Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Nota
Este artigo aborda o Databricks Connect para Databricks Runtime 13.3 LTS e versões superiores.
O Databricks Connect permite conectar IDEs populares, como o PyCharm, servidores de notebook e outros aplicativos personalizados, à computação do Azure Databricks. Consulte O que é Databricks Connect?.
Este artigo demonstra como começar rapidamente com o Databricks Connect para Python usando PyCharm.
- Para a versão R deste artigo, consulte Databricks Connect for R.
- Para a versão Scala deste artigo, consulte Databricks Connect for Scala.
Guia de Aprendizagem
No tutorial a seguir, você cria um projeto no PyCharm, instala o Databricks Connect for Databricks Runtime 13.3 LTS e superior e executa código simples em computação em seu espaço de trabalho Databricks do PyCharm. Para obter informações adicionais e exemplos, consulte Próximas etapas.
Requisitos
Para concluir este tutorial, você deve atender aos seguintes requisitos:
- Seu espaço de trabalho do Azure Databricks de destino deve ter o Unity Catalog habilitado.
- Você tem o PyCharm instalado. Este tutorial foi testado com o PyCharm Community Edition 2023.3.5. Se você usar uma versão ou edição diferente do PyCharm, as instruções a seguir podem variar.
- Seu ambiente local e computação atendem aos requisitos de versão de instalação do Databricks Connect for Python .
- Se você estiver usando computação clássica, precisará da ID do cluster. Para obter a ID do cluster, no espaço de trabalho, clique em Computação na barra lateral e, em seguida, clique no nome do cluster. Na barra de endereço do navegador da Web, copie a cadeia de caracteres entre
clusterseconfigurationno URL.
Etapa 1: Configurar a autenticação do Azure Databricks
Este tutorial usa a autenticação OAuth de usuário-para-máquina (U2M) do Azure Databricks e um perfil de configuração do Azure Databricks para autenticar no espaço de trabalho do Azure Databricks. Para usar um tipo de autenticação diferente, consulte Configurar propriedades de conexão.
A configuração da autenticação U2M do OAuth requer a CLI do Databricks. Para obter informações sobre como instalar a CLI do Databricks, consulte Instalar ou atualizar a CLI do Databricks.
Inicie a autenticação OAuth U2M, da seguinte maneira:
Use a CLI do Databricks para iniciar o gerenciamento de token OAuth localmente executando o seguinte comando para cada espaço de trabalho de destino.
No comando a seguir, substitua
<workspace-url>pela URL por espaço de trabalho do Azure Databricks, por exemplo .databricks auth login --configure-cluster --host <workspace-url>Gorjeta
Para usar a computação sem servidor com o Databricks Connect, consulte Configurar uma conexão com computação sem servidor.
A CLI do Databricks solicita que você salve as informações inseridas como um perfil de configuração do Azure Databricks. Pressione
Enterpara aceitar o nome de perfil sugerido ou digite o nome de um perfil novo ou existente. Qualquer perfil existente com o mesmo nome é substituído pelas informações que você inseriu. Você pode usar perfis para alternar rapidamente seu contexto de autenticação em vários espaços de trabalho.Para obter uma lista de quaisquer perfis existentes, em um terminal ou prompt de comando separado, use a CLI do Databricks para executar o comando
databricks auth profiles. Para visualizar as configurações existentes de um perfil específico, execute o comandodatabricks auth env --profile <profile-name>.No navegador da Web, conclua as instruções na tela para fazer logon no espaço de trabalho do Azure Databricks.
Na lista de clusters disponíveis que aparece no seu terminal ou prompt de comando, use as teclas de seta para cima e seta para baixo para selecionar o cluster Azure Databricks de destino no seu espaço de trabalho e pressione
Enter. Você também pode digitar qualquer parte do nome de exibição do cluster para filtrar a lista de clusters disponíveis.Para exibir o valor atual do token OAuth de um perfil e o carimbo de data/hora de expiração do token, execute um dos seguintes comandos:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Se tiver vários perfis com o mesmo valor
--host, talvez seja necessário especificar as opções--hoste-pem conjunto para ajudar a CLI do Databricks a encontrar as informações corretas do token OAuth.
Etapa 2: Criar o projeto
- Inicie o PyCharm.
- No menu principal, clique em Arquivo > Novo Projeto.
- Na caixa de diálogo Novo projeto, clique em Python puro.
- Em Local, clique no ícone da pasta e conclua as instruções na tela para especificar o caminho para seu novo projeto Python.
- Deixe a opção Criar um script de boas-vindas main.py selecionada.
- Para Tipo de intérprete, clique em Project venv.
