Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
O Autoscaling do Lakebase é a versão mais recente do Lakebase, com computação autoescalável, escala até zero, ramificação e restauração instantânea. Para regiões suportadas, consulte Disponibilidade de Regiões. Se é utilizador do Lakebase Provisioned, consulte Lakebase Provisioned.
Lakebase Postgres Autoscaling é uma base de dados Postgres totalmente gerida, construída para qualquer aplicação que necessite de processamento de transações online (OLTP) e serviço de dados de baixa latência. Está integrado na plataforma Databricks, permitindo-lhe construir aplicações transacionais em tempo real juntamente com as suas cargas de trabalho analíticas.
O Autoscaling do Lakebase Postgres combina a fiabilidade e familiaridade do Postgres com capacidades modernas de bases de dados, incluindo autoescalabilidade, escala até zero, ramificação e restauro instantâneo. Estas funcionalidades permitem fluxos de trabalho de desenvolvimento flexíveis, operações económicas e iteração rápida.
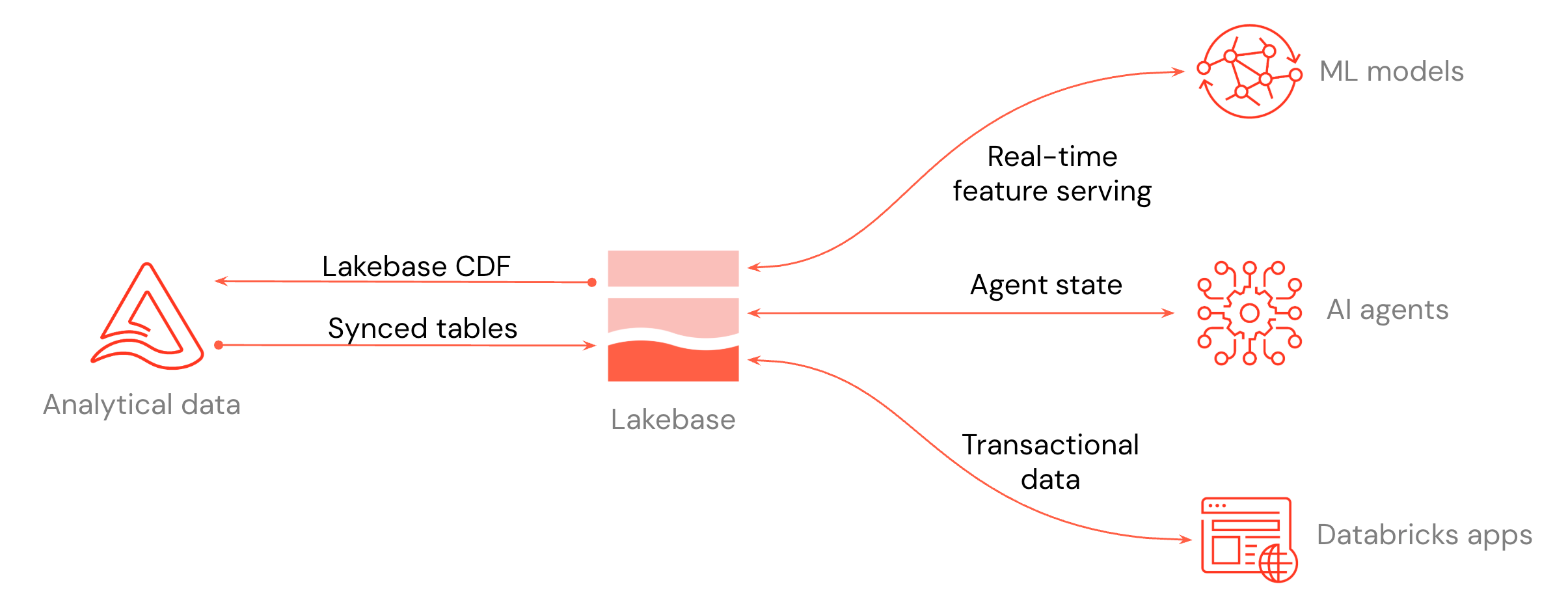
O diagrama mostra como o Lakebase se integra com o resto da plataforma: serviço de funcionalidades em tempo real para modelos de ML e Feature Store, estado do agente para agentes de IA e dados transacionais para aplicações Databricks ou qualquer aplicação que lhe ligues.
Podes mover dados em qualquer direção entre a tua casa do lago e a Lakebase. Tabelas sincronizadas transferem dados da casa do lago para o Lakebase para que as suas aplicações possam consultá-los com baixa latência.
Exemplos de casos de uso e tipos de carga de trabalho
Seguem-se apenas alguns exemplos das várias formas de utilizar uma base de dados OLTP Postgres como a Lakebase em vários setores: recomendações personalizadas e segmentação de ofertas no comércio eletrónico e retalho, dados de ensaios clínicos e sistemas de recomendação na saúde, negociação automatizada e análise em streaming em serviços financeiros, e fluxos de trabalho de telemetria e manutenção de máquinas na indústria transformadora.
Os tipos comuns de carga de trabalho para bases de dados OLTP podem incluir os seguintes:
- Serviço de dados: Forneça informações de tabelas douradas a aplicativos com baixa latência e alto QPS.
