Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este tutorial orienta você pelo uso de um bloco de anotações do Azure Databricks para importar dados de um arquivo CSV contendo dados de nome de bebê de health.data.ny.gov para o volume do Catálogo Unity usando Python, Scala e R. Você também aprende a modificar um nome de coluna, visualizar os dados e salvar em uma tabela.
Observação
Se estiveres a usar o Databricks Free Edition, seleciona o separador Python para todos os exemplos de código neste tutorial. A Free Edition não suporta R nem Scala. Além disso, a Free Edition restringe o acesso à internet de saída, por isso deve carregar o ficheiro CSV usando a interface do workspace em vez de o descarregar com código. Consulte o Passo 3 para instruções detalhadas.
Requisitos
Para concluir as tarefas neste artigo, você deve atender aos seguintes requisitos:
- Seu espaço de trabalho deve ter Unity Catalog habilitado. Para obter informações sobre como começar a usar o Unity Catalog, consulte Introdução ao Unity Catalog. O Azure Databricks Free Edition e os espaços de trabalho de teste gratuitos têm o Unity Catalog ativado por defeito.
- Você deve ter o privilégio
WRITE VOLUMEnum volume, o privilégioUSE SCHEMAno esquema pai e o privilégioUSE CATALOGno catálogo pai. Os utilizadores da Free Edition têm estes privilégios no catálogo edefaultesquema do espaço de trabalho por defeito. - Você deve ter permissão para usar um recurso de computação existente ou criar um novo recurso de computação. Veja Compute ou consulte o seu administrador do Azure Databricks.
Gorjeta
Para obter um bloco de anotações concluído para este artigo, consulte Importar e visualizar blocos de anotações de dados.
Etapa 1: Criar um novo bloco de anotações
Para criar um bloco de notas na sua área de trabalho, clique ![]() em Novo na barra lateral e, em seguida, clique em Bloco de Notas. Um bloco de anotações em branco é aberto no espaço de trabalho.
em Novo na barra lateral e, em seguida, clique em Bloco de Notas. Um bloco de anotações em branco é aberto no espaço de trabalho.
Para saber mais sobre como criar e gerir cadernos, consulte Gerir cadernos Databricks.
Etapa 2: Definir variáveis
Nesta etapa, você define variáveis para uso no bloco de anotações de exemplo criado neste artigo. Precisas dos nomes de um catálogo do Unity Catalog, de um esquema do Unity Catalog, e de um volume do Unity Catalog.
Gorjeta
Se não souber o seu catálogo e nomes de esquemas, clique no ![]() Catálogo na barra lateral. O catálogo de espaços de trabalho partilha um nome com o seu espaço de trabalho e está listado no painel do catálogo. Expande-o para ver os esquemas disponíveis. Os utilizadores da Edição Gratuita e da versão de avaliação gratuita podem usar o catálogo do espaço de trabalho e o
Catálogo na barra lateral. O catálogo de espaços de trabalho partilha um nome com o seu espaço de trabalho e está listado no painel do catálogo. Expande-o para ver os esquemas disponíveis. Os utilizadores da Edição Gratuita e da versão de avaliação gratuita podem usar o catálogo do espaço de trabalho e o default esquema.
Se não tiver um volume, crie um executando o seguinte comando numa célula de caderno (substitua <catalog_name> e <schema_name> pelos seus valores):
CREATE VOLUME IF NOT EXISTS <catalog_name>.<schema_name>.my_volume
Copie e cole o código a seguir na nova célula vazia do bloco de anotações. Substitua
<catalog-name>,<schema-name>e<volume-name>pelos nomes de catálogo, esquema e volume de um volume do Catálogo Unity. Opcionalmente, substitua o valortable_namepor um nome de tabela de sua escolha. Guarda os dados do nome do bebé nesta tabela mais à frente neste artigo.Pressione
Shift+Enterpara executar a célula e criar uma nova célula em branco.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathlinguagem de programação Scala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Etapa 3: Importar arquivo CSV
Nesta etapa, importa-se um arquivo CSV com dados sobre nomes de bebés do health.data.ny.gov para o volume do Catálogo Unity. Escolha um dos métodos seguintes:
- Carregar usando a interface do workspace — Use este método se estiver na Databricks Free Edition, ou se o download do código na opção B falhar devido a um erro de rede. A Free Edition e outros ambientes de computação serverless restringem o acesso à internet de saída, por isso deve carregar o ficheiro a partir da sua máquina local.
