Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Use as expectativas para aplicar restrições de qualidade que validam os dados à medida que fluem pelos pipelines de ETL. As expectativas fornecem uma visão mais aprofundada das métricas de qualidade de dados e permitem que você falhe atualizações ou descarte registros ao detetar registros inválidos.
Este artigo tem uma visão geral das expectativas, incluindo exemplos de sintaxe e opções de comportamento. Para obter casos de uso mais avançados e práticas recomendadas, consulte Recomendações de espectativas e padrões avançados.
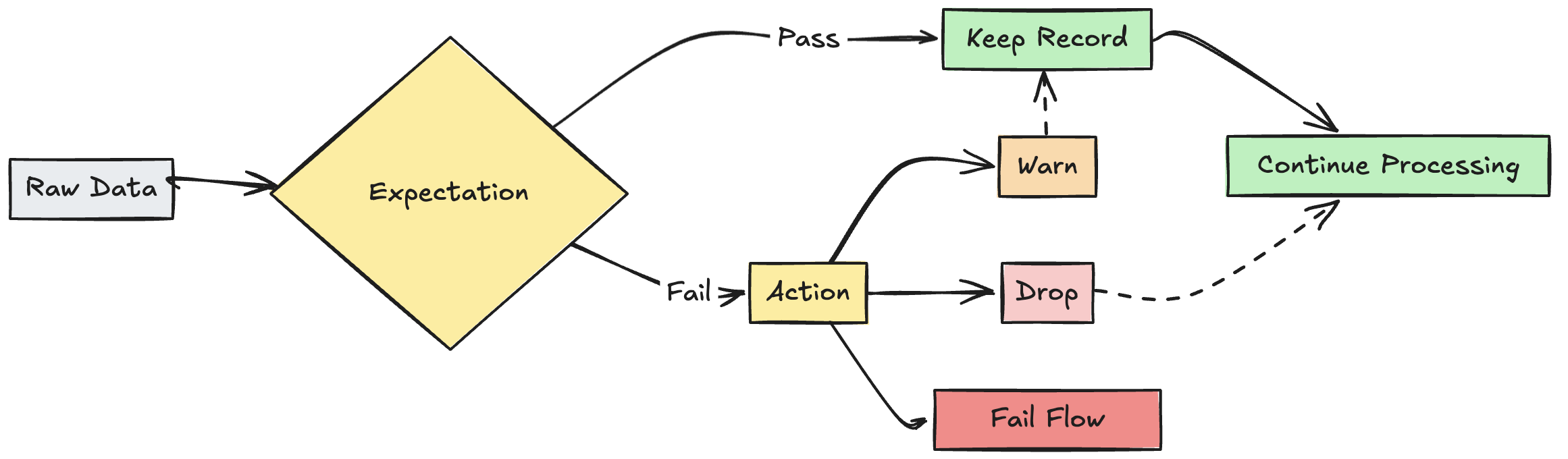
O que são expectativas?
As expectativas são cláusulas opcionais na exibição materializada de pipeline, tabela de streaming ou instruções de criação de exibição que aplicam verificações de qualidade de dados em cada registro que passa por uma consulta. As expectativas utilizam declarações padrão Booleanas SQL para especificar restrições. Você pode combinar várias expectativas para um único conjunto de dados e definir expectativas em todas as declarações de conjunto de dados em um pipeline.
As seções a seguir apresentam os três componentes de uma expectativa e fornecem exemplos de sintaxe.
Nome de expectativa
Cada expectativa deve ter um nome, que é usado como um identificador para rastrear e monitorar a expectativa. Escolha um nome que comunique as métricas que estão sendo validadas. O exemplo a seguir define a expectativa valid_customer_age para confirmar que a idade está entre 0 e 120 anos.
Importante
Um nome de expectativa deve ser exclusivo para um determinado conjunto de dados. Você pode reutilizar expectativas em vários conjuntos de dados num pipeline. Consulte Expectativas portáteis e reutilizáveis.
