Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Esta página apresenta o Data Engineering Agent, que adiciona capacidades ao Databricks Assistant. Para usar o Agente de Engenharia de Dados, selecione o modo Agente no Assistente.
O agente de Engenharia de Dados foi concebido especificamente para Lakeflow Spark Declarative Pipelines (SDP) e para o Lakeflow Pipelines Editor, explora dados, gera e executa código de pipeline, e corrige erros, tudo a partir de um único prompt.
O que é o Agente de Engenharia de Dados?
O Agente de Engenharia de Dados é uma capacidade poderosa no Modo Agente Assistente Databricks que transforma o Assistente num parceiro autónomo capaz de automatizar fluxos de trabalho inteiros de engenharia de dados em múltiplos passos no SDP e no Editor de Pipelines Lakeflow.
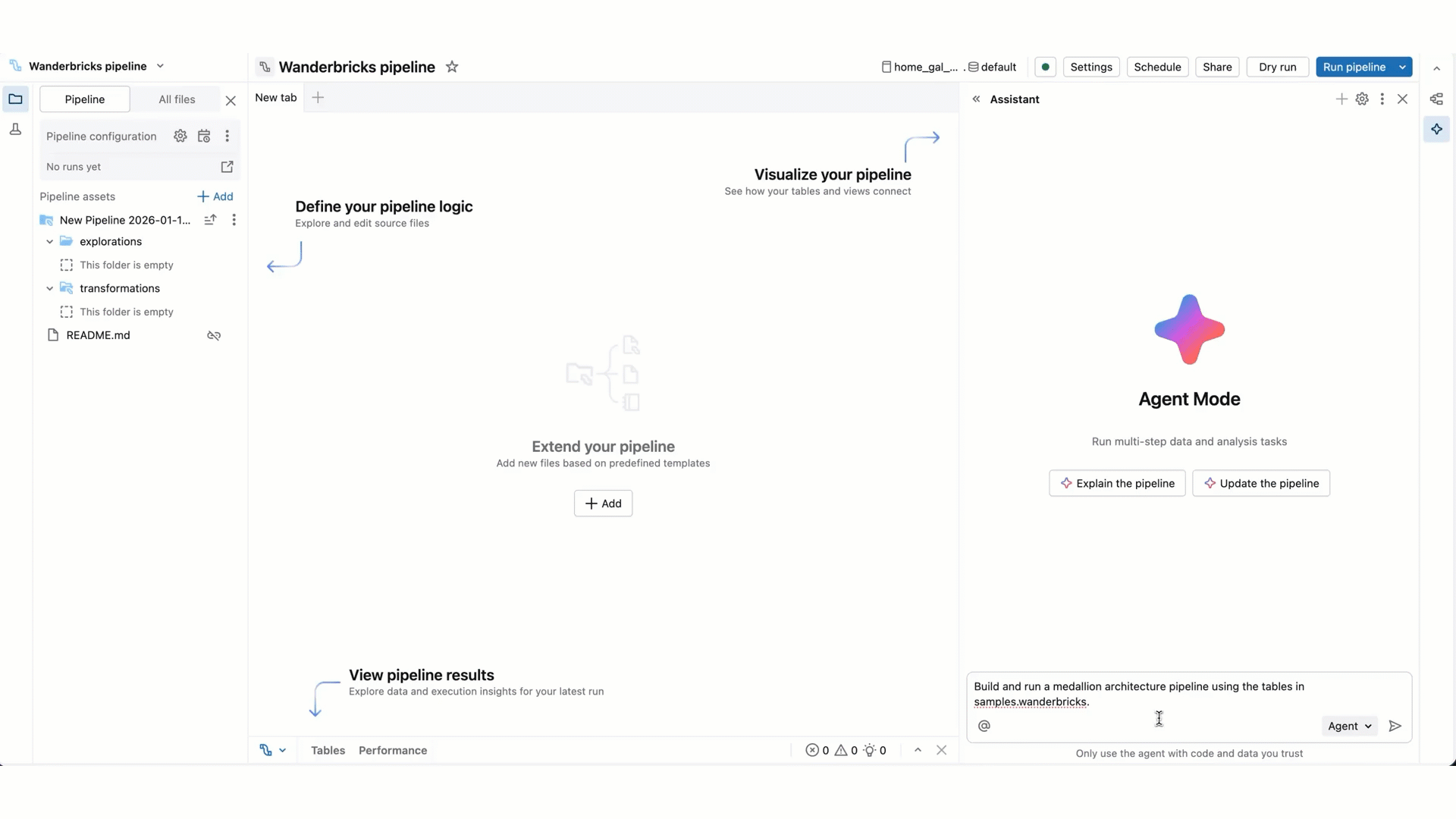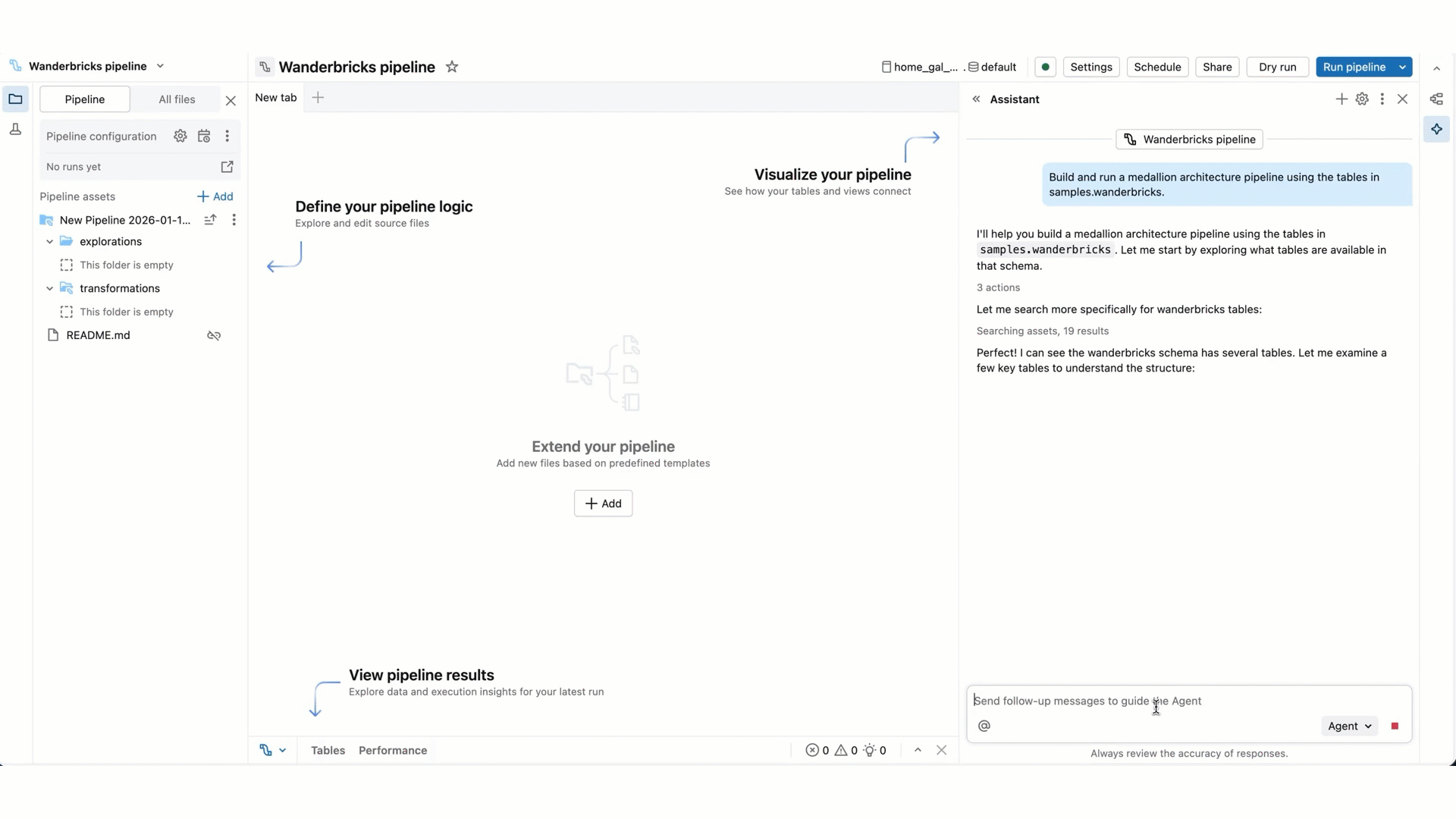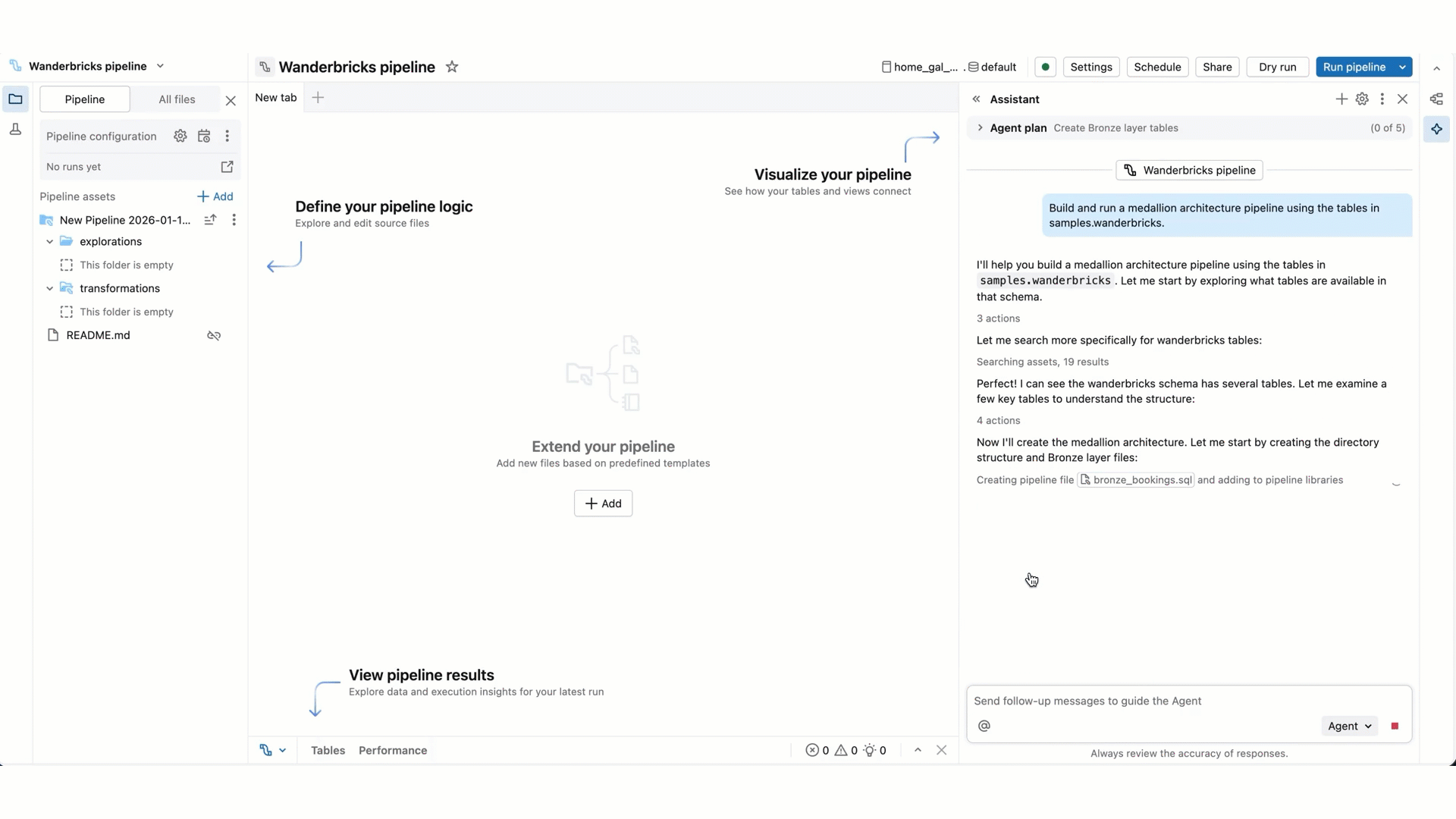