Executar Projetos do MLflow no Azure Databricks
Um projeto MLflow é um formato para empacotar código de ciência de dados de forma reutilizável e reproduzível. O componente MLflow Projects inclui uma API e ferramentas de linha de comando para executar projetos, que também se integram ao componente Tracking para registrar automaticamente os parâmetros e git commit do seu código-fonte para reprodutibilidade.
Este artigo descreve o formato de um projeto MLflow e como executar um projeto MLflow remotamente em clusters do Azure Databricks usando a CLI MLflow, o que facilita o dimensionamento vertical do código de ciência de dados.
Formato do projeto MLflow
Qualquer diretório local ou repositório Git pode ser tratado como um projeto MLflow. As seguintes convenções definem um projeto:
- O nome do projeto é o nome do diretório.
- O ambiente de software é especificado em
python_env.yaml, se presente. Se nenhumpython_env.yamlarquivo estiver presente, o MLflow usará um ambiente virtualenv contendo apenas Python (especificamente, o Python mais recente disponível para virtualenv) ao executar o projeto. - Qualquer
.pyarquivo ou.shno projeto pode ser um ponto de entrada, sem parâmetros explicitamente declarados. Quando você executa esse comando com um conjunto de parâmetros, MLflow passa cada parâmetro na linha de comando usando--key <value>sintaxe.
Você especifica mais opções adicionando um arquivo MLproject, que é um arquivo de texto na sintaxe YAML. Um exemplo de arquivo MLproject tem esta aparência:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
Para o Databricks Runtime 13.0 ML e superior, os Projetos MLflow não podem ser executados com êxito em um cluster de tipo de trabalho Databricks. Para migrar projetos MLflow existentes para o Databricks Runtime 13.0 ML e superior, consulte MLflow Databricks Spark job project format.
Formato do projeto de trabalho MLflow Databricks Spark
O projeto de trabalho MLflow Databricks Spark é um novo tipo de projeto MLflow introduzido no MLflow 2.14. Esse tipo de projeto suporta a execução de projetos MLflow de dentro de um cluster Spark Jobs e só pode ser executado usando o back-end "databricks". Segue-se um exemplo do MLproject ficheiro para este novo tipo de projeto:
name: My Project
databricks_spark_job:
python_file: "train.py" # the file which is the entry point file to execute
parameters: ["param1", "param2"] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
O projeto de trabalho Databricks Spark não suporta a especificação das seguintes seções no arquivo MLproject: entry_points, docker_env, python_env, ou conda_env. As dependências para seu projeto podem ser especificadas nopython_libraries campo da databricks_spark_job seção. As versões do Python não podem ser personalizadas com este tipo de projeto. O ambiente em execução deve usar o ambiente de tempo de execução do driver Spark principal para ser executado em clusters de trabalhos que usam o Databricks Runtime 13.0 ou superior. Da mesma forma, todas as dependências Python definidas como necessárias para o projeto devem ser instaladas como dependências de cluster Databricks. Esse comportamento é diferente dos comportamentos de execução de projeto anteriores em que as bibliotecas precisavam ser instaladas em um ambiente separado.
Executar um projeto MLflow
Para executar um projeto MLflow em um cluster do Azure Databricks no espaço de trabalho padrão, use o comando:
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
onde <uri> é um URI de repositório Git ou pasta que contém um projeto MLflow e <json-new-cluster-spec> é um documento JSON que contém uma estrutura new_cluster. O URI do Git deve ter a seguinte forma: https://github.com/<repo>#<project-folder>.
Um exemplo de especificação de cluster é:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
Se você precisar instalar bibliotecas no trabalhador, use o formato "especificação de cluster". Observe que os arquivos de roda Python devem ser carregados no DBFS e especificados como pypi dependências. Por exemplo:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
Importante
.egge.jardependências não são suportadas para projetos MLflow.- Não há suporte para a execução de projetos MLflow com ambientes Docker.
