Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Crias um novo pipeline Lakeflow para orquestração de dados com o Auto Loader, depois estendes o pipeline de amostras limpando os dados e criando uma consulta para encontrar os 100 utilizadores principais.
Neste tutorial, aprende a usar o Lakeflow Pipelines Editor para:
- Crie um novo pipeline com a estrutura de pastas padrão e comece com um conjunto de ficheiros de exemplo.
- Defina as restrições de qualidade dos dados usando expectativas.
- Use as funcionalidades do editor para estender o pipeline com uma nova transformação para realizar análises nos seus dados.
Requerimentos
Antes de começares este tutorial, deves:
- Esteja logado num espaço de trabalho Azure Databricks.
- Tenha o Unity Catalog ativado para o seu espaço de trabalho.
- Ter permissão para criar um recurso de computação ou acesso a um recurso de computação.
- Ter permissões para criar um novo esquema num catálogo. As permissões necessárias são
ALL PRIVILEGESouUSE CATALOGeCREATE SCHEMA. - Para o conjunto completo de privilégios necessários para criar, executar, atualizar e visualizar pipelines e os seus resultados, consulte Gerir identidades, permissões e privilégios para pipelines.
Etapa 1: Criar um pipeline
Neste passo, cria-se um pipeline usando a estrutura de pastas padrão e exemplos de código. Os exemplos de código referenciam a users tabela na wanderbricks fonte de dados de exemplo.
No seu espaço de trabalho Azure Databricks, clique em
 Novo, depois
Novo, depois  ETL pipeline. Isto abre o editor de pipeline com um nome de pipeline predefinido como
ETL pipeline. Isto abre o editor de pipeline com um nome de pipeline predefinido como New Pipeline <date> <time>.(Opcional) Selecione o nome e insira um nome descritivo para o pipeline.
(Opcional) À direita do nome, clique no catálogo e no esquema para definir diferentes predefinições.
(Opcional) No ficheiro fonte
my_transformationcriado para si, selecione Python ou SQL na lista suspensa de linguagem para definir a linguagem do ficheiro.Clica
 Usa código de exemplo.
Usa código de exemplo.O código de exemplo na língua selecionada aparece no
my_transformationficheiro fonte natransformationspasta. Os conjuntos de dados de saída ainda não foram criados, e o gráfico Pipeline no lado direito do ecrã está vazio.Para executar o código do pipeline (o código na
transformationspasta), clique em Executar pipeline no canto superior direito do ecrã.Após a conclusão da execução, a parte inferior do espaço de trabalho mostra as duas novas tabelas que foram criadas,
sample_users_<date_time>esample_aggregation_<date_time>. O gráfico do pipeline no lado direito do espaço de trabalho mostra agora as duas tabelas, mostrando também quesample_usersé a origem desample_aggregation. Anota o nome completosample_users_<date_time>da tabela; refere-o no passo seguinte.
Passo 2: Aplicar verificações de qualidade dos dados
Neste passo, adiciona uma verificação de qualidade dos dados à sample_users tabela.
Utiliza-se as expectativas do pipeline para restringir os dados. Neste caso, apaga quaisquer registos de utilizador que não tenham um endereço de email válido e produz a tabela limpa como users_cleaned.
No navegador de ativos do pipeline à esquerda, clique
e selecione Transformação.No diálogo Criar novo ficheiro de transformação , faça as seguintes seleções:
- Escolha Python ou SQL para a Language. Isto não tem de corresponder à sua escolha anterior.
- Dá um nome ao ficheiro. Neste caso, escolha
users_cleaned. - Para o caminho de destino, mantenha o padrão.
- Para o tipo de conjunto de dados, deixe-o como Nenhum selecionado ou escolha a vista Materializada. Se selecionares vista materializada, gera código de exemplo para ti.
Clique em Criar para criar o ficheiro de código de transformação.
No teu novo ficheiro de código, edita o código para corresponder ao seguinte (usa SQL ou Python, com base na tua seleção no ecrã anterior). Substitui
sample_users_<date_time>pelo nome completo da tuasample_userstabela da secção anterior.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )Clique em Executar pipeline para atualizar o pipeline. Agora deveria ter três mesas.
Passo 3: Analisar os principais utilizadores
De seguida, obtenha os 100 melhores utilizadores pelo número de reservas que fizeram. Junta a wanderbricks.bookings tabela à users_cleaned vista materializada.
No navegador de ativos do pipeline, à esquerda, clique
e selecione Transformação.No diálogo Criar novo ficheiro de transformação , faça as seguintes seleções:
- Escolha Python ou SQL para a Language. Isto não tem de corresponder às tuas escolhas anteriores.
- Dá um nome ao ficheiro. Neste caso, escolha
users_and_bookings. - Para o caminho de destino, mantenha o padrão.
- Para o tipo de conjunto de dados, deixe-o como Nenhum selecionado.
Clique em Criar para criar o ficheiro de código de transformação.
No teu novo ficheiro de código, edita o código para corresponder ao seguinte (usa SQL ou Python, com base na tua seleção no ecrã anterior).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Clique em Executar pipeline para atualizar os conjuntos de dados. Quando a execução termina, pode ver no Gráfico de Pipeline que existem quatro tabelas, incluindo a nova
users_and_bookingstabela.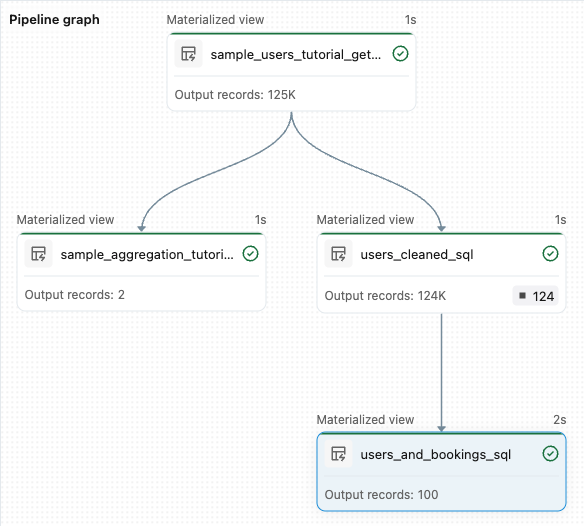
Recursos adicionais
Agora que aprendeu a usar algumas das funcionalidades do editor de pipelines Lakeflow e criou um pipeline, aqui ficam outras funcionalidades sobre as quais pode saber mais:
Ferramentas para trabalhar e depurar transformações ao criar pipelines.
- Execução seletiva
- Pré-visualizações de dados
- Grafo interativo do fluxo de processamento (grafo dos conjuntos de dados no seu fluxo de processamento)
A integração de Pacotes de Automação Declarativa incorporados para colaboração eficiente, controlo de versões e CI/CD diretamente do editor: