel lateral Ambiente
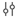 .
. - Em Ambiente Base, selecione um ambiente no menu suspenso.
- Clique em Aplicar.
Adicionar dependências ao bloco de notas
Como o serverless não suporta políticas de computação nem scripts de inicialização, tem de instalar dependências personalizadas através do painel lateral Ambiente. Podes instalar dependências individualmente ou usar um ambiente base partilhado para instalar múltiplas dependências.
O Azure Databricks armazena em cache o ambiente virtual do seu portátil, para que as dependências não se reinstalem sempre que reabre um caderno ou retoma após inatividade. Tarefas de trabalho que partilham o mesmo conjunto de dependências também beneficiam deste cache dentro de uma execução.
Para instalar individualmente uma dependência:
Na interface do utilizador do caderno, clique no painel lateral Ambiente
.Na seção Dependências , clique em Adicionar Dependência e insira o caminho da dependência no campo. Você pode especificar uma dependência em qualquer formato que seja válido em um arquivo requirements.txt . Ficheiros wheel do Python ou ficheiros de projeto Python (por exemplo, o diretório que contém um
pyproject.tomlou umsetup.py) podem ser localizados em ficheiros de armazém de trabalho ou volumes do Unity Catalog.- Se estiver usando um arquivo de espaço de trabalho, o caminho deve ser absoluto e começar com
/Workspace/. - Se estiver usando um arquivo em um volume do Catálogo Unity, o caminho deverá estar no seguinte formato:
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.
- Se estiver usando um arquivo de espaço de trabalho, o caminho deve ser absoluto e começar com
Clique em Apply para instalar as dependências e reiniciar o processo Python.
Important
Não instale o PySpark ou qualquer biblioteca que instale o PySpark como uma dependência em seus notebooks sem servidor. Isso interromperá sua sessão e resultará em um erro. Se isso ocorrer, remova a biblioteca e redefina seu ambiente.
Para ver dependências instaladas, clique no separador Instalado no painel lateral de Ambientes . Abra os registos de instalação do pip para o ambiente do bloco de notas clicando em pip logs na parte inferior do painel.
Note
Os administradores da área de trabalho podem configurar repositórios de pacotes privados ou autenticados como origem predefinida do pip para notebooks e tarefas serverless. Isto permite aos utilizadores instalar pacotes a partir de repositórios internos sem especificar index-url ou extra-index-url. Consulte Configure repositórios de pacotes Python padrão.
Criar uma especificação de ambiente personalizada
Você pode criar e reutilizar especificações de ambiente personalizadas.
- Num portátil serverless, seleciona um ambiente base e instala as dependências que quiseres.
- Clique no botão do menu kebab
 na parte inferior do painel de ambiente e, em seguida, clique em Exportar ambiente.
na parte inferior do painel de ambiente e, em seguida, clique em Exportar ambiente. - Salve a especificação como um arquivo de espaço de trabalho ou em um volume de catálogo Unity. Certifica-te de que tens permissão para escrever no destino, caso contrário a exportação falha com um
Forbiddenerro.
Para utilizar a sua especificação de ambiente personalizada num notebook, selecione Personalizado no menu pendente Ambiente base e, em seguida, utilize o ícone de pasta ![]() para selecionar o seu ficheiro YAML.
para selecionar o seu ficheiro YAML.
Crie ferramentas comuns para partilhar no seu espaço de trabalho
Este exemplo armazena um utilitário num ficheiro do espaço de trabalho e instala-o como uma dependência de um notebook sem servidor:
Crie uma pasta com a seguinte estrutura. Certifique-se de que outros utilizadores têm acesso de leitura a este caminho:
helper_utils/ ├── helpers/ │ └── __init__.py # your common functions live here ├── pyproject.tomlPreencha
pyproject.tomlassim:[project] name = "common_utils" version = "0.1.0"Adicione uma função ao
init.pyarquivo. Por exemplo:def greet(name: str) -> str: return f"Hello, {name}!"Na interface do bloco de notas, clique no painel lateral Ambiente

Na seção Dependências , clique em Adicionar Dependência e insira o caminho do arquivo util. Por exemplo:
/Workspace/helper_utils.Clique em Aplicar.
Agora você pode usar a função em seu notebook:
from helpers import greet
print(greet('world'))
Isto resulta como:
Hello, world!
Utilize Tempo de Execução de IA (GPU sem servidor)
Important
O tempo de execução da IA está em Pré-visualização Pública.
Siga estes passos para configurar o AI Runtime, alimentado por computação GPU serverless, no seu portátil Azure Databricks:
- A partir de um portátil, clique no menu suspenso de computação no topo e selecione GPU Serverless.
- Clique no para abrir o painel lateral Ambiente.
- Selecione A10 no campo Acelerador .
- No ambiente Base, selecione Standard para o ambiente predefinido ou AI para o ambiente otimizado para IA com bibliotecas de machine learning (ML) pré-instaladas.
- Clica em Aplicar e depois Confirma que queres aplicar o AI Runtime ao ambiente do teu portátil.
Para mais detalhes, consulte AI Runtime.
Use computação sem servidor de alta capacidade de memória
Se encontrar erros de falta de memória no seu portátil, configure o portátil para usar um tamanho de memória maior. Esta definição de tamanho de memória aumenta o tamanho da memória REPL usada ao executar código no caderno. Não afeta o tamanho da memória da sessão Spark. O uso sem servidor com alta memória tem uma taxa de emissão de DBU mais alta do que a memória padrão.
As opções de memória disponíveis são:
- Padrão: 16 GB de memória total.
- Alta: 32 GB de memória total.
Para configurar a configuração de memória do computador portátil:
- Na interface do utilizador do caderno, clique no painel lateral Ambiente.
- Em Memória, selecione Memória alta.
- Clique em Aplicar.
Esta definição de memória aplica-se também a tarefas de tarefas de notebook que são executadas usando as preferências de memória do notebook. A atualização da preferência de memória no caderno afeta a próxima execução do trabalho.
Selecione uma política de utilização sem servidor
As políticas de utilização serverless permitem que a sua organização aplique etiquetas personalizadas ao uso serverless para a atribuição granular de faturação.
Se o seu espaço de trabalho utilizar políticas de utilização sem servidor, selecione a política que pretende aplicar ao bloco de notas. Se a um utilizador for atribuída apenas uma política de utilização serverless, essa política aplica-se por defeito.
Depois de estabelecer ligação à computação sem servidor, selecione uma política no painel lateral Ambiente:
- Na interface do utilizador do caderno, clique no painel lateral Ambiente.
- Na política de utilização de serverless, selecione a política de utilização de serverless que pretende aplicar ao seu notebook.
- Clique em Aplicar.
Depois de aplicada, toda a utilização do notebook passa a usar as etiquetas personalizadas da política.
Note
Se o seu notebook tiver origem num repositório Git ou não tiver uma política de utilização serverless atribuída, será utilizada por defeito a última política de utilização serverless escolhida quando for novamente associado à computação serverless.
Incluir o ambiente nas exportações de ficheiros fonte
Para os notebooks de Python, pode ativar ou desativar Incluir nas exportações de ficheiros de origem nas definições do ambiente. Quando ativado, o ambiente base e as dependências são armazenados no formato PEP 723 nas exportações de ficheiros de origem. Isto ajuda a manter a configuração do ambiente quando os notebooks são armazenados em pastas Git ou descarregados como ficheiros de origem.
Por exemplo, um notebook que utiliza Standard v5 exporta a sua configuração de ambiente como metadados em linha no topo do ficheiro:
# Databricks notebook source
# /// script
# [tool.databricks.environment]
# environment_version = "5"
# ///
print("Hello World!")
Redefinir as dependências do ambiente
Se o seu notebook estiver ligado a computação serverless, Databricks armazenará automaticamente em cache o conteúdo do ambiente virtual do notebook. Isto significa que, geralmente, não precisas de reinstalar as dependências Python especificadas no painel lateral Ambiente quando abres um caderno existente, mesmo que este tenha sido desligado devido à inatividade.
O cache de ambientes virtuais em Python também se aplica a empregos. Quando uma tarefa é executada, qualquer tarefa que partilhe o mesmo conjunto de dependências que uma tarefa concluída na mesma execução termina mais rapidamente, porque a cache já contém as dependências necessárias.
Note
Se alterar a implementação de um pacote Python personalizado usado numa tarefa sem servidor, deve também atualizar o número de versão para que as tarefas possam adotar a implementação mais recente.
Para limpar a cache do ambiente e efetuar uma nova instalação das dependências especificadas no painel lateral Ambiente de um notebook associado à computação sem servidor, clique na seta junto de Aplicar e, em seguida, clique em Repor as predefinições.
Se você instalar pacotes que quebram ou alteram o notebook principal ou o ambiente Apache Spark, remova os pacotes ofensivos e redefina o ambiente. Iniciar uma nova sessão não limpa todo o cache do ambiente.
Configurar ambiente para tarefas de trabalho
Cada tarefa de trabalho corre num ambiente isolado que inclui um ambiente base e quaisquer bibliotecas adicionais que especifique. O ambiente base define as versões de runtime em Python e Scala e as bibliotecas pré-instaladas. As tarefas herdam o conjunto padrão de bibliotecas instaladas da versão do ambiente. Para ver o que está incluído, consulte a secção Bibliotecas Python instaladas ou Bibliotecas Java e Scala instaladas da versão do ambiente que está a utilizar.
Pode complementar as bibliotecas pré-instaladas com bibliotecas de ficheiros de workspace, volumes do Unity Catalog ou repositórios públicos de pacotes. Apenas as dependências necessárias para a tarefa são instaladas em tempo de execução.
Important
A utilização de computação serverless para tarefas JAR está em Versão Beta Pública.
Important
A seleção de um ambiente base gerida está em fase beta. O menu pendente Ambiente base na caixa de diálogo Configurar ambiente permite-lhe selecionar entre ambientes disponibilizados pela Databricks (como Standard e ML) ou ambientes configurados no espaço de trabalho. Sem esta funcionalidade, a caixa de diálogo apresenta, em alternativa, uma lista pendente versão do ambiente. Os administradores do espaço de trabalho podem ativar esta funcionalidade a partir da página de Pré-visualizações .
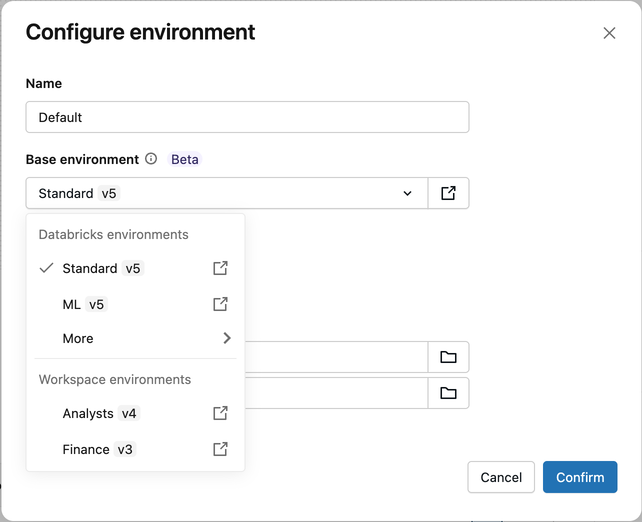
Configurar o ambiente por tipo de tarefa
A forma como configuras os ambientes num trabalho depende do tipo de tarefa:
Tarefas do caderno
As tarefas do caderno utilizam por defeito o Ambiente do Caderno, que utiliza o próprio ambiente base configurado e as dependências do caderno. Podes ultrapassar isto com um ambiente ao nível do trabalho.
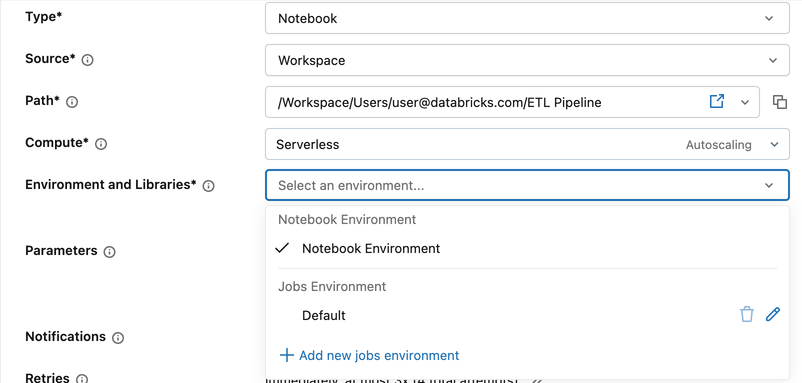
Para configurar um ambiente ao nível do trabalho:
- Na configuração da tarefa, clique no menu suspenso Ambiente e Bibliotecas .
- No Ambiente de Empregos, clique no ícone de lápis ao lado de Predefinido, ou clique em + Adicionar novo ambiente de empregos.
- No diálogo Configurar ambiente , selecione no menu suspenso Ambiente Base :
- Ambientes do Databricks: opções disponibilizadas pelo Azure Databricks, como Standard e ML.
- Ambientes de espaço de trabalho: Ambientes personalizados configurados pelo administrador do seu espaço de trabalho. Consulte Gerenciar ambientes base do espaço de trabalho.
- Mais: Versões anteriores e Personalizado (especificar um ficheiro YAML).
- Em Dependências, adicione quaisquer bibliotecas adicionais. Pode especificar uma biblioteca em qualquer formato válido num ficheiro requirements.txt, ou utilizar um caminho absoluto para um ficheiro da área de trabalho ou um volume do Unity Catalog.
- Clique em Confirmar.
Note
Se a sua área de trabalho não tiver ativado o ambiente base da área de trabalho para a pré-visualização de tarefas, a caixa de diálogo Configurar ambiente mostra uma lista pendente Versão do ambiente em vez de Ambiente base.
Para configurar o ambiente, selecione uma versão e depois clique em + Adicionar biblioteca. Pode especificar um caminho de ficheiro de workspace (começando por /Workspace/), um caminho de volume do Unity Catalog (começando por /Volumes/), ou uma referência de ficheiro de requisitos (por exemplo, -r /Workspace/path/to/requirements.txt).
Tarefas de scripts em Python e roda em Python
As tarefas de script Python e roda de Python exigem uma configuração de ambiente.
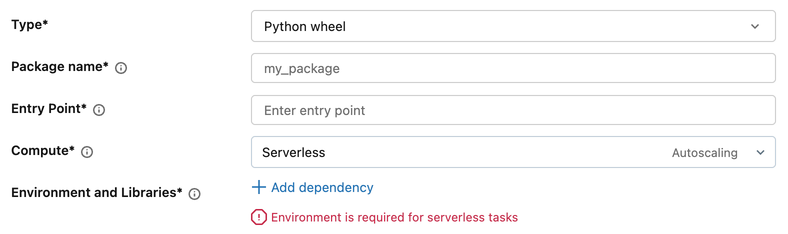
- Na configuração da tarefa, em Ambiente e Bibliotecas, clique + Adicionar dependência.
- No diálogo Configurar ambiente , selecione no menu suspenso Ambiente Base :
- Ambientes do Databricks: opções disponibilizadas pelo Azure Databricks, como Standard e ML.
- Ambientes de espaço de trabalho: Ambientes personalizados configurados pelo administrador do seu espaço de trabalho. Consulte Gerenciar ambientes base do espaço de trabalho.
- Mais: Versões anteriores e Personalizado (especificar um ficheiro YAML).
- Em Dependências, adicione quaisquer bibliotecas adicionais.
- Clique em Confirmar.
Note
Se a sua área de trabalho não tiver ativado o ambiente base da área de trabalho para a pré-visualização de tarefas, a caixa de diálogo Configurar ambiente mostra uma lista pendente Versão do ambiente em vez de Ambiente base.
Para configurar o ambiente, selecione uma versão e depois clique em + Adicionar biblioteca. Pode especificar um caminho de ficheiro de workspace (começando por /Workspace/), um caminho de volume do Unity Catalog (começando por /Volumes/), ou uma referência de ficheiro de requisitos (por exemplo, -r /Workspace/path/to/requirements.txt).
Tarefas de Dbt
As tarefas de DBT utilizam um ambiente ao nível do trabalho para a configuração da biblioteca.
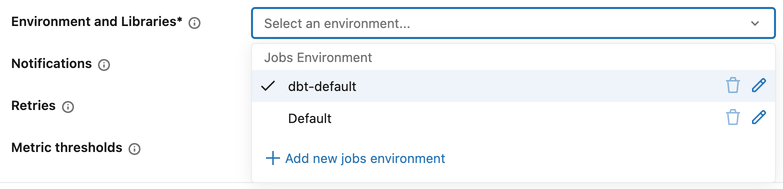
Para configurar um ambiente ao nível do trabalho:
- Na configuração da tarefa, clique no menu suspenso Ambiente e Bibliotecas .
- No Ambiente de Empregos, clique no ícone do lápis ao lado de um ambiente existente, ou clique em + Adicionar novo ambiente de empregos.
- No diálogo Configurar ambiente , selecione no menu suspenso Ambiente Base :
- Ambientes do Databricks: opções disponibilizadas pelo Azure Databricks, como Standard e ML.
- Ambientes de espaço de trabalho: Ambientes personalizados configurados pelo administrador do seu espaço de trabalho. Consulte Gerenciar ambientes base do espaço de trabalho.
- Mais: Versões anteriores e Personalizado (especificar um ficheiro YAML).
- Em Dependências, adicione quaisquer bibliotecas adicionais. Pode especificar uma biblioteca em qualquer formato válido num ficheiro requirements.txt, ou utilizar um caminho absoluto para um ficheiro da área de trabalho ou um volume do Unity Catalog.
- Clique em Confirmar.
Note
Se a sua área de trabalho não tiver ativado o ambiente base da área de trabalho para a pré-visualização de tarefas, a caixa de diálogo Configurar ambiente mostra uma lista pendente Versão do ambiente em vez de Ambiente base.
Para configurar o ambiente, selecione uma versão e depois clique em + Adicionar biblioteca. Pode especificar um caminho de ficheiro de workspace (começando por /Workspace/), um caminho de volume do Unity Catalog (começando por /Volumes/), ou uma referência de ficheiro de requisitos (por exemplo, -r /Workspace/path/to/requirements.txt).
Tarefas JAR
Os ambientes de base da área de trabalho não são suportados para tarefas JAR. Para configurar o ambiente de uma tarefa JAR:
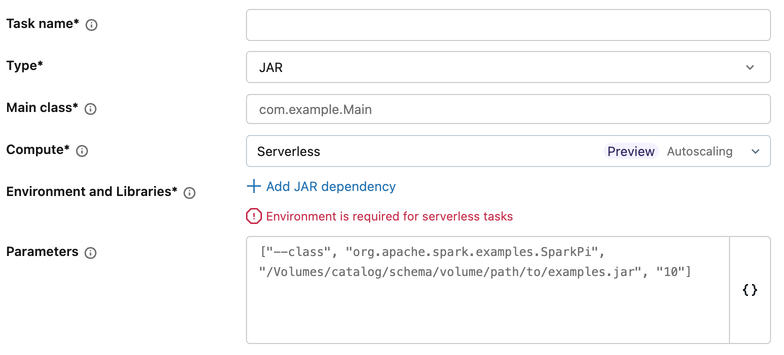
- Na configuração da tarefa, em Ambiente e Bibliotecas, clique + Adicionar dependência JAR.
- No diálogo Configurar ambiente :
- Opcionalmente, introduza um caminho para um ficheiro YAML no campo do ambiente base .
- Selecione uma versão do ambiente no menu pendente Versão do ambiente.
- Em Dependências JAR, adicione os caminhos aos seus ficheiros JAR.
- Clique em Confirmar.
Para criar um ambiente base personalizado baseado em YAML, veja Criar uma especificação de ambiente personalizada.
Compatibilidade entre ambiente e computação
O ambiente base que seleciona deve ser compatível com o tipo de computação da tarefa. Por exemplo, um ambiente construído para computação por GPU não é compatível com computação por CPU. Na interface jobs, ambientes incompatíveis não estão disponíveis no menu suspenso do ambiente base.
Quando configuras uma tarefa de portátil, o tipo de computação (CPU ou GPU) e o ambiente base podem vir tanto das definições do trabalho como das definições do portátil.
- Se definir um acelerador de hardware (GPU) a nível de tarefa, também deve selecionar um ambiente base a nível de tarefa. Não é possível utilizar o ambiente do notebook com um acelerador ao nível da tarefa.
- Se tiver tarefas de trabalho que referenciam um caderno e atualizar o tipo de computação do caderno referenciado (por exemplo, de CPU para GPU), as tarefas existentes podem tornar-se incompatíveis com o ambiente configurado deles. Revise as definições do ambiente do seu trabalho depois de alterar a configuração de computação do portátil.
- Para utilizadores da API: se definir o ambiente de base ao nível da tarefa, mas o notebook definir o tipo de computação, o Azure Databricks valida a compatibilidade em tempo de execução, e não no momento da criação da tarefa. Se a configuração for incompatível, a execução falha com um erro.