Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Esta página oferece uma visão geral das ferramentas e abordagens para exportar dados e configuração a partir do seu espaço de trabalho Azure Databricks. Pode exportar ativos de espaço de trabalho para requisitos de conformidade, portabilidade de dados, backups ou migração do espaço de trabalho.
Visão geral
Os espaços de trabalho Azure Databricks contêm uma variedade de ativos, incluindo configuração de espaços de trabalho, tabelas geridas, objetos de IA e ML, e dados armazenados em armazenamento na cloud. Quando precisar de exportar dados do espaço de trabalho, pode usar uma combinação de ferramentas e APIs integradas para extrair estes ativos de forma sistemática.
Razões comuns para exportar dados de espaços de trabalho incluem:
- Requisitos de conformidade: Cumprimento das obrigações de portabilidade de dados ao abrigo de regulamentos como o RGPD e o CCPA.
- Backup e recuperação de desastres: Criação de cópias de ativos críticos do espaço de trabalho para a continuidade do negócio.
- Migração de espaços de trabalho: Movimentação de ativos entre espaços de trabalho ou fornecedores cloud.
- Auditoria e arquivo: Preservação de registos históricos da configuração e dados do espaço de trabalho.
Planeie a sua exportação
Antes de começar a exportar dados do espaço de trabalho, crie um inventário dos ativos que precisa de exportar e compreenda as dependências entre eles.
Compreender os ativos do espaço de trabalho
O seu espaço de trabalho Azure Databricks contém várias categorias de ativos que pode exportar:
- Configuração do espaço de trabalho: Cadernos, pastas, repositórios, segredos, utilizadores, grupos, listas de controlo de acesso (ACLs), configurações de clusters e definições de tarefas.
- Ativos de dados: Tabelas geridas, bases de dados, ficheiros do sistema de ficheiros Databricks e dados armazenados em armazenamento na cloud.
- Recursos de computação: Configurações de cluster, políticas e definições de pool de instâncias.
- Recursos de IA e ML: experiências MLflow, execuções, modelos, tabelas de Feature Store, índices de Pesquisa Vetorial e modelos do Catálogo Unity.
- Objetos do Catálogo Unity: Configuração do Metastore, catálogos, esquemas, tabelas, volumes e permissões.
Define o âmbito da tua exportação
Crie uma lista de verificação de ativos para exportar com base nas suas necessidades. Considere estas perguntas:
- Precisas de exportar todos os assets ou apenas categorias específicas?
- Existem requisitos de conformidade ou segurança que determinam quais os ativos que deve exportar?
- Precisas de preservar relações entre ativos (por exemplo, trabalhos que referenciam cadernos)?
- Precisa de recriar a configuração do espaço de trabalho noutro ambiente?
Planear o âmbito de exportação ajuda-o a escolher as ferramentas certas e a evitar perder dependências críticas.
Configuração do espaço de trabalho de exportação
O exportador Terraform é a principal ferramenta para exportar a configuração do espaço de trabalho. Gera ficheiros de configuração Terraform que representam os teus ativos de espaço de trabalho como código.
Use o exportador Terraform
O exportador Terraform está integrado no fornecedor Azure Databricks Terraform e gera ficheiros de configuração Terraform para recursos de espaço de trabalho, incluindo notebooks, jobs, clusters, utilizadores, grupos, segredos e listas de controlo de acesso. O exportador deve ser executado separadamente para cada espaço de trabalho. Veja o fornecedor Databricks Terraform.
Pré-requisitos:
- Terraform instalado no seu computador
- Autenticação do Azure Databricks configurada
- Privilégios de administrador no espaço de trabalho que quer exportar
Para exportar recursos do espaço de trabalho:
Veja o vídeo de exemplo de utilização para uma demonstração do funcionamento do exportador.
Descarregue e instale o fornecedor Terraform com a ferramenta exportadora:
wget -q -O terraform-provider-databricks.zip $(curl -s https://api.github.com/repos/databricks/terraform-provider-databricks/releases/latest|grep browser_download_url|grep linux_amd64|sed -e 's|.*: "\([^"]*\)".*$|\1|') unzip -d terraform-provider-databricks terraform-provider-databricks.zipConfigure variáveis de ambiente de autenticação para o seu espaço de trabalho:
export DATABRICKS_HOST=https://your-workspace-url export DATABRICKS_TOKEN=your-tokenExecute o exportador para gerar ficheiros de configuração do Terraform:
terraform-provider-databricks exporter \ -directory ./exported-workspace \ -listing notebooks,jobs,clusters,users,groups,secretsOpções comuns para exportadores:
-
-listing: Especificar tipos de recursos a exportar (separados por vírgulas) -
-services: Alternativa à listagem para filtrar recursos -
-directory: Diretório de saída para ficheiros gerados.tf -
-incremental: Executa em modo incremental para migrações em etapas
-
Revise os ficheiros gerados
.tfno diretório de saída. O exportador cria um ficheiro para cada tipo de recurso.