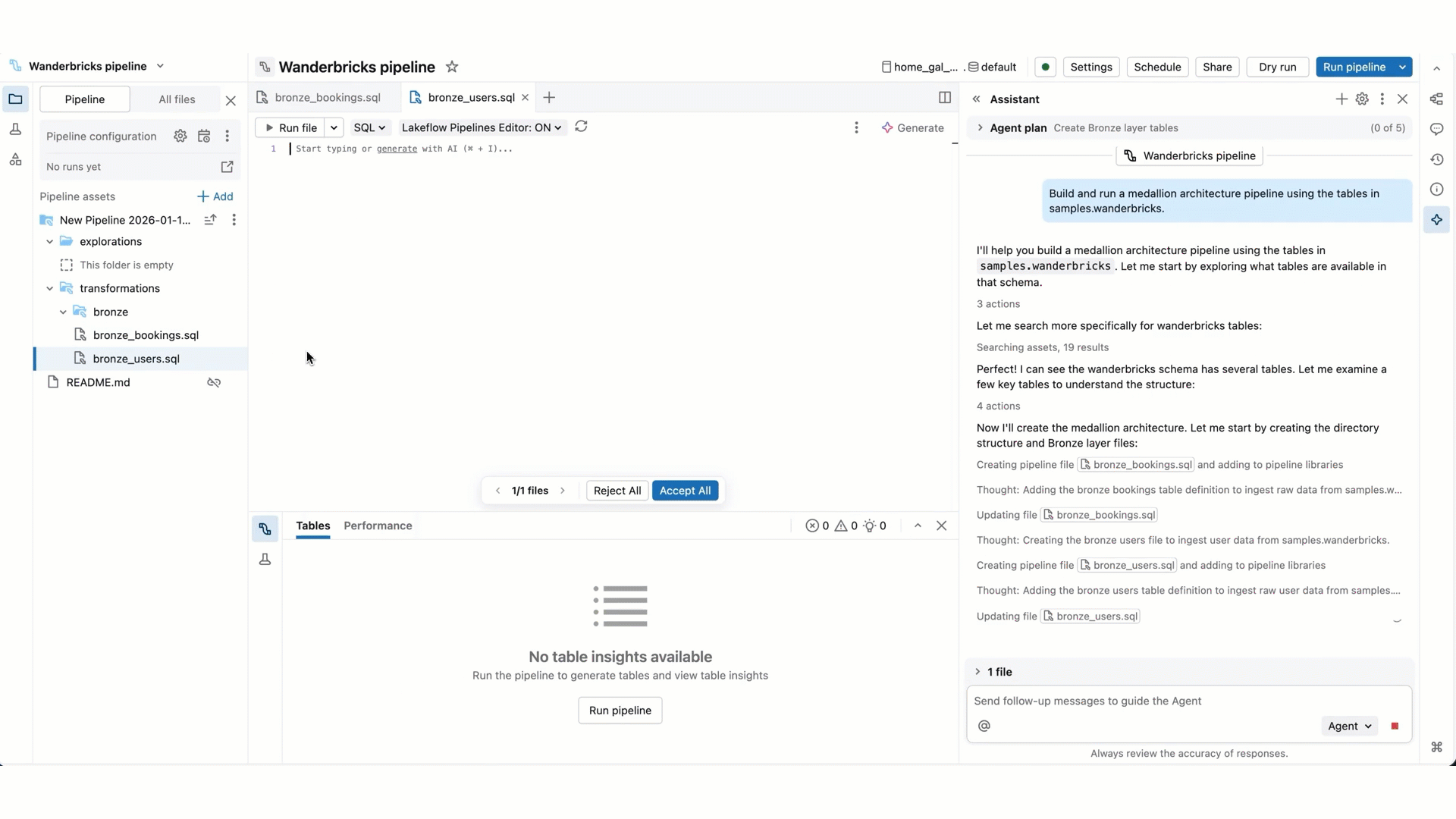
Comparado com o modo de chat Assistente, o modo agente tem capacidades alargadas: planear uma solução, recuperar ativos relevantes, executar código, usar saídas de pipeline para melhorar resultados, corrigir erros automaticamente e muito mais.
