Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Além das integrações de Auto Tracing , você pode instrumentar seu código Python usando o SDK de Rastreamento MLflow. Isso é especialmente útil quando você precisa instrumentar seu código Python personalizado.
Decorador
O @mlflow.trace decorador permite criar um intervalo para qualquer função. Essa abordagem fornece uma maneira simples, mas eficaz, de adicionar rastreamento ao seu código com o mínimo de esforço:
- O MLflow deteta as relações pai-filho entre funções, tornando-o compatível com integrações de rastreamento automático.
- Captura exceções durante a execução da função e as registra como eventos de extensão.
- Registra automaticamente o nome, as entradas, as saídas e o tempo de execução da função.
- Pode ser usado juntamente com recursos de rastreamento automático , como
mlflow.openai.autolog.
O decorador @mlflow\.trace atualmente suporta os seguintes tipos de funções:
| Tipo de função | Suportado |
|---|---|
| Sincronização | Sim |
| Assíncrono | Sim (>= 2.16.0) |
| Gerador | Sim (>= 2.20.2) |
| Gerador assíncrono | Sim (>= 2.20.2) |
Exemplo
O código a seguir é um exemplo mínimo de uso do decorador para rastrear funções Python.
Sugestão
Para garantir uma observabilidade completa, o @mlflow.trace decorador deve geralmente ser o mais externo quando se utilizam múltiplos decoradores. Consulte Using @mlflow.trace with Other Decorators para obter uma explicação detalhada e exemplos.
import mlflow
@mlflow.trace(span_type="func", attributes={"key": "value"})
def add_1(x):
return x + 1
@mlflow.trace(span_type="func", attributes={"key1": "value1"})
def minus_1(x):
return x - 1
@mlflow.trace(name="Trace Test")
def trace_test(x):
step1 = add_1(x)
return minus_1(step1)
trace_test(4)
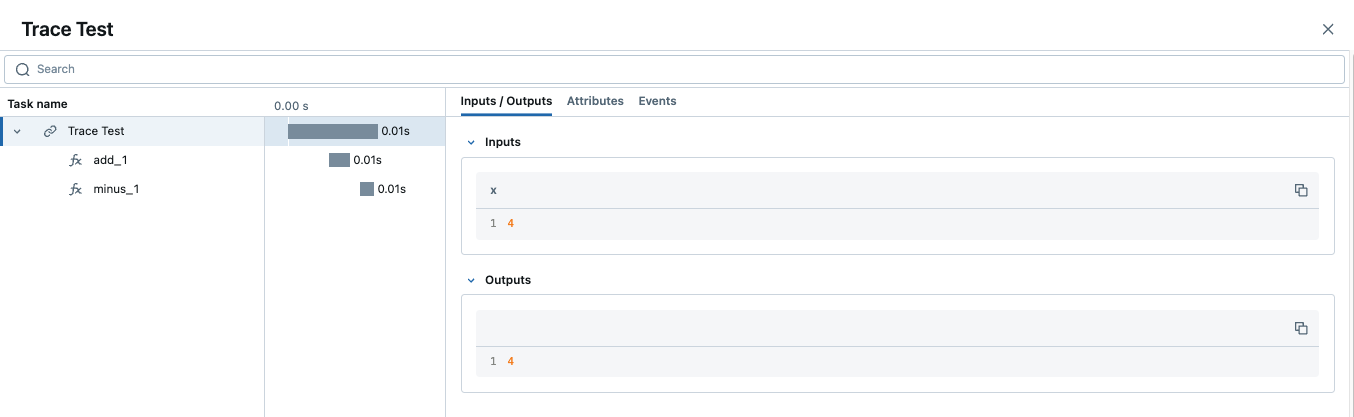
Observação
Quando um rastreamento contém vários segmentos com o mesmo nome, o MLflow acrescenta um sufixo de incremento automático a eles, como _1, _2.
Personalização de Intervalos
O @mlflow.trace decorador aceita os seguintes argumentos para personalizar o elemento de intervalo a ser criado:
-
nameparâmetro para substituir o nome do span do padrão (o nome da função decorada) -
span_typeparâmetro para definir o tipo de intervalo. Defina um dos Span Types incorporados ou uma cadeia de caracteres. -
attributespara adicionar atributos personalizados ao elemento span.
Sugestão
Ao combinar @mlflow.trace com outros decoradores (por exemplo, de frameworks web), é crucial que seja o mais externo. Para obter um exemplo claro de ordem correta versus incorreta, consulte Using @mlflow.trace with Other Decorators.
@mlflow.trace(
name="call-local-llm", span_type=SpanType.LLM, attributes={"model": "gpt-4o-mini"}
)
def invoke(prompt: str):
return client.invoke(
messages=[{"role": "user", "content": prompt}], model="gpt-4o-mini"
)
Alternativamente, pode atualizar o intervalo dinamicamente dentro da função usando mlflow.get_current_active_span API.
@mlflow.trace(span_type=SpanType.LLM)
def invoke(prompt: str):
model_id = "gpt-4o-mini"
# Get the current span (created by the @mlflow.trace decorator)
span = mlflow.get_current_active_span()
# Set the attribute to the span
span.set_attributes({"model": model_id})
return client.invoke(messages=[{"role": "user", "content": prompt}], model=model_id)
Usando @mlflow.trace com outros decoradores
Ao aplicar vários decoradores a uma única função, é crucial colocar @mlflow.trace como o decorador mais externo (aquele no topo). Isso garante que o MLflow possa capturar toda a execução da função, incluindo o comportamento de qualquer decorador interno.
