Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Visão geral
Os pontuadores personalizados oferecem a máxima flexibilidade para definir com precisão como a qualidade do seu aplicativo GenAI é medida. Os pontuadores personalizados oferecem flexibilidade para definir métricas de avaliação adaptadas ao seu caso de uso de negócios específico, seja com base em heurísticas simples, lógica avançada ou avaliações programáticas.
Use pontuadores personalizados para os seguintes cenários:
- Definindo uma métrica de avaliação huerística personalizada ou baseada em código
- Personalizando como os dados do rastreamento do seu aplicativo são mapeados para os juízes de LLM apoiados por pesquisa da Databricks nos pontuadores de LLM predefinidos
- Criar um juiz LLM com texto de prompt personalizado usando o artigo de pontuadores LLM baseados em prompt.
- Usando seu próprio modelo LLM (em vez de um modelo de juiz LLM hospedado pelo Databricks) para avaliação
- Quaisquer outros casos de uso em que você precise de mais flexibilidade e controle do que o fornecido pelas abstrações predefinidas
Observação
Consulte a página de conceito do marcador ou os documentos da API para obter uma referência detalhada sobre as interfaces personalizadas do marcador.
Visão geral do uso
Os pontuadores personalizados são escritos em Python e oferecem controle total para avaliar quaisquer dados dos rastreamentos do seu aplicativo. Um único marcador personalizado funciona em ambos os cenários para avaliação offline ou se passado para a monitorização da produção.
Os seguintes tipos de saídas são suportados:
- Cadeia de caracteres de aprovação/reprovação:
"yes" or "no"os valores de cadeia de caracteres são renderizados como "Aprovado" ou "Reprovado" na UI. - Valor numérico: Valores ordinais: inteiros ou flutuantes.
- Valor booleano:
TrueouFalse. - Objeto de feedback: retorna um
Feedbackobjeto com uma pontuação, lógica e metadados adicionais
Como entrada, os pontuadores personalizados têm acesso a:
- O rastreamento completo do MLflow, incluindo spans, atributos e saídas. O rastreamento é passado para o pontuador personalizado como uma classe instanciada
mlflow.entities.trace. - O
inputsdicionário, derivado de conjunto de dados de entrada ou do pós-processamento do MLflow do seu rastreamento. - O valor
outputs, derivado de um conjunto de dados de entrada ou de rastreamento. Sepredict_fnfor fornecido, o valor deoutputsserá o retorno depredict_fn. - O
expectationsdicionário, derivado do campoexpectationsno conjunto de dados de entrada, ou as avaliações associadas ao rastreamento.
O @scorer decorador permite que os usuários definam métricas de avaliação personalizadas que podem ser passadas para mlflow.genai.evaluate() usando o argumento scorers ou create_monitor(...).
A função 'scorer' é invocada com argumentos nomeados com base na assinatura abaixo. Todos os argumentos nomeados são opcionais para que você possa usar qualquer combinação. Por exemplo, você pode definir um marcador que só tem inputs e trace como argumentos e omitir outputs e expectations:
from mlflow.genai.scorers import scorer
from typing import Optional, Any
from mlflow.entities import Feedback
@scorer
def my_custom_scorer(
*, # evaluate(...) harness will always call your scorer with named arguments
inputs: Optional[dict[str, Any]], # The agent's raw input, parsed from the Trace or dataset, as a Python dict
outputs: Optional[Any], # The agent's raw output, parsed from the Trace or
expectations: Optional[dict[str, Any]], # The expectations passed to evaluate(data=...), as a Python dict
trace: Optional[mlflow.entities.Trace] # The app's resulting Trace containing spans and other metadata
) -> int | float | bool | str | Feedback | list[Feedback]
Abordagem de desenvolvimento de classificadores personalizados
À medida que você desenvolve métricas, você precisa iterar rapidamente a métrica sem ter que executar seu aplicativo toda vez que fizer uma alteração no marcador. Para fazer isso, recomendamos as seguintes etapas:
Etapa 1: definir sua métrica inicial, aplicativo e dados de avaliação
import mlflow
from mlflow.entities import Trace
from mlflow.genai.scorers import scorer
from typing import Any
@mlflow.trace
def my_app(input_field_name: str):
return {'output': input_field_name+'_output'}
@scorer
def my_metric() -> int:
# placeholder return value
return 1
eval_set = [{'inputs': {'input_field_name': 'test'}}]
Etapa 2: gerar rastreamentos do seu aplicativo usando evaluate()
eval_results = mlflow.genai.evaluate(
data=eval_set,
predict_fn=my_app,
scorers=[dummy_metric]
)
Etapa 3: Consultar e armazenar os rastreamentos resultantes
generated_traces = mlflow.search_traces(run_id=eval_results.run_id)
Etapa 4: Passe os rastreamentos resultantes como entrada para evaluate() enquanto você itera sobre a sua métrica
A função search_traces retorna um Pandas DataFrame de rastreamentos, que pode passar diretamente para evaluate() como um conjunto de dados de entrada. Isto permite que revises rapidamente a tua métrica sem teres de executar novamente a tua aplicação.
