Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo contém recomendações para implementar expectativas em escala e exemplos de padrões avançados suportados por expectativas. Esses padrões usam vários conjuntos de dados em conjunto com as expectativas e exigem que os usuários entendam a sintaxe e a semântica de exibições materializadas, tabelas de streaming e expectativas.
Para obter uma visão geral básica do comportamento e da sintaxe das expectativas, consulte Gerenciar a qualidade dos dados com as expectativas do pipeline.
Expectativas portáteis e reutilizáveis
A Databricks recomenda as seguintes práticas recomendadas ao implementar expectativas para melhorar a portabilidade e reduzir os encargos de manutenção:
| Recommendation | Impacto |
|---|---|
| Armazene as definições de expectativa separadamente da lógica de pipeline. | Aplique facilmente as expectativas a vários conjuntos de dados ou pipelines. Atualize, audite e mantenha as expectativas sem modificar o código-fonte do pipeline. |
| Adicione tags personalizadas para criar grupos de expectativas relacionadas. | Filtre expectativas com base em tags. |
| Aplique as expectativas de forma consistente em conjuntos de dados semelhantes. | Use as mesmas expectativas em vários conjuntos de dados e pipelines para avaliar lógica idêntica. |
Os exemplos a seguir demonstram o uso de uma tabela ou dicionário Delta para criar um repositório central de expectativas. Em seguida, as funções Python personalizadas aplicam essas expectativas a conjuntos de dados em um pipeline de exemplo:
Note
O carregamento dinâmico das expectativas de um ficheiro não é suportado em SQL.
Tabela Delta
O exemplo a seguir cria uma tabela nomeada rules para manter regras:
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
O exemplo Python a seguir define as expectativas de qualidade de dados com base nas regras da rules tabela. A get_rules() função lê as regras da rules tabela e retorna um dicionário Python contendo regras correspondentes ao tag argumento passado para a função.
Neste exemplo, o dicionário é aplicado usando @dp.expect_all_or_drop() decoradores para impor restrições de qualidade de dados.
Por exemplo, quaisquer registros que falhem nas regras e estejam marcados com validity serão retirados da tabela raw_farmers_market.
from pyspark import pipelines as dp
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Módulo Python
O exemplo a seguir cria um módulo Python para manter regras. Para este exemplo, armazene esse código em um arquivo nomeado rules_module.py na mesma pasta que o bloco de anotações usado como código-fonte para o pipeline:
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
O exemplo Python a seguir define as expectativas de qualidade de dados com base nas regras definidas no rules_module.py arquivo. A get_rules() função retorna um dicionário Python contendo regras correspondentes ao tag argumento passado para ela.
Neste exemplo, o dicionário é aplicado usando @dp.expect_all_or_drop() decoradores para impor restrições de qualidade de dados.
Por exemplo, quaisquer registros que falhem nas regras e estejam marcados com validity serão retirados da tabela raw_farmers_market.
from pyspark import pipelines as dp
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Validação da contagem de linhas
O exemplo a seguir valida a igualdade de contagem de linhas entre table_a e table_b para verificar se nenhum dado é perdido durante as transformações:
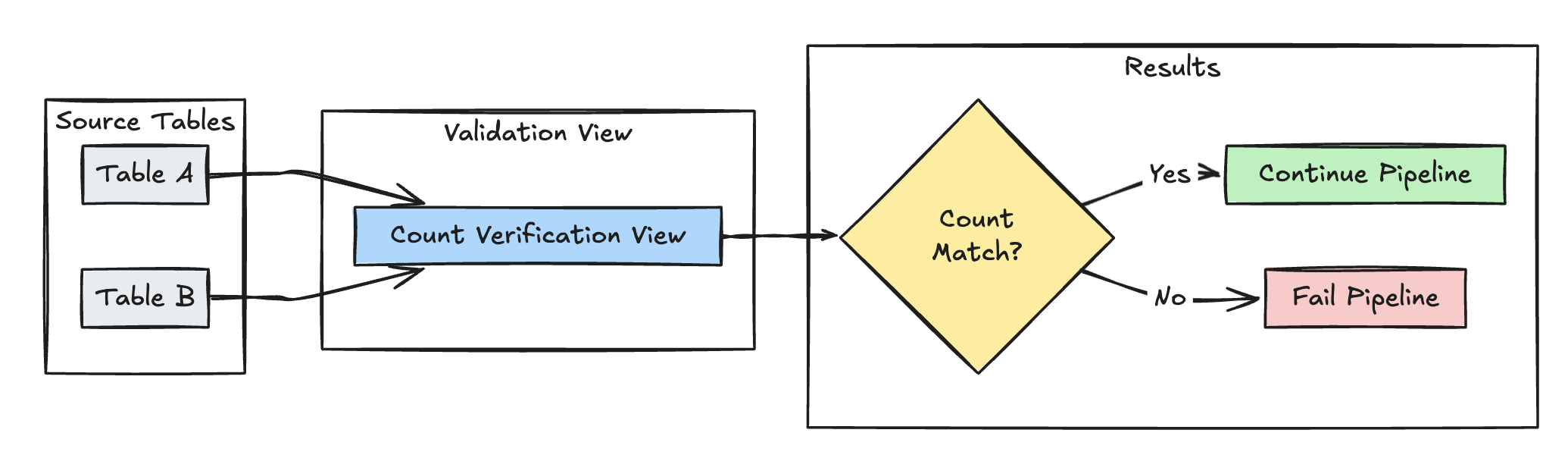
Python
@dp.view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dp.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
SQL
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
Deteção de registro ausente
O exemplo seguinte valida que todos os registos esperados estão presentes na tabela report.