Píton
@dlt.table
@dlt.expect("valid_customer_age", "age BETWEEN 0 AND 120")
def customers():
return spark.readStream.table("datasets.samples.raw_customers")
SQL
CREATE OR REFRESH STREAMING TABLE customers(
CONSTRAINT valid_customer_age EXPECT (age BETWEEN 0 AND 120)
) AS SELECT * FROM STREAM(datasets.samples.raw_customers);
Restrição para avaliar
A cláusula de restrição é uma instrução condicional SQL que deve ser avaliada como true ou false para cada registro. A restrição contém a lógica real para o que está sendo validado. Quando um registo não cumpre esta condição, a expectativa é ativada.
As restrições devem usar sintaxe SQL válida e não podem conter o seguinte:
- Funções Python personalizadas
- Chamadas de serviço externo
- Subconsultas que fazem referência a outras tabelas
A seguir estão exemplos de restrições que podem ser adicionadas às instruções de criação de conjunto de dados:
Píton
A sintaxe para uma restrição em Python é:
@dlt.expect(<constraint-name>, <constraint-clause>)
Várias restrições podem ser especificadas:
@dlt.expect(<constraint-name>, <constraint-clause>)
@dlt.expect(<constraint2-name>, <constraint2-clause>)
Exemplos:
# Simple constraint
@dlt.expect("non_negative_price", "price >= 0")
# SQL functions
@dlt.expect("valid_date", "year(transaction_date) >= 2020")
# CASE statements
@dlt.expect("valid_order_status", """
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
""")
# Multiple constraints
@dlt.expect("non_negative_price", "price >= 0")
@dlt.expect("valid_purchase_date", "date <= current_date()")
# Complex business logic
@dlt.expect(
"valid_subscription_dates",
"""start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'"""
)
# Complex boolean logic
@dlt.expect("valid_order_state", """
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
""")
SQL
A sintaxe para uma restrição no SQL é:
CONSTRAINT <constraint-name> EXPECT ( <constraint-clause> )
Várias restrições devem ser separadas por uma vírgula:
CONSTRAINT <constraint-name> EXPECT ( <constraint-clause> ),
CONSTRAINT <constraint2-name> EXPECT ( <constraint2-clause> )
Exemplos:
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0)
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020)
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0),
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
Ação em registro inválido
Você deve especificar uma ação para determinar o que acontece quando um registro falha na verificação de validação. A tabela a seguir descreve as ações disponíveis:
| Ação | Sintaxe SQL | Sintaxe Python | Resultado |
|---|---|---|---|
| avisar (padrão) | EXPECT |
dlt.expect |
Registros inválidos são gravados no destino final. |
| queda | EXPECT ... ON VIOLATION DROP ROW |
dlt.expect_or_drop |
Os registros inválidos são descartados antes que os dados sejam gravados no destino. A contagem de registros descartados é registrada junto com outras métricas do conjunto de dados. |
| erro | EXPECT ... ON VIOLATION FAIL UPDATE |
dlt.expect_or_fail |
Registros inválidos impedem que a atualização seja bem-sucedida. É necessária uma intervenção manual antes do reprocessamento. Essa expectativa causa uma falha de um único fluxo e não faz com que outros fluxos em seu pipeline falhem. |
Você também pode implementar lógica avançada para colocar em quarentena registros inválidos sem falhar ou descartar dados. Consulte Quarentena de registos inválidos.
Métricas de acompanhamento de expectativas
Você pode ver as métricas de acompanhamento de warn ou drop ações da interface do pipeline. Como fail faz com que a atualização falhe quando um registro inválido é detetado, as métricas não são registradas.
Para visualizar as métricas de expectativa, conclua as seguintes etapas:
- Na barra lateral do espaço de trabalho do Azure Databricks, clique em Trabalhos & Pipelines.
- Clique no Nome do seu pipeline.
- Clique em um conjunto de dados com uma expectativa definida.
- Selecione o separador Qualidade de dados na barra lateral direita.
Você pode exibir métricas de qualidade de dados consultando o log de eventos do Lakeflow Declarative Pipelines. Consulte qualidade dos dados de consulta a partir do registo de eventos.
