Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Um data lakehouse é um sistema de gestão de dados que combina os benefícios de data lakes e data warehouses. Este artigo descreve o padrão de arquitetura lakehouse e o que você pode fazer com ele no Azure Databricks.
Para que serve um data lakehouse?
Um data lakehouse fornece recursos escaláveis de armazenamento e processamento para organizações modernas que desejam evitar sistemas isolados para processar diferentes cargas de trabalho, como aprendizado de máquina (ML) e business intelligence (BI). Um data lakehouse pode ajudar a estabelecer uma única fonte de verdade, eliminar custos redundantes e garantir a atualização dos dados.
Os data lakehouses geralmente usam um padrão de design de dados que melhora, enriquece e refina incrementalmente os dados à medida que eles se movem por camadas de preparação e transformação. Cada camada da casa do lago pode incluir uma ou mais camadas. Este padrão é frequentemente referido como uma arquitetura medalhão. Para obter mais informações, consulte O que é a arquitetura do medallion lakehouse?
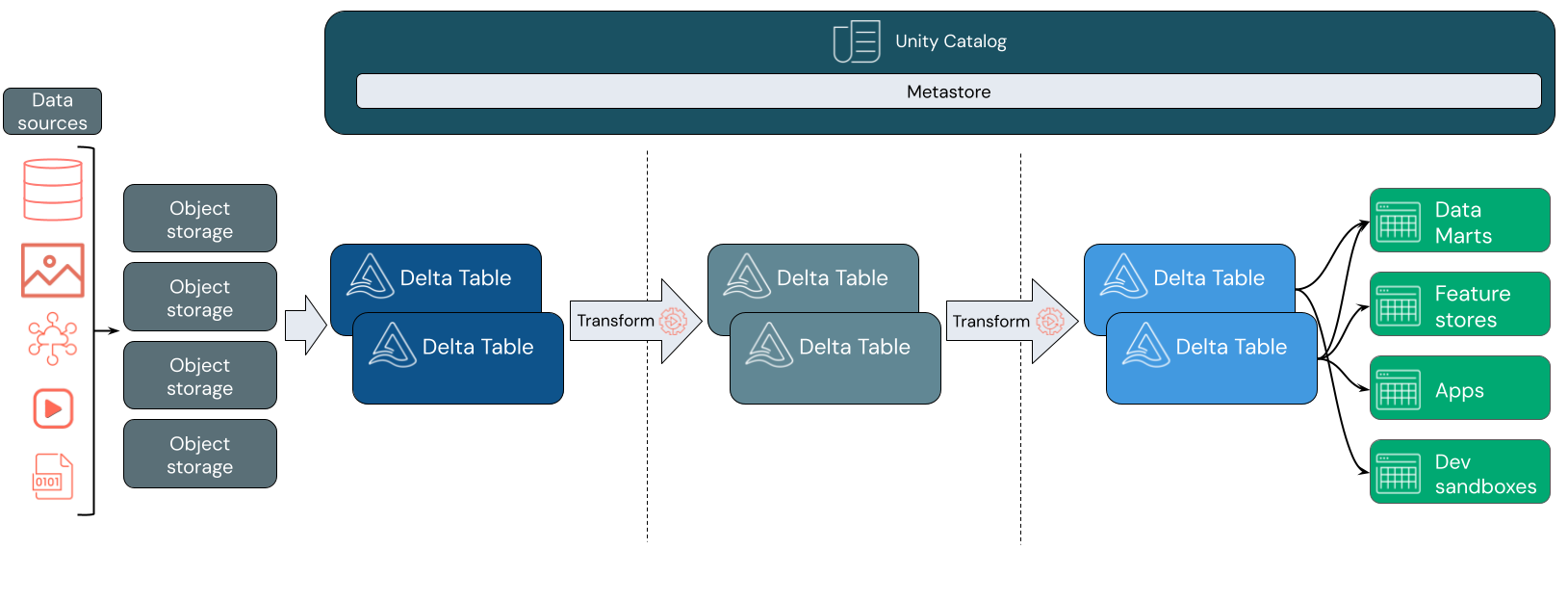
Como funciona o lago Databricks?
O Databricks é construído no Apache Spark. O Apache Spark permite um mecanismo massivamente escalável que é executado em recursos de computação dissociados do armazenamento. Para obter mais informações, consulte Visão geral do Apache Spark
O lago Databricks usa duas tecnologias-chave adicionais:
- Delta Lake: uma camada de armazenamento otimizada que suporta transações ACID e imposição de esquema.
- Unity Catalog: uma solução de governança unificada e refinada para dados e IA.
Ingestão de dados
Na camada de ingestão, os dados em lote ou streaming chegam de uma variedade de fontes e em uma variedade de formatos. Essa primeira camada lógica fornece um local para que esses dados aterrissem em seu formato bruto. Ao converter esses arquivos em tabelas Delta, você pode usar os recursos de imposição de esquema do Delta Lake para verificar se há dados ausentes ou inesperados. Você pode usar o Unity Catalog para registrar tabelas de acordo com seu modelo de governança de dados e limites de isolamento de dados necessários. O Unity Catalog permite que você acompanhe a linhagem de seus dados à medida que são transformados e refinados, bem como aplique um modelo de governança unificado para manter os dados confidenciais privados e seguros.