Observação
O exportador Terraform foca-se na configuração do espaço de trabalho e nos metadados. Não exporta os dados reais armazenados em tabelas ou no sistema de ficheiros Databricks. Deve exportar os dados separadamente utilizando as abordagens descritas nas secções seguintes.
Tipos de ativos específicos para exportação
Para ativos não totalmente cobertos pelo exportador Terraform, utilize estas abordagens:
- Cadernos: Descarregue cadernos individualmente a partir da interface do utilizador do espaço de trabalho ou use a API do Workspace para exportar os cadernos de forma programática. Veja Gerir objetos de espaço de trabalho.
- Segredos: Os segredos não podem ser exportados diretamente por razões de segurança. Tens de recriar manualmente os segredos no ambiente alvo. Documentar nomes e âmbitos secretos para referência.
- Objetos MLflow: Use a ferramenta mlflow-export-import para exportar experiências, execuções e modelos. Consulte a secção de ativos de ML abaixo.
Dados de exportação
Os dados dos clientes normalmente ficam no armazenamento da sua conta na cloud, não no Azure Databricks. Não precisas de exportar dados que já estão no teu armazenamento na cloud. No entanto, precisa de exportar dados armazenados em localizações geridas pelo Azure Databricks.
Exportar tabelas geridas
Embora as tabelas geridas estejam dentro do seu armazenamento na cloud, são armazenadas numa hierarquia baseada em UUID que pode ser difícil de analisar. Pode usar o DEEP CLONE comando para reescrever tabelas geridas como tabelas externas numa localização especificada, tornando-as mais fáceis de trabalhar.
Comandos de exemplo DEEP CLONE :
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/storage/`
DEEP CLONE my_catalog.my_schema.my_table
Para um script completo que clone todas as tabelas dentro de uma lista de catálogos, veja o script de exemplo abaixo.
Exportar armazenamento padrão do Databricks
Para espaços de trabalho serverless, o Azure Databricks oferece armazenamento padrão, que é uma solução de armazenamento totalmente gerido dentro da conta do Azure Databricks. Os dados no armazenamento padrão devem ser exportados para contentores de armazenamento propriedade do cliente antes da eliminação ou desativação do espaço de trabalho. Para mais informações sobre espaços de trabalho serverless, consulte Criar um espaço de trabalho serverless.
Para tabelas em armazenamento padrão, use DEEP CLONE para escrever dados num contentor de armazenamento propriedade do cliente. Para volumes e ficheiros arbitrários, siga os mesmos padrões descritos na secção de exportação raiz do DBFS abaixo.
Exportar raiz do sistema de ficheiros do Databricks
A raiz do Sistema de Ficheiros do Databricks é a localização de armazenamento legada na sua conta de espaço de trabalho que pode conter ativos pertencentes ao cliente, carregamentos de utilizadores, scripts de inicialização, bibliotecas e tabelas. Embora a raiz do sistema de ficheiros do Databrick seja um padrão de armazenamento obsoleto, os espaços de trabalho legados podem ainda ter dados armazenados nesta localização que precisam de ser exportados. Para mais informações sobre a arquitetura de armazenamento em espaços de trabalho, consulte Armazenamento em espaços de trabalho.
Exportar raiz do Sistema de Ficheiros do Databricks:
Como os buckets raiz no Azure são privados, não podes usar ferramentas nativas Azure, como azcopy mover dados entre contas de armazenamento. Em vez disso, use dbutils fs cp e Delta DEEP CLONE dentro do Azure Databricks. Isto pode demorar muito tempo a funcionar, dependendo do volume de dados.
# Copy DBFS files to a local path
dbutils.fs.cp("dbfs:/path/to/remote/folder", "/path/to/local/folder", recurse=True)
Para tabelas no armazenamento raiz do Sistema de Arquivos Databricks, use DEEP CLONE:
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/external/storage/`
DEEP CLONE delta.`dbfs:/path/to/dbfs/location`
Importante
Exportar grandes volumes de dados a partir do armazenamento na nuvem pode implicar custos significativos de transferência e armazenamento de dados. Revise os preços do seu fornecedor de cloud antes de iniciar grandes exportações.