- Você deve usar uma nova especificação de cluster ao executar um projeto MLflow no Databricks. Não há suporte para a execução de projetos em clusters existentes.
Usando o SparkR
Para usar o SparkR em uma execução de projeto MLflow, o código do projeto deve primeiro instalar e importar o SparkR da seguinte maneira:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Seu projeto pode então inicializar uma sessão do SparkR e usar o SparkR normalmente:
sparkR.session()
...
Exemplo
Este exemplo mostra como criar um experimento, executar o projeto tutorial MLflow em um cluster do Azure Databricks, exibir a saída da execução do trabalho e exibir a execução no experimento.
Requisitos
- Instale o MLflow usando
pip install mlflowo . - Instale e configure a CLI do Databricks. O mecanismo de autenticação da CLI do Databricks é necessário para executar trabalhos em um cluster do Azure Databricks.
Etapa 1: Criar um experimento
No espaço de trabalho, selecione Criar > experiência MLflow.
No campo Nome, digite
Tutorial.Clique em Criar. Observe a ID do experimento. Neste exemplo, é
14622565.
Etapa 2: Executar o projeto tutorial MLflow
As etapas a seguir configuram a MLFLOW_TRACKING_URI variável de ambiente e executam o projeto, registrando os parâmetros de treinamento, as métricas e o modelo treinado para o experimento observado na etapa anterior:
Defina a
MLFLOW_TRACKING_URIvariável de ambiente para o espaço de trabalho do Azure Databricks.export MLFLOW_TRACKING_URI=databricksExecute o projeto tutorial MLflow, treinando um modelo de vinho. Substitua
<experiment-id>pelo ID do experimento que você anotou na etapa anterior.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===Copie a URL
https://<databricks-instance>#job/<job-id>/run/1na última linha da saída de execução do MLflow.
Etapa 3: Exibir a execução do trabalho do Azure Databricks
Abra a URL copiada na etapa anterior em um navegador para exibir a saída de execução do trabalho do Azure Databricks:
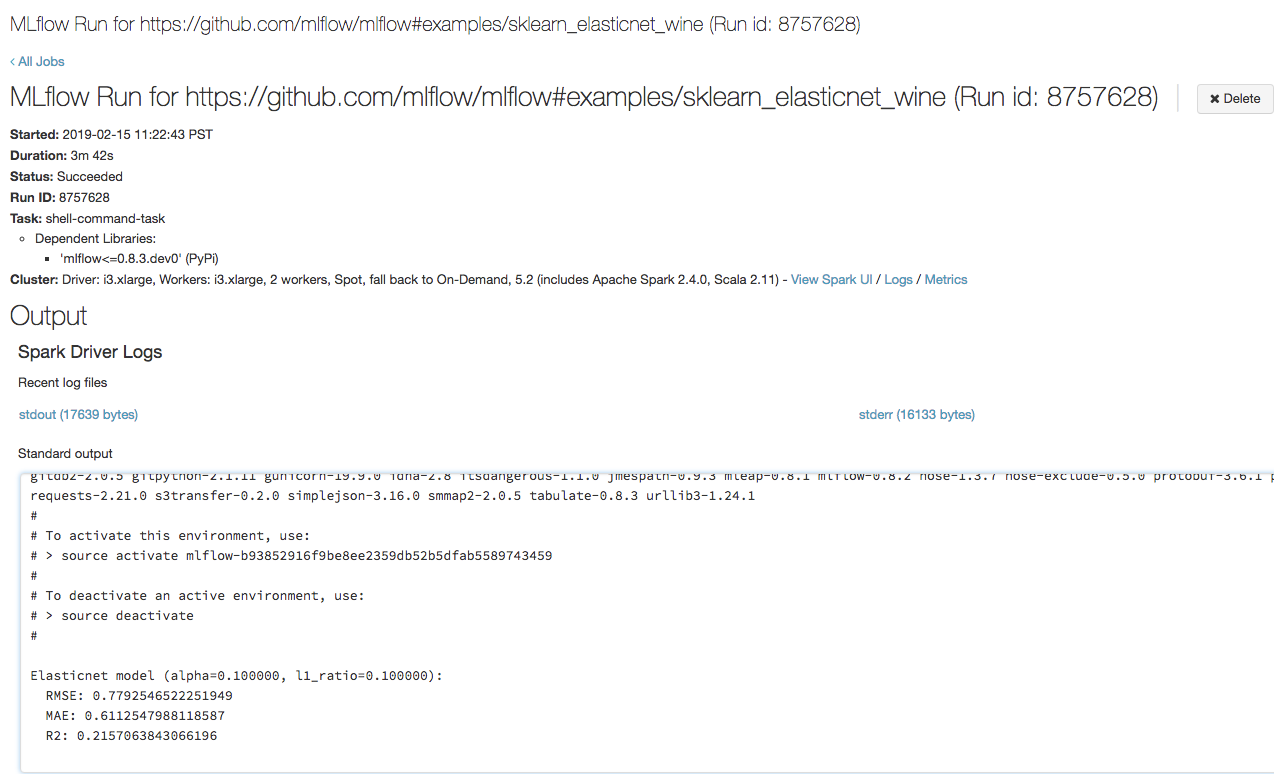
Etapa 4: Exibir o experimento e os detalhes da execução do MLflow
Navegue até o experimento em seu espaço de trabalho do Azure Databricks.
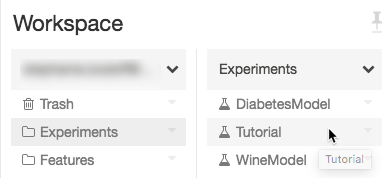
Clique no experimento.
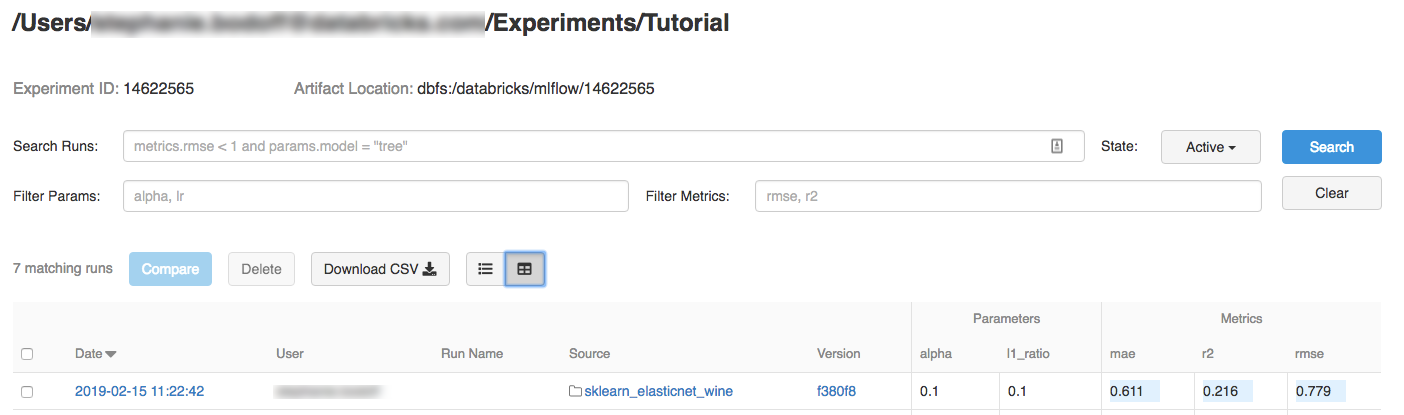
Para exibir os detalhes da execução, clique em um link na coluna Data.
