Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Serviços de DevOps do Azure | Azure DevOps Server | Azure DevOps Server 2022
Você pode organizar o seu pipeline em tarefas. Cada pipeline tem pelo menos uma tarefa. Um trabalho é uma série de etapas que são executadas sequencialmente como uma unidade. Em outras palavras, um trabalho é a menor unidade de trabalho que pode ser programada para ser executada.
Para saber mais sobre os principais conceitos e componentes que compõem um pipeline, consulte Conceitos-chave para novos usuários do Azure Pipelines.
O Azure Pipelines não oferece suporte à prioridade de trabalho para pipelines YAML. Para controlar quando os trabalhos são executados, você pode especificar condições e dependências.
Definir um único trabalho
No caso mais simples, um pipeline tem uma única tarefa. Nesse caso, você não precisa usar explicitamente a job palavra-chave, a menos que esteja usando um modelo. Você pode especificar diretamente as etapas em seu arquivo YAML.
Este ficheiro YAML tem um trabalho que é executado num agente hospedado pela Microsoft e produz saídas .
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
Talvez queiras especificar mais propriedades nessa tarefa. Nesse caso, você pode usar a job palavra-chave.
jobs:
- job: myJob
timeoutInMinutes: 10
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
O seu pipeline pode ter múltiplas tarefas. Nesse caso, use a jobs palavra-chave.
jobs:
- job: A
steps:
- bash: echo "A"
- job: B
steps:
- bash: echo "B"
O seu processo pode ter várias etapas, cada uma com várias tarefas. Nesse caso, use a stages palavra-chave.
stages:
- stage: A
jobs:
- job: A1
- job: A2
- stage: B
jobs:
- job: B1
- job: B2
A sintaxe completa para especificar um trabalho é:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
A sintaxe completa para especificar um trabalho é:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
uses: # Any resources (repos or pools) required by this job that are not already referenced
repositories: [ string ] # Repository references to Azure Git repositories
pools: [ string ] # Pool names, typically when using a matrix strategy for the job
Se a intenção principal do seu trabalho for implantar seu aplicativo (em vez de criar ou testar seu aplicativo), você poderá usar um tipo especial de trabalho chamado trabalho de implantação.
A sintaxe de um trabalho de implantação é:
- deployment: string # instead of job keyword, use deployment keyword
pool:
name: string
demands: string | [ string ]
environment: string
strategy:
runOnce:
deploy:
steps:
- script: echo Hi!
Embora possas adicionar etapas para tarefas de implementação num job, recomendamos que, em vez disso, utilizes uma tarefa de implementação. Uma tarefa de implantação tem alguns benefícios. Por exemplo, você pode implantar num ambiente, o que inclui benefícios como poder visualizar o histórico do que foi implementado.

Tipos de empregos
Os trabalhos podem ser de diferentes tipos, dependendo de onde são executados.
- Os trabalhos de pool de agentes são executados num agente num pool de agentes.
- Os trabalhos de servidor são executadas no Azure DevOps Server.
- Os trabalhos de contentor são executados num contentor num agente de um conjunto de agentes. Para obter mais informações sobre como escolher contêineres, consulte Definir trabalhos de contêiner.
Trabalhos no pool de agentes
Os trabalhos de pool de agentes são os trabalhos mais comuns. Esses trabalhos são executados num agente num grupo de agentes. Você pode especificar o pool no qual executar o trabalho e também pode especificar demandas para especificar quais recursos um agente deve ter para executar seu trabalho. Os agentes podem ser hospedados pela Microsoft ou auto-hospedados. Para mais informações, veja agentes do Azure Pipelines.
- Quando estiver a utilizar agentes hospedados pela Microsoft, cada tarefa num pipeline recebe um novo agente.
- Ao usar agentes auto-hospedados, você pode usar demandas para especificar quais recursos um agente deve ter para executar seu trabalho. Você pode obter o mesmo agente para trabalhos consecutivos, dependendo se há mais de um agente em seu pool de agentes que corresponda às demandas do seu pipeline. Se houver apenas um agente em seu pool que corresponda às demandas do pipeline, o pipeline aguardará até que esse agente esteja disponível.
Nota
As exigências e as capacidades são projetadas para uso com agentes autoalojados, para que as tarefas possam ser associadas a um agente que satisfaça os requisitos da tarefa. Ao usar agentes hospedados pela Microsoft, você seleciona uma imagem para o agente que corresponde aos requisitos do trabalho. Embora seja possível adicionar recursos a um agente hospedado pela Microsoft, você não precisa usar recursos com agentes hospedados pela Microsoft.
pool:
name: myPrivateAgents # your job runs on an agent in this pool
demands: agent.os -equals Windows_NT # the agent must have this capability to run the job
steps:
- script: echo hello world
Ou múltiplas exigências:
pool:
name: myPrivateAgents
demands:
- agent.os -equals Darwin
- anotherCapability -equals somethingElse
steps:
- script: echo hello world
Saiba mais sobre os recursos do agente.
Trabalhos no servidor
O servidor orquestra e executa tarefas em um trabalho de servidor. Um trabalho de servidor não requer um agente ou nenhum computador de destino. Apenas algumas tarefas são suportadas em um trabalho de servidor agora. O tempo máximo para um trabalho de servidor é de 30 dias.
Tarefas suportadas por trabalhos sem agente
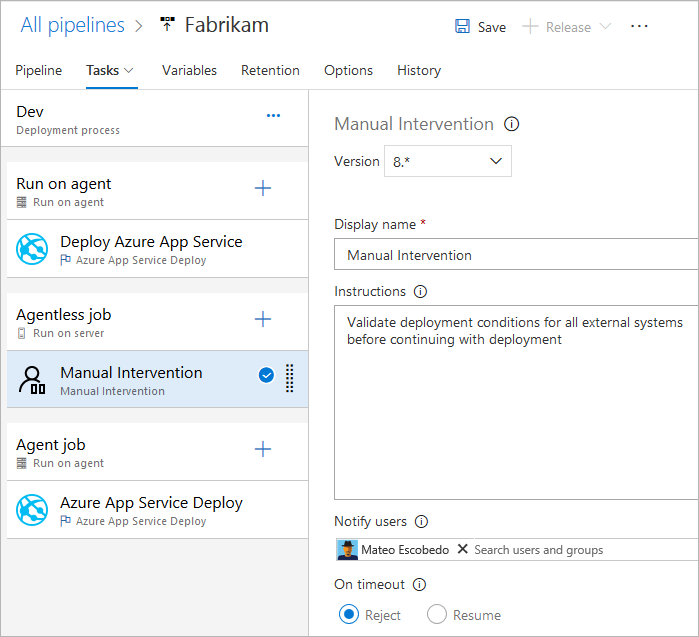
Atualmente, apenas as seguintes tarefas são suportadas de forma nativa para trabalhos sem agente.
- Atrasar tarefa
- Tarefa de Invocação do Azure Function
- Invocar tarefa da API REST
- Tarefa de validação manual
- Tarefa de Publicação no Barramento de Serviço do Azure
- Tarefa Consultar Alertas do Azure Monitor
- Tarefa de Consultar Itens de Trabalho
Como as tarefas são extensíveis, você pode adicionar mais tarefas sem agente usando extensões. O tempo limite padrão para trabalhos sem agente é de 60 minutos.
A sintaxe completa para especificar um trabalho de servidor é:
jobs:
- job: string
timeoutInMinutes: number
cancelTimeoutInMinutes: number
strategy:
maxParallel: number
matrix: { string: { string: string } }
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Você também pode usar a sintaxe simplificada:
jobs:
- job: string
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Dependências
Ao definir vários trabalhos em um único estágio, você pode especificar dependências entre eles. As pipelines devem conter pelo menos um trabalho sem dependências. Por padrão, os trabalhos de pipeline YAML do Azure DevOps são executados em paralelo, a menos que o valor dependsOn seja especificado.
Nota
Cada agente pode executar apenas um trabalho de cada vez. Para executar vários trabalhos em paralelo, você deve configurar vários agentes. Você também precisa de trabalhos paralelos suficientes.
A sintaxe para definir vários trabalhos e suas dependências é:
jobs:
- job: string
dependsOn: string
condition: string
Exemplos de trabalhos que são construídos sequencialmente:
jobs:
- job: Debug
steps:
- script: echo hello from the Debug build
- job: Release
dependsOn: Debug
steps:
- script: echo hello from the Release build
Exemplos de trabalhos que são criados em paralelo (sem dependências):
jobs:
- job: Windows
pool:
vmImage: 'windows-latest'
steps:
- script: echo hello from Windows
- job: macOS
pool:
vmImage: 'macOS-latest'
steps:
- script: echo hello from macOS
- job: Linux
pool:
vmImage: 'ubuntu-latest'
steps:
- script: echo hello from Linux
Exemplo de fan-out:
jobs:
- job: InitialJob
steps:
- script: echo hello from initial job
- job: SubsequentA
dependsOn: InitialJob
steps:
- script: echo hello from subsequent A
- job: SubsequentB
dependsOn: InitialJob
steps:
- script: echo hello from subsequent B
Exemplo de fan-in:
jobs:
- job: InitialA
steps:
- script: echo hello from initial A
- job: InitialB
steps:
- script: echo hello from initial B
- job: Subsequent
dependsOn:
- InitialA
- InitialB
steps:
- script: echo hello from subsequent
Condições
Você pode especificar as condições sob as quais cada tarefa é executada. Por padrão, um trabalho é executado se não depender de nenhum outro trabalho ou se todos os trabalhos dos quais ele depende forem concluídos com êxito. Você pode personalizar esse comportamento forçando a execução de um trabalho mesmo se um trabalho anterior falhar ou especificando uma condição personalizada.
Exemplo para executar um trabalho com base no status de execução de um trabalho anterior:
jobs:
- job: A
steps:
- script: exit 1
- job: B
dependsOn: A
condition: failed()
steps:
- script: echo this will run when A fails
- job: C
dependsOn:
- A
- B
condition: succeeded('B')
steps:
- script: echo this will run when B runs and succeeds
Exemplo de utilização de uma condição personalizada:
jobs:
- job: A
steps:
- script: echo hello
- job: B
dependsOn: A
condition: and(succeeded(), eq(variables['build.sourceBranch'], 'refs/heads/main'))
steps:
- script: echo this only runs for master
Você pode especificar que um trabalho seja executado com base no valor de uma variável de saída definida em um trabalho anterior. Nesse caso, você só pode usar variáveis definidas em trabalhos diretamente dependentes:
jobs:
- job: A
steps:
- script: "echo '##vso[task.setvariable variable=skipsubsequent;isOutput=true]false'"
name: printvar
- job: B
condition: and(succeeded(), ne(dependencies.A.outputs['printvar.skipsubsequent'], 'true'))
dependsOn: A
steps:
- script: echo hello from B
Interrupções
Para evitar a ocupação de recursos quando o seu trabalho não responde ou demora demasiado tempo, pode definir um limite de tempo para a execução do seu trabalho. Utilize a definição de tempo limite do trabalho para especificar o limite em minutos para executar o trabalho. Definir o valor como zero significa que o trabalho pode ser executado:
- Para sempre em agentes auto-hospedados
- Por 360 minutos (6 horas) em agentes hospedados pela Microsoft com um projeto público e repositório público
- Por 60 minutos em agentes hospedados pela Microsoft com um projeto ou repositório privado (a menos que se pague por capacidade extra)
O período de tempo limite começa quando o trabalho começa a ser executado. Ele não inclui o tempo que o trabalho está na fila ou à espera de um agente.
O timeoutInMinutes permite que um limite seja definido para o tempo de execução do trabalho. Quando não especificado, o padrão é 60 minutos. Quando 0 é especificado, o limite máximo é usado.
O cancelTimeoutInMinutes permite que um limite seja definido para o tempo de cancelamento do trabalho quando a tarefa de implantação é definida para continuar em execução se uma tarefa anterior falhar. Quando não especificado, o padrão é 5 minutos. O valor deve estar no intervalo de 1 a 35790 minutos.
Nota
Definir timeoutInMinutes ou cancelTimeoutInMinutes para um valor superior ao comprimento máximo de tarefa do agente alojado pela Microsoft não afeta os pipelines dos agentes alojados, pois essas tarefas expiram com base nos limites do agente alojado. Para mais informações, consulte a secção Tempo Limite anterior.
jobs:
- job: Test
timeoutInMinutes: 10 # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: 2 # how much time to give 'run always even if cancelled tasks' before stopping them
Os tempos limite têm o seguinte nível de precedência.
- Em agentes hospedados pela Microsoft, os trabalhos são limitados em quanto tempo podem ser executados com base no tipo de projeto e se são executados usando um trabalho paralelo pago. Quando o intervalo de tempo limite do trabalho hospedado pela Microsoft expira, o trabalho é encerrado. Em agentes hospedados pela Microsoft, as tarefas não podem ser executadas por mais do que o referido intervalo, independentemente de qualquer tempo limite de nível de tarefa que tenha sido especificado.
- O tempo limite configurado no nível do trabalho especifica a duração máxima para que o trabalho seja executado. Quando o intervalo de tempo limite atribuído ao nível de trabalho expira, o trabalho é encerrado. Quando o trabalho é executado num agente hospedado pela Microsoft, definir o tempo limite ao nível do trabalho para um valor superior ao tempo limite interno predefinido para trabalhos hospedados pela Microsoft não tem efeito.
- Você também pode definir o tempo limite para cada tarefa individualmente - consulte as opções de controle de tarefa. Se o intervalo de tempo limite do nível do trabalho decorrer antes da conclusão da tarefa, o trabalho em execução será encerrado, mesmo que a tarefa esteja configurada com um intervalo de tempo limite maior.
Configuração de múltiplos trabalhos
A partir de um único trabalho criado, você pode executar vários trabalhos em vários agentes em paralelo. Alguns exemplos incluem:
Compilações de várias configurações: você pode criar várias configurações em paralelo. Por exemplo, você pode criar um aplicativo Visual C++ tanto para as configurações
debugcomo parareleasee tanto nas plataformasx86como emx64. Para obter mais informações, consulte Visual Studio Build - várias configurações para várias plataformas.Implantações multiconfiguração: Pode executar várias implantações em paralelo, por exemplo, em diferentes regiões geográficas.
Teste de várias configurações: você pode executar várias configurações de teste em paralelo.
A multiconfiguração sempre gera pelo menos um trabalho, mesmo que uma variável de multiconfiguração esteja vazia.
A matrix estratégia permite que um trabalho seja despachado várias vezes, com diferentes conjuntos de variáveis. A maxParallel tag restringe a quantidade de paralelismo. O trabalho a seguir é enviado três vezes com os valores de Localização e Navegador definidos conforme especificado. No entanto, apenas dois trabalhos são executados ao mesmo tempo.
jobs:
- job: Test
strategy:
maxParallel: 2
matrix:
US_IE:
Location: US
Browser: IE
US_Chrome:
Location: US
Browser: Chrome
Europe_Chrome:
Location: Europe
Browser: Chrome
Nota
Os nomes de configuração da matriz (como US_IE no exemplo) devem conter apenas letras básicas do alfabeto latino (A - Z, a - z), números e sublinhados (_).
O nome tem de começar por uma letra.
Além disso, eles devem ter 100 caracteres ou menos.
Também é possível usar variáveis de saída para gerar uma matriz. Esse método pode ser útil se você precisar gerar a matriz usando um script.
matrix aceita uma expressão de tempo de execução contendo um objeto JSON stringified.
Esse objeto JSON, quando expandido, deve corresponder à sintaxe de matriz.
No exemplo seguinte, codificámos a string JSON, mas pode gerá-la com uma linguagem de scripting ou programa de linha de comandos.
jobs:
- job: generator
steps:
- bash: echo "##vso[task.setVariable variable=legs;isOutput=true]{'a':{'myvar':'A'}, 'b':{'myvar':'B'}}"
name: mtrx
# This expands to the matrix
# a:
# myvar: A
# b:
# myvar: B
- job: runner
dependsOn: generator
strategy:
matrix: $[ dependencies.generator.outputs['mtrx.legs'] ]
steps:
- script: echo $(myvar) # echos A or B depending on which leg is running
Fatiamento
Um trabalho de agente pode ser usado para executar um conjunto de testes em paralelo. Por exemplo, você pode executar um grande conjunto de 1.000 testes em um único agente. Ou, você pode usar dois agentes e executar 500 testes em cada um em paralelo.
Para aplicar o fatiamento, as tarefas no trabalho devem ser inteligentes o suficiente para entender a fatia a que pertencem.
A tarefa de teste do Visual Studio é uma tarefa dessas que suporta a divisão de testes. Se você instalou vários agentes, você pode especificar como a tarefa de teste do Visual Studio é executada em paralelo nesses agentes.
A parallel estratégia permite que um trabalho seja duplicado muitas vezes.
Variáveis System.JobPositionInPhase e System.TotalJobsInPhase são adicionadas a cada trabalho. As variáveis podem ser usadas nos seus scripts para dividir o trabalho entre as tarefas.
Consulte Execução paralela e múltipla usando trabalhos de agentes.
O trabalho a seguir é despachado cinco vezes com os valores de System.JobPositionInPhase e System.TotalJobsInPhase definidos de forma adequada.
jobs:
- job: Test
strategy:
parallel: 5
Variáveis de trabalho
Se você estiver usando YAML, as variáveis podem ser especificadas no trabalho. As variáveis podem ser passadas para entradas de tarefas usando a sintaxe de macro $(variableName) ou acessadas dentro de um script usando a variável stage.
Aqui está um exemplo de como definir variáveis em um trabalho e usá-las dentro de tarefas.
variables:
mySimpleVar: simple var value
"my.dotted.var": dotted var value
"my var with spaces": var with spaces value
steps:
- script: echo Input macro = $(mySimpleVar). Env var = %MYSIMPLEVAR%
condition: eq(variables['agent.os'], 'Windows_NT')
- script: echo Input macro = $(mySimpleVar). Env var = $MYSIMPLEVAR
condition: in(variables['agent.os'], 'Darwin', 'Linux')
- bash: echo Input macro = $(my.dotted.var). Env var = $MY_DOTTED_VAR
- powershell: Write-Host "Input macro = $(my var with spaces). Env var = $env:MY_VAR_WITH_SPACES"
Para obter informações sobre como usar uma condição, consulte Especificar condições.
Área de trabalho
Quando se executa um trabalho de pool de agentes, é criado um espaço de trabalho no agente. O espaço de trabalho é um diretório no qual ele baixa a fonte, executa etapas e produz saídas. O diretório do espaço de trabalho pode ser referenciado em seu trabalho usando Pipeline.Workspace a variável. Sob isso, vários subdiretórios são criados:
-
Build.SourcesDirectoryé onde as tarefas baixam o código-fonte do aplicativo. -
Build.ArtifactStagingDirectoryé onde as tarefas fazem download de artefatos necessários para o pipeline ou fazem upload de artefatos antes de serem publicados. -
Build.BinariesDirectoryé onde as tarefas escrevem as suas saídas. -
Common.TestResultsDirectoryé onde as tarefas carregam seus resultados de teste.
Os $(Build.ArtifactStagingDirectory) e $(Common.TestResultsDirectory) são sempre excluídos e recriados de novo antes de cada compilação.
Quando um pipeline é executado num agente auto-hospedado, por padrão, nenhum dos subdiretórios, além de $(Build.ArtifactStagingDirectory) e $(Common.TestResultsDirectory), é limpo entre duas execuções consecutivas. Como resultado, é possível fazer construções e implementações incrementais, caso as tarefas sejam implementadas para as utilizar. Você pode substituir esse comportamento usando a configuração workspace no trabalho.
Importante
As opções de limpeza do espaço de trabalho são aplicáveis apenas para agentes auto-hospedados. Os trabalhos são sempre executados em um novo agente com agentes hospedados pela Microsoft.
- job: myJob
workspace:
clean: outputs | resources | all # what to clean up before the job runs
Quando você especifica uma das clean opções, elas são interpretadas da seguinte forma:
-
outputs: ExcluirBuild.BinariesDirectoryantes de executar um novo trabalho. -
resources: ExcluirBuild.SourcesDirectoryantes de executar um novo trabalho. -
all: Exclua o diretórioPipeline.Workspaceinteiro antes de executar uma nova tarefa.
jobs:
- deployment: MyDeploy
pool:
vmImage: 'ubuntu-latest'
workspace:
clean: all
environment: staging
Nota
Dependendo dos recursos do agente e das demandas de pipeline, cada trabalho pode ser roteado para um agente diferente em seu pool auto-hospedado. Como resultado, é possível obter um novo agente para execuções de pipeline subsequentes (ou estágios ou trabalhos no mesmo pipeline), portanto a limpeza não garante que execuções, trabalhos ou estágios subsequentes possam acessar saídas de execuções, trabalhos ou estágios anteriores. Você pode configurar os recursos do agente e as demandas de pipeline para especificar quais agentes são usados para executar um trabalho de pipeline. Mas a menos que haja apenas um único agente no pool que atenda às demandas, não há garantia de que os trabalhos subsequentes usem o mesmo agente que os trabalhos anteriores. Para obter mais informações, consulte Especificar demandas.
Além de limpar o espaço de trabalho, é possível configurar a limpeza ajustando a definição Limpar na interface do utilizador das configurações do pipeline. Quando a definição Limpar é true, que também é o seu valor padrão, é equivalente a especificar clean: true para cada etapa de checkout do seu pipeline. Ao especificar clean: true, você executa git clean -ffdx seguido por git reset --hard HEAD antes da busca do git. Para configurar a definição Limpar:
Edite seu pipeline, escolha ..., e selecione Triggers.
Selecione YAML, Obter fontes e configure a opção Limpar desejada. O padrão é true.
Download do artefacto
Este arquivo YAML de exemplo publica o artefato Website e, em seguida, baixa o artefato para $(Pipeline.Workspace). A tarefa de Implantação só será executada se a tarefa de Construção for bem-sucedida.
# test and upload my code as an artifact named Website
jobs:
- job: Build
pool:
vmImage: 'ubuntu-latest'
steps:
- script: npm test
- task: PublishPipelineArtifact@1
inputs:
artifactName: Website
targetPath: '$(System.DefaultWorkingDirectory)'
# download the artifact and deploy it only if the build job succeeded
- job: Deploy
pool:
vmImage: 'ubuntu-latest'
steps:
- checkout: none #skip checking out the default repository resource
- task: DownloadPipelineArtifact@2
displayName: 'Download Pipeline Artifact'
inputs:
artifactName: Website
targetPath: '$(Pipeline.Workspace)'
dependsOn: Build
condition: succeeded()
Para obter informações sobre como usar dependsOn e condition, consulte Especificar condições.
Acesso ao token OAuth
Você pode permitir que scripts executados em um trabalho acessem o token de segurança OAuth atual do Azure Pipelines. O token pode ser usado para autenticar na API REST do Azure Pipelines.
O token OAuth está sempre disponível para pipelines YAML.
Ele deve ser explicitamente mapeado na tarefa ou etapa usando env.
Eis um exemplo:
steps:
- powershell: |
$url = "$($env:SYSTEM_TEAMFOUNDATIONCOLLECTIONURI)$env:SYSTEM_TEAMPROJECTID/_apis/build/definitions/$($env:SYSTEM_DEFINITIONID)?api-version=4.1-preview"
Write-Host "URL: $url"
$pipeline = Invoke-RestMethod -Uri $url -Headers @{
Authorization = "Bearer $env:SYSTEM_ACCESSTOKEN"
}
Write-Host "Pipeline = $($pipeline | ConvertTo-Json -Depth 100)"
env:
SYSTEM_ACCESSTOKEN: $(system.accesstoken)