Reter registos inválidos
A retenção de registros inválidos é o comportamento padrão para as expectativas. Use o operador expect quando pretender manter registos que violem a expectativa, mas coletem métricas sobre quantos registos passam ou falham uma restrição. Os registros que violam a expectativa são adicionados ao conjunto de dados de destino junto com registros válidos:
Píton
@dlt.expect("valid timestamp", "timestamp > '2012-01-01'")
SQL
CONSTRAINT valid_timestamp EXPECT (timestamp > '2012-01-01')
Eliminar registos inválidos
Use o operador expect_or_drop para evitar o processamento adicional de registros inválidos. Os registros que violam a expectativa são descartados do conjunto de dados de destino:
Píton
@dlt.expect_or_drop("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
SQL
CONSTRAINT valid_current_page EXPECT (current_page_id IS NOT NULL and current_page_title IS NOT NULL) ON VIOLATION DROP ROW
Falha em registos inválidos
Quando registros inválidos forem inaceitáveis, use o operador expect_or_fail para interromper a execução imediatamente quando um registro falhar na validação. Se a operação for uma atualização de tabela, o sistema atomicamente reverte a transação.
Píton
@dlt.expect_or_fail("valid_count", "count > 0")
SQL
CONSTRAINT valid_count EXPECT (count > 0) ON VIOLATION FAIL UPDATE
Importante
Se você tiver vários fluxos paralelos definidos em um pipeline, a falha de um único fluxo não fará com que outros fluxos falhem.
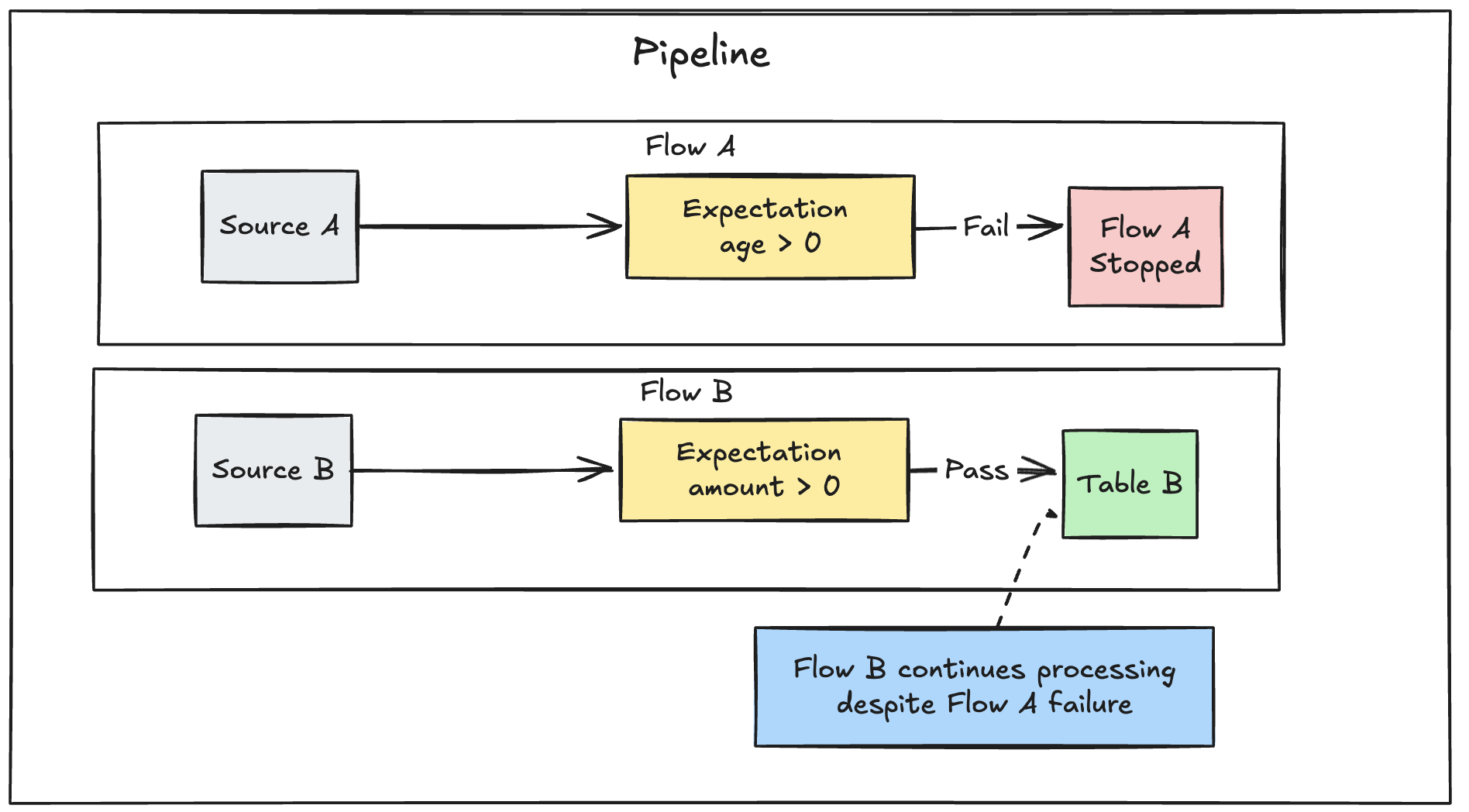
Solução de problemas de atualizações falhadas em relação às expectativas