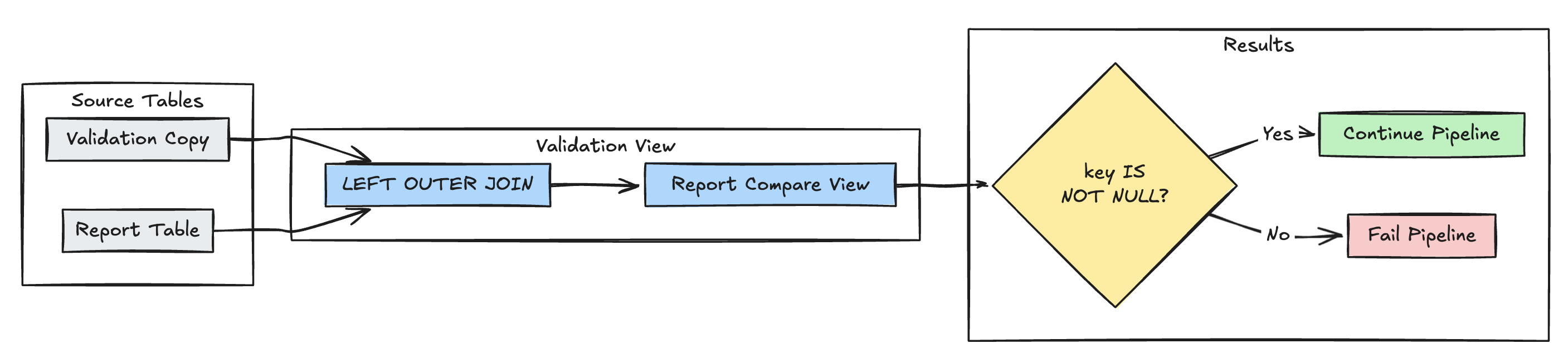
Python
@dp.view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dp.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
spark.read.table("validation_copy").alias("v")
.join(
spark.read.table("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
Exclusividade da chave primária
O exemplo a seguir valida restrições de chave primária entre tabelas:
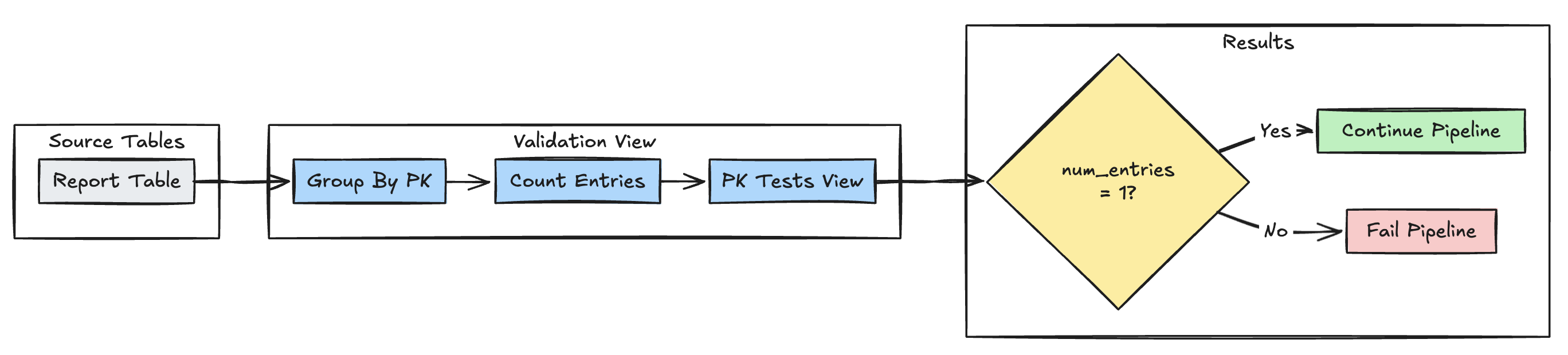
Python
@dp.view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dp.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
spark.read.table("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
Padrão de evolução do esquema
O exemplo a seguir mostra como manipular a evolução do esquema para colunas adicionais. Use este padrão ao migrar fontes de dados ou lidar com várias versões de dados de origem, garantindo compatibilidade retroativa e assegurando a qualidade dos dados.