Se @mlflow.trace não for o decorador mais externo, sua visibilidade na execução da função pode ser limitada ou incorreta, potencialmente levando a traços incompletos ou deturpação das entradas, saídas e tempo de execução da função.
Considere o seguinte exemplo conceitual:
import mlflow
import functools
import time
# A hypothetical additional decorator
def simple_timing_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{func.__name__} executed in {end_time - start_time:.4f} seconds by simple_timing_decorator.")
return result
return wrapper
# Correct order: @mlflow.trace is outermost
@mlflow.trace(name="my_decorated_function_correct_order")
@simple_timing_decorator
# @another_framework_decorator # e.g., @app.route("/mypath") from Flask
def my_complex_function(x, y):
# Function logic here
time.sleep(0.1) # Simulate work
return x + y
# Incorrect order: @mlflow.trace is NOT outermost
@simple_timing_decorator
@mlflow.trace(name="my_decorated_function_incorrect_order")
# @another_framework_decorator
def my_other_complex_function(x, y):
time.sleep(0.1)
return x * y
# Example calls
if __name__ == "__main__":
print("Calling function with correct decorator order:")
my_complex_function(5, 3)
print("\nCalling function with incorrect decorator order:")
my_other_complex_function(5, 3)
my_complex_function No exemplo (ordem correta), @mlflow.trace irá capturar a execução completa, incluindo o tempo adicionado por simple_timing_decorator. Em my_other_complex_function (ordem incorreta), o rastreamento capturado pelo MLflow pode não refletir com precisão o tempo total de execução ou pode perder modificações nas entradas/saídas feitas por simple_timing_decorator antes @mlflow.trace de vê-las.
Adicionando tags de rastreamento
As tags podem ser adicionadas a rastreamentos para fornecer metadados adicionais no nível de rastreamento. Há algumas maneiras diferentes de definir etiquetas em um rastreio. Por favor, consulte o how-to guide para os outros métodos.
@mlflow.trace
def my_func(x):
mlflow.update_current_trace(tags={"fruit": "apple"})
return x + 1
Personalizando visualizações de solicitação e resposta na interface do usuário
A aba Rastreios na interface do utilizador do MLflow exibe uma lista de rastreios, e as colunas Request e Response mostram uma visualização da entrada e saída de ponta a ponta de cada rastreio. Isso permite que você entenda rapidamente o que cada traço representa.
Por padrão, essas visualizações são truncadas para um número fixo de caracteres. No entanto, você pode personalizar o que é mostrado nessas colunas usando os request_preview parâmetros e response_preview dentro da mlflow.update_current_trace() função. Isso é particularmente útil para entradas ou saídas complexas em que o truncamento padrão pode não mostrar as informações mais relevantes.
Abaixo está um exemplo de definição de uma pré-visualização de pedido personalizada para um rastreamento que processa um documento longo e instruções do utilizador, com o objetivo de apresentar as informações mais relevantes na coluna Request da interface do utilizador.
import mlflow
@mlflow.trace(name="Summarization Pipeline")
def summarize_document(document_content: str, user_instructions: str):
# Construct a custom preview for the request column
# For example, show beginning of document and user instructions
request_p = f"Doc: {document_content[:30]}... Instr: {user_instructions[:30]}..."
mlflow.update_current_trace(request_preview=request_p)
# Simulate LLM call
# messages = [
# {"role": "system", "content": "Summarize the following document based on user instructions."},
# {"role": "user", "content": f"Document: {document_content}\nInstructions: {user_instructions}"}
# ]
# completion = client.chat.completions.create(model="gpt-4o-mini", messages=messages)
# summary = completion.choices[0].message.content
summary = f"Summary of document starting with '{document_content[:20]}...' based on '{user_instructions}'"
# Customize the response preview
response_p = f"Summary: {summary[:50]}..."
mlflow.update_current_trace(response_preview=response_p)
return summary
# Example Call
long_document = "This is a very long document that contains many details about various topics..." * 10
instructions = "Focus on the key takeaways regarding topic X."
summary_result = summarize_document(long_document, instructions)
# print(summary_result)
Ao definir request_preview e response_preview no rastreamento (normalmente a extensão raiz), você controla como a interação geral é resumida na exibição da lista de rastreamento principal, facilitando a identificação e a compreensão rápida dos rastreamentos.
Tratamento automático de exceções
Se um Exception for gerado durante o processamento de uma operação instrumentada por rastreamento, uma indicação será mostrada na interface de utilizador de que a invocação não foi bem-sucedida e uma captura parcial dos dados será disponibilizada para ajudar na depuração. Além disso, os detalhes sobre a Exceção que foi levantada serão incluídos dentro Events da extensão parcialmente concluída, ajudando ainda mais na identificação de onde os problemas estão ocorrendo em seu código.