- Armazenar estado da aplicação: Gerir o fluxo de trabalho e o estado do agente num repositório de dados transacionais.
- Serviço de destaque: Servir dados caracterizados com baixa latência para modelos de ML.
Integração com Databricks
O diagrama acima destaca três casos de uso chave de integração:
- Serviço de funcionalidades em tempo real: Utiliza projetos Lakebase como repositório online para modelos de ML e Feature Store, para poder servir dados personalizados com baixa latência. Consulte a Loja de Funcionalidades Online (Lakebase) e o Serviço de Funcionalidades.
- Estado do agente para agentes de IA: Armazene e gere o estado dos agentes de IA numa base de dados transacional, para que as conversas e o contexto do fluxo de trabalho persistam entre os pedidos.
- Dados transacionais para aplicações: Armazena dados para aplicações Databricks ou qualquer aplicação que se conecte ao Lakebase. Para aplicações Databricks, adicione um projeto Lakebase como recurso de aplicação. Consulte Adicionar um recurso do Lakebase a um aplicativo Databricks.
Lakebase Abastecida
Lakebase Provisioned é a oferta original do Lakebase que utiliza computação provisionada que você escala manualmente. As instâncias Provisionadas existentes continuam a ser suportadas. O desenvolvimento do novo Lakebase está focado no Autoscaling. Se tiver instâncias Provisionadas ou estiver a avaliar ambas as opções, consulte O que é o Lakebase Provisionado? e Autoscaling por defeito.
O que é um projeto?
Os recursos de Autoscaling do Lakebase estão organizados numa estrutura de projeto . Um projeto é o contentor de topo para os recursos da tua base de dados. Quando crias uma base de dados de Autoscaling Lakebase, crias um projeto. O projeto mantém os seus ramos (ambientes de bases de dados), computações, funções e bases de dados. Pensa num projeto como a unidade de organização para uma aplicação ou carga de trabalho. Podes ter vários projetos num espaço de trabalho, cada um com os seus próprios ramos e dados.
Como os projetos são organizados
Compreender a hierarquia dos objetos dentro de um projeto ajuda-o a organizar e gerir os seus recursos:
Databricks Workspace
└── Project(s)
└── Branch(es)
├── Compute (primary R/W)
├── Read replica(s) (optional)
├── Role(s)
└── Database(s)
└── Schema(s)
Cada nível na hierarquia serve um propósito específico:
| Objeto | Description |
|---|---|
| Project | O contentor de topo para os recursos da tua base de dados. Um projeto contém ramificações, bases de dados, funções e recursos de computação. Ver Gerir projetos. |
| Filial | Um ambiente de base de dados isolado que partilha armazenamento com a sua ramificação principal. Cada projeto pode conter múltiplos ramos. Ver Gerir agências. |
| Computar | O servidor Postgres que alimenta uma filial. Cada ramo tem o seu próprio sistema de computação que fornece o poder de processamento e a memória para operações na base de dados. Consulte Gerir recursos de computação. |
| Base de dados | Uma base de dados Postgres padrão dentro de uma filial. Cada ramo pode conter múltiplas bases de dados com as suas próprias tabelas, esquemas e dados. Consulte Gerir bases de dados. |
Compreender os ramos
Uma das características mais poderosas do Lakebase Postgres é a ramificação. Tal como os branches Git para o seu código, os branches permitem-lhe criar ambientes de bases de dados isolados para desenvolvimento e testes — sem afetar a produção.
Porque é que isto importa: Os fluxos de trabalho tradicionais de bases de dados exigem servidores de desenvolvimento e staging separados, atualizações manuais de dados e coordenação cuidadosa. Com os ramos, pode:
- Crie instantaneamente um ambiente de desenvolvimento com dados de produção
- Testar alterações de esquema de forma segura antes de as aplicar em produção
- Recupere de erros criando ramificações em qualquer momento
- Pague apenas pelos dados que altera, não por bases de dados totalmente duplicadas
| Tópico | Description |
|---|---|
| Sucursais | Saiba como funcionam as filiais, fluxos de trabalho comuns e boas práticas para a sua equipa. |
| Gerir filiais | Criar, reiniciar e eliminar branches para desenvolvimento e testes. |
| Ramos protegidos | Proteger os ramos de produção contra alterações acidentais e eliminações. |
Conceitos-chave
O Lakebase baseia-se em várias inovações chave que o diferenciam dos sistemas tradicionais de bases de dados:
- Computação e armazenamento separados: Escale os recursos computacionais independentemente do armazenamento para maior eficiência de custos e flexibilidade.
- Autoescalonamento: O Compute ajusta-se automaticamente com base na procura de carga de trabalho, com suporte para escalar até zero durante os períodos de inatividade.
- Armazenamento por copiar e escrever: Permite ramificações instantâneas, onde só se paga por alterações de dados, não por duplicados completos.
- Operações instantâneas no tempo: Crie ramificações ou restaure a qualquer momento dentro da sua janela de restauro configurada (2-30 dias)
Estes conceitos trabalham em conjunto para permitir fluxos de trabalho flexíveis de desenvolvimento, operações eficientes em termos de custos e uma rápida recuperação de erros.
Para uma explicação detalhada de cada conceito central, veja Conceitos fundamentais.