Integração e entrega contínuas no Azure Databricks mediante a utilização do Azure DevOps
Nota
Este artigo aborda o Azure DevOps, que é desenvolvido por terceiros. Para entrar em contato com o provedor, consulte Suporte dos Serviços de DevOps do Azure.
Este artigo orienta você na configuração da automação do Azure DevOps para seu código e artefatos que funcionam com o Azure Databricks. Especificamente, você configurará um fluxo de trabalho de integração e entrega contínua (CI/CD) para se conectar a um repositório Git, executar trabalhos usando o Azure Pipelines para criar e testar uma roda Python (*.whl) e implantá-la para uso em blocos de anotações Databricks.
Fluxo de trabalho de desenvolvimento de CI/CD
O Databricks sugere o seguinte fluxo de trabalho para desenvolvimento de CI/CD com o Azure DevOps:
- Crie um repositório ou use um repositório existente com seu provedor Git de terceiros.
- Conecte sua máquina de desenvolvimento local ao mesmo repositório de terceiros. Para obter instruções, consulte a documentação do seu provedor Git de terceiros.
- Extraia todos os artefatos atualizados existentes (como blocos de anotações, arquivos de código e scripts de compilação) para sua máquina de desenvolvimento local a partir do repositório de terceiros.
- Conforme necessário, crie, atualize e teste artefatos em sua máquina de desenvolvimento local. Em seguida, envie quaisquer artefatos novos e alterados de sua máquina de desenvolvimento local para o repositório de terceiros. Para obter instruções, consulte a documentação do seu provedor Git de terceiros.
- Repita os passos 3 e 4 conforme necessário.
- Use o Azure DevOps periodicamente como uma abordagem integrada para extrair automaticamente artefatos de seu repositório de terceiros, criar, testar e executar código em seu espaço de trabalho do Azure Databricks e relatar resultados de teste e execução. Embora você possa executar o Azure DevOps manualmente, em implementações do mundo real, você instruiria seu provedor Git de terceiros a executar o Azure DevOps sempre que um evento específico acontecesse, como uma solicitação pull de repositório.
Existem inúmeras ferramentas de CI/CD que você pode usar para gerenciar e executar seu pipeline. Este artigo ilustra como usar o Azure DevOps. CI/CD é um padrão de design, portanto, as etapas e estágios descritos no exemplo deste artigo devem ser transferidos com algumas alterações na linguagem de definição de pipeline em cada ferramenta. Além disso, grande parte do código neste pipeline de exemplo é código Python padrão que pode ser invocado em outras ferramentas.
Gorjeta
Para obter informações sobre como usar o Jenkins com o Azure Databricks em vez do Azure DevOps, consulte CI/CD com Jenkins no Azure Databricks.
O restante deste artigo descreve um par de pipelines de exemplo no Azure DevOps que você pode adaptar às suas próprias necessidades para o Azure Databricks.
Sobre o exemplo
O exemplo deste artigo usa dois pipelines para reunir, implantar e executar código Python de exemplo e blocos de anotações Python armazenados em um repositório Git remoto.
O primeiro pipeline, conhecido como pipeline de construção , prepara artefatos de construção para o segundo pipeline, conhecido como pipeline de liberação . Separar o pipeline de compilação do pipeline de liberação permite criar um artefato de compilação sem implantá-lo ou implantar simultaneamente artefatos de várias compilações. Para construir os pipelines de compilação e liberação:
- Crie uma máquina virtual do Azure para o pipeline de compilação.
- Copie os arquivos do repositório Git para a máquina virtual.
- Crie um arquivo tar gzip'ed que contenha o código Python, blocos de anotações Python e arquivos de configurações de compilação, implantação e execução relacionados.
- Copie o arquivo tar gzip'ed como um arquivo zip em um local para o pipeline de liberação acessar.
- Crie outra máquina virtual do Azure para o pipeline de versão.
- Obtenha o arquivo zip do local do pipeline de compilação e, em seguida, descompacte o arquivo zip para obter o código Python, blocos de anotações Python e arquivos de configurações de compilação, implantação e execução relacionados.
- Implante o código Python, os blocos de anotações Python e os arquivos de configurações de compilação, implantação e execução relacionados em seu espaço de trabalho remoto do Azure Databricks.
- Crie os arquivos de código de componentes da biblioteca de rodas Python em um arquivo de roda Python.
- Execute testes de unidade no código do componente para verificar a lógica no arquivo de roda do Python.
- Execute os blocos de anotações Python, um dos quais chama a funcionalidade do arquivo de roda Python.
Sobre a CLI do Databricks
O exemplo deste artigo demonstra como usar a CLI do Databricks em um modo não interativo dentro de um pipeline. O pipeline de exemplo deste artigo implanta código, cria uma biblioteca e executa blocos de anotações em seu espaço de trabalho do Azure Databricks.
Se você estiver usando a CLI do Databricks em seu pipeline sem implementar o código de exemplo, a biblioteca e os blocos de anotações deste artigo, siga estas etapas:
Prepare seu espaço de trabalho do Azure Databricks para usar a autenticação máquina a máquina (M2M) OAuth para autenticar uma entidade de serviço. Antes de começar, confirme se você tem uma entidade de serviço do Microsoft Entra ID com um segredo OAuth do Azure Databricks. Consulte Autorizar acesso sem supervisão aos recursos do Azure Databricks com um principal de serviço usando OAuth.
Instale a CLI do Databricks em seu pipeline. Para fazer isso, adicione uma tarefa Bash Script ao seu pipeline que executa o seguinte script:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | shPara adicionar uma tarefa Bash Script ao seu pipeline, consulte a Etapa 3.6. Instale as ferramentas de construção de roda Databricks CLI e Python.