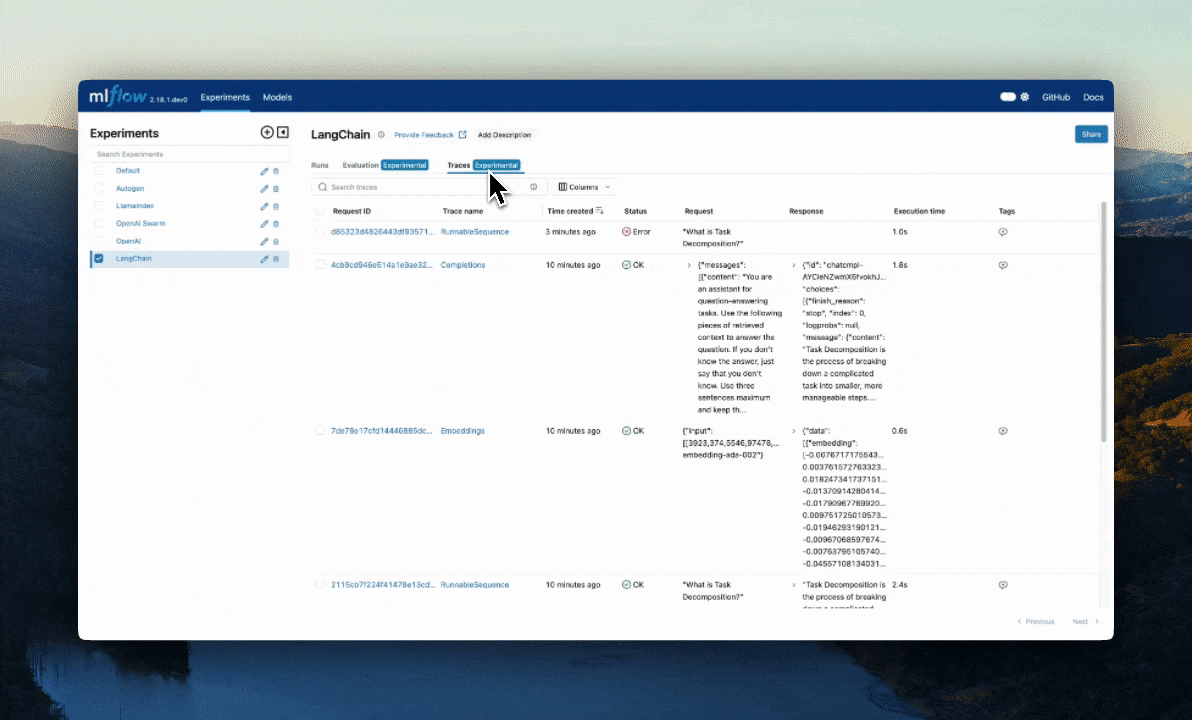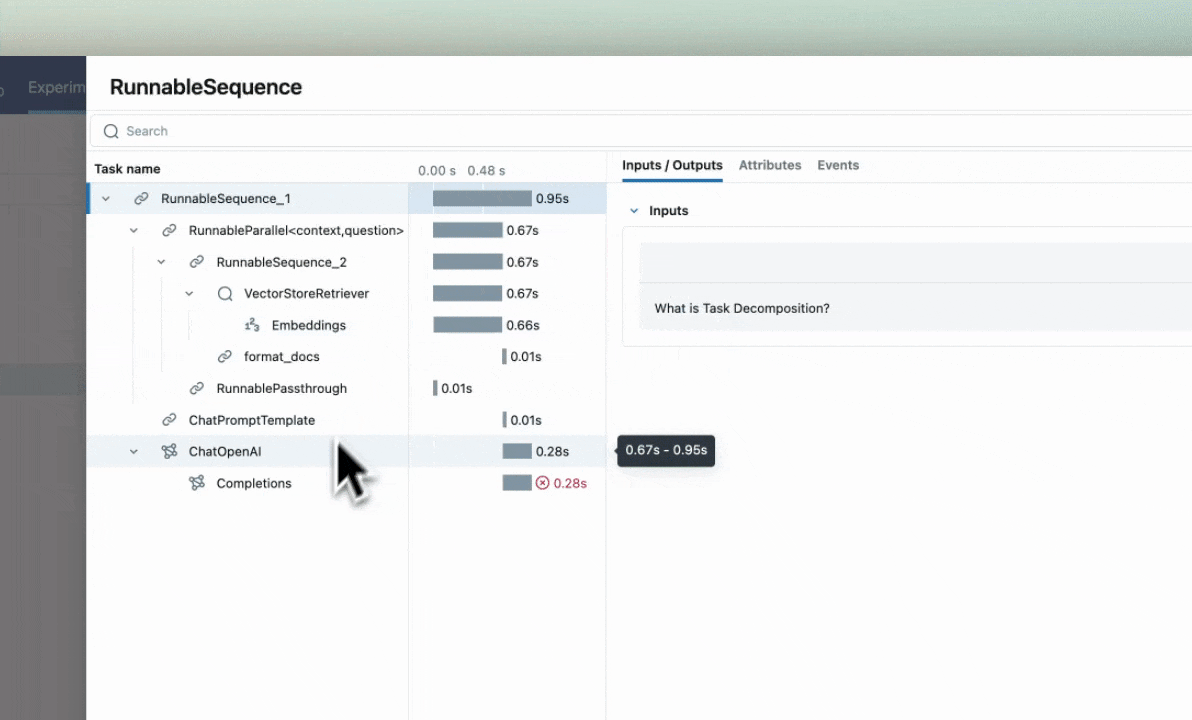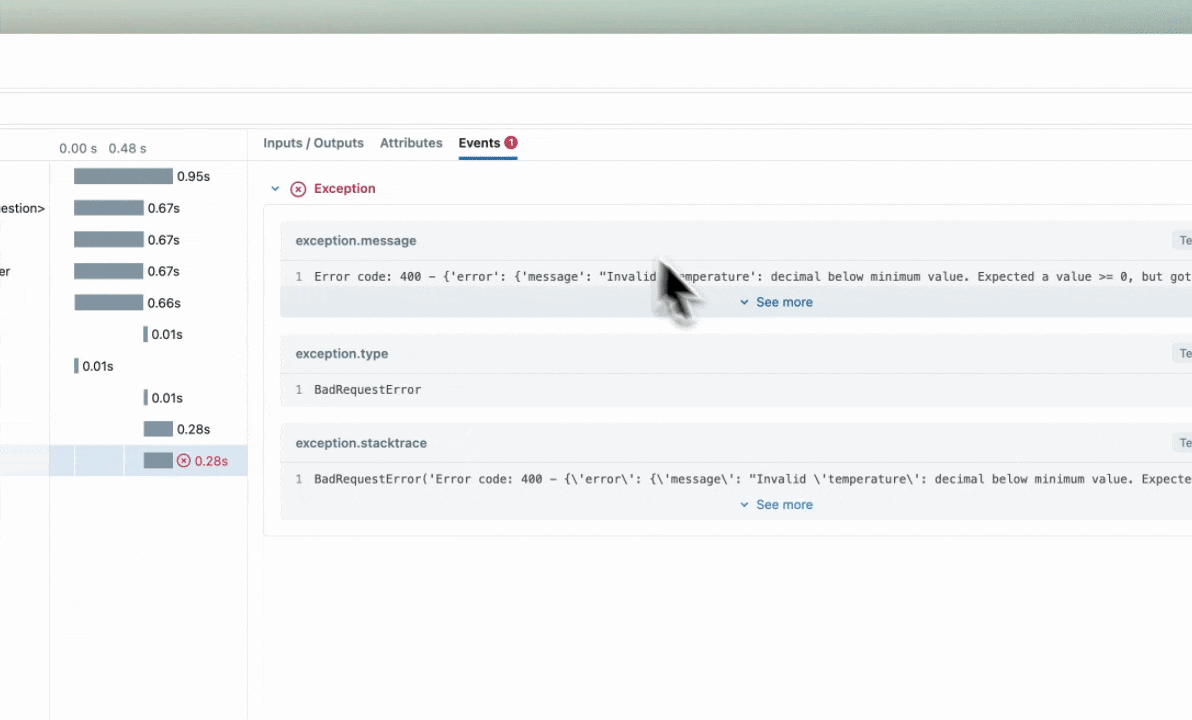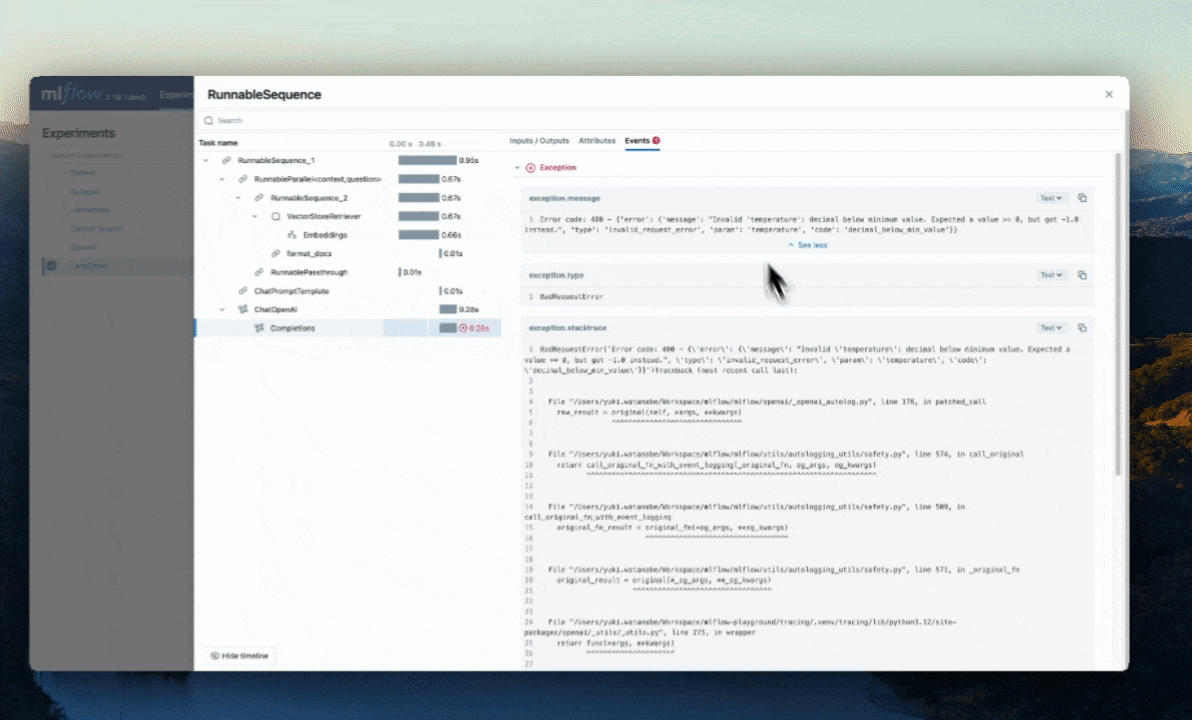
Combinação com o Auto-Tracing
O @mlflow.trace decorador pode ser usado em conjunto com o rastreamento automático para combinar o rastreamento automático com intervalos definidos manualmente em um único rastreio coeso e integrado. Saiba mais aqui.