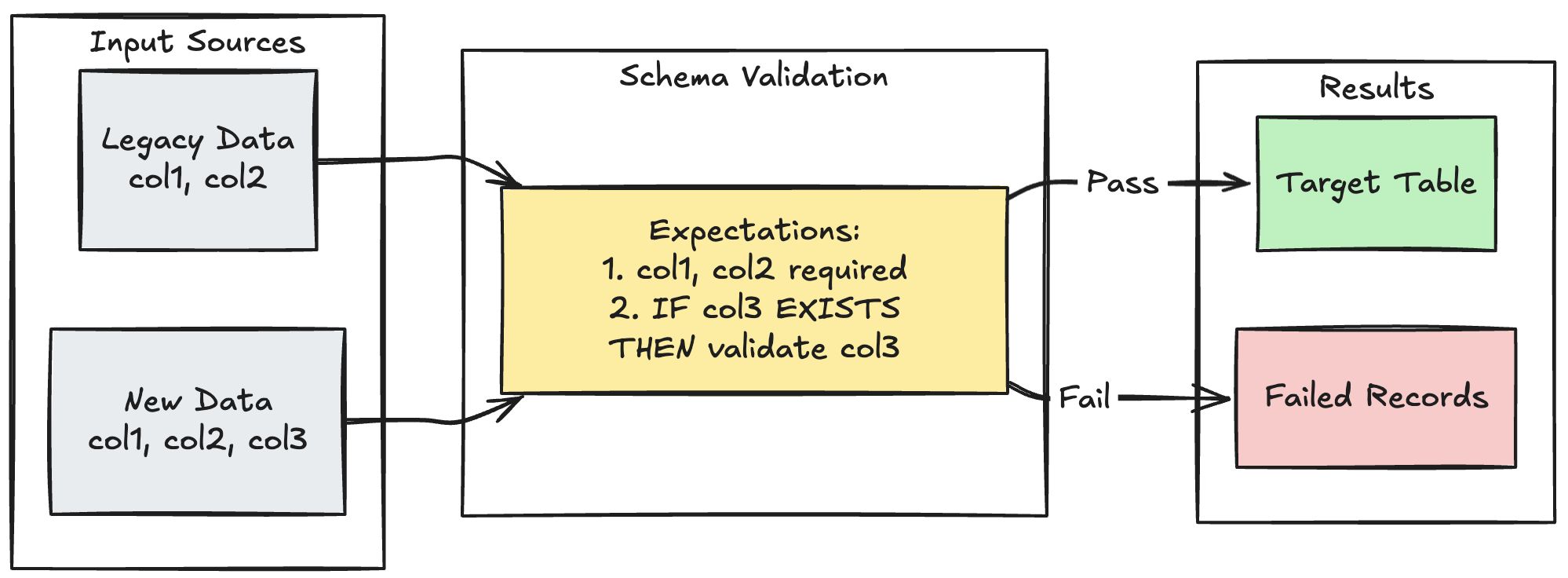
Python
@dp.table
@dp.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
SQL
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
Padrão de validação baseado em intervalo
O exemplo a seguir demonstra como validar novos pontos de dados em relação a intervalos estatísticos históricos, ajudando a identificar valores atípicos e anomalias no fluxo de dados:
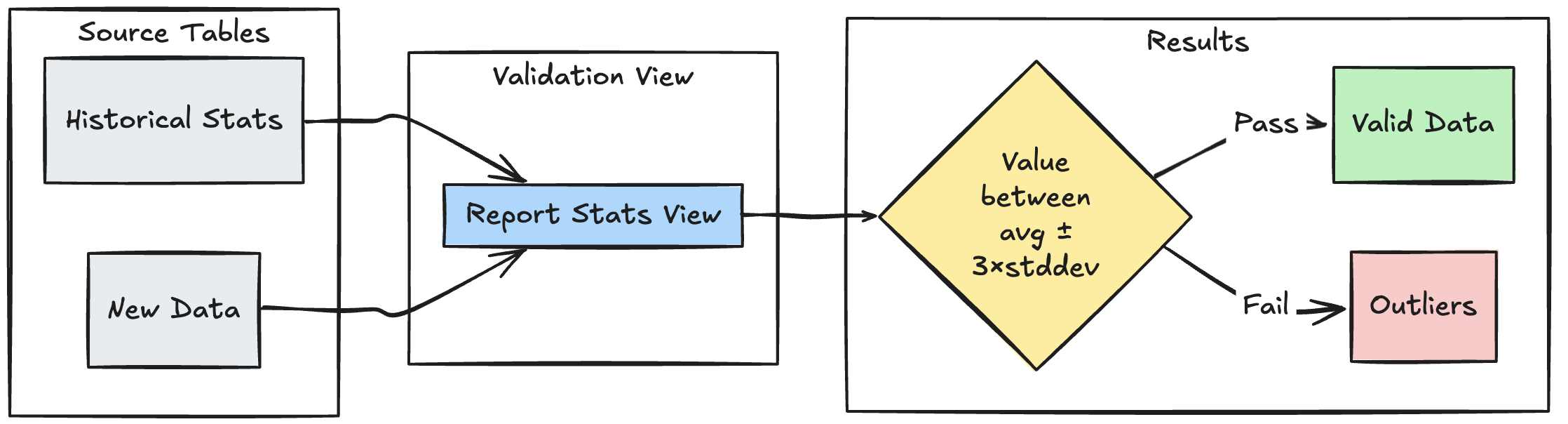
Python
@dp.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dp.table
@dp.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return spark.read.table("stats_validation_view")
SQL
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
Quarentena de registos inválidos