Configure seu pipeline para permitir que a CLI do Databricks instalada autentique sua entidade de serviço com seu espaço de trabalho. Para fazer isso, consulte Etapa 3.1: Definir variáveis de ambiente para o pipeline de versão.
Adicione mais tarefas do Bash Script ao seu pipeline conforme necessário para executar os comandos da CLI do Databricks. Consulte Comandos da CLI do Databricks.
Antes de começar
Para usar o exemplo deste artigo, você deve ter:
- Um projeto existente do Azure DevOps . Se você ainda não tiver um projeto, crie um projeto no Azure DevOps.
- Um repositório existente com um provedor Git que o Azure DevOps suporta. Você adicionará o código de exemplo do Python, o bloco de anotações Python de exemplo e os arquivos de configurações de versão relacionados a este repositório. Se você ainda não tem um repositório, crie um seguindo as instruções do seu provedor Git. Em seguida, conecte seu projeto de DevOps do Azure a esse repositório, caso ainda não tenha feito isso. Para obter instruções, siga os links em Repositórios de origem suportados.
- O exemplo deste artigo usa a autenticação OAuth máquina-a-máquina (M2M) para autenticar uma entidade de serviço Microsoft Entra ID em um espaço de trabalho do Azure Databricks. Você deve ter uma entidade de serviço Microsoft Entra ID com um segredo OAuth do Azure Databricks para essa entidade de serviço. Veja Autorizar acesso autónomo aos recursos do Azure Databricks com um principal de serviço usando OAuth.
Etapa 1: Adicionar os arquivos do exemplo ao repositório
Nesta etapa, no repositório com seu provedor Git de terceiros, você adiciona todos os arquivos de exemplo deste artigo que seus pipelines de DevOps do Azure criam, implantam e executam em seu espaço de trabalho remoto do Azure Databricks.
Etapa 1.1: Adicionar os arquivos do componente de roda Python
No exemplo deste artigo, seus pipelines do Azure DevOps criam e testam um arquivo de roda Python. Em seguida, um bloco de anotações do Azure Databricks chama a funcionalidade do arquivo de roda Python criado.
Para definir a lógica e os testes de unidade para o arquivo de roda Python contra o qual os blocos de anotações são executados, na raiz do repositório, crie dois arquivos chamados addcol.py e test_addcol.py, e adicione-os a uma estrutura de pastas nomeada python/dabdemo/dabdemo em uma Libraries pasta, visualizada da seguinte maneira:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
O addcol.py arquivo contém uma função de biblioteca que é criada posteriormente em um arquivo de roda Python e, em seguida, instalada em clusters do Azure Databricks. É uma função simples que adiciona uma nova coluna, preenchida por um literal, a um Apache Spark DataFrame:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
O test_addcol.py arquivo contém testes para passar um objeto DataFrame simulado para a with_status função, definida em addcol.py. O resultado é então comparado a um objeto DataFrame contendo os valores esperados. Se os valores corresponderem, o teste é aprovado:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Para habilitar a CLI do Databricks para empacotar corretamente esse código de biblioteca em um arquivo de roda Python, crie dois arquivos nomeados __init__.py e __main__.py na mesma pasta que os dois arquivos anteriores. Além disso, crie um arquivo nomeado setup.py na pasta, visualizado python/dabdemo da seguinte maneira:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
O __init__.py arquivo contém o número da versão e o autor da biblioteca. Substitua <my-author-name> pelo seu nome:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
O __main__.py arquivo contém o ponto de entrada da biblioteca:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
O setup.py arquivo contém configurações adicionais para construir a biblioteca em um arquivo de roda Python. Substitua <my-url>, <my-author-name>@<my-organization>e <my-package-description> por valores válidos:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Etapa 1.2: Adicionar um bloco de anotações de teste de unidade para o arquivo de roda Python
Mais tarde, a CLI do Databricks executa um trabalho de bloco de anotações. Este trabalho executa um bloco de anotações Python com o nome do run_unit_tests.pyarquivo . Este notebook é executado pytest contra a lógica da biblioteca de rodas Python.
Para executar os testes de unidade para o exemplo deste artigo, adicione à raiz do repositório um arquivo de bloco de anotações nomeado run_unit_tests.py com o seguinte conteúdo:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Etapa 1.3: Adicionar um bloco de anotações que chama o arquivo de roda Python
Mais tarde, a CLI do Databricks executa outro trabalho de bloco de anotações. Este bloco de anotações cria um objeto DataFrame, passa-o para a função da with_status biblioteca de rodas Python, imprime o resultado e relata os resultados da execução do trabalho. Crie a raiz do seu repositório um arquivo de bloco de anotações nomeado dabdemo_notebook.py com o seguinte conteúdo:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
Etapa 1.4: Criar a configuração do pacote
O exemplo deste artigo usa Databricks Asset Bundles para definir as configurações e comportamentos para criar, implantar e executar o arquivo de roda Python, os dois blocos de anotações e o arquivo de código Python. Os Databricks Asset Bundles, conhecidos simplesmente como bundles, tornam possível expressar dados completos, análises e projetos de ML como uma coleção de arquivos de origem. Consulte O que são Databricks Asset Bundles?.
Para configurar o pacote para o exemplo deste artigo, crie na raiz do repositório um arquivo chamado databricks.yml. Neste arquivo de exemplo databricks.yml , substitua os seguintes espaços reservados:
- Substitua
<bundle-name>por um nome programático exclusivo para o pacote. Por exemplo,azure-devops-demo. - Substitua
<job-prefix-name>por alguma cadeia de caracteres para ajudar a identificar exclusivamente os trabalhos criados em seu espaço de trabalho do Azure Databricks para este exemplo. Por exemplo,azure-devops-demo. - Substitua
<spark-version-id>pelo ID de versão do Databricks Runtime para seus clusters de trabalho, por exemplo13.3.x-scala2.12. - Substitua
<cluster-node-type-id>pelo ID do tipo de nó do cluster para seus clusters de trabalho, por exemploStandard_DS3_v2. - Observe que
devnotargetsmapeamento especifica o host e os comportamentos de implantação relacionados. Em implementações do mundo real, você pode dar a esse destino um nome diferente em seus próprios pacotes.