Processamento, curadoria e integração de dados
Uma vez verificado, pode começar a organizar e refinar os seus dados. Cientistas de dados e profissionais de aprendizado de máquina frequentemente trabalham com dados neste estágio para começar a combinar ou criar novos recursos e limpar dados completos. Uma vez que seus dados tenham sido completamente limpos, eles podem ser integrados e reorganizados em tabelas projetadas para atender às suas necessidades específicas de negócios.
Uma abordagem schema-on-write, combinada com os recursos de evolução do esquema Delta, significa que você pode fazer alterações nessa camada sem necessariamente ter que reescrever a lógica downstream que fornece dados aos usuários finais.
Fornecimento de dados
A camada final fornece dados limpos e enriquecidos aos usuários finais. As tabelas finais devem ser projetadas para fornecer dados para todos os seus casos de uso. Um modelo de governança unificado significa que você pode rastrear a linhagem de dados até sua única fonte de verdade. Os layouts de dados, otimizados para diferentes tarefas, permitem que os usuários finais acessem dados para aplicativos de aprendizado de máquina, engenharia de dados, business intelligence e relatórios.
Para saber mais sobre o Delta Lake, consulte O que é Delta Lake no Azure Databricks? Para saber mais sobre o Unity Catalog, consulte O que é o Unity Catalog?
Capacidades de um lago Databricks
Um lakehouse construído em Databricks substitui a dependência atual de data lakes e data warehouses para empresas de dados modernas. Algumas das principais tarefas que você pode executar incluem:
- Processamento de dados em tempo real: processe dados em fluxo contínuo em tempo real para análise imediata e ação.
- Integração de dados: Unifique seus dados em um único sistema para permitir a colaboração e estabelecer uma única fonte de verdade para sua organização.
- Evolução do esquema: Modifique o esquema de dados ao longo do tempo para se adaptar às necessidades de negócios em constante mudança sem interromper os pipelines de dados existentes.
- Transformações de dados: Usar o Apache Spark e o Delta Lake traz velocidade, escalabilidade e confiabilidade aos seus dados.
- Análise de dados e emissão de relatórios: Execute consultas analíticas complexas com um mecanismo otimizado para cargas de trabalho de data warehouse.
- Aprendizado de máquina e IA: Aplique técnicas avançadas de análise a todos os seus dados. Use o ML para enriquecer seus dados e dar suporte a outras cargas de trabalho.
- Versionamento e linhagem de dados: Mantenha o histórico de versões de conjuntos de dados e rastreie a linhagem para garantir a procedência e rastreabilidade dos dados.
- Governança de dados: Use um sistema único e unificado para controlar o acesso aos seus dados e realizar auditorias.
- Compartilhamento de dados: Facilite a colaboração permitindo o compartilhamento de conjuntos de dados, relatórios e insights selecionados entre as equipes.
- Análise operacional: Monitore métricas de qualidade de dados, métricas de qualidade de modelo e desvio usando o Monitoramento de Qualidade de Dados.
Lakehouse vs Data Lake vs Data Warehouse
Os armazéns de dados têm impulsionado as decisões de business intelligence (BI) há cerca de 30 anos, tendo evoluído como um conjunto de diretrizes de projeto para sistemas que controlam o fluxo de dados. Os armazéns de dados corporativos otimizam consultas para relatórios de BI, mas podem levar minutos ou até horas para gerar resultados. Projetados para dados que provavelmente não serão alterados com alta frequência, os data warehouses procuram evitar conflitos entre consultas em execução simultânea. Muitos armazéns de dados dependem de formatos proprietários, que muitas vezes limitam o suporte para aprendizado de máquina. O armazenamento de dados no Azure Databricks aproveita os recursos de um Databricks lakehouse e Databricks SQL. Para obter mais informações, consulte Data warehousing on Azure Databricks.
Impulsionados pelos avanços tecnológicos no armazenamento de dados e impulsionados por aumentos exponenciais nos tipos e volume de dados, os data lakes passaram a ser amplamente utilizados na última década. Os data lakes armazenam e processam dados de forma barata e eficiente. Os data lakes são frequentemente definidos em oposição aos data warehouses: um data warehouse fornece dados limpos e estruturados para análise de BI, enquanto um data lake armazena dados de qualquer natureza de forma permanente e barata em qualquer formato. Muitas organizações usam data lakes para ciência de dados e aprendizado de máquina, mas não para relatórios de BI devido à sua natureza não validada.
O data lakehouse combina os benefícios dos data lakes e dos data warehouses e oferece soluções abrangentes de armazenamento e análise de dados.
- Acesso aberto e direto aos dados armazenados em formatos de dados padrão.
- Protocolos de indexação otimizados para machine learning e ciência de dados.
- Baixa latência de consulta e alta confiabilidade para BI e análises avançadas.
Ao combinar uma camada de metadados otimizada com dados validados armazenados em formatos padrão no armazenamento de objetos em nuvem, o Data Lakehouse permite que você trabalhe a partir dos mesmos dados e na mesma plataforma em diferentes casos de uso.
Próximo passo
Para saber mais sobre os princípios e as práticas recomendadas para implementar e operar um lakehouse usando Databricks, veja Introdução ao data lakehouse bem arquitetado