O Agente de Engenharia de Dados pode planear e gerar pipelines inteiros de ponta a ponta do zero, ou acelerar o trabalho num pipeline existente. O agente trabalha consigo para aprovar os seus planos e confirmar os próximos passos antes de avançar. Com a sua aprovação, o Agente de Engenharia de Dados pode usar ferramentas para realizar tarefas como pesquisa em tabelas, editar um ficheiro fonte SQL ou Python, executar atualizações de pipeline e ler conjuntos de dados de pipelines.
O acesso e as ações do Agente de Engenharia de Dados são regidos pelas permissões do utilizador. Ele só pode acessar dados aos quais você tem acesso e executar operações para as quais você tem permissões.
Observação
Quando ativas o modo agente no Assistente, o Assistente adapta as suas capacidades com base nas funcionalidades que estás a usar atualmente no Databricks. Por exemplo, no Lakeflow Pipelines Editor, o Assistente foca-se em tarefas de edição de pipelines e engenharia de dados. Nos cadernos e no Editor SQL, o assistente suporta a exploração e análise de dados. Consulte Agente de Ciência de Dados para mais informações.
Requerimentos
Para utilizar o Agente de Engenharia de Dados, o seu espaço de trabalho precisa do seguinte:
- Recursos de IA baseados em parceiros habilitados para a conta e o espaço de trabalho. Consulte Funcionalidades de IA potenciadas por parceiros.
- Modo de pré-visualização do Assistente Databricks no Modo Agente ativado. Consulte Gerenciar visualizações do Azure Databricks.
Use o Agente de Engenharia de Dados
Para usar o Agente de Engenharia de Dados:
A partir do Editor de Pipelines Lakeflow, abra o painel lateral do Assistente clicando no
 Assistente no canto superior direito do seu espaço de trabalho.
Assistente no canto superior direito do seu espaço de trabalho.No canto inferior direito, selecione Agente. Isto ativa o modo agente do Assistente, permitindo-lhe interagir com o Agente de Engenharia de Dados.
Introduza um prompt para o agente. Por exemplo, podes fazer perguntas sobre o teu fluxo de trabalho, como "descreve este fluxo de trabalho". Também pode pedir para adicionar novos conjuntos de dados, por exemplo, "criar silver_sales_data num novo ficheiro que leia bronze_sales_data e limpe os dados e adicione expectativas úteis de qualidade."
Observação
O agente respeita as permissões do Catálogo Unity do utilizador, pelo que só pode aceder aos dados e à fonte do pipeline a que tem acesso.
À medida que o agente gera a sua resposta, muitas vezes faz uma pausa para obter a sua opinião:
Para tarefas mais complexas, o agente pode criar um plano passo-a-passo e fazer perguntas esclarecedoras. Responda às perguntas esclarecedoras do agente para o ajudar a aprimorar o seu plano.
Quando o agente precisa de executar código ou atualizar um pipeline, pede a sua aprovação antes de avançar. Permitir ou Recusar sua solicitação. Você também pode selecionar Permitir neste thread (referindo-se ao thread de conversa do Assistente) ou Sempre permitir.
