Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo fornece soluções para problemas comuns que você pode encontrar ao usar o EventProcessorClient tipo. Se você estiver procurando soluções para outros problemas comuns que pode encontrar ao usar Hubs de Eventos do Azure, consulte Solucionar problemas de Hubs de Eventos do Azure.
412 Erros de pré-condição ao usar um processador de eventos
412 Os erros de pré-condição ocorrem quando o cliente tenta assumir ou renovar a propriedade de uma partição, mas a versão local do registro de propriedade está desatualizada. Esse problema ocorre quando outra instância do processador rouba a propriedade da partição. Para obter mais informações, consulte a próxima seção.
A propriedade da partição muda frequentemente
Quando o número de instâncias EventProcessorClient muda (ou seja, são adicionadas ou removidas), as instâncias em execução tentam equilibrar a carga das partições entre si. Por alguns minutos após as alterações no número de processadores, espera-se que as partições mudem de proprietário. Depois de equilibrada, a propriedade da partição deve ser estável e mudar com pouca frequência. Se a propriedade da partição estiver mudando com frequência quando o número de processadores for constante, isso provavelmente indica um problema. Recomendamos que você registre um problema no GitHub com logs e uma reprodução.
A propriedade da partição é determinada através dos registos de propriedade no CheckpointStore. Em cada intervalo de balanceamento de carga, o EventProcessorClient executará as seguintes tarefas:
- Obtenha os registos de propriedade mais recentes.
- Verifique os registos para ver quais registos não atualizaram o seu carimbo de data/hora dentro do intervalo de expiração da propriedade da partição. Só são considerados os registos que correspondam a estes critérios.
- Se houver partições não pertencentes e a carga não estiver equilibrada entre instâncias de
EventProcessorClient, o cliente do processador de eventos tentará reivindicar uma partição. - Atualize o registro de propriedade para as partições que ele possui que têm um link ativo para essa partição.
Você pode configurar o balanceamento de carga e os intervalos de expiração de propriedade ao criar o EventProcessorClient através do EventProcessorClientBuilder, conforme descrito na lista a seguir:
- O método loadBalancingUpdateInterval(Duration) indica com que frequência o ciclo de balanceamento de carga é executado.
- O método partitionOwnershipExpirationInterval(Duration) indica a quantidade mínima de tempo desde que o registro de propriedade foi atualizado, antes que o processador considere uma partição sem propriedade.
Por exemplo, se um registo de propriedade foi atualizado às 9h30 e partitionOwnershipExpirationInterval tem 2 minutos. Quando ocorre um ciclo de balanceamento de carga e ele percebe que o registro de propriedade não foi atualizado nos últimos 2 minutos ou até 9h32, ele considerará a partição sem propriedade.
Se ocorrer um erro em um dos consumidores de partição, ele fechará o consumidor correspondente, mas não tentará recuperá-lo até o próximo ciclo de balanceamento de carga.
"... recetor atual '<RECEIVER_NAME>' com época '0' está sendo desconectado"
A mensagem de erro completa é semelhante à seguinte saída:
New receiver 'nil' with higher epoch of '0' is created hence current receiver 'nil' with epoch '0'
is getting disconnected. If you are recreating the receiver, make sure a higher epoch is used.
TrackingId:<GUID>, SystemTracker:<NAMESPACE>:eventhub:<EVENT_HUB_NAME>|<CONSUMER_GROUP>,
Timestamp:2022-01-01T12:00:00}"}
Este erro é esperado quando o balanceamento de carga ocorre depois que as instâncias EventProcessorClient são adicionadas ou removidas. O balanceamento de carga é um processo contínuo. Ao utilizar o BlobCheckpointStore com o seu consumidor, a cada ~30 segundos (por defeito), o consumidor verifica quais consumidores têm reivindicações para cada partição e, em seguida, aplica lógica para determinar se precisa "roubar" uma partição de outro consumidor. O mecanismo de serviço usado para afirmar a propriedade exclusiva sobre uma partição é conhecido como a Época.
No entanto, se nenhuma instância estiver sendo adicionada ou removida, há um problema subjacente que deve ser resolvido. Para obter mais informações, consulte a seção Mudanças frequentes de propriedade da partição e Problemas de arquivamento do GitHub.
Uso elevado de CPU
O alto uso da CPU geralmente ocorre porque uma instância possui muitas partições. Recomendamos não mais do que três partições para cada núcleo da CPU. É melhor começar com 1.5 partições para cada núcleo da CPU e, em seguida, testar aumentando o número de partições possuídas.
Sem memória e escolhendo o tamanho da pilha
O problema de falta de memória (OOM) pode ocorrer se o heap máximo atual da JVM for insuficiente para executar a aplicação. Você pode querer medir o requisito de heap do aplicativo. Em seguida, com base no resultado, dimensione a pilha definindo a memória máxima apropriada para o heap usando a opção JVM -Xmx.
Você não deve especificar -Xmx como um valor maior do que a memória disponível ou limite definido para o host (a VM ou contêiner) - por exemplo, a memória solicitada na configuração do contêiner. Você deve alocar memória suficiente para o host suportar o heap Java.
As etapas a seguir descrevem uma maneira típica de medir o valor para max Java Heap:
Execute o aplicativo em um ambiente próximo à produção, onde o aplicativo envia, recebe e processa eventos sob a carga de pico esperada na produção.
Aguarde até que a aplicação atinja um estado estacionário. Nesta etapa, o aplicativo e a JVM teriam carregado todos os objetos de domínio, tipos de classe, instâncias estáticas, pools de objetos (TCP, pools de conexão de banco de dados), etc.
No estado estacionário, você vê o padrão estável em forma de dente de serra para a coleção de pilha, conforme mostrado na captura de tela a seguir:
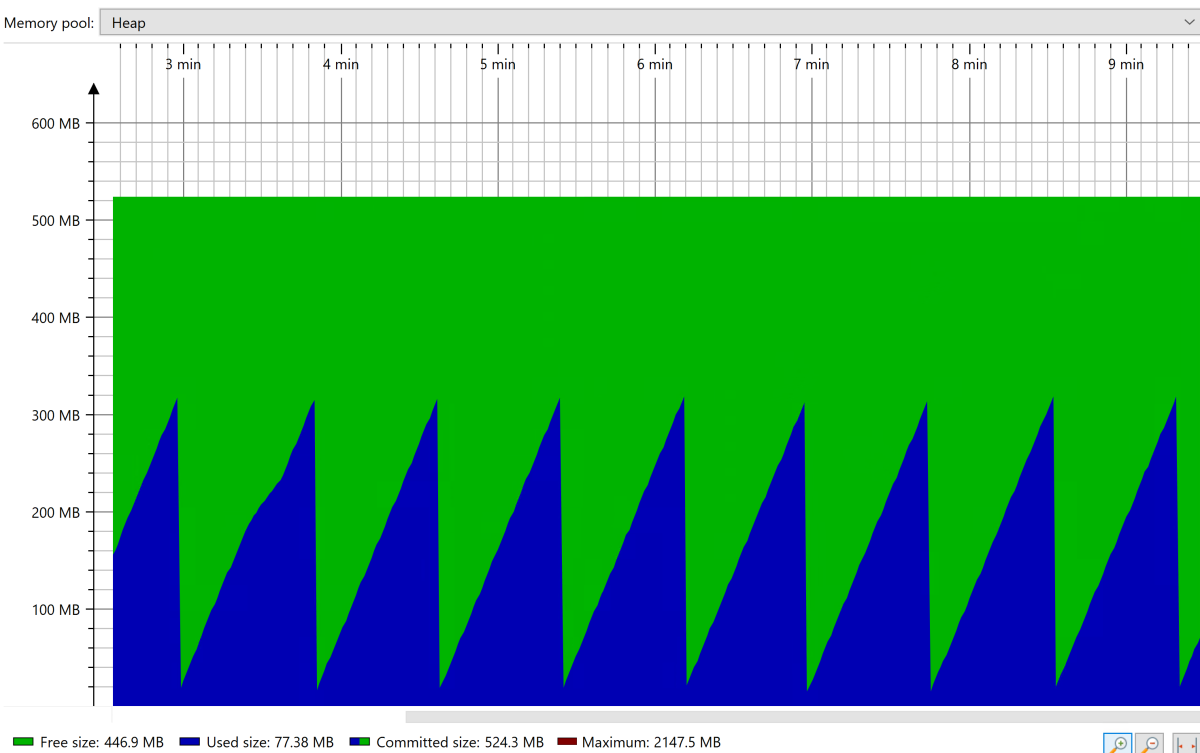
Depois que o aplicativo atingir o estado estacionário, force uma coleta de lixo completa (GC) usando ferramentas como JConsole. Observe a memória ocupada após o GC completo. Você deseja dimensionar a pilha de modo que apenas 30% sejam ocupados após o GC completo. Você pode usar esse valor para definir o tamanho máximo da pilha (usando
-Xmx).

Se estiver no contentor, dimensione-o para ter ~1 GB adicional de memória para a necessidade de memória fora do heap da instância da JVM.
Cliente do processador para de receber
O cliente do processador geralmente é executado continuamente em um aplicativo host por dias a fio. Às vezes, ele percebe que EventProcessorClient não está processando uma ou mais partições. Normalmente, não há informações suficientes para determinar por que a exceção ocorreu. A EventProcessorClient parada é o sintoma de uma causa subjacente (ou seja, a condição de corrida) que ocorreu ao tentar se recuperar de um erro transitório. Para obter as informações necessárias, consulte Arquivando problemas do GitHub.
Duplo EventData recebido quando o processador é reiniciado
O serviço EventProcessorClient e Hubs de Eventos garante uma entrega ao menos uma vez. Você pode adicionar metadados para discernir eventos duplicados. Para obter mais informações, consulte Os Hubs de Eventos do Azure garantem uma entrega pelo menos uma vez? no Stack Overflow. Caso necessite de uma entrega única, deve considerar o Service Bus, que aguarda uma confirmação do cliente. Para obter uma comparação dos serviços de mensagens, consulte Escolhendo entre os serviços de mensagens do Azure.
Cliente consumidor de baixo nível deixa de receber
EventHubConsumerAsyncClient é um cliente consumidor de baixo nível fornecido pela biblioteca de Hubs de Eventos, projetado para usuários avançados que exigem maior controle e flexibilidade sobre seus aplicativos Reativos. Este cliente oferece uma interface de baixo nível, permitindo que os utilizadores gerenciem o backpressure, threading e a recuperação dentro da cadeia Reactor. Ao contrário de EventProcessorClient, EventHubConsumerAsyncClient não inclui mecanismos de recuperação automática para todas as causas terminais. Portanto, os usuários devem lidar com eventos terminais e selecionar operadores de reatores apropriados para implementar estratégias de recuperação.
O EventHubConsumerAsyncClient::receiveFromPartition método emite um erro terminal quando a conexão encontra um erro não recuperável ou quando uma série de tentativas de recuperação de conexão falha consecutivamente, esgotando o limite máximo de repetição. Embora o recetor de baixo nível tente se recuperar de erros transitórios, espera-se que os usuários do cliente consumidor lidem com eventos de terminal. Se a receção contínua de eventos for desejada, a aplicação deve ajustar a cadeia do Reator para criar um novo cliente consumidor num evento terminal.
Migrar da biblioteca herdada para a nova biblioteca de cliente
O guia de migração inclui etapas sobre a migração do cliente herdado e a migração de pontos de verificação herdados.
Próximos passos
Se as diretrizes de solução de problemas neste artigo não ajudarem a resolver problemas quando você usa o SDK do Azure para bibliotecas de cliente Java, recomendamos que você arquive um problema no repositório SDK do Azure para Java GitHub.