Aqui está o conteúdo do arquivo deste exemplo databricks.yml :
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
targets:
dev:
mode: development
Para obter mais informações sobre a sintaxe do databricks.yml arquivo, consulte Configuração do Databricks Asset Bundle.
Etapa 2: Definir o pipeline de compilação
O Azure DevOps fornece uma interface de usuário hospedada na nuvem para definir os estágios do seu pipeline de CI/CD usando YAML. Para obter mais informações sobre o Azure DevOps e pipelines, consulte a documentação do Azure DevOps.
Nesta etapa, você usa a marcação YAML para definir o pipeline de compilação, que cria um artefato de implantação. Para implantar o código em um espaço de trabalho do Azure Databricks, especifique o artefato de compilação desse pipeline como entrada em um pipeline de versão. Você define esse pipeline de liberação mais tarde.
Para executar pipelines de compilação, o Azure DevOps fornece agentes de execução sob demanda hospedados na nuvem que dão suporte a implantações para Kubernetes, VMs, Azure Functions, Aplicativos Web do Azure e muitos outros destinos. Neste exemplo, você usa um agente sob demanda para automatizar a criação do artefato de implantação.
Defina o pipeline de compilação de exemplo deste artigo da seguinte maneira:
Entre no Azure DevOps e clique no link Entrar para abrir seu projeto do Azure DevOps.
Nota
Se o Portal do Azure for exibido em vez do seu projeto do Azure DevOps, clique em Mais serviços > Organizações > do Azure DevOps Minhas organizações do Azure DevOps e abra seu projeto do Azure DevOps.
Clique em Pipelines na barra lateral e, em seguida, clique em Pipelines no menu Pipelines .
Clique no botão Novo pipeline e siga as instruções na tela. (Se você já tiver pipelines, clique em Crie o Pipeline em vez disso.) No final dessas instruções, o editor de pipeline é aberto. Aqui você define seu script de pipeline de
azure-pipelines.ymlconstrução no arquivo que aparece. Se o editor de pipeline não estiver visível no final das instruções, selecione o nome do pipeline de compilação e clique em Editar.Você pode usar o seletor
 de ramificação Git para personalizar o processo de compilação para cada ramificação em seu repositório Git. É uma prática recomendada de CI/CD não fazer trabalho de produção diretamente na ramificação do