- Descarregue usando código — Use este método se o seu ambiente de computação tiver acesso à internet de saída.
Opção A: Carregar usando a interface do espaço de trabalho
- Na sua máquina local, abra health.data.ny.gov/api/views/jxy9-yhdk/rows.csv no seu navegador. O ficheiro é descarregado para o seu computador como
rows.csv. - Encontre o ficheiro descarregado no seu computador e renomeie-o de
rows.csvparababy_names.csv. Isto corresponde àfile_namevariável que definiste no Passo 2. - Volta ao teu espaço de trabalho Azure Databricks. Na barra lateral, clique
 Novo > Adicionar ou carregar dados.
Novo > Adicionar ou carregar dados. - Clique em Carregar ficheiros para um volume.
- Clique Navegar e seleciona o
baby_names.csvficheiro, ou arrasta-o e larga-o na área de carregamento. - Em Volume de destino, selecione o volume que especificou no Passo 2.
- Depois de terminar o upload, volte ao seu caderno e continue com o Passo 4.
Para mais detalhes sobre o carregamento de ficheiros, consulte Trabalhar com ficheiros em volumes do Catálogo Unity.
Opção B: Descarregar usando código
Copie e cole o código a seguir na nova célula vazia do bloco de anotações. Este código copia o ficheiro
rows.csvde health.data.ny.gov para o seu volume do Catálogo Unity usando o comando Databricks dbutils.Pressione
Shift+Enterpara executar a célula e, em seguida, vá para a próxima célula.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")linguagem de programação Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Etapa 4: Carregar dados CSV em um DataFrame
Nesta etapa, você cria um DataFrame chamado df a partir do arquivo CSV que você carregou anteriormente no volume do Catálogo Unity usando o método spark.read.csv.
Copie e cole o código a seguir na nova célula vazia do bloco de anotações. Esse código carrega dados de nome do bebê no DataFrame
dfa partir do arquivo CSV.Pressione
Shift+Enterpara executar a célula e, em seguida, vá para a próxima célula.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")linguagem de programação Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Você pode carregar dados de muitos formatos de arquivo suportados.
Etapa 5: visualizar dados do notebook
Nesta etapa, você usa o método display() para exibir o conteúdo do DataFrame em uma tabela no bloco de anotações e, em seguida, visualizar os dados em um gráfico de nuvem de palavras no bloco de anotações.
Copie e cole o código a seguir na nova célula vazia do notebook e, em seguida, clique em Executar célula para exibir dados em uma tabela.
Python
display(df)linguagem de programação Scala
display(df)R
display(df)Analise os resultados na tabela.