Desafios comuns à exportação
Segredos:
Os segredos não podem ser exportados diretamente por razões de segurança. Ao usar o exportador Terraform com essa -export-secrets opção, o exportador gera uma variável em vars.tf com o mesmo nome do segredo. Deve atualizar manualmente este ficheiro com os valores secretos reais ou executar o exportador Terraform com essa -export-secrets opção (apenas para segredos geridos pelo Azure Databricks).
O Azure Databricks recomenda usar um armazenamento secreto apoiado pelo Azure Key Vault.
Exportar ativos de IA e ML
Alguns ativos de IA e ML requerem ferramentas e abordagens diferentes para exportação. Os modelos do Unity Catalog são exportados como parte do exportador Terraform.
Objetos MLflow
O MLflow não é coberto pelo exportador Terraform devido a lacunas na API e dificuldades com a serialização. Para exportar experiências, execuções, modelos e artefactos MLflow, utilize a ferramenta mlflow-export-import. Esta ferramenta open-source oferece uma cobertura semi-completa da migração do MLflow.
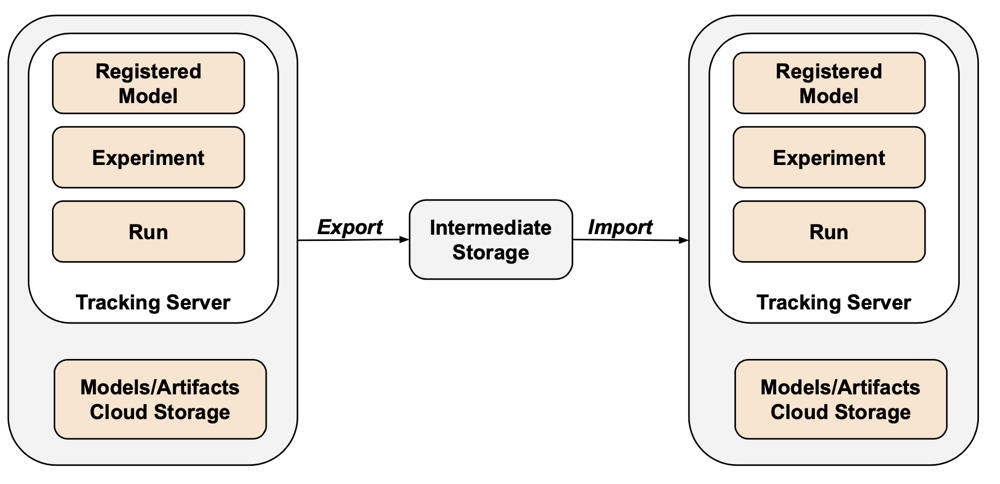
Para cenários apenas de exportação, pode armazenar todos os ativos do MLflow dentro de um bucket propriedade do cliente sem necessidade de realizar a etapa de importação. Para mais informações sobre a gestão de MLflow, consulte Gerir o ciclo de vida do modelo no Unity Catalog.
Armazenamento de Funcionalidades e Pesquisa Vetorial
Índices de Pesquisa Vetorial: Os índices de Pesquisa Vetorial não estão incluídos nos procedimentos de exportação de dados da UE. Se ainda quiser exportá-las, devem ser escritas numa tabela padrão e depois exportadas usando DEEP CLONE.
Tabelas de Feature Store: A Feature Store deve ser tratada de forma semelhante aos índices de Pesquisa Vetorial. Usando SQL, selecione dados relevantes e escreva-os numa tabela padrão, depois exporte usando DEEP CLONE.
Validar dados exportados
Após exportar os dados do espaço de trabalho, valide que jobs, utilizadores, cadernos e outros recursos foram exportados corretamente antes de desativar o ambiente antigo. Use a lista de verificação que criou durante a fase de definição e planeamento para verificar se tudo o que esperava exportar foi exportado com sucesso.
Lista de verificação
Use esta lista de verificação para verificar a sua exportação:
- Ficheiros de configuração gerados: Os ficheiros de configuração Terraform são criados para todos os recursos necessários do espaço de trabalho.
- Cadernos exportados: Todos os cadernos são exportados com o seu conteúdo e metadados intactos.
- Tabelas clonadas: As tabelas geridas são clonadas com sucesso para o local de exportação.
- Ficheiros de dados copiados: Os dados de armazenamento na cloud são copiados completamente sem erros.
- Objetos MLflow exportados: Experiências, execuções e modelos são exportados com seus artefatos.
- Permissões documentadas: As listas e permissões de controlo de acesso são capturadas na configuração do Terraform.
- Dependências identificadas: As relações entre ativos (por exemplo, trabalhos que referenciam cadernos) são preservadas na exportação.
Melhores práticas pós-exportação
A validação e os testes de aceitação dependem em grande parte dos seus requisitos e podem variar bastante. No entanto, aplicam-se estas melhores práticas gerais:
- Defina um banco de testes: Crie um banco de testes de trabalhos ou notebooks que validem que segredos, dados, montagens, conectores e outras dependências estão a funcionar corretamente no ambiente exportado.
- Comece pelos ambientes de desenvolvimento: Se for avançar de forma faseada, comece pelo ambiente de desenvolvimento e avance até à produção. Isto revela problemas graves desde cedo e evita impactos na produção.
- Aproveite as pastas Git: Sempre que possível, use pastas Git, pois estão num repositório Git externo. Isto evita a exportação manual e garante que o código é idêntico em todos os ambientes.
- Documente o processo de exportação: Registre as ferramentas usadas, os comandos executados e quaisquer problemas encontrados.
- Dados exportados seguros: Garanta que os dados exportados são armazenados de forma segura com controlos de acesso adequados, especialmente se contiverem informação sensível ou pessoalmente identificável.
- Manter a conformidade: Se exportar para fins de conformidade, verifique se a exportação cumpre os requisitos regulamentares e as políticas de retenção.
Exemplos de scripts e automação
Podes automatizar exportações de espaços de trabalho usando scripts e tarefas agendadas.
Script de exportação de Deep Clone
O script seguinte exporta tabelas geridas pelo Unity Catalog usando DEEP CLONE. Este código deve ser executado no espaço de trabalho fonte para exportar um dado catálogo para um bucket intermédio. Atualize as variáveis catalogs_to_copy e dest_bucket.
import pandas as pd
# define catalogs and destination bucket
catalogs_to_copy = ["my_catalog_name"]
dest_bucket = "<cloud-storage-path>://my-intermediate-bucket"
manifest_name = "manifest"
# initialize vars
system_info = sql("SELECT * FROM system.information_schema.tables")
copied_table_names = []
copied_table_types = []
copied_table_schemas = []
copied_table_catalogs = []
copied_table_locations = []
# loop through all catalogs to copy, then copy all non-system tables
# note: this would likely be parallelized using thread pooling in prod
for catalog in catalogs_to_copy:
filtered_tables = system_info.filter((system_info.table_catalog == catalog) & (system_info.table_schema != "information_schema"))
for table in filtered_tables.collect():
schema = table['table_schema']
table_name = table['table_name']
table_type = table['table_type']
print(f"Copying table {schema}.{table_name}...")
target_location = f"{dest_bucket}/{catalog}_{schema}_{table_name}"
sqlstring = f"CREATE TABLE delta.`{target_location}` DEEP CLONE {catalog}.{schema}.{table_name}"
sql(sqlstring)
# lists used to create manifest table DF
copied_table_names.append(table_name)
copied_table_types.append(table_type)
copied_table_schemas.append(schema)
copied_table_catalogs.append(catalog)
copied_table_locations.append(target_location)
# create the manifest as a df and write to a table in dr target
# this contains catalog, schema, table and location
manifest_df = pd.DataFrame({"catalog": copied_table_catalogs,
"schema": copied_table_schemas,
"table": copied_table_names,
"location": copied_table_locations,
"type": copied_table_types})
spark.createDataFrame(manifest_df).write.mode("overwrite").format("delta").save(f"{dest_bucket}/{manifest_name}")
display(manifest_df)
Considerações de automação
Ao automatizar exportações:
- Use trabalhos agendados: Crie trabalhos Azure Databricks que executem scripts de exportação de forma regular.
- Monitorizar trabalhos de exportação: Configure alertas para o notificar se as exportações falharem ou demorarem mais do que o esperado.
- Gerir credenciais: Armazene credenciais de armazenamento na cloud e tokens de API de forma segura usando os segredos do Azure Databricks. Consulte Gestão secreta.
- Exportações de versões: Use carimbos temporais ou números de versão nos caminhos de exportação para manter as exportações históricas.
- Limpar exportações antigas: Implementar políticas de retenção para eliminar exportações antigas e gerir custos de armazenamento.
- Exportações incrementais: Para grandes espaços de trabalho, considere implementar exportações incrementais que só exportam dados alterados desde a última exportação.