de ramificação Git para personalizar o processo de compilação para cada ramificação em seu repositório Git. É uma prática recomendada de CI/CD não fazer trabalho de produção diretamente na ramificação do mainrepositório. Este exemplo pressupõe que existe uma ramificação nomeadareleaseno repositório a ser usada em vez demain.
O
azure-pipelines.ymlscript de pipeline de construção é armazenado por padrão na raiz do repositório Git remoto que você associa ao pipeline.Substitua o conteúdo inicial do
azure-pipelines.ymlarquivo do pipeline pela seguinte definição e clique em Salvar.# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
Etapa 3: Definir o pipeline de liberação
O pipeline de liberação implanta os artefatos de compilação do pipeline de compilação em um ambiente do Azure Databricks. Separar o pipeline de liberação nesta etapa do pipeline de compilação nas etapas anteriores permite criar uma compilação sem implantá-la ou implantar artefatos de várias compilações simultaneamente.
Em seu projeto do Azure DevOps, no menu Pipelines na barra lateral, clique em Releases.
Clique em Novo > pipeline de versão. (Se você já tiver pipelines, clique em Novo pipeline em vez disso.)
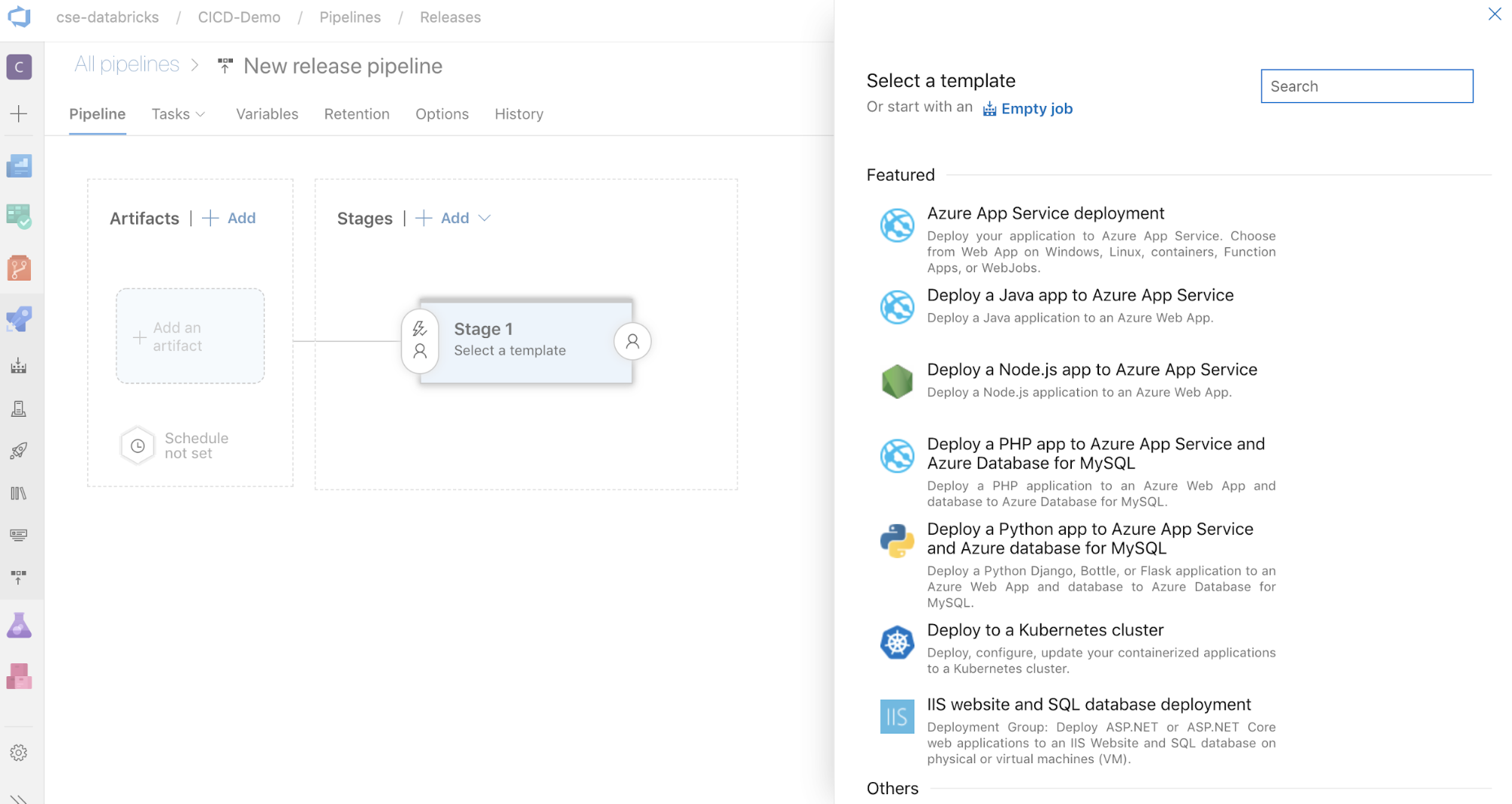
Na lateral da tela há uma lista de modelos em destaque para padrões de implantação comuns. Para este exemplo de pipeline de versão, clique em
 .
.
Na caixa Artefatos na lateral da tela, clique em
 . No painel Adicionar um artefato, para Origem (pipeline de build), selecione o pipeline de build que criou anteriormente. Em seguida, clique em Adicionar.
. No painel Adicionar um artefato, para Origem (pipeline de build), selecione o pipeline de build que criou anteriormente. Em seguida, clique em Adicionar.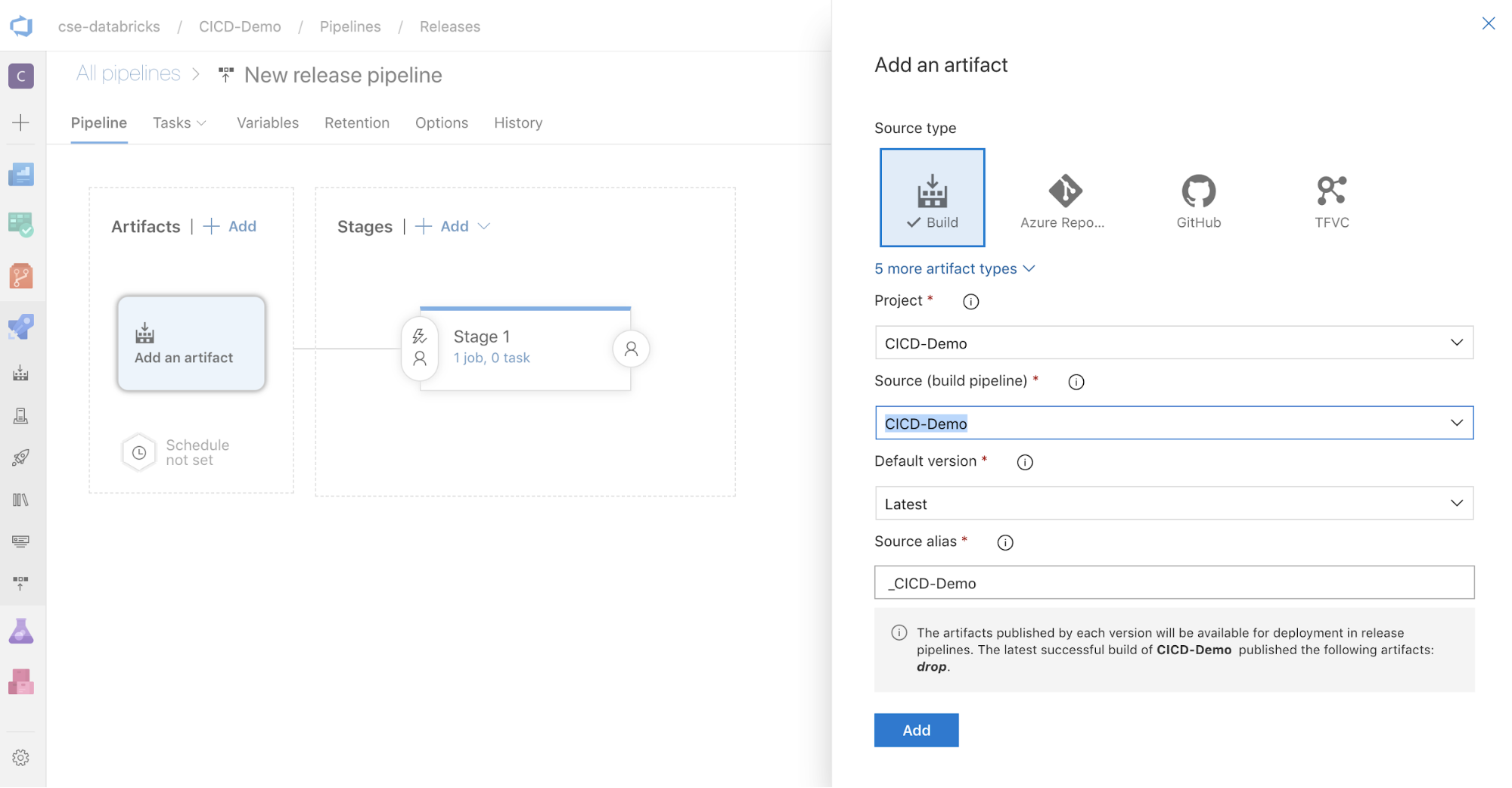
Você pode configurar como o pipeline é acionado clicando para
 exibir as opções de acionamento na lateral da tela. Se você quiser que uma liberação seja iniciada automaticamente com base na disponibilidade do artefato de compilação ou após um fluxo de trabalho de solicitação pull, habilite o gatilho apropriado. Por enquanto, neste exemplo, na última etapa deste artigo, você aciona manualmente o pipeline de compilação e, em seguida, o pipeline de liberação.