Serviço de streaming
O @mlflow.trace decorador pode ser usado para rastrear funções que retornam um gerador ou um iterador, desde MLflow 2.20.2.
@mlflow.trace
def stream_data():
for i in range(5):
yield i
O exemplo acima gerará um traço com um único intervalo para a função stream_data. Por defeito, o MLflow capturará todos os elementos produzidos pelo gerador como uma lista na saída do span. No exemplo acima, a saída do span será [0, 1, 2, 3, 4].
Observação
Uma extensão para uma função de fluxo começará quando o iterador retornado começar a ser consumido e terminará quando o iterador estiver esgotado ou uma exceção for gerada durante a iteração.
Usando redutores de saída
Se quiser agregar os elementos para ser uma saída de span única, você pode usar o output_reducer parâmetro para especificar uma função personalizada para agregar os elementos. A função personalizada deve ter uma lista de elementos produzidos como entradas.
from typing import List, Any
@mlflow.trace(output_reducer=lambda x: ",".join(x))
def stream_data():
for c in "hello":
yield c
No exemplo acima, a saída do span será "h,e,l,l,o". Os blocos brutos ainda podem ser encontrados no separador Events do intervalo na interface do usuário MLflow Trace, permitindo que você inspecione valores individuais produzidos durante a depuração.
Padrões comuns de redutor de saída
Aqui estão alguns padrões comuns para implementar redutores de saída:
Agregação de Tokens
from typing import List, Dict, Any
def aggregate_tokens(chunks: List[str]) -> str:
"""Concatenate streaming tokens into complete text"""
return "".join(chunks)
@mlflow.trace(output_reducer=aggregate_tokens)
def stream_text():
for word in ["Hello", " ", "World", "!"]:
yield word
Agregação de métricas
def aggregate_metrics(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Aggregate streaming metrics into summary statistics"""
values = [c["value"] for c in chunks if "value" in c]
return {
"count": len(values),
"sum": sum(values),
"average": sum(values) / len(values) if values else 0,
"max": max(values) if values else None,
"min": min(values) if values else None
}
@mlflow.trace(output_reducer=aggregate_metrics)
def stream_metrics():
for i in range(10):
yield {"value": i * 2, "timestamp": time.time()}
Recolha de erros
def collect_results_and_errors(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Separate successful results from errors"""
results = []
errors = []
for chunk in chunks:
if chunk.get("error"):
errors.append(chunk["error"])
else:
results.append(chunk.get("data"))
return {
"results": results,
"errors": errors,
"success_rate": len(results) / len(chunks) if chunks else 0,
"has_errors": len(errors) > 0
}
Exemplo avançado: OpenAI Streaming
A seguir está um exemplo avançado que usa o output_reducer para consolidar a saída do ChatCompletionChunk de um LLM da OpenAI em um único objeto de mensagem.
Sugestão
Recomendamos o uso do rastreamento automático para OpenAI para casos de uso de produção, que lida com isso automaticamente. O exemplo abaixo é para fins de demonstração.
import mlflow
import openai
from openai.types.chat import *
from typing import Optional
def aggregate_chunks(outputs: list[ChatCompletionChunk]) -> Optional[ChatCompletion]:
"""Consolidate ChatCompletionChunks to a single ChatCompletion"""
if not outputs:
return None
first_chunk = outputs[0]
delta = first_chunk.choices[0].delta
message = ChatCompletionMessage(
role=delta.role, content=delta.content, tool_calls=delta.tool_calls or []
)
finish_reason = first_chunk.choices[0].finish_reason
for chunk in outputs[1:]:
delta = chunk.choices[0].delta
message.content += delta.content or ""
message.tool_calls += delta.tool_calls or []
finish_reason = finish_reason or chunk.choices[0].finish_reason
base = ChatCompletion(
id=first_chunk.id,
choices=[Choice(index=0, message=message, finish_reason=finish_reason)],
created=first_chunk.created,
model=first_chunk.model,
object="chat.completion",
)
return base
@mlflow.trace(output_reducer=aggregate_chunks)
def predict(messages: list[dict]):
stream = openai.OpenAI().chat.completions.create(
model="gpt-4o-mini",
messages=messages,
stream=True,
)
for chunk in stream:
yield chunk
for chunk in predict([{"role": "user", "content": "Hello"}]):
print(chunk)
No exemplo acima, o span gerado predict terá uma única mensagem de conclusão de chat como saída, que é agregada pela função redutor personalizada.