Quando um pipeline falha devido a uma violação de expectativa, você deve corrigir o código do pipeline para manipular os dados inválidos corretamente antes de executar novamente o pipeline.
As expectativas configuradas para pipelines que falham modificam o plano de consulta do Spark das suas transformações para monitorizar as informações necessárias para detetar e relatar violações. Você pode usar essas informações para identificar qual registro de entrada resultou na violação para muitas consultas. Lakeflow Declarative Pipelines fornece uma mensagem de erro dedicada para relatar tais violações. Aqui está um exemplo de uma mensagem de erro de violação de expectativa:
[EXPECTATION_VIOLATION.VERBOSITY_ALL] Flow 'sensor-pipeline' failed to meet the expectation. Violated expectations: 'temperature_in_valid_range'. Input data: '{"id":"TEMP_001","temperature":-500,"timestamp_ms":"1710498600"}'. Output record: '{"sensor_id":"TEMP_001","temperature":-500,"change_time":"2024-03-15 10:30:00"}'. Missing input data: false
Gestão de expectativas múltiplas
Observação
Embora o SQL e o Python suportem várias expectativas em um único conjunto de dados, apenas o Python permite agrupar várias expectativas e especificar ações coletivas.
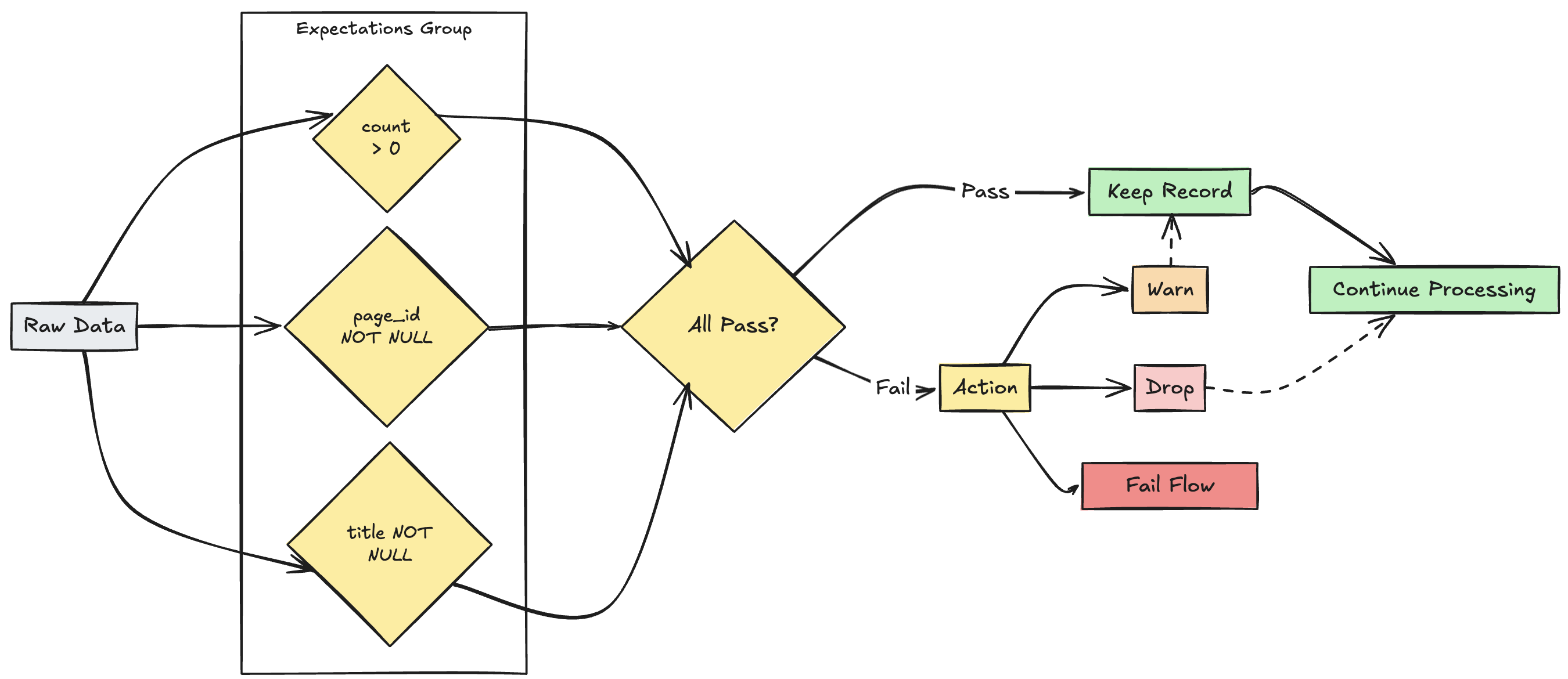
Você pode agrupar várias expectativas e especificar ações coletivas usando as funções expect_all, expect_all_or_drope expect_all_or_fail.