exibir as opções de acionamento na lateral da tela. Se você quiser que uma liberação seja iniciada automaticamente com base na disponibilidade do artefato de compilação ou após um fluxo de trabalho de solicitação pull, habilite o gatilho apropriado. Por enquanto, neste exemplo, na última etapa deste artigo, você aciona manualmente o pipeline de compilação e, em seguida, o pipeline de liberação.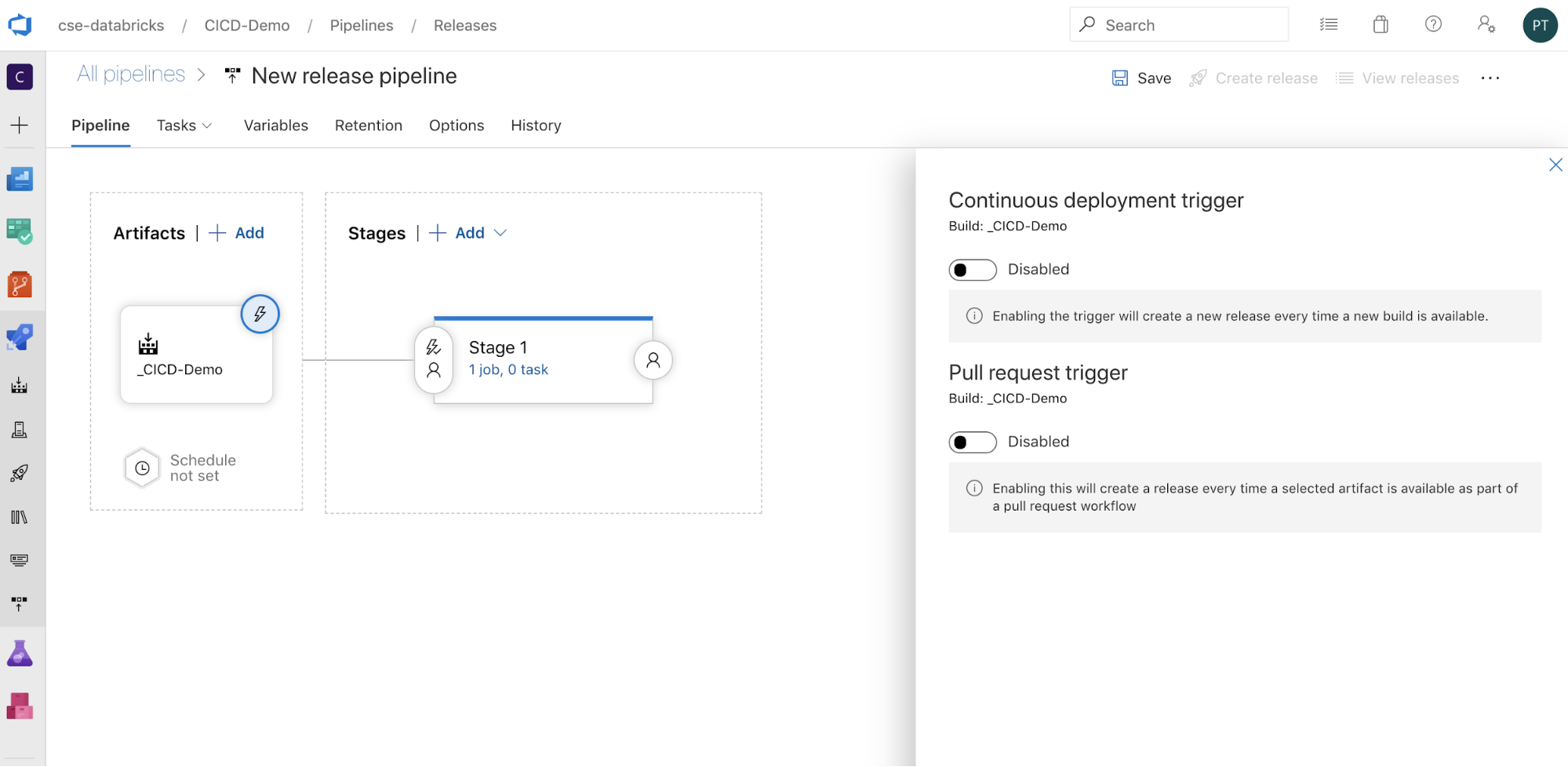
Clique em Salvar > OK.