@scorer
def my_metric(outputs: Any):
# Implement the actual metric logic here.
return outputs == "test_output"
# Note the lack of a predict_fn parameter
mlflow.genai.evaluate(
data=generated_traces,
scorers=[my_metric],
)
Exemplos de Scorers Personalizados
Neste guia, mostraremos várias abordagens para criar pontuadores personalizados.

Pré-requisito: criar um aplicativo de exemplo e obter uma cópia local dos rastreamentos
Em todas as abordagens, usamos a aplicação de exemplo abaixo mencionada e a cópia dos registos (extraídos usando a abordagem acima).
import mlflow
from openai import OpenAI
from typing import Any
from mlflow.entities import Trace
from mlflow.genai.scorers import scorer
# Enable auto logging for OpenAI
mlflow.openai.autolog()
# Connect to a Databricks LLM via OpenAI using the same credentials as MLflow
# Alternatively, you can use your own OpenAI credentials here
mlflow_creds = mlflow.utils.databricks_utils.get_databricks_host_creds()
client = OpenAI(
api_key=mlflow_creds.token,
base_url=f"{mlflow_creds.host}/serving-endpoints"
)
@mlflow.trace
def sample_app(messages: list[dict[str, str]]):
# 1. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant."},
*messages,
]
# 2. Call LLM to generate a response
response = client.chat.completions.create(
model="databricks-claude-3-7-sonnet", # This example uses Databricks hosted Claude. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=messages_for_llm,
)
return response.choices[0].message.content
# Create a list of messages for the LLM to generate a response
eval_dataset = [
{
"inputs": {
"messages": [
{"role": "user", "content": "How much does a microwave cost?"},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "Can I return the microwave I bought 2 months ago?",
},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "Website"},
]
},
},
]
@scorer
def dummy_metric():
# This scorer is just to help generate initial traces.
return 1
# Generate initial traces by running the sample_app.
# The results, including traces, are logged to the MLflow experiment defined above.
initial_eval_results = mlflow.genai.evaluate(
data=eval_dataset, predict_fn=sample_app, scorers=[dummy_metric]
)
generated_traces = mlflow.search_traces(run_id=initial_eval_results.run_id)
Depois de executar o código acima, você deve ter três rastreamentos em seu experimento.
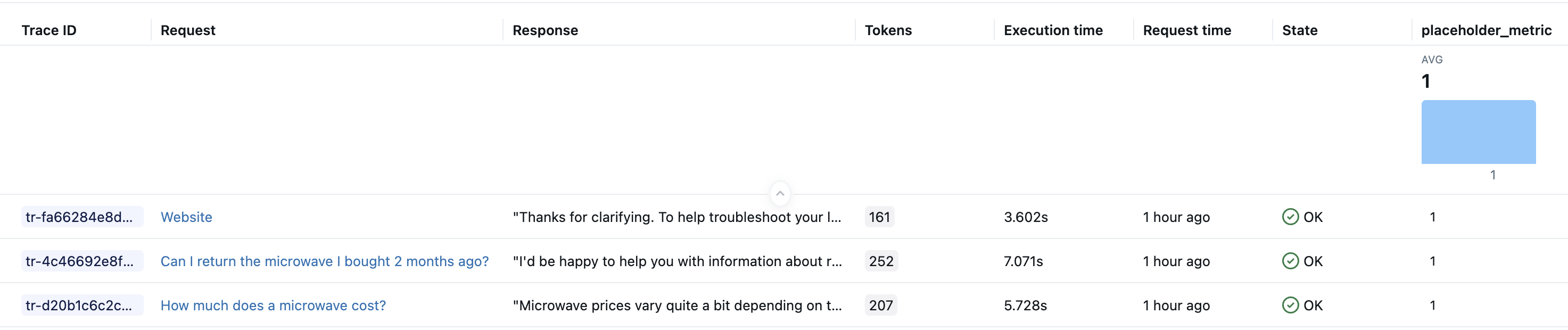
Exemplo 1: Aceder a dados a partir do rastreio
Acesse o objeto MLflow Trace completo para usar vários detalhes (vãos, entradas, saídas, atributos, temporização) para cálculo métrico refinado.