Esse padrão combina expectativas com tabelas e exibições temporárias para rastrear métricas de qualidade de dados durante atualizações de pipeline e permitir caminhos de processamento separados para registros válidos e inválidos em operações downstream.
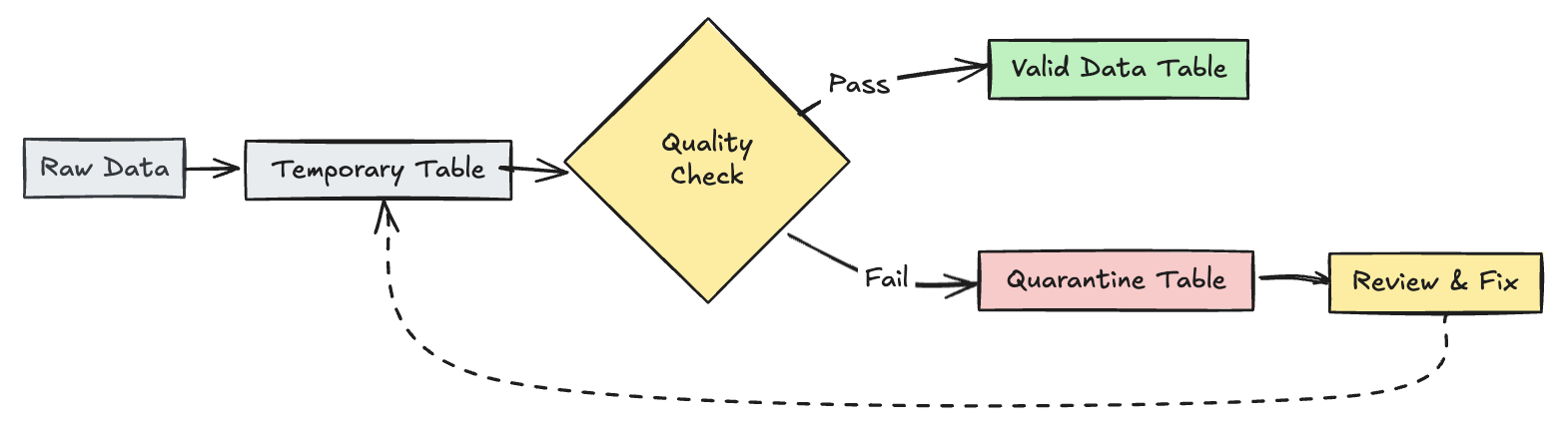
Python
from pyspark import pipelines as dp
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dp.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dp.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dp.expect_all(rules)
def trips_data_quarantine():
return (
spark.readStream.table("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dp.view
def valid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=false")
@dp.view
def invalid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=true")
SQL
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;