Importante
O Agente de Engenharia de Dados pode gerar e executar código no seu pipeline. Embora tenha guarda-corpos para evitar ações perigosas, ainda há risco. Deves usá-lo apenas com dados de confiança e deves rever o código antes de o executar.
À medida que o agente continua o seu trabalho, poderá ser solicitado a selecionar Continuar ou Rejeitar. Revise o trabalho existente do agente, depois selecione Continuar para permitir que o agente continue para os próximos passos ou Rejeitar para lhe dizer que tente outra coisa.
Para parar o agente enquanto está a trabalhar, clique no

O agente pode criar novos ficheiros, gerar texto, consultas e código, executar ficheiros ou pipelines e aceder aos conjuntos de dados de saída para interpretar os resultados.
Observação
Para que o Agente de Engenharia de Dados continue o seu trabalho e tome os próximos passos, é necessário manter-se no separador atual onde o agente está a trabalhar.
Sugestão
Pode adicionar instruções para o agente usar na maioria das respostas. Por exemplo, se tiver convenções de código que queira usar, ou bibliotecas preferidas para usar, pode adicionar estas diretrizes às instruções do agente. Também pode criar competências para expandir o agente com capacidades especializadas para tarefas específicas do seu domínio. Para mais detalhes e outras dicas, consulte Personalizar e melhorar as respostas do Databricks Assistant.
Capabilities
O Agente de Engenharia de Dados pode ajudar na maioria das tarefas de desenvolvimento de pipelines. As capacidades-chave incluem:
- Descoberta de dados: O agente pode pesquisar tabelas no espaço de trabalho para o ajudar a encontrar os dados necessários para uma tarefa.
- Edições de código de pipeline: O agente pode simultaneamente criar e editar vários ficheiros. Mantém-te informado sobre quais os ficheiros que está a alterar e mostra-te o diferencial de código em cada ficheiro, para que possas rever as alterações individualmente ou em conjunto no final.
- Execução do pipeline: O agente pode executar ficheiros individuais, fazer uma execução em modo de teste/executar o pipeline ou realizar uma atualização completa. Quando o agente quer avançar, pede a sua confirmação antes de o fazer.
- Compreender e melhorar o comportamento do pipeline: O agente pode inspecionar conjuntos de dados e saídas do pipeline para o ajudar a compreender o que um pipeline está a fazer de ponta a ponta e porquê. Por exemplo, pode resumir transformações, traçar como os dados fluem para as tabelas a jusante e destacar alterações inesperadas no número de linhas ou nos esquemas. Quando surgir potenciais problemas de qualidade dos dados, o agente pode ajudá-lo a raciocinar sobre a sua causa e sugerir onde e como resolvê-los no processo.
Estas capacidades suportam casos de uso comuns tais como:
- Criar um novo pipeline: O Agente de Engenharia de Dados pode ajudar em todas as etapas da criação de um novo pipeline de arquitetura medallion, desde a ingestão de dados, à padronização e limpeza dos dados, até à sua transformação e análise.
- Explique um pipeline: O agente pode analisar e explicar um pipeline existente para o ajudar a acelerar rapidamente.
- Corrigir problemas: Quando tem erros, o agente pode ajudar a diagnosticar e corrigir os problemas, iterando por vários ficheiros até que o problema seja resolvido.
Examples
Tente as seguintes instruções para começar:
- Construa e execute um pipeline de arquitetura medallion para detecção de fraude usando as transações da tabela e os dados dos clientes em my_catalog.my_schema.
- Explica cada passo deste processo.
- "Corrige a falha neste pipeline."
Próximos passos
- Saiba mais sobre as funcionalidades assistivas de IA do Databricks
- Obtenha dicas para personalizar e melhorar as respostas do Databricks Assistant
- Use o Data Science Agent para descoberta e exploração de dados
- Explore o Editor de Pipelines Lakeflow