Ao lado do separador Tabela, clique em + e, em seguida, clique em Visualização.
No editor de visualização, clique em Tipo de Visualização e verifique se a nuvem de palavras está selecionada.
Na coluna Palavras, verifique se
First Nameestá selecionado.No Limites de Frequências, clique em
35.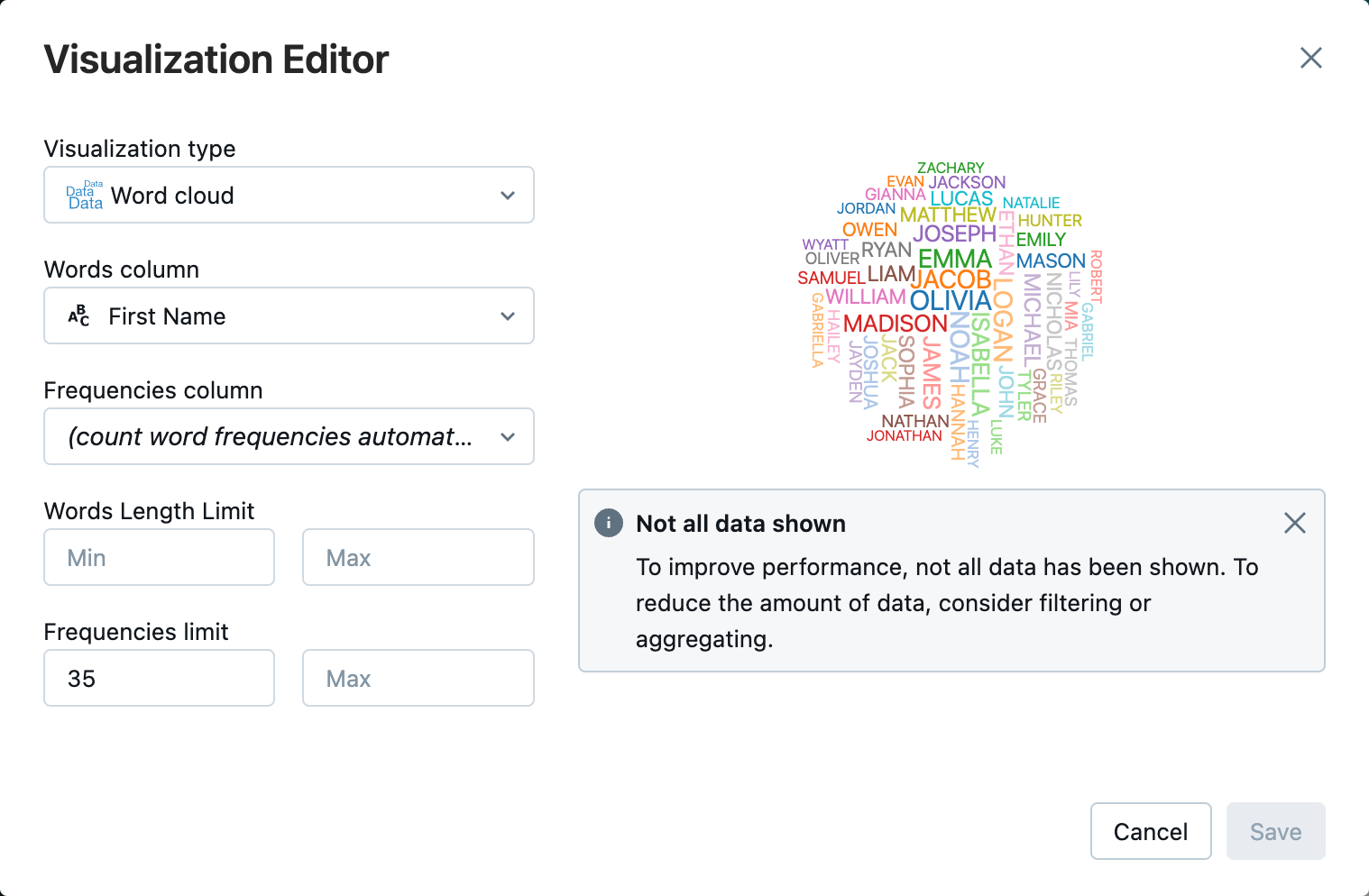
Clique em Guardar.
Etapa 6: Salvar o DataFrame em uma tabela
Importante
Para salvar seu DataFrame no Unity Catalog, você deve ter privilégios de tabela CREATE no catálogo e no esquema. Para obter informações sobre permissões no Catálogo Unity, consulte Privilégios e objetos protegíveis no Unity Catalog e Gerenciar privilégios no Unity Catalog.
Copie e cole o código a seguir em uma célula vazia do bloco de anotações. Este código substitui um espaço no nome da coluna. Caracteres especiais, como espaços, não são permitidos em nomes de coluna. Este código usa o método Apache Spark
withColumnRenamed().Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemalinguagem de programação Scala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Copie e cole o código a seguir em uma célula vazia do bloco de anotações. Esse código salva o conteúdo do DataFrame em uma tabela no Unity Catalog usando a variável de nome de tabela que você definiu no início deste artigo.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")linguagem de programação Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Para verificar se a tabela foi salva, clique em Catálogo na barra lateral esquerda para abrir a interface do utilizador do Catalog Explorer. Abra o catálogo e, em seguida, o esquema para verificar se a tabela aparece.
Clique na tabela para visualizar o esquema da tabela na aba Visão Geral.
Clique em Dados de Exemplo para exibir 100 linhas de dados da tabela.
Importar e visualizar blocos de anotações de dados
Use um dos seguintes blocos de anotações para executar as etapas neste artigo. Substitua <catalog-name>, <schema-name>e <volume-name> pelos nomes de catálogo, esquema e volume de um volume do Catálogo Unity. Opcionalmente, substitua o valor table_name por um nome de tabela de sua escolha.
Python
Importar dados de CSV usando Python
linguagem de programação Scala
Importar dados do CSV usando o Scala
R
Importar dados do CSV usando R
Próximos passos
- Para saber mais sobre técnicas de análise exploratória de dados (EDA), consulte Tutorial: técnicas de EDA usando blocos de anotações Databricks.
- Para aprender sobre como construir um pipeline ETL (extrair, transformar e carregar), veja o Tutorial: Construir um pipeline ETL com pipelines Lakeflow e o Tutorial: Construir um pipeline ETL com Apache Spark na plataforma Databricks