- Expanda a versão do Python e use o ícone de pasta ou a lista suspensa para especificar o caminho para o interpretador Python dos requisitos anteriores.
- Clique em Criar.
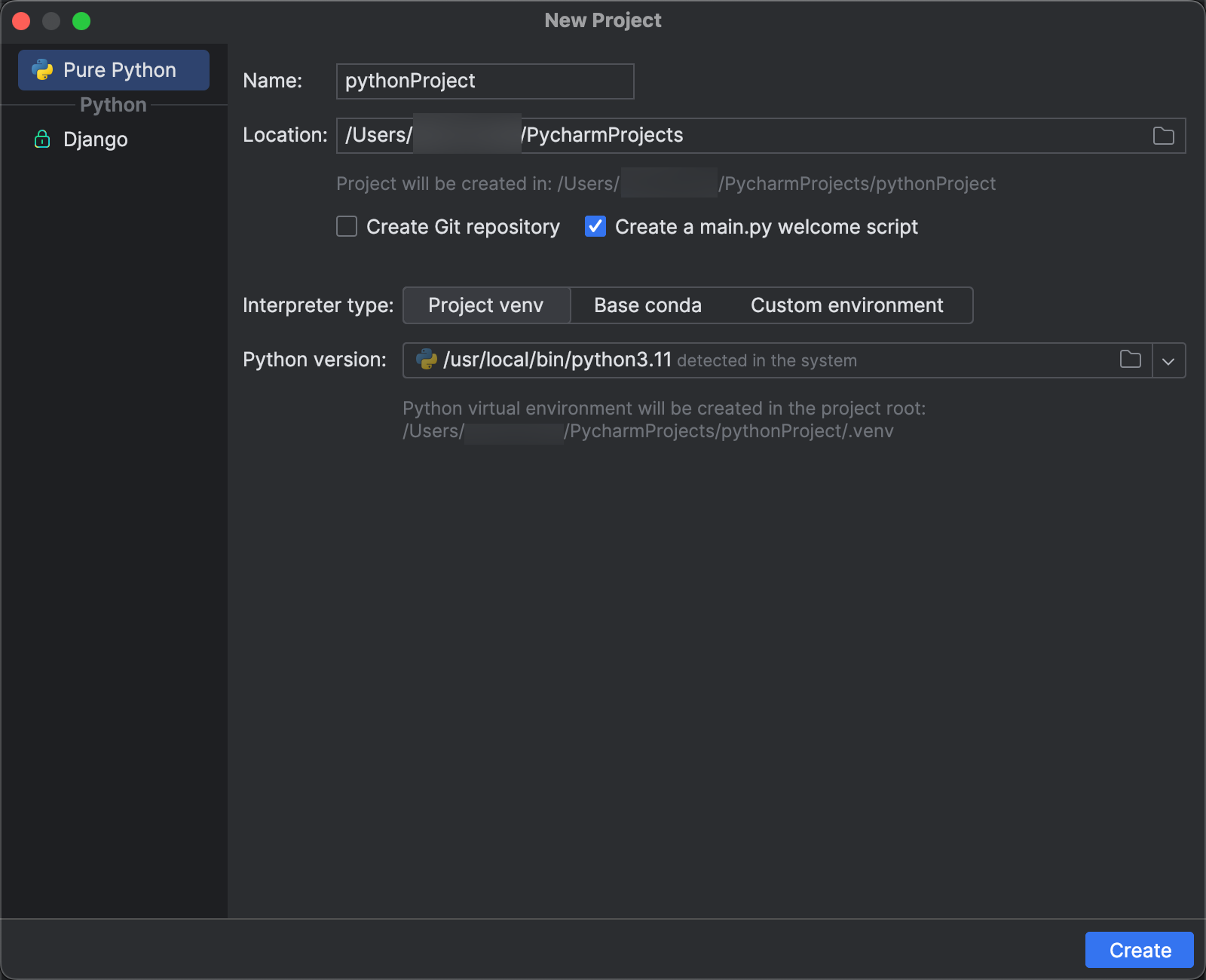
Etapa 3: Adicionar o pacote Databricks Connect
- No menu principal do PyCharm, clique em View > Tool Windows > Python Packages.
- Na caixa de pesquisa, introduza
databricks-connect. - Na lista do repositório PyPI, clique em databricks-connect.
- Na lista suspensa mais recente do painel de resultados, selecione a versão que corresponde à versão do Databricks Runtime do cluster. Por exemplo, se o cluster tiver o Databricks Runtime 14.3 instalado, selecione 14.3.1.
- Clique em Instalar pacote.
- Depois de o pacote ser instalado, poderás fechar a janela Pacotes Python.