Real-World casos de uso
Aqui estão exemplos adicionais de redutores de saída para cenários comuns de GenAI:
Resposta LLM com análise JSON
from typing import List, Dict, Any
import json
def parse_json_from_llm(content: str) -> str:
"""Extract and clean JSON from LLM responses that may include markdown"""
# Remove common markdown code block wrappers
if content.startswith("```json") and content.endswith("```"):
content = content[7:-3] # Remove ```json prefix and ``` suffix
elif content.startswith("```") and content.endswith("```"):
content = content[3:-3] # Remove generic ``` wrappers
return content.strip()
def json_stream_reducer(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Aggregate LLM streaming output and parse JSON response"""
full_content = ""
metadata = {}
errors = []
# Process different chunk types
for chunk in chunks:
chunk_type = chunk.get("type", "content")
if chunk_type == "content" or chunk_type == "token":
full_content += chunk.get("content", "")
elif chunk_type == "metadata":
metadata.update(chunk.get("data", {}))
elif chunk_type == "error":
errors.append(chunk.get("error"))
# Return early if errors occurred
if errors:
return {
"status": "error",
"errors": errors,
"raw_content": full_content,
**metadata
}
# Try to parse accumulated content as JSON
try:
cleaned_content = parse_json_from_llm(full_content)
parsed_data = json.loads(cleaned_content)
return {
"status": "success",
"data": parsed_data,
"raw_content": full_content,
**metadata
}
except json.JSONDecodeError as e:
return {
"status": "parse_error",
"error": f"Failed to parse JSON: {str(e)}",
"raw_content": full_content,
**metadata
}
@mlflow.trace(output_reducer=json_stream_reducer)
def generate_structured_output(prompt: str, schema: dict):
"""Generate structured JSON output from an LLM"""
# Simulate streaming JSON generation
yield {"type": "content", "content": '{"name": "John", '}
yield {"type": "content", "content": '"email": "john@example.com", '}
yield {"type": "content", "content": '"age": 30}'}
# Add metadata
trace_id = mlflow.get_current_active_span().request_id if mlflow.get_current_active_span() else None
yield {"type": "metadata", "data": {"trace_id": trace_id, "model": "gpt-4"}}
Geração de saída estruturada com OpenAI
Aqui está um exemplo completo do uso de redutores de saída com OpenAI para gerar e analisar respostas JSON estruturadas:
import json
import mlflow
import openai
from typing import List, Dict, Any, Optional
def structured_output_reducer(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""
Aggregate streaming chunks into structured output with comprehensive error handling.
Handles token streaming, metadata collection, and JSON parsing.
"""
content_parts = []
trace_id = None
model_info = None
errors = []
for chunk in chunks:
chunk_type = chunk.get("type", "token")
if chunk_type == "token":
content_parts.append(chunk.get("content", ""))
elif chunk_type == "trace_info":
trace_id = chunk.get("trace_id")
model_info = chunk.get("model")
elif chunk_type == "error":
errors.append(chunk.get("message"))
# Join all content parts
full_content = "".join(content_parts)
# Base response
response = {
"trace_id": trace_id,
"model": model_info,
"raw_content": full_content
}
# Handle errors
if errors:
response["status"] = "error"
response["errors"] = errors
return response
# Try to extract and parse JSON
try:
# Clean markdown wrappers if present
json_content = full_content.strip()
if json_content.startswith("```json") and json_content.endswith("```"):
json_content = json_content[7:-3].strip()
elif json_content.startswith("```") and json_content.endswith("```"):
json_content = json_content[3:-3].strip()
parsed_data = json.loads(json_content)
response["status"] = "success"
response["data"] = parsed_data
except json.JSONDecodeError as e:
response["status"] = "parse_error"
response["error"] = f"JSON parsing failed: {str(e)}"
response["error_position"] = e.pos if hasattr(e, 'pos') else None
return response
@mlflow.trace(output_reducer=structured_output_reducer)
async def generate_customer_email(
customer_name: str,
issue: str,
sentiment: str = "professional"
) -> None:
"""
Generate a structured customer service email response.
Demonstrates real-world streaming with OpenAI and structured output parsing.
"""
client = openai.AsyncOpenAI()
system_prompt = """You are a customer service assistant. Generate a professional email response in JSON format:
{
"subject": "email subject line",
"greeting": "personalized greeting",
"body": "main email content addressing the issue",
"closing": "professional closing",
"priority": "high|medium|low"
}"""
user_prompt = f"Customer: {customer_name}\nIssue: {issue}\nTone: {sentiment}"
try:
# Stream the response
stream = await client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
stream=True,
temperature=0.7
)
# Yield streaming tokens
async for chunk in stream:
if chunk.choices[0].delta.content:
yield {
"type": "token",
"content": chunk.choices[0].delta.content
}
# Add trace metadata
if current_span := mlflow.get_current_active_span():
yield {
"type": "trace_info",
"trace_id": current_span.request_id,
"model": "gpt-4o-mini"
}
except Exception as e:
yield {
"type": "error",
"message": f"OpenAI API error: {str(e)}"
}
# Example usage
async def main():
# This will automatically aggregate the streamed output into structured JSON
async for chunk in generate_customer_email(
customer_name="John Doe",
issue="Product arrived damaged",
sentiment="empathetic"
):
# In practice, you might send these chunks to a frontend
print(chunk.get("content", ""), end="", flush=True)
Observação
Este exemplo mostra vários padrões do mundo real:
- Atualizações de interface do utilizador em tempo real: podem ser exibidos à medida que chegam
- Validação de saída estruturada: a análise JSON garante o formato de resposta
- Resiliência a erros: lida com erros de API e falhas de análise normalmente
- Correlação de traços: estabelece ligação entre a saída de streaming e traços do MLflow para depuração.