Etapa 3.1: Definir variáveis de ambiente para o pipeline de liberação
O pipeline de liberação deste exemplo depende das seguintes variáveis de ambiente, que você pode adicionar clicando em Adicionar na seção Variáveis de pipeline na guia Variáveis, com um Escopo do Estágio 1:
-
BUNDLE_TARGET, que deve corresponder aotargetnome no seudatabricks.ymlficheiro. No exemplo deste artigo, este édev. -
DATABRICKS_HOST, que representa a URL por espaço de trabalho do seu espaço de trabalho do Azure Databricks, começando comhttps://, por exemplohttps://adb-<workspace-id>.<random-number>.azuredatabricks.net. Não inclua o trailing/após.net. -
DATABRICKS_CLIENT_ID, que representa a ID do aplicativo para a entidade de serviço do Microsoft Entra ID. -
DATABRICKS_CLIENT_SECRET, que representa o segredo OAuth do Azure Databricks para a entidade de serviço Microsoft Entra ID.
Etapa 3.2: Configurar o agente de liberação para o pipeline de liberação
Clique no link 1 trabalho, 0 tarefa dentro do objeto Estágio 1 .
Na guia Tarefas, clique em Trabalho do agente.
Na secção de seleção do agente, para o pool de agentes , selecione Azure Pipelines.
Para Agent Specification, selecione o mesmo agente que você especificou para o agente de compilação anteriormente, neste exemplo ubuntu-22.04.
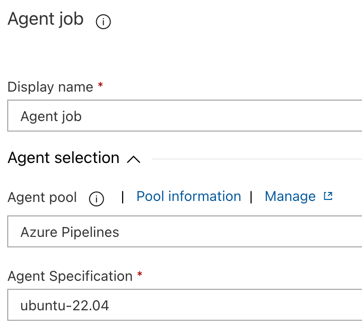
Clique em Salvar > OK.
Etapa 3.3: Definir a versão do Python para o release agent
Clique no sinal de adição na seção Trabalho do agente , indicado pela seta vermelha na figura a seguir. É apresentada uma lista pesquisável de tarefas disponíveis. Há também uma guia do Marketplace para plug-ins de terceiros que podem ser usados para complementar as tarefas padrão do Azure DevOps. Você adicionará várias tarefas ao agente de liberação durante as próximas etapas.
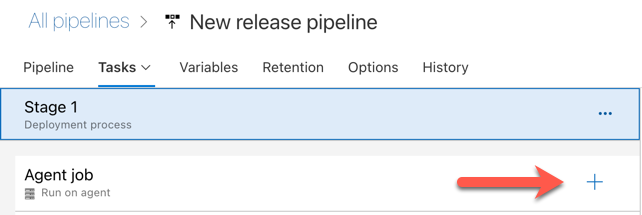
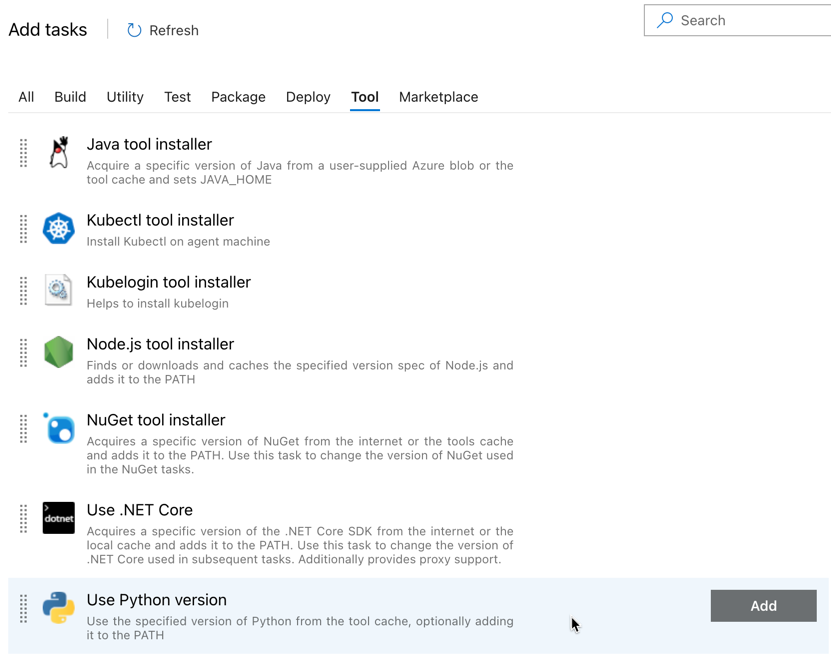
A primeira tarefa adicionada é Usar a versão do Python, localizada na guia Ferramenta . Se não conseguir encontrar esta tarefa, utilize a caixa Pesquisar para a procurar. Quando encontrá-lo, selecione-o e clique no botão Adicionar ao lado da tarefa Usar a versão do Python.
Assim como no pipeline de compilação, você deseja certificar-se de que a versão do Python é compatível com os scripts chamados nas tarefas subsequentes. Nesse caso, clique na tarefa Usar Python 3.x ao lado do trabalho do Agente e, em seguida, defina a especificação de versão como
3.10. Defina também Nome para exibição comoUse Python 3.10. Esse pipeline pressupõe que você esteja usando o Databricks Runtime 13.3 LTS nos clusters, que têm o Python 3.10.12 instalado.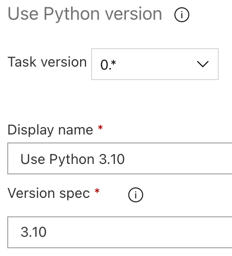
Clique em Salvar > OK.
Etapa 3.4: Descompactar o artefato de compilação do pipeline de compilação
Em seguida, peça ao agente de lançamento para extrair o ficheiro wheel do Python, os ficheiros de configurações de lançamento relacionados, os notebooks e o ficheiro de código Python do ficheiro zip usando a tarefa Extrair arquivos: clique no sinal de adição na secção de trabalho Agent, selecione a tarefa Extrair arquivos na aba Utility e, em seguida, clique em Adicionar.