Observação
generated_traces da seção de pré-requisitos será usado como dados de entrada para estes exemplos.
Este marcador verifica se o tempo total de execução do rastreamento está dentro de uma faixa aceitável.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Trace, Feedback, SpanType
@scorer
def llm_response_time_good(trace: Trace) -> Feedback:
# Search particular span type from the trace
llm_span = trace.search_spans(span_type=SpanType.CHAT_MODEL)[0]
response_time = (llm_span.end_time_ns - llm_span.start_time_ns) / 1e9 # second
max_duration = 5.0
if response_time <= max_duration:
return Feedback(
value="yes",
rationale=f"LLM response time {response_time:.2f}s is within the {max_duration}s limit."
)
else:
return Feedback(
value="no",
rationale=f"LLM response time {response_time:.2f}s exceeds the {max_duration}s limit."
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
span_check_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[llm_response_time_good]
)
Exemplo 2: Envolver um juiz LLM predefinido
Crie um marcador personalizado que integre os juízes LLM predefinidos do MLflow. Use isso para pré-processar dados de rastreamento para o juiz ou pós-processar seu feedback.
Este exemplo demonstra como envolver o is_context_relevant juiz que avalia se o contexto dado é relevante para a consulta, para avaliar se a resposta do assistente é relevante para a consulta do usuário.
import mlflow
from mlflow.entities import Trace, Feedback
from mlflow.genai.judges import is_context_relevant
from mlflow.genai.scorers import scorer
from typing import Any
# Assume `generated_traces` is available from the prerequisite code block.
@scorer
def is_message_relevant(inputs: dict[str, Any], outputs: str) -> Feedback:
# The `inputs` field for `sample_app` is a dictionary like: {"messages": [{"role": ..., "content": ...}, ...]}
# We need to extract the content of the last user message to pass to the relevance judge.
last_user_message_content = None
if "messages" in inputs and isinstance(inputs["messages"], list):
for message in reversed(inputs["messages"]):
if message.get("role") == "user" and "content" in message:
last_user_message_content = message["content"]
break
if not last_user_message_content:
raise Exception("Could not extract the last user message from inputs to evaluate relevance.")
# Call the `relevance_to_query judge. It will return a Feedback object.
return is_context_relevant(
request=last_user_message_content,
context={"response": outputs},
)
# Evaluate the custom relevance scorer
custom_relevance_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[is_message_relevant]
)
Exemplo 3: Usando expectations
Quando mlflow.genai.evaluate() é chamado com um data argumento que é uma lista de dicionários ou um Pandas DataFrame, cada linha pode conter uma expectations chave. O valor associado a esta chave é passado diretamente para o seu avaliador personalizado.
import mlflow
from mlflow.entities import Feedback
from mlflow.genai.scorers import scorer
from typing import Any, List, Optional, Union
expectations_eval_dataset_list = [
{
"inputs": {"messages": [{"role": "user", "content": "What is 2+2?"}]},
"expectations": {
"expected_response": "2+2 equals 4.",
"expected_keywords": ["4", "four", "equals"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Describe MLflow in one sentence."}]},
"expectations": {
"expected_response": "MLflow is an open-source platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models.",
"expected_keywords": ["mlflow", "open-source", "platform", "machine learning"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Say hello."}]},
"expectations": {
"expected_response": "Hello there!",
# No keywords needed for this one, but the field can be omitted or empty
}
}
]
Exemplo 3.1: Correspondência exata com a resposta esperada
Este marcador verifica se a resposta do assistente corresponde exatamente à expected_response fornecida no expectations.
@scorer
def exact_match(outputs: str, expectations: dict[str, Any]) -> bool:
# Scorer can return primitive value like bool, int, float, str, etc.
return outputs == expectations["expected_response"]
exact_match_eval_results = mlflow.genai.evaluate(
data=expectations_eval_dataset_list,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[exact_match]
)
Exemplo 3.2: Verificação de presença de palavra-chave a partir de expectativas
Este marcador verifica se todos os expected_keywords do expectations estão presentes na resposta do assistente.