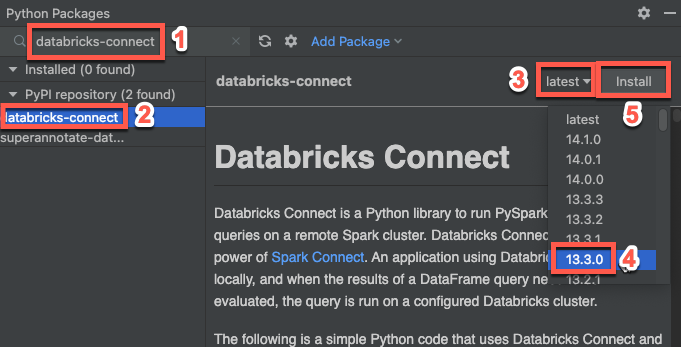
Passo 4: Adicionar código
Na janela da ferramenta Project , clique com o botão direito do mouse na pasta raiz do projeto e clique em New > Python File.
Insira
main.pye clique duas vezes em ficheiro Python.Insira o seguinte código no arquivo e salve-o, dependendo do nome do seu perfil de configuração.
Se o seu perfil de configuração da Etapa 1 for nomeado
DEFAULT, insira o seguinte código no arquivo e salve o arquivo:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)Se o seu perfil de configuração da Etapa 1 não for nomeado
DEFAULT, insira o código a seguir no arquivo. Substitua o espaço reservado<profile-name>pelo nome do seu perfil de configuração na Etapa 1 e salve o arquivo:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
Etapa 5: Executar o código
- Inicie o cluster de destino em seu espaço de trabalho remoto do Azure Databricks.
- Depois que o cluster for iniciado, no menu principal, clique em Executar > executar 'main'.
- Na janela Executar (Ver > Janelas de Ferramentas > Executar), no painel principal da aba Executar, as primeiras 5 linhas do
samples.nyctaxi.tripsaparecem.
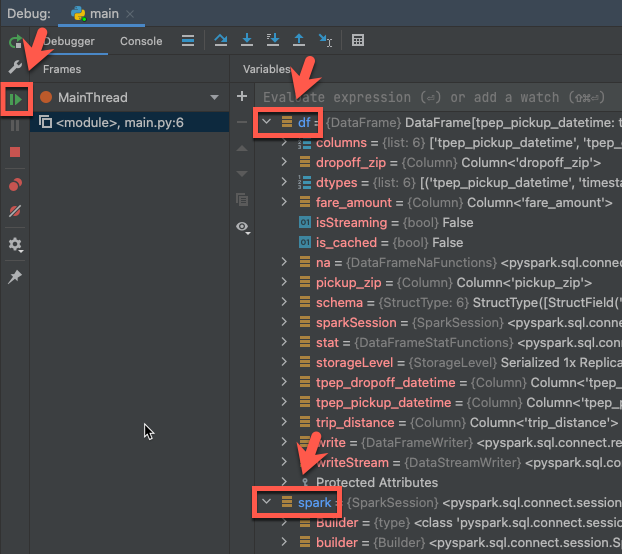
Etapa 6: Depurar o código
- Com o cluster ainda em execução, no código anterior, clique na margem ao lado de
df.show(5)para definir um ponto de interrupção. - No menu principal, clique em >.
- Na janela da ferramenta Depurar (Ver > Janelas de Ferramentas > Depurar), no painel Variáveis do separador Depurador, expanda os nós das variáveis df e spark para procurar informações sobre o código
dfe assparkvariáveis. - Na barra lateral da janela da ferramenta Depurar , clique no ícone de seta verde (Retomar Programa).
- No painel Console da guia Depurador, as primeiras 5 linhas do
samples.nyctaxi.tripssão exibidas.
Próximos passos
Para saber mais sobre o Databricks Connect, consulte artigos como os seguintes:
- Para usar um tipo de autenticação diferente, consulte Configurar propriedades de conexão.
- Use o Databricks Connect com outros IDEs, servidores de notebook e o shell do Spark.
- Para exibir exemplos de código simples adicionais, consulte Exemplos de código para Databricks Connect for Python.
- Para visualizar exemplos de código mais complexos, consulte os aplicativos de exemplo para o repositório Databricks Connect no GitHub, especificamente:
- Para usar utilitários Databricks com Databricks Connect, consulte Utilitários Databricks com Databricks Connect para Python.
- Para migrar do Databricks Connect for Databricks Runtime 12.2 LTS e inferior para o Databricks Connect for Databricks Runtime 13.3 LTS e superior, consulte Migrar para o Databricks Connect for Python.
- Consulte também informações sobre solução de problemas e limitações.