Clique na tarefa Extrair arquivos ao lado de trabalho do agente , defina padrões de arquivo para Arquivar como
**/*.zipe defina a pasta de Destino para a variável de sistema$(Release.PrimaryArtifactSourceAlias)/Databricks. Além disso, defina Nome para exibição paraExtract build pipeline artifact.Nota
$(Release.PrimaryArtifactSourceAlias)representa um alias gerado pelo Azure DevOps para identificar o local de origem do artefato primário no agente de versão, por exemplo_<your-github-alias>.<your-github-repo-name>. O pipeline de liberação define esse valor como a variávelRELEASE_PRIMARYARTIFACTSOURCEALIASde ambiente na fase de trabalho Inicializar para o agente de liberação. Consulte Variáveis de liberação clássica e artefatos.Defina o nome de exibição para
Extract build pipeline artifact.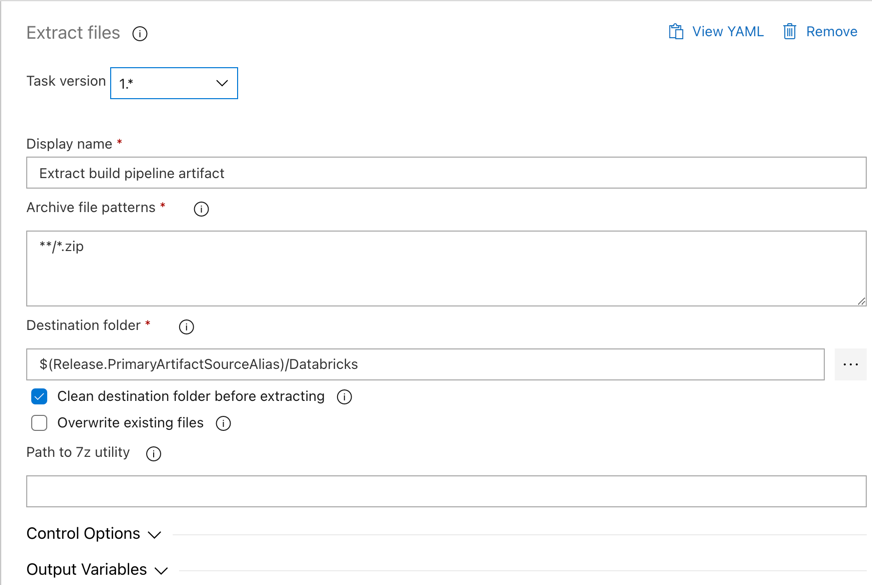
Clique em Salvar > OK.
Etapa 3.5: Definir a variável de ambiente BUNDLE_ROOT
Para que o exemplo deste artigo funcione conforme o esperado, você deve definir uma variável de ambiente chamada BUNDLE_ROOT no pipeline de versão. O Databricks Asset Bundles usa essa variável de ambiente para determinar onde o arquivo databricks.yml está localizado. Para definir esta variável de ambiente:
Use a tarefa Variáveis de Ambiente: clique no sinal de adição novamente na secção de trabalho do agente , selecione a tarefa Variáveis de Ambiente na guia de Utilitário e clique em Adicionar .
Nota
Se a tarefa Variáveis de Ambiente não for visível no separador Utilitário , introduza
Environment Variablesna caixa de Pesquisa e siga as instruções apresentadas no ecrã para adicionar a tarefa ao separador Utilitário . Pode ser necessário sair do Azure DevOps e regressar a este local onde parou.Para Variáveis de Ambiente (separadas por vírgula), insira a seguinte definição:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks.Nota
$(Agent.ReleaseDirectory)representa um alias gerado pelo Azure DevOps para identificar o local do diretório de versão no release agent, por exemplo/home/vsts/work/r1/a. O pipeline de liberação define esse valor como a variávelAGENT_RELEASEDIRECTORYde ambiente na fase de trabalho Inicializar para o agente de liberação. Consulte Variáveis de liberação clássica e artefatos. Para obter informações sobre$(Release.PrimaryArtifactSourceAlias)o , consulte a observação na etapa anterior.Configure o nome de exibição para
Set BUNDLE_ROOT environment variable.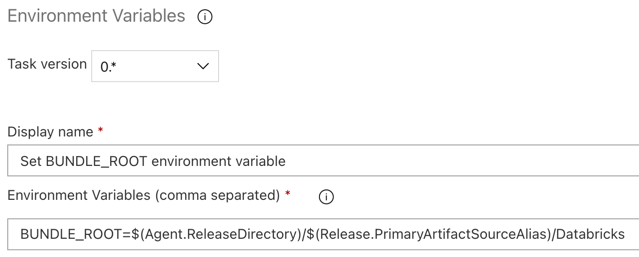
Clique em Salvar > OK.
Passo 3.6. Instale as ferramentas de construção de roda Databricks CLI e Python
Em seguida, instale as ferramentas de construção de roda Databricks CLI e Python no release agent. O agente de liberação chamará as ferramentas de construção de roda Databricks CLI e Python nas próximas tarefas. Para fazer isso, use a tarefa Bash: clique no sinal de adição novamente na seção de trabalho do Agent, selecione a tarefa Bash na guia Utility e clique em Adicionar.
Clique na tarefa Bash Script ao lado de Trabalho do agente.
Para Tipo, selecione embutido .
Substitua o conteúdo do Script pelo seguinte comando, que instala as ferramentas de construção de roda Databricks CLI e Python:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelDefina Nome para exibição como
Install Databricks CLI and Python wheel build tools.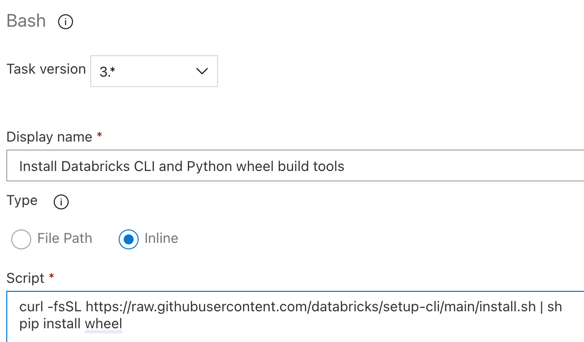
Clique em Salvar > OK.