@scorer
def keyword_presence_scorer(outputs: str, expectations: dict[str, Any]) -> Feedback:
expected_keywords = expectations.get("expected_keywords")
print(expected_keywords)
if expected_keywords is None:
return Feedback(
score=None, # Undetermined, as no keywords were expected
rationale="No 'expected_keywords' provided in expectations."
)
missing_keywords = []
for keyword in expected_keywords:
if keyword.lower() not in outputs.lower():
missing_keywords.append(keyword)
if not missing_keywords:
return Feedback(value="yes", rationale="All expected keywords are present in the response.")
else:
return Feedback(value="no", rationale=f"Missing keywords: {', '.join(missing_keywords)}.")
keyword_presence_eval_results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[keyword_presence_scorer]
)
Exemplo 4: Retornando vários objetos de feedback
Um único avaliador pode retornar uma lista de objetos Feedback, permitindo que um avaliador avalie várias facetas de qualidade (por exemplo, PII, sentimento, concisão) simultaneamente. Cada objeto Feedback deveria idealmente ter um único name (que se torna o nome da métrica nos resultados); caso contrário, podem sobrescrever-se mutuamente se os nomes forem gerados automaticamente e colidirem. Se um nome não for fornecido, o MLflow tentará gerar um com base no nome da função do marcador e em um índice.
Este exemplo demonstra um avaliador que retorna duas partes distintas de feedback para cada traço.
-
is_not_empty_check: Um booleano que indica se o conteúdo da resposta não está vazio. -
response_char_length: Um valor numérico para o comprimento de caracteres da resposta.
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback, Trace # Ensure Feedback and Trace are imported
from typing import Any, Optional
# Assume `generated_traces` is available from the prerequisite code block.
@scorer
def comprehensive_response_checker(outputs: str) -> list[Feedback]:
feedbacks = []
# 1. Check if the response is not empty
feedbacks.append(
Feedback(name="is_not_empty_check", value="yes" if outputs != "" else "no")
)
# 2. Calculate response character length
char_length = len(outputs)
feedbacks.append(Feedback(name="response_char_length", value=char_length))
return feedbacks
multi_feedback_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[comprehensive_response_checker]
)
O resultado terá duas colunas: is_not_empty_check e response_char_length como avaliações.
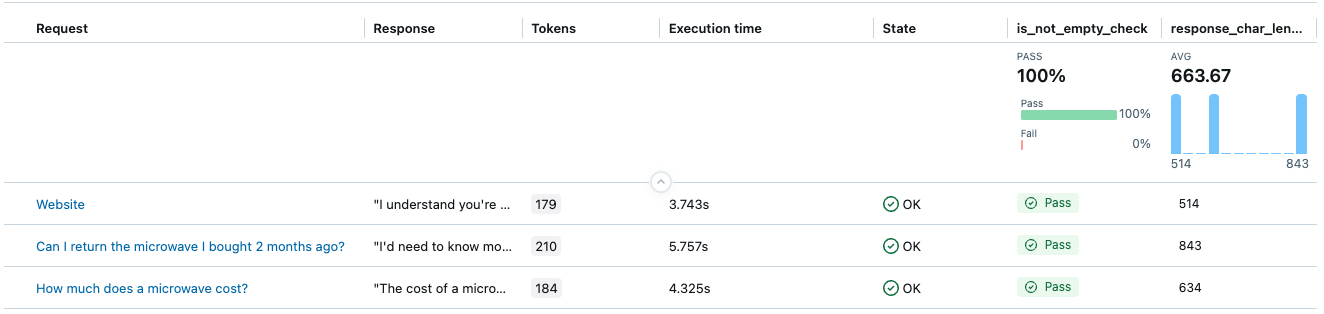
Exemplo 5: Usando seu próprio LLM para um juiz
Integre um LLM personalizado ou hospedado externamente dentro de um avaliador. O pontuador lida com chamadas de API, formatação de entrada/saída e gera Feedback a partir da resposta do seu LLM, dando controle total sobre o processo de avaliação.
Você também pode definir o sourceFeedback campo no objeto para indicar que a fonte da avaliação é um juiz LLM.
import mlflow
import json
from mlflow.genai.scorers import scorer
from mlflow.entities import AssessmentSource, AssessmentSourceType, Feedback
from typing import Any, Optional
# Assume `generated_traces` is available from the prerequisite code block.
# Assume `client` (OpenAI SDK client configured for Databricks) is available from the prerequisite block.
# client = OpenAI(...)
# Define the prompts for the Judge LLM.
judge_system_prompt = """
You are an impartial AI assistant responsible for evaluating the quality of a response generated by another AI model.