Estes decoradores aceitam um dicionário Python como argumento, onde a chave representa o nome da expectativa e o valor é a restrição correspondente. Você pode reutilizar o mesmo conjunto de expectativas em vários conjuntos de dados em seu pipeline. Exemplos de cada um dos operadores Python expect_all são mostrados a seguir.
valid_pages = {"valid_count": "count > 0", "valid_current_page": "current_page_id IS NOT NULL AND current_page_title IS NOT NULL"}
@dlt.table
@dlt.expect_all(valid_pages)
def raw_data():
# Create a raw dataset
@dlt.table
@dlt.expect_all_or_drop(valid_pages)
def prepared_data():
# Create a cleaned and prepared dataset
@dlt.table
@dlt.expect_all_or_fail(valid_pages)
def customer_facing_data():
# Create cleaned and prepared to share the dataset
Limitações
- Como apenas tabelas de streaming e exibições materializadas dão suporte às expectativas, as métricas de qualidade de dados são suportadas apenas para esses tipos de objeto.
- As métricas de qualidade de dados não estão disponíveis quando:
- Nenhuma expectativa é definida em uma consulta.
- Um fluxo usa um operador que não dá suporte a expectações.
- O tipo de fluxo, como os sumidouros de oleodutos declarativos Lakeflow, não suporta as expectativas.
- Não há atualizações na tabela de streaming associada ou na visualização materializada para uma determinada execução de fluxo.
- A configuração do pipeline não inclui as configurações necessárias para capturar métricas, como
pipelines.metrics.flowTimeReporter.enabled.
- Para alguns casos, um
COMPLETEDfluxo pode não conter métricas. Em vez disso, as métricas são relatadas em cada microlote num eventoflow_progresscom o statusRUNNING.