Agregação de resposta multimodelo
def multi_model_reducer(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Aggregate responses from multiple models"""
responses = {}
latencies = {}
for chunk in chunks:
model = chunk.get("model")
if model:
responses[model] = chunk.get("response", "")
latencies[model] = chunk.get("latency", 0)
return {
"responses": responses,
"latencies": latencies,
"fastest_model": min(latencies, key=latencies.get) if latencies else None,
"consensus": len(set(responses.values())) == 1
}
Teste de Redutores de Saída
Os redutores de saída podem ser testados independentemente da estrutura de rastreamento, facilitando a garantia de que eles lidam com casos extremos corretamente.
import unittest
from typing import List, Dict, Any
def my_reducer(chunks: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Example reducer to be tested"""
if not chunks:
return {"status": "empty", "total": 0}
total = sum(c.get("value", 0) for c in chunks)
errors = [c for c in chunks if c.get("error")]
return {
"status": "error" if errors else "success",
"total": total,
"count": len(chunks),
"average": total / len(chunks) if chunks else 0,
"error_count": len(errors)
}
class TestOutputReducer(unittest.TestCase):
def test_normal_case(self):
chunks = [
{"value": 10},
{"value": 20},
{"value": 30}
]
result = my_reducer(chunks)
self.assertEqual(result["status"], "success")
self.assertEqual(result["total"], 60)
self.assertEqual(result["average"], 20.0)
def test_empty_input(self):
result = my_reducer([])
self.assertEqual(result["status"], "empty")
self.assertEqual(result["total"], 0)
def test_error_handling(self):
chunks = [
{"value": 10},
{"error": "Network timeout"},
{"value": 20}
]
result = my_reducer(chunks)
self.assertEqual(result["status"], "error")
self.assertEqual(result["total"], 30)
self.assertEqual(result["error_count"], 1)
def test_missing_values(self):
chunks = [
{"value": 10},
{"metadata": "some info"}, # No value field
{"value": 20}
]
result = my_reducer(chunks)
self.assertEqual(result["total"], 30)
self.assertEqual(result["count"], 3)
Sugestão
- Os redutores de saída recebem todos os fragmentos na memória de uma só vez. Para fluxos muito grandes, considere a implementação de alternativas de streaming ou estratégias de fragmentação.
- O vão permanece aberto até que o gerador seja totalmente consumido, o que afeta as métricas de latência.
- Os redutores devem ser sem estado e evitar efeitos secundários para um comportamento previsível.
Encapsulamento de funções
O encapsulamento de funções fornece uma maneira flexível de adicionar rastreamento a funções existentes sem modificar suas definições. Isso é particularmente útil quando você deseja adicionar rastreamento a funções de terceiros ou funções definidas fora do seu controle. Ao envolver uma função externa com @mlflow.trace, pode capturar as suas entradas, saídas e contexto de execução.
Observação
Ao envolver funções dinamicamente, o conceito de "mais externo" ainda se aplica. O wrapper de rastreamento deve ser aplicado no ponto em que você deseja capturar toda a chamada para a função encapsulada.
import math
import mlflow
def invocation(x, y, exp=2):
# Wrap an external function from the math library
traced_pow = mlflow.trace(math.pow)
raised = traced_pow(x, exp)
traced_factorial = mlflow.trace(math.factorial)
factorial = traced_factorial(int(raised))
return response
invocation(4)
Gestor de Contexto
Além do decorador, o MLflow permite criar um intervalo que pode ser acessado dentro de qualquer bloco de código arbitrário encapsulado usando o gerenciador de contexto mlflow.start_span. Ele pode ser útil para capturar interações complexas dentro do seu código em detalhes mais finos do que o que é possível capturando os limites de uma única função.
Da mesma forma que o decorador, o gerenciador de contexto captura automaticamente a relação pai-filho, exceções, tempo de execução e trabalha com rastreamento automático. No entanto, o nome, as entradas e as saídas do intervalo devem ser fornecidos manualmente. Você pode defini-los através do mlflow.entities.Span objeto que é retornado do gerenciador de contexto.
with mlflow.start_span(name="my_span") as span:
span.set_inputs({"x": 1, "y": 2})
z = x + y
span.set_outputs(z)
Abaixo está um exemplo um pouco mais complexo que usa o gerente de contexto mlflow.start_span em conjunto com o decorador e a rastreação automática para o OpenAI.
import mlflow
from mlflow.entities import SpanType
@mlflow.trace(span_type=SpanType.CHAIN)
def start_session():
messages = [{"role": "system", "content": "You are a friendly chat bot"}]
while True:
with mlflow.start_span(name="User") as span:
span.set_inputs(messages)
user_input = input(">> ")
span.set_outputs(user_input)
if user_input == "BYE":
break
messages.append({"role": "user", "content": user_input})
response = openai.OpenAI().chat.completions.create(
model="gpt-4o-mini",
max_tokens=100,
messages=messages,
)
answer = response.choices[0].message.content
print(f"🤖: {answer}")
messages.append({"role": "assistant", "content": answer})
mlflow.openai.autolog()
start_session()
Multi Threading
O MLflow Tracing é thread-safe, os rastreamentos são isolados por padrão por thread. Mas você também pode criar um rastreamento que abrange vários threads com algumas etapas adicionais.