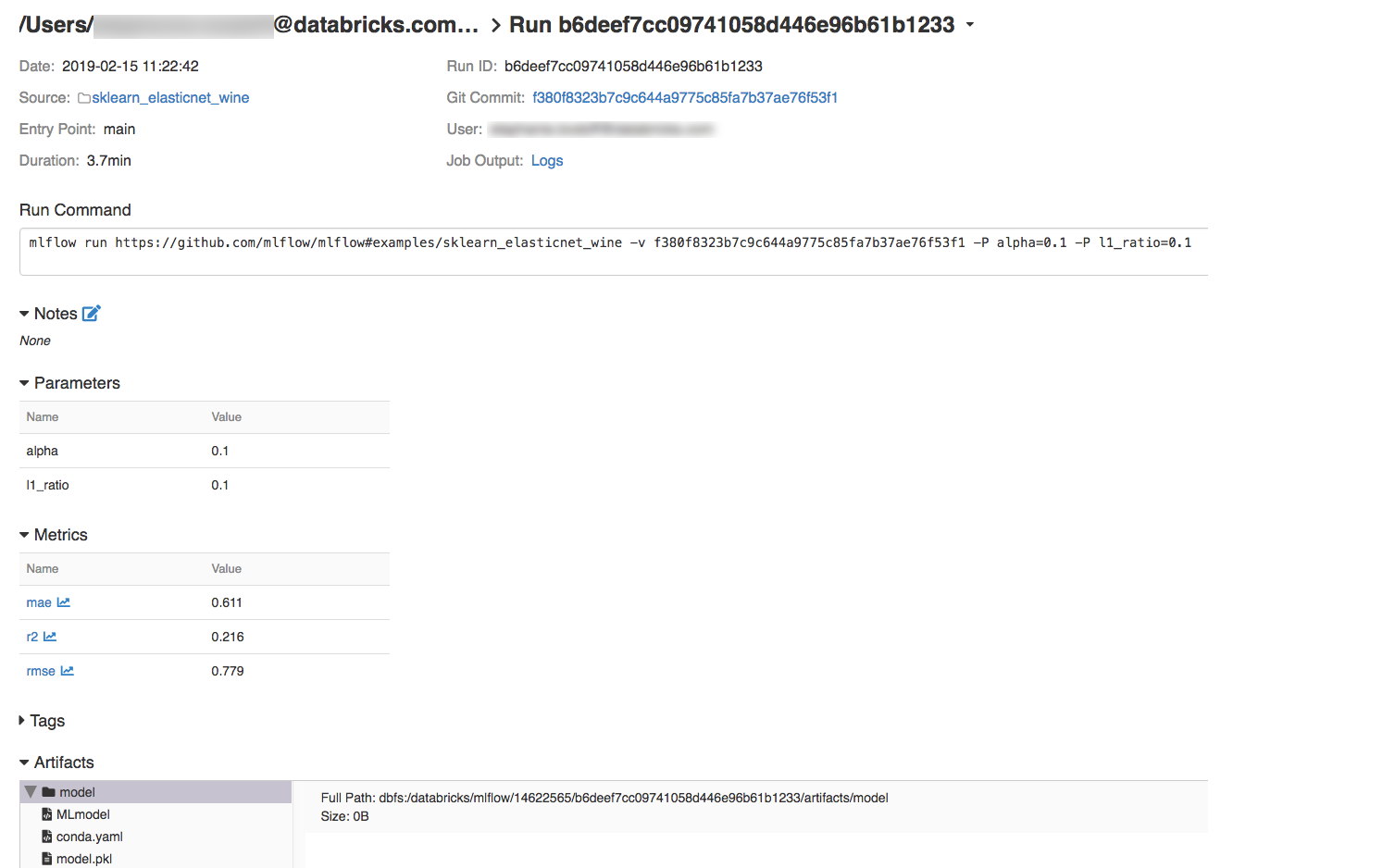
Você pode visualizar os logs da sua execução clicando no link Logs no campo Saída do trabalho.
Recursos
Para alguns exemplos de projetos MLflow, consulte a Biblioteca de aplicativos MLflow, que contém um repositório de projetos prontos para execução com o objetivo de facilitar a inclusão da funcionalidade de ML em seu código.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários