Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo explica como usar a computação sem servidor para notebooks. Para obter informações sobre como usar a computação sem servidor para trabalhos, consulte Executar seus trabalhos do Lakeflow com computação sem servidor para fluxos de trabalho.
Para informações sobre preços sobre o uso de computação serverless em portáteis, consulte Preços do Databricks.
Requisitos
- Seu espaço de trabalho deve estar habilitado para o Catálogo Unity.
- O seu espaço de trabalho deve estar numa região suportada para computação serverless.
Anexar um bloco de notas à computação sem servidor
Se o espaço de trabalho estiver habilitado para computação interativa sem servidor, todos os utilizadores no espaço de trabalho terão acesso à computação sem servidor para blocos de anotações. Não são necessárias permissões adicionais.
Para anexar à computação sem servidor, clique no menu suspenso de computação no notebook e selecione Serverless. Para novos cadernos, a computação anexada utiliza por defeito o modo serverless quando o código é executado, caso nenhum outro recurso tenha sido selecionado.
Ver informações de consulta
A computação sem servidor para blocos de anotações e trabalhos usa informações de consulta para avaliar o desempenho de execução do Spark. Depois de executar uma célula num caderno, pode visualizar insights relacionados com consultas SQL e Python clicando na ligação Ver desempenho.
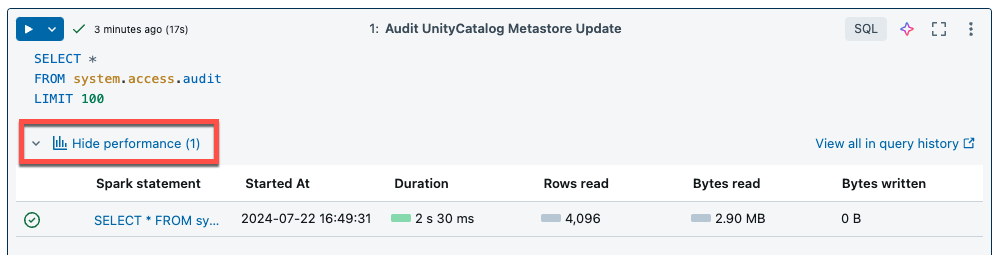
Você pode clicar em qualquer uma das instruções do Spark para visualizar as métricas de consulta. A partir daí, você pode clicar em Ver perfil de consulta para ver uma visualização da execução da consulta. Para obter mais informações sobre perfis de consulta, consulte Perfil de consulta.
Nota
Para exibir informações de desempenho para suas execuções de trabalho, consulte Exibir informações de consulta de execução de trabalho.
Histórico de consultas
Todas as consultas executadas em computação sem servidor também serão registradas na página de histórico de consultas do seu espaço de trabalho. Para obter informações sobre o histórico de consultas, consulte Histórico de consultas.
Limitações do insight de consulta
- As métricas são atualizadas em tempo real durante a execução da consulta, mas o perfil completo da consulta só está disponível após o término da consulta.
- Apenas os seguintes estados de consulta estão cobertos: A DECORRER, CANCELADO, FALHADO, CONCLUÍDO.
- As consultas em execução não podem ser canceladas a partir da página de histórico de consultas. Eles podem ser cancelados em blocos de notas ou tarefas.
- Métricas verbosas não estão disponíveis.
- O download do Perfil de Consulta não está disponível.
- O acesso à interface do usuário do Spark não está disponível.
- O texto da instrução contém apenas a última linha que foi executada. No entanto, pode haver várias linhas que precedem essa linha que foram executadas como parte da mesma instrução.
Proteção contra gastos excessivos sem servidor
Para controlar consultas de execução prolongada, os notebooks serverless têm um limite de tempo de execução predefinido de 2,5 horas (9 000 segundos). Consultas que excedam o timeout são canceladas.
Configure o timeout para todos os cadernos no espaço de trabalho
Os administradores do espaço de trabalho podem alterar o tempo limite de execução predefinido dos notebooks serverless. Nas definições de administração do espaço de trabalho, vá a Definições>Computação e, em Serverless interactive, configure a definição Tempo limite de execução interativa sem servidor. As alterações demoram aproximadamente 5 minutos a propagar-se.
Anule o timeout de um único caderno
Para substituir a predefinição da área de trabalho de um notebook específico, defina spark.databricks.execution.timeout no notebook. O valor por caderno tem prioridade sobre a definição do espaço de trabalho. Consulte Configurar propriedades do Spark para blocos de anotações e trabalhos sem servidor.