Etapa 3.7: Validar o Databricks Asset Bundle
Nesta etapa, você se certifica de que o databricks.yml arquivo está sintaticamente correto.
Use a tarefa Bash: clique no sinal de adição novamente na secção de trabalho do Agente , selecione a tarefa Bash no separador do Utilitário e clique em Adicionar.
Clique na tarefa Bash Script ao lado de Trabalho do agente.
Para Tipo, selecione Embutido .
Substitua o conteúdo do Script pelo seguinte comando, que usa a CLI do Databricks para verificar se o
databricks.ymlarquivo está sintaticamente correto:databricks bundle validate -t $(BUNDLE_TARGET)Defina Nome para exibição como
Validate bundle.Clique em Salvar > OK.
Etapa 3.8: Implantar o pacote
Nesta etapa, você cria o arquivo de roda Python e implanta o arquivo de roda Python construído, os dois blocos de anotações Python e o arquivo Python do pipeline de versão para seu espaço de trabalho do Azure Databricks.
Use a tarefa Bash: clique no sinal de adição novamente na seção de trabalho do Agent, selecione a tarefa Bash na guia do Utilitário e clique em Adicionar.
Clique na tarefa Bash Script ao lado de Trabalho do agente.
Para Tipo, selecione Embutido .
Substitua o conteúdo de Script pelo comando a seguir, que usa a CLI do Databricks para criar o arquivo de roda Python e implantar os arquivos de exemplo deste artigo do pipeline de liberação para seu espaço de trabalho do Azure Databricks:
databricks bundle deploy -t $(BUNDLE_TARGET)Defina Nome para exibição como
Deploy bundle.Clique em Salvar > OK.
Etapa 3.9: Execute o bloco de anotações de teste de unidade para a roda Python
Nesta etapa, você executa um trabalho que executa o bloco de anotações de teste de unidade em seu espaço de trabalho do Azure Databricks. Este notebook executa testes de unidade em relação à lógica da biblioteca de rodas Python.
Use a tarefa Bash: clique no sinal de adição novamente na seção trabalho do Agente, selecione a tarefa Bash no separador Utilitário e clique em Adicionar.
Clique na tarefa Bash Script ao lado de Trabalho do agente.
Para Tipo, selecione embutido .
Substitua o conteúdo do Script pelo seguinte comando, que usa a CLI do Databricks para executar o trabalho em seu espaço de trabalho do Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsDefina Nome para exibição como
Run unit tests.Clique em Salvar > OK.
Etapa 3.10: Execute o notebook que chama a roda Python
Nesta etapa, você executa um trabalho que executa outro bloco de anotações em seu espaço de trabalho do Azure Databricks. Este bloco de anotações chama a biblioteca de rodas Python.
Use a tarefa Bash: clique no sinal de adição novamente na seção de trabalho do Agente , selecione a tarefa Bash na guia do Utilitário e clique em Adicionar.
Clique na tarefa Bash Script ao lado de Trabalho do agente.
Para Tipo, selecione Embutido.
Substitua o conteúdo do Script pelo seguinte comando, que usa a CLI do Databricks para executar o trabalho em seu espaço de trabalho do Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookDefina Nome para exibição como
Run notebook.Clique em Salvar > OK.
Agora você concluiu a configuração do pipeline de liberação. Deve ter a seguinte aparência:
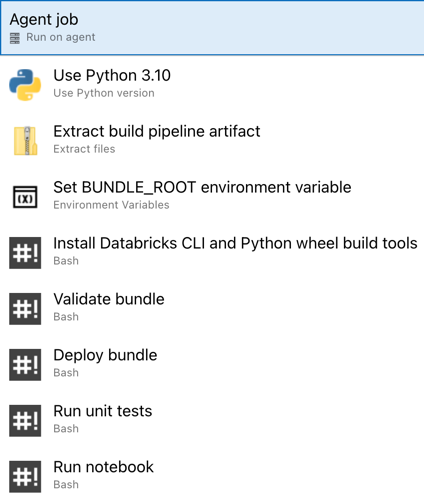
Etapa 4: Executar os pipelines de compilação e liberação
Nesta etapa, você executa os pipelines manualmente. Para saber como executar os pipelines automaticamente, consulte Especificar eventos que acionam pipelines e Acionadores de versão.
Para executar o pipeline de compilação manualmente:
- No menu Pipelines na barra lateral, clique em Pipelines.
- Clique no nome do pipeline de compilação e, em seguida, clique em Executar pipeline.
- Para Branch/tag, selecione o nome da ramificação no seu repositório Git que contém todo o código fonte que adicionou. Este exemplo pressupõe que isso esteja na
releaseramificação. - Clique em Executar. A página de execução do pipeline de compilação é exibida.
- Para ver o progresso do pipeline de compilação e visualizar os logs relacionados, clique no ícone giratório ao lado de Trabalho.
- Depois que o ícone Trabalho se transformar em uma marca de seleção verde, prossiga para executar o pipeline de liberação.
Para executar o pipeline de liberação manualmente:
- Depois que o pipeline de compilação for executado com êxito, no menu Pipelines na barra lateral, clique em Releases.
- Clique no nome do pipeline de liberação e, em seguida, clique em Criar versão.
- Clique em Criar.
- Para ver o progresso do pipeline de lançamento, na lista de versões, clique no nome da versão mais recente.
- Na caixa Estágios, clique em Estágio 1 e clique em Logs.