O MLflow usa o mecanismo ContextVar integrado do Python para garantir a segurança do thread, que não é propagado entre threads por padrão. Portanto, você precisa copiar manualmente o contexto do thread principal para o thread de trabalho, conforme mostrado no exemplo abaixo.
import contextvars
from concurrent.futures import ThreadPoolExecutor, as_completed
import mlflow
from mlflow.entities import SpanType
import openai
client = openai.OpenAI()
# Enable MLflow Tracing for OpenAI
mlflow.openai.autolog()
@mlflow.trace
def worker(question: str) -> str:
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question},
]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
temperature=0.1,
max_tokens=100,
)
return response.choices[0].message.content
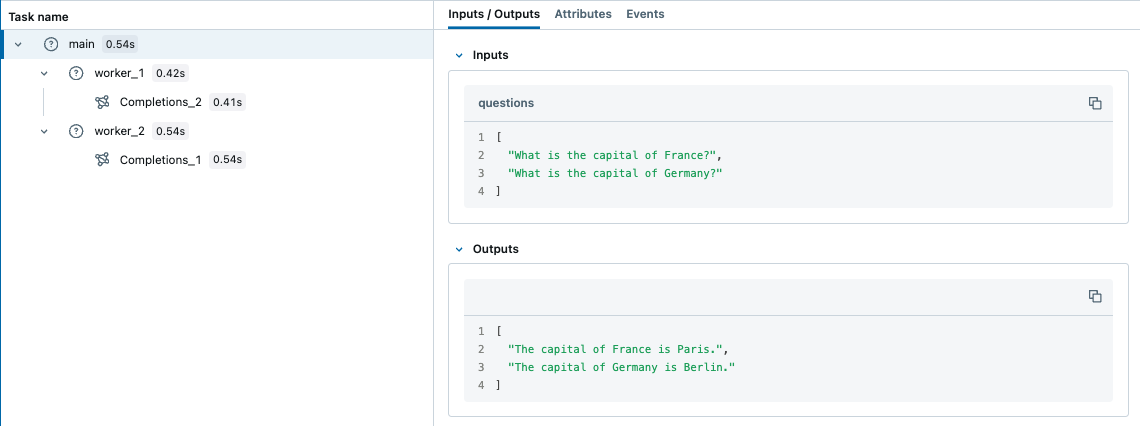
@mlflow.trace
def main(questions: list[str]) -> list[str]:
results = []
# Almost same as how you would use ThreadPoolExecutor, but two additional steps
# 1. Copy the context in the main thread using copy_context()
# 2. Use ctx.run() to run the worker in the copied context
with ThreadPoolExecutor(max_workers=2) as executor:
futures = []
for question in questions:
ctx = contextvars.copy_context()
futures.append(executor.submit(ctx.run, worker, question))
for future in as_completed(futures):
results.append(future.result())
return results
questions = [
"What is the capital of France?",
"What is the capital of Germany?",
]
main(questions)
Sugestão
Por outro lado, ContextVar é copiado para tarefas assíncronas por padrão. Portanto, não precisa de copiar manualmente o contexto ao usar asyncio, o que pode ser uma maneira mais fácil de lidar com tarefas de E/S simultâneas em Python com MLflow Tracing.
(Avançado) APIs de cliente de baixo nível
Quando o decorador ou o gerenciador de contexto não atender às suas necessidades, você poderá usar as APIs de cliente de baixo nível. Por exemplo, pode ser necessário iniciar e terminar um período de funções diferentes. A API do cliente foi projetada como um wrapper fino sobre as APIs REST do MLflow, oferecendo mais controle sobre o ciclo de vida do rastreamento. Para mais detalhes, consulte o guia.
Advertência
Ao usar APIs de cliente, esteja ciente das seguintes limitações:
- A relação pai-filho NÃO é capturada automaticamente. Você precisa passar manualmente o ID do span pai.
- Os spans criados usando a API do cliente NÃO se combinam com spans de rastreamento automático.
- As APIs de baixo nível marcadas como experimentais estão sujeitas a alterações com base em atualizações de implementação de back-end.
## Next steps
Continue your journey with these recommended actions and tutorials.
- [Low-level Client APIs](/mlflow3/genai/tracing/app-instrumentation/manual-tracing/low-level-api.md) - Learn advanced tracing control for complex scenarios
- [Debug & observe your app](/mlflow3/genai/tracing/observe-with-traces/index.md) - Use your traced app for debugging and analysis
- [Combine with automatic tracing](/mlflow3/genai/tracing/app-instrumentation/automatic.md) - Mix manual and automatic tracing
## Reference guides
Explore detailed documentation for concepts and features mentioned in this guide.
- [Tracing data model](/mlflow3/genai/tracing/data-model.md) - Understand the structure of traces and spans
- [Tracing concepts](/mlflow3/genai/tracing/tracing-101.md) - Learn fundamentals of distributed tracing
- [FAQ](/mlflow3/genai/tracing/faq.md) - Common questions about tracing implementation