Your evaluation should be based on the original user query and the AI's response.
Provide a quality score as an integer from 1 to 5 (1=Poor, 2=Fair, 3=Good, 4=Very Good, 5=Excellent).
Also, provide a brief rationale for your score.
Your output MUST be a single valid JSON object with two keys: "score" (an integer) and "rationale" (a string).
Example:
{"score": 4, "rationale": "The response was mostly accurate and helpful, addressing the user's query directly."}
"""
judge_user_prompt = """
Please evaluate the AI's Response below based on the Original User Query.
Original User Query:
```{user_query}```
AI's Response:
```{llm_response_from_app}```
Provide your evaluation strictly as a JSON object with "score" and "rationale" keys.
"""
@scorer
def answer_quality(inputs: dict[str, Any], outputs: str) -> Feedback:
user_query = inputs["messages"][-1]["content"]
# Call the Judge LLM using the OpenAI SDK client.
judge_llm_response_obj = client.chat.completions.create(
model="databricks-claude-3-7-sonnet", # This example uses Databricks hosted Claude. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o-mini, etc.
messages=[
{"role": "system", "content": judge_system_prompt},
{"role": "user", "content": judge_user_prompt.format(user_query=user_query, llm_response_from_app=outputs)},
],
max_tokens=200, # Max tokens for the judge's rationale
temperature=0.0, # For more deterministic judging
)
judge_llm_output_text = judge_llm_response_obj.choices[0].message.content
# Parse the Judge LLM's JSON output.
judge_eval_json = json.loads(judge_llm_output_text)
parsed_score = int(judge_eval_json["score"])
parsed_rationale = judge_eval_json["rationale"]
return Feedback(
value=parsed_score,
rationale=parsed_rationale,
# Set the source of the assessment to indicate the LLM judge used to generate the feedback
source=AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="claude-3-7-sonnet",
)
)
# Evaluate the scorer using the pre-generated traces.
custom_llm_judge_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[answer_quality]
)
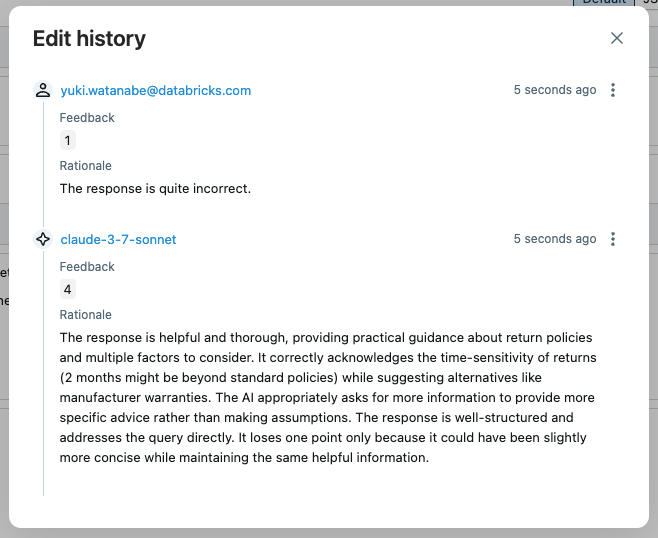
Ao abrir o rastreamento na interface do usuário e clicar na avaliação "answer_quality", você pode ver os metadados para o juiz, como fundamentação, carimbo de data/hora, nome do modelo do juiz, etc. Se a avaliação do juiz não estiver correta, você pode substituir a pontuação clicando no Edit botão.
A nova avaliação substituirá a avaliação original do juiz, mas o histórico de edições será preservado para referência futura.
Próximos passos
Continue sua jornada com estas ações e tutoriais recomendados.
- Avalie com pontuadores LLM personalizados - Crie avaliação semântica usando LLMs
- Executar pontuadores em produção - Implante seus pontuadores para monitoramento contínuo
- Criar conjuntos de dados de avaliação - Crie dados de teste para seus pontuadores
Guias de referência
Explore a documentação detalhada dos conceitos e recursos mencionados neste guia.
- Scorers - Aprofunde-se em como os marcadores funcionam e na sua arquitetura
-
Arnês de Avaliação - Entenda como
mlflow.genai.evaluate()usa seus pontuadores - Juízes LLM - Aprenda a base